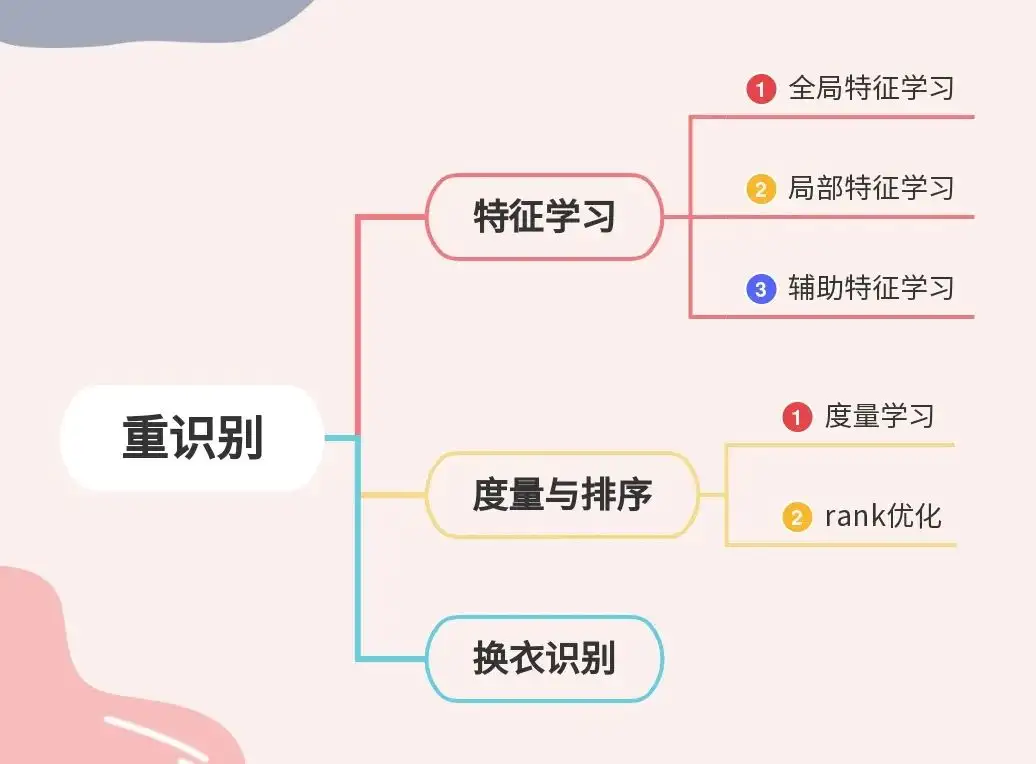
前言 本专栏针对Closed-world的ReID任务,首先介绍本任务的目标与主要数据集,包括行人重识别、跨模态行人重识别与车辆重识别。然后从三类表征学习的角度解读相关论文,表征学习是本任务的核心,大量重识别工作都致力于提高表征学习的性能。再次,我们介绍了度量学习和排序优化的发展。最后,我们解读了重识别领域最新的研究方法和研究思路。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
任务概述
ReID( Re-identification),是利用计算机视觉技术判断图像或视频中是否存在特定行人或车辆的技术,它是属于图像检索的一个子任务。ReID的概念最早在2006年的CVPR会议上被提出,简单来说,在监控拍不到目标的情况下,ReID可以代替行人、车辆识别来在视频中找到目标对象。
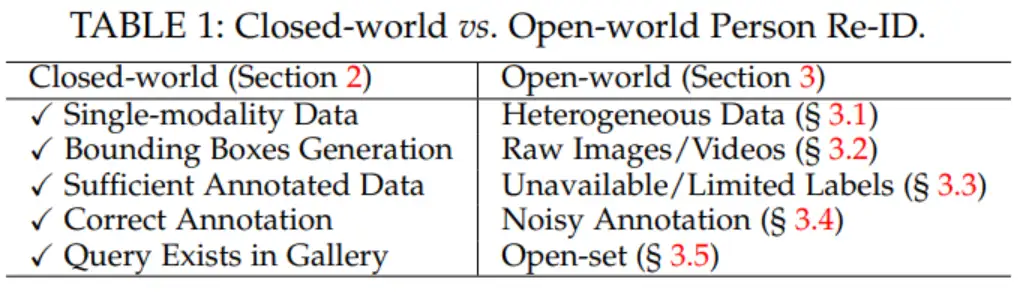
现阶段的reid问题主要分为两大类:closed-world和open-world。closed-world重在研究,主要是从一大堆行人或车辆的bounding box图片中去检索目标,而open-world重在“落地”,主要是直接从视频中去检索目标,或者是偏向无监督、弱监督学习。以下是两个world的具体区别:
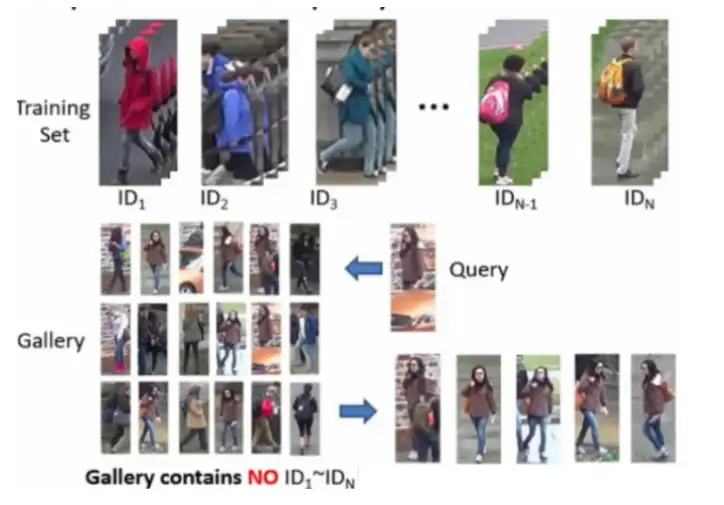
ReID作为匹配任务在测试时会用到两个数据集,Query sets 和Gallery sets,主要有以下特征:ReID数据集:1.数据集分为训练集、验证集、Query sets、Gallery sets 2.数据集通常是通过人工标注或者检测算法得到的行人、车辆图片,目前与检测独立,每个行人或车辆为一个类别子集 3.在训练集上进行模型的训练,得到模型后对Query与Gallery中的图片提取特征计算相似度,对于每个Query在Gallery中找出前N个与其相似的图片 4.训练、测试中目标身份不重复
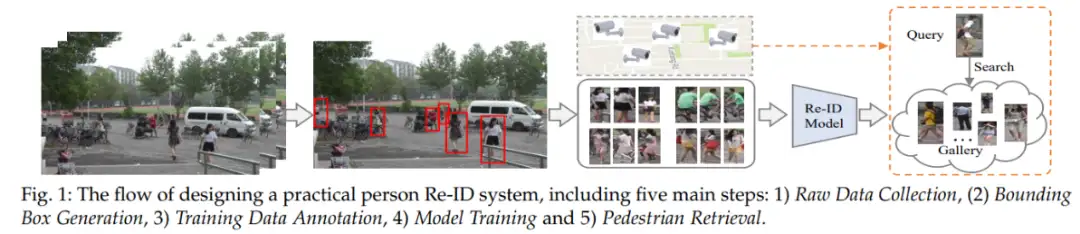
总体步骤:
行人重识别
任务难点:
- Gallery中同一个行人照片的视角不一样
- 光照条件不一样
- 行人在照片中的尺寸很小,也就导致了行人的bounding box像素很低
- 行人的姿势不一样
- 可能存在遮挡
而对于现实的“落地”,难点就更多了:
- 摄像机可能在不断增加,拍摄的场景也就更加复杂
- Gallery十分巨大
- 训练时可能不存在标注的信息(也就是需要无监督或者弱监督学习)
- 对网络的泛化能力要求很高(跨域)
- testing环节是未知的
- 行人可能换衣服了
数据集
单模态
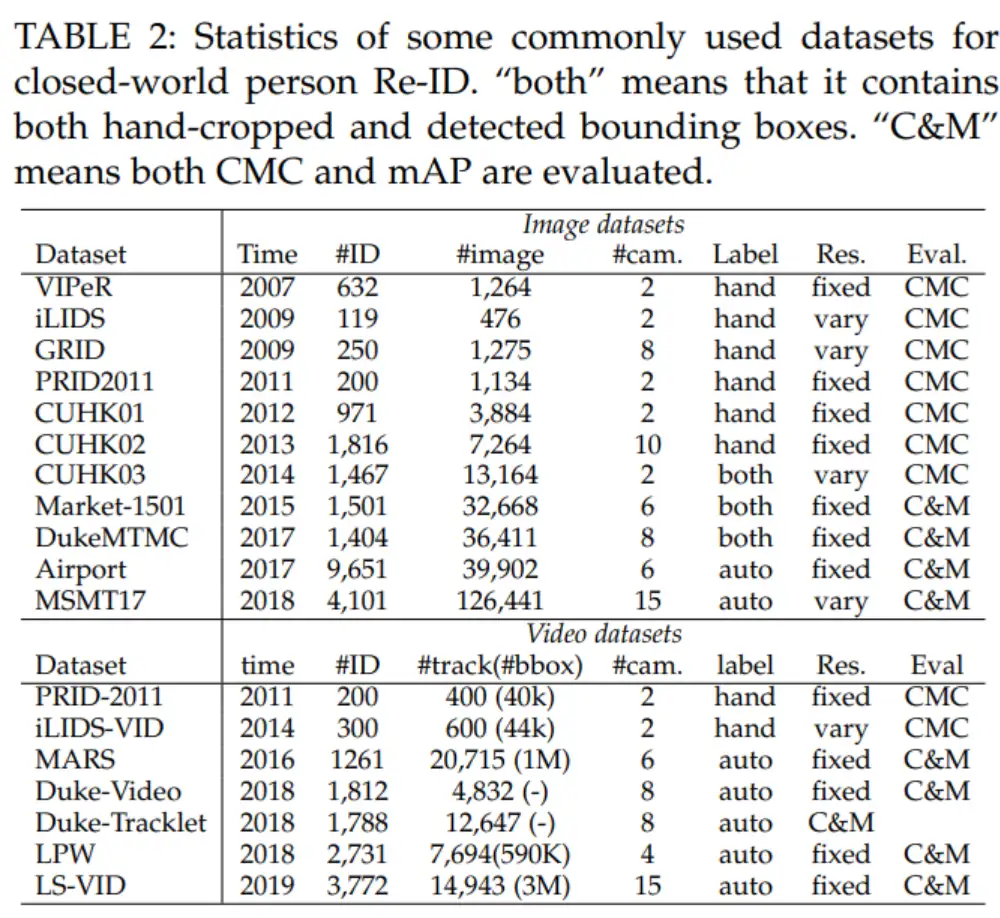
经典数据集:
Market-1501:Person Re-Identification Meets Image Search:
链接:https://pan.baidu.com/s/1ntIi2Op
2015年,论文 Person Re-Identification Meets Image Search 提出了 Market 1501 数据集,现在 Market 1501 数据集已经成为行人重识别领域最常用的数据集之一。
Market 1501 的行人图片采集自清华大学校园的 6 个摄像头,一共标注了 1501 个行人。其中,751 个行人标注用于训练集,750 个行人标注用于测试集,训练集和测试集中没有重复的行人 ID,也就是说出现在训练集中的 751 个行人均未出现在测试集中。
训练集:751 个行人,12936 张图片 测试集:750 个行人,19732 张图片 query 集:750 个行人,3368 张图片 query 集的行人图片都是手动标注的图片,从 6 个摄像头中为测试集中的每个行人选取一张图片,构成 query 集。测试集中的每个行人至多有 6 张图片,query 集共有 3368 张图片。
网络模型训练时,会用到训练集;测试模型好坏时,会用到测试集和 query 集。此时测试集也被称作 gallery 集。因此实际用到的子集为,训练集、gallery 集 和 query 集。
MARS: A Video Benchmark for Large-Scale Person Re-identification(基于视频)
链接:https://pan.baidu.com/s/1XKBdY8437O79FnjWvkjusw 提取码: ymc5
考虑了视频中的人员再识别(reid)问题,本文介绍了一个新的视频reid数据集,名为运动分析和重新识别集(MARS),是Market-1501 datase数据集的视频扩展。
MARS是迄今为止最大的视频reid数据集,它包含1,261个id和大约20,000个tracklet,与基于图像的数据集相比,它提供了丰富的视觉信息。
DukeMTMC-reID:Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in vitro
链接:https://drive.google.com/open?id=1jjE85dRCMOgRtvJ5RQV9-Afs-2_5dY3O
它的行人数据来源于论文 Performance Measures and a Data Set for Multi-Target, Multi-Camera Tracking 提出的行人追踪 DukeMTMC 数据集,DukeMTMC-reID 是 DukeMTMC 数据集的一个子集。需要注意的是,该数据集存在隐私泄露问题,作者已在官方渠道下架数据集。目前部分顶会文章仍在使用。
DukeMTMC 数据集采集自 Duke 大学的 8 个摄像头,数据集以视频形式存储,具有手动标注的行人边界框。DukeMTMC-reID 数据集从 DukeMTMC 数据集的视频中,每 120 帧采集一张图像构成 DukeMTMC-reID 数据集。原始数据集包含了85分钟的高分辨率视频,采集自8个不同的摄像头。并且提供了人工标注的bounding box。从视频中每120帧采样一张图像,得到了 36,411张图像。一共有1,404个人出现在大于两个摄像头下,有408个人只出现在一个摄像头下。所以作者随机采样了 702 个人作为训练集,702个人作为测试集。在测试集中,采样了每个ID的每个摄像头下的一张照片作为 查询图像(query)。剩下的图像加入测试的 搜索库(gallery),并且将之前的 408人作为干扰项,也加到 gallery中。最终,DukeMTMC-reID 包含了 16,522张训练图片(来自702个人), 2,228个查询图像(来自另外的702个人),以及 17,661 张图像的搜索库(gallery)。并提供切割后的图像供下载。
跨模态
RegDB:Person Recognition System Based on a Combination of Body Images from Visible Light and Thermal Cameras
数据集RegDB包含了412个行人身份,每个行人收集了10张RGB图像和10张热图像,其中有254个女性和158个男性,并且412个人中有156个人是从正面拍摄,256个人从背面拍摄。
SYSU-MM01(最常用)
链接:https://pan.baidu.com/share/init?surl=mAp_722PlqXCLYAzJi5mSw 提取码:sysu
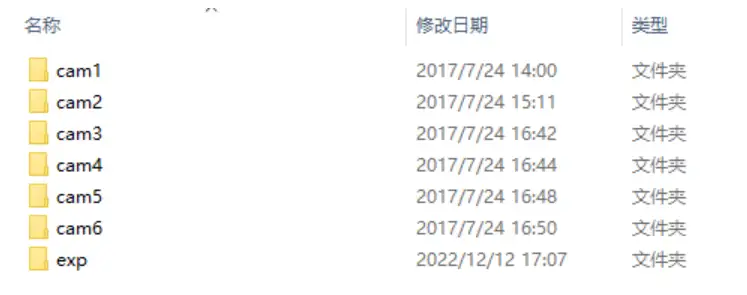
491和人物ID,296个用于训练,99个用于验证,96个用于测试,287,628 RGB images and 15,792 IR images。4个RGB相机,2个红外相机。
SYSU_MM01数据集共包含七个文件夹, 其中cam1,cam2,cam4,cam5均为RGB图像,cam3和cam6为IR(Infrared)图像.
车辆重识别
任务难点:
- 摄像机的拍摄角度不同
- 光照强度不同
- 车辆间遮挡、环境遮挡
- 色差变化
- 车头车尾角度不同
- 同型号车相似度极高
数据集
VeRi776:A Deep Learning-Based Approach to Progressive Vehicle Re-identification for Urban Surveillance
链接:https://vehiclereid.github.io/VeRi/
包含超过50,000张776辆车的图像,这些图像由20台摄像机拍摄,在24小时内覆盖1.0平方公里的面积,这使得该数据集可扩展到足以用于车辆Re-Id和其他相关研究。图像是在真实世界的无约束监视场景中捕获的,并标有不同的属性,例如:BBox,类型,颜色和品牌。因此可以学习和评估车辆Re-Id的复杂模型。每辆车在不同的视点,照明,分辨率和遮挡下由2~18台摄像机拍摄,在实际监控环境中为车辆Re-Id提供高复发率。它还标有足够的牌照和时空信息,例如板块的BBox,板条,车辆的时间戳以及相邻相机之间的距离。
VehicleID:Deep Relative Distance Learning: Tell the Difference Between Similar Vehicles
链接:https://www.pkuml.org/resources/pku-vehicleid.html
数据集包含白天在中国一个小城市中分布的多个真实监控摄像头捕获的数据,其中包括26267辆车(共221763张图像),主要包含前后两种视角,且每张图像除了车辆ID、摄像头编号的标注信息以外,还有车辆型号的详细信息(共 250 种厂商车型),为了使车辆再识别方法的性能评测更加全面,VehicleID将测试集按照车辆图像的尺寸划分为大、中、小3个子集。每个图像都带有一个与现实世界中的身份相对应的id标签。此外,作者手动标记了10319辆车辆(共90196张图像)的车辆型号信息。
VERI-Wild: A Large Dataset and a New Method for Vehicle Re-Identification in the Wild
链接:https://pan.baidu.com/share/init?surl=FzvR5iRQgh8ZbSYZPbi9aQ 提取码:kob9
该数据集收集于市郊地区,包含174个交通摄像头拍摄的 416 314 张关于 40 671 辆汽车的图像。VERI-Wild是在超过200平方公里的市郊地区收集得到的,摄像机是24小时连续拍摄30天,其长时间的连续拍摄考虑了车辆真实的各种天气和光照问题,因此车辆在被捕获的过程中不受过多限制,且车辆所处场景更加丰富,车辆图像的采集时间跨度长,光照和天气的变化十分明显。训练集包括277 797张图像(共30 671辆汽车),测试集包括138 517张图像(共10 000辆汽车)。同样地,VERI-Wild的测试集也根据图像尺寸被分为了大、中、小3个子集。
评价指标
- Rank-n:图像库搜索中置信度最靠前的 n 张图片中有正确结果的概率。例如 Rank-5 代表,搜索库中计算置信度排序,置信度最高的前 5 张图片中有正确结果的概率。
- mAP 与 mINP:AP 的计算和目标检测 AP 计算类似,即求不同 Recall 对应Precision 的平均值,mAP 为 AP 的平均值;mINP(mean Inverse Negative Penalty)计算公式如下:
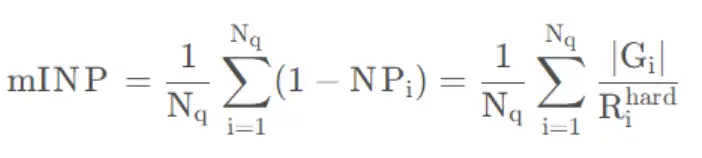
即 平均逆置负样本惩罚率。
小结
在后续的分享中,我们将从全局表征学习、局部表征学习和f辅助表征学习的思路去详细介绍这一领域的发展,然后介绍重识别中有关度量方法的进展,这与其他视觉任务的度量有较大区别。最后,我们总结重识别最新的赛道和未来的发展方向。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
CVPR'23|泛化到任意分割类别?FreeSeg:统一、通用的开放词汇图像分割新框架
全新YOLO模型YOLOCS来啦 | 面面俱到地改进YOLOv5的Backbone/Neck/Head
通用AI大型模型Segment Anything在医学图像分割领域的最新成果!
可复现、自动化、低成本、高评估水平,首个自动化评估大模型的大模型PandaLM来了
实例:手写 CUDA 算子,让 Pytorch 提速 20 倍
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary