一、选题背景
随着社交媒体的发展和智能手机的普及,抖音已经成为了全球最受欢迎的短视频平台之一。越来越多的用户通过抖音平台进行商品的选购和交易,使得抖音电商成为了一个热门的话题。因此,通过对抖音电商的爬虫分析,可以深入了解用户的购物偏好、热门商品和行业趋势,为电商平台和品牌商提供有价值的市场分析和营销策略。同时,也可以帮助监管部门对抖音电商进行监管和规范,保障消费者的权益。因此,抖音电商爬虫的选题背景具有重要的实践和研究意义。
二、主题式网络爬虫设计方案
数据来源:达多多抖音电商选品库 | 抖音短视频电商选品带货平台 - 达多多数据 (daduoduo.com)
内容:抖音电商12月销售数据
实现思路:首先需要确定要爬取的抖音电商数据,包括用户信息、商品信息、交易记录等。通过分析抖音电商的网页结构和数据接口,找到需要爬取的数据所对应的接口地址。使用Python语言编写爬虫程序,通过发送HTTP请求获取抖音电商数据接口的响应,并解析响应数据,提取所需的信息。
技术难点:反爬策略: 许多网站使用了反爬策略,如限制IP、限制访问频率等,这可能导致爬虫被禁止访问。需要解决这些问题,以保证爬虫的稳定运行。网页结构变化: 网页的结构可能会随着时间的推移而发生变化。因此,需要定期更新爬虫程序,以适应这些变化。法律法规: 在爬取网页时,需要遵守法律法规和网站的robots协议。避免爬取敏感信息或者侵犯版权。
三、主题式页面的结构特征分析
这里搜索眉笔的数据,选择近30日
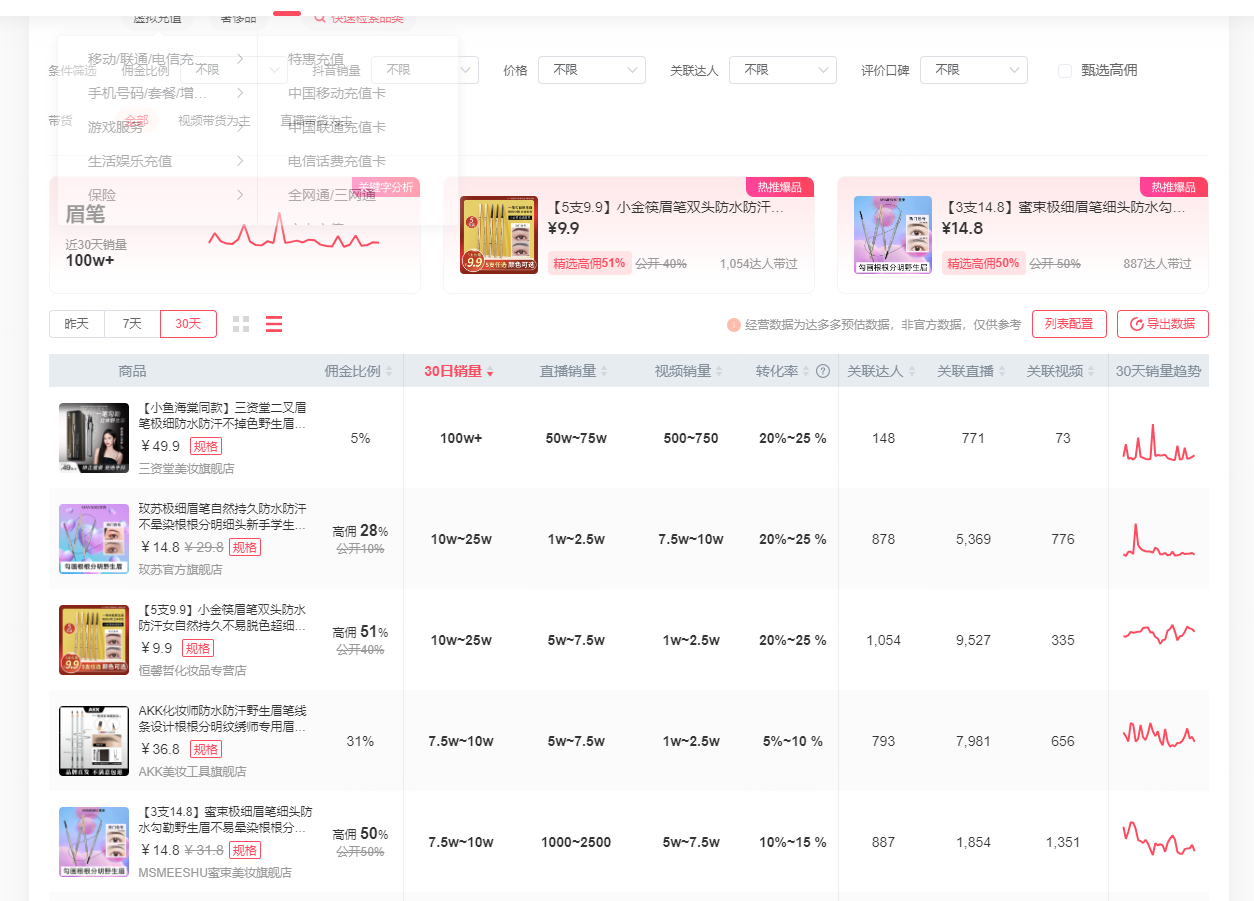
结构
四、网络爬虫程序设计
实现思路:模拟浏览器发起请求获取到返回的响应数据,并进行处理后存储到本地excel中
爬取到的数据

代码实现
1 import requests
2 import xlrd, xlwt, os
3 from xlutils.copy import copy
4
5 class DouYinShop():
6 def __init__(self):
7 pass
8
9 def spider(self):
10 start_url = 'https://www.daduoduo.com/ajax/dyLiveDataAjax.ashx'
11 headers = {
12 'authority': 'www.daduoduo.com',
13 'accept': 'application/json, text/plain, */*',
14 'accept-language': 'zh-CN,zh;q=0.9',
15 'authtoken': 'Pc:ShuJu:6359713f34b546f5a13b1a112aaf5fb8',
16 'cache-control': 'no-cache',
17 # 'content-length': '0',
18 # Requests sorts cookies= alphabetically
19 'cookie': 'Hm_lvt_d96ac5a4947d937668f115ba0d474667=1701236310; _clck=4zacm3%7C2%7Cfh4%7C0%7C1428; ESDataStatusInfo3_2023-11-29={"isDayDataOk":1,"isWeekDataOk":1,"isMonthDataOk":1}; ESDataStatusInfo1_2023-11-29={"isDayDataOk":1,"isWeekDataOk":1,"isMonthDataOk":1}; utoken=Pc:ShuJu:6359713f34b546f5a13b1a112aaf5fb8; show_holiday_vip_promotion_banner2_oXTE20TEdoDuDjnrnuCnubfSbhdo=true; acw_tc=0b32824e17012476630381685e9e2c1ac6db4eb0138d22567fa13fa9223d4f; Hm_lpvt_d96ac5a4947d937668f115ba0d474667=1701247718; _clsk=10a40y7%7C1701247718999%7C7%7C1%7Cr.clarity.ms%2Fcollect; SERVERID=9f312ff2ae689a6a6f30662ddd0d7b73|1701247772|1701247663',
20 'origin': 'https://www.daduoduo.com',
21 'pragma': 'no-cache',
22 'referer': 'https://www.daduoduo.com/product/products?keyword=%E7%94%9F%E8%9A%9D',
23 'sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A_Brand";v="24"',
24 'sec-ch-ua-mobile': '?0',
25 'sec-ch-ua-platform': '"Windows"',
26 'sec-fetch-dest': 'empty',
27 'sec-fetch-mode': 'cors',
28 'sec-fetch-site': 'same-origin',
29 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
30 }
31 params = {
32 'action': 'GetGoodsList',
33 'keyword': '眉笔',
34 'rootCatId': '0',
35 'hasFilter': '0',
36 'sortType': '1',
37 'sortValue': 'DESC',
38 'dataType': '30',
39 'pageIndex': '1', #控制翻页数据
40 'pageSize': '50',
41 }
42 response = requests.post(start_url, params=params, headers=headers).json()
43 datas = response['data']['data']
44 for data in datas:
45 #1、商品ID
46 goodsid = data['goodsId']
47 #2、商品
48 goodName = data['goodName']
49 #3、佣金比例
50 cosRate = data['cosRate']
51 #4、30日销量
52 adSaleCnt = data['adSaleCnt']
53 #5、直播销量
54 orderCnt = data['orderCnt']
55 #6、视频销量
56 videoSaleCnt = data['videoSaleCnt']
57 #7、转化率
58 thirtyInversionRate = data['thirtyInversionRate']
59 #8、关联达人
60 peopleCnt = data['peopleCnt']
61 #9、关联直播
62 roomCnt = data['roomCnt']
63 #10、关联视频
64 videoCnt = data['videoCnt']
65 #11、售价
66 sellPrice = data['sellPrice']
67 #12、品牌名
68 brandName = data['brandName']
69 #13、商品logo
70 shopLogo = data['shopLogo']
71 #14、店铺
72 shopName = data['shopName']
73 #15、商品评分
74 shopScore = data['shopScore']
75 print(goodsid,goodName,cosRate,adSaleCnt,orderCnt,videoSaleCnt,thirtyInversionRate,peopleCnt,roomCnt,videoCnt,sellPrice,brandName,shopLogo,shopName,shopScore)
76 data = {
77 '电商数据': [goodsid,goodName,cosRate,adSaleCnt,orderCnt,videoSaleCnt,thirtyInversionRate,peopleCnt,roomCnt,videoCnt,sellPrice,brandName,shopLogo,shopName,shopScore]
78 }
79 self.save_data(data)
80
81 #储存数据在excel
82 def save_data(self, data):
83 if not os.path.exists('电商数据.xls'):
84 # 1、创建 Excel 文件
85 wb = xlwt.Workbook(encoding='utf-8')
86 # 2、创建新的 Sheet 表
87 sheet = wb.add_sheet('电商数据', cell_overwrite_ok=True)
88 # 3、设置 Borders边框样式
89 borders = xlwt.Borders()
90 borders.left = xlwt.Borders.THIN
91 borders.right = xlwt.Borders.THIN
92 borders.top = xlwt.Borders.THIN
93 borders.bottom = xlwt.Borders.THIN
94 borders.left_colour = 0x40
95 borders.right_colour = 0x40
96 borders.top_colour = 0x40
97 borders.bottom_colour = 0x40
98 style = xlwt.XFStyle() # Create Style
99 style.borders = borders # Add Borders to Style
100 # 4、写入时居中设置
101 align = xlwt.Alignment()
102 align.horz = 0x02 # 水平居中
103 align.vert = 0x01 # 垂直居中
104 style.alignment = align
105 # 5、设置表头信息, 遍历写入数据, 保存数据
106 header = ('商品ID','商品','佣金比例', '30日销量', '直播销量', '视频销量','转化率','关联达人','关联直播','关联视频','售价',
107 '品牌名','商品lojo','店铺','商品评分')
108 for i in range(0, len(header)):
109 sheet.col(i).width = 2560 * 3
110 # 行,列, 内容, 样式
111 sheet.write(0, i, header[i], style)
112 wb.save('电商数据.xls')
113 # 判断工作表是否存在
114 if os.path.exists('电商数据.xls'):
115 # 打开工作薄
116 wb = xlrd.open_workbook('电商数据.xls')
117 # 获取工作薄中所有表的个数
118 sheets = wb.sheet_names()
119 for i in range(len(sheets)):
120 for name in data.keys():
121 worksheet = wb.sheet_by_name(sheets[i])
122 # 获取工作薄中所有表中的表名与数据名对比
123 if worksheet.name == name:
124 # 获取表中已存在的行数
125 rows_old = worksheet.nrows
126 # 将xlrd对象拷贝转化为xlwt对象
127 new_workbook = copy(wb)
128 # 获取转化后的工作薄中的第i张表
129 new_worksheet = new_workbook.get_sheet(i)
130 for num in range(0, len(data[name])):
131 new_worksheet.write(rows_old, num, data[name][num])
132 new_workbook.save('电商数据.xls')
133
134
135
136 if __name__ == '__main__':
137 d=DouYinShop()
138 d.spider()
五、大数据分析与可视化处理
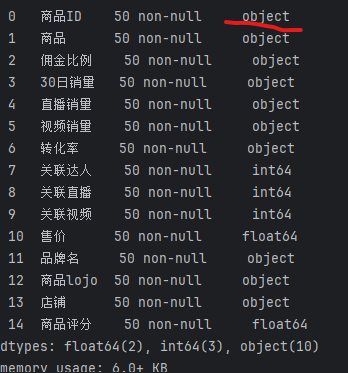
1.数据清洗
将id值转为字符型,并填充品牌名缺失的数据为未知品牌
1 import pandas as pd
2 # 读取excel文件
3 df = pd.read_excel('电商数据.xls')
4 # 输出清洗前信息
5 print(df.info())
6 # 将商品ID改为字符型
7 df["商品ID"] = df["商品ID"].astype("str")
8 # 删除重复值
9 df.drop_duplicates(inplace=True)
10 # 填充品牌名缺失值
11 df["品牌名"].fillna("未知品牌", inplace=True)
12 # 输出清洗后信息
13 print(df.info())
清洗前结果:

清洗后结果:
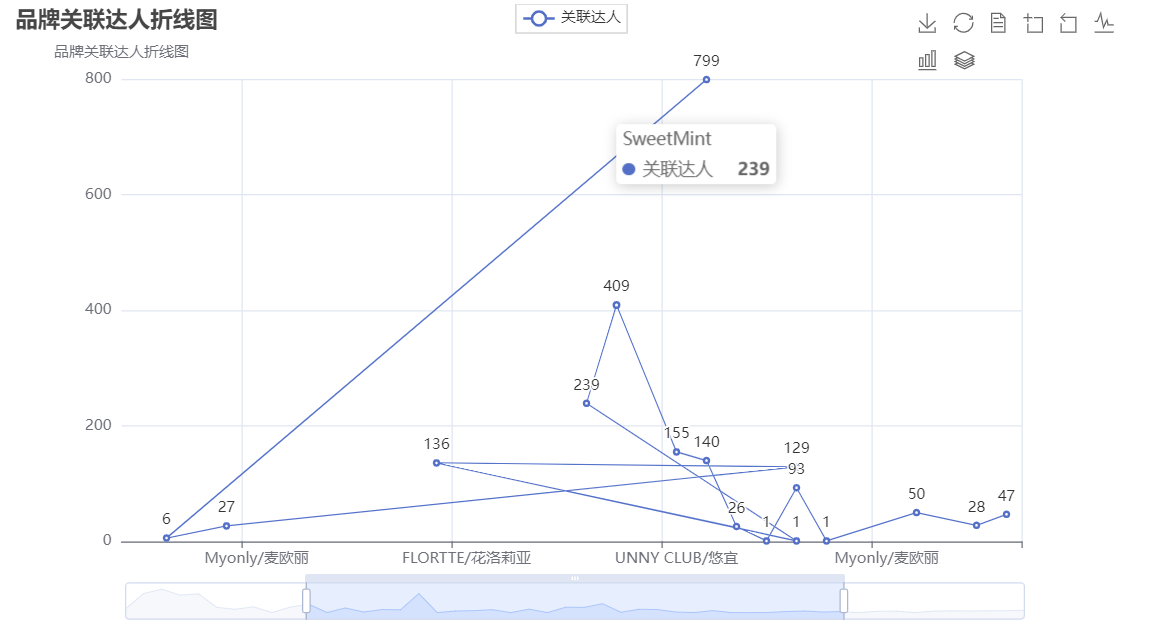
2.品牌的售价和关联达人的折线图
折线图
实现代码
1 import pandas as pd
2 from pyecharts.charts import Line, Bar
3 from pyecharts import options as opts
4
5 # 读取Excel文件
6 df = pd.read_excel('电商数据.xls')
7
8 # 提取数据
9 brands = df['品牌名'].tolist()
10 prices = df['售价'].tolist()
11 daren = df['关联达人'].tolist()
12 # 创建折线图
13 line_chart = Line()
14 line_chart.add_xaxis(brands)
15 line_chart.add_yaxis("关联达人", daren)
16 line_chart.set_global_opts(
17 title_opts=opts.TitleOpts(title="品牌关联达人折线图"),
18 toolbox_opts=opts.ToolboxOpts(),
19 tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
20 yaxis_opts=opts.AxisOpts(name="品牌关联达人折线图"),
21 xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=0)),
22 datazoom_opts=[
23 opts.DataZoomOpts(type_="slider", is_show=True),
24 opts.DataZoomOpts(type_="inside", is_show=True),
25 ],
26
27 )
28
29 # 渲染图表到HTML文件
30 line_chart.render('折线关联达人可视化.html')
3.每个品牌的售价柱状图

代码实现
1 import pandas as pd
2 from pyecharts.charts import Line, Bar
3 from pyecharts import options as opts
4
5 # 读取Excel文件
6 df = pd.read_excel('电商数据.xls')
7
8 # 提取数据
9 brands = df['品牌名'].tolist()
10 prices = df['售价'].tolist()
11 daren = df['关联达人'].tolist()
12
13 # 创建柱状图
14 bar_chart = Bar()
15 bar_chart.add_xaxis(brands)
16 bar_chart.add_yaxis("价格", prices)
17 bar_chart.set_global_opts(
18 title_opts=opts.TitleOpts(title="品牌售价柱状图"),
19 toolbox_opts=opts.ToolboxOpts(),
20 tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
21 yaxis_opts=opts.AxisOpts(name="品牌售价柱状图"),
22 xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=0)),
23 datazoom_opts=[
24 opts.DataZoomOpts(type_="slider", is_show=True),
25 opts.DataZoomOpts(type_="inside", is_show=True),
26 ],
27 )
28
29 # 渲染图表到HTML文件
30 bar_chart.render('品牌售价柱状图可视化.html')
4.每件商品出现最多的关键词
不难看出,眉笔的防水和9.9为商品名称出现频率最高的关键词

代码实现
1 from pyecharts.charts import WordCloud
2 from pyecharts import options as opts
3 from pyecharts.globals import SymbolType
4 import jieba
5 import pandas as pd
6 from collections import Counter
7
8 # 读取Excel文件
9 df = pd.read_excel('电商数据.xls')
10 # 提取商品名
11 goods_name = df["商品"].tolist()
12 # 提取关键字
13 seg_list = [jieba.lcut(text) for text in goods_name]
14 words = [word for seg in seg_list for word in seg if len(word) > 1]
15 word_counts = Counter(words)
16 word_cloud_data = [(word, count) for word, count in word_counts.items()]
17
18 # 创建词云图
19 wordcloud = (
20 WordCloud(init_opts=opts.InitOpts(bg_color='#00FFFF'))
21 .add("", word_cloud_data, word_size_range=[20, 100], shape=SymbolType.DIAMOND,
22 word_gap=5, rotate_step=45,
23 textstyle_opts=opts.TextStyleOpts(font_family='cursive', font_size=15))
24 .set_global_opts(title_opts=opts.TitleOpts(title="商品名词云图",pos_top="5%", pos_left="center"),
25 toolbox_opts=opts.ToolboxOpts(
26 is_show=True,
27 feature={
28 "saveAsImage": {},
29 "dataView": {},
30 "restore": {},
31 "refresh": {}
32 }
33 )
34
35 )
36 )
37
38 # 渲染词图到HTML文件
39 wordcloud.render("商品名词云图.html")
5.关联的直播与直播销量的关系散点图
关联的直播与直播的销量是否有关系存在?x轴为关联直播的数量,y轴为直播的销量

代码实现
这里需要对直播销量数据进行提取 取范围内的中值
1 import pandas as pd
2 from pyecharts import options as opts
3 from pyecharts.charts import Scatter, Line
4 from pyecharts.globals import ThemeType
5 from scipy import stats
6
7 # 读取excel文件
8 df = pd.read_excel("电商数据.xls")
9 # 重新排序
10 df.sort_values(by='关联直播', inplace=True)
11 # 处理直播销量数据
12 def filter_sales_pz(sales):
13 acount = sales.split("~")
14 res = list()
15 for i in acount:
16 if i.find("w") != -1:
17 i = float(i.replace("w", "")) * 10000
18 res.append(int(i))
19 return res
20
21 def filter_sales(sales):
22 acount = filter_sales_pz(sales)
23 num = acount[0]
24 if len(acount) > 1:
25 num = acount[0] + ((acount[1] - acount[0]) // 2)
26 return num
27
28
29 live_count = df["关联直播"].tolist()
30 live_sales = df["直播销量"].apply(lambda x: filter_sales(x)).tolist()
31
32 # 初始化散点图
33 scatter = Scatter()
34 scatter.add_xaxis(live_count)
35 scatter.add_yaxis("直播销量",live_sales)
36 scatter.set_global_opts(title_opts=opts.TitleOpts(title="直播销量与关联直播关系",pos_top="5%", pos_left="center"),
37 toolbox_opts=opts.ToolboxOpts(
38 is_show=True,
39 feature={
40 "saveAsImage": {},
41 "dataView": {},
42 "restore": {},
43 "refresh": {}
44 }
45 )
46 )
47 # 渲染图表到HTML文件
48 scatter.render("直播销量和关联直播的关系.html")
六、整体代码
1 import requests
2 import xlrd, xlwt, os
3 from xlutils.copy import copy
4
5 class DouYinShop():
6 def __init__(self):
7 pass
8
9 def spider(self):
10 start_url = 'https://www.daduoduo.com/ajax/dyLiveDataAjax.ashx'
11 headers = {
12 'authority': 'www.daduoduo.com',
13 'accept': 'application/json, text/plain, */*',
14 'accept-language': 'zh-CN,zh;q=0.9',
15 'authtoken': 'Pc:ShuJu:6359713f34b546f5a13b1a112aaf5fb8',
16 'cache-control': 'no-cache',
17 # 'content-length': '0',
18 # Requests sorts cookies= alphabetically
19 'cookie': 'Hm_lvt_d96ac5a4947d937668f115ba0d474667=1701236310; _clck=4zacm3%7C2%7Cfh4%7C0%7C1428; ESDataStatusInfo3_2023-11-29={"isDayDataOk":1,"isWeekDataOk":1,"isMonthDataOk":1}; ESDataStatusInfo1_2023-11-29={"isDayDataOk":1,"isWeekDataOk":1,"isMonthDataOk":1}; utoken=Pc:ShuJu:6359713f34b546f5a13b1a112aaf5fb8; show_holiday_vip_promotion_banner2_oXTE20TEdoDuDjnrnuCnubfSbhdo=true; acw_tc=0b32824e17012476630381685e9e2c1ac6db4eb0138d22567fa13fa9223d4f; Hm_lpvt_d96ac5a4947d937668f115ba0d474667=1701247718; _clsk=10a40y7%7C1701247718999%7C7%7C1%7Cr.clarity.ms%2Fcollect; SERVERID=9f312ff2ae689a6a6f30662ddd0d7b73|1701247772|1701247663',
20 'origin': 'https://www.daduoduo.com',
21 'pragma': 'no-cache',
22 'referer': 'https://www.daduoduo.com/product/products?keyword=%E7%94%9F%E8%9A%9D',
23 'sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A_Brand";v="24"',
24 'sec-ch-ua-mobile': '?0',
25 'sec-ch-ua-platform': '"Windows"',
26 'sec-fetch-dest': 'empty',
27 'sec-fetch-mode': 'cors',
28 'sec-fetch-site': 'same-origin',
29 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
30 }
31 params = {
32 'action': 'GetGoodsList',
33 'keyword': '眉笔',
34 'rootCatId': '0',
35 'hasFilter': '0',
36 'sortType': '1',
37 'sortValue': 'DESC',
38 'dataType': '30',
39 'pageIndex': '1', #控制翻页数据
40 'pageSize': '50',
41 }
42 response = requests.post(start_url, params=params, headers=headers).json()
43 datas = response['data']['data']
44 for data in datas:
45 #1、商品ID
46 goodsid = data['goodsId']
47 #2、商品
48 goodName = data['goodName']
49 #3、佣金比例
50 cosRate = data['cosRate']
51 #4、30日销量
52 adSaleCnt = data['adSaleCnt']
53 #5、直播销量
54 orderCnt = data['orderCnt']
55 #6、视频销量
56 videoSaleCnt = data['videoSaleCnt']
57 #7、转化率
58 thirtyInversionRate = data['thirtyInversionRate']
59 #8、关联达人
60 peopleCnt = data['peopleCnt']
61 #9、关联直播
62 roomCnt = data['roomCnt']
63 #10、关联视频
64 videoCnt = data['videoCnt']
65 #11、售价
66 sellPrice = data['sellPrice']
67 #12、品牌名
68 brandName = data['brandName']
69 #13、商品logo
70 shopLogo = data['shopLogo']
71 #14、店铺
72 shopName = data['shopName']
73 #15、商品评分
74 shopScore = data['shopScore']
75 print(goodsid,goodName,cosRate,adSaleCnt,orderCnt,videoSaleCnt,thirtyInversionRate,peopleCnt,roomCnt,videoCnt,sellPrice,brandName,shopLogo,shopName,shopScore)
76 data = {
77 '电商数据': [goodsid,goodName,cosRate,adSaleCnt,orderCnt,videoSaleCnt,thirtyInversionRate,peopleCnt,roomCnt,videoCnt,sellPrice,brandName,shopLogo,shopName,shopScore]
78 }
79 self.save_data(data)
80
81 #储存数据在excel
82 def save_data(self, data):
83 if not os.path.exists('电商数据.xls'):
84 # 1、创建 Excel 文件
85 wb = xlwt.Workbook(encoding='utf-8')
86 # 2、创建新的 Sheet 表
87 sheet = wb.add_sheet('电商数据', cell_overwrite_ok=True)
88 # 3、设置 Borders边框样式
89 borders = xlwt.Borders()
90 borders.left = xlwt.Borders.THIN
91 borders.right = xlwt.Borders.THIN
92 borders.top = xlwt.Borders.THIN
93 borders.bottom = xlwt.Borders.THIN
94 borders.left_colour = 0x40
95 borders.right_colour = 0x40
96 borders.top_colour = 0x40
97 borders.bottom_colour = 0x40
98 style = xlwt.XFStyle() # Create Style
99 style.borders = borders # Add Borders to Style
100 # 4、写入时居中设置
101 align = xlwt.Alignment()
102 align.horz = 0x02 # 水平居中
103 align.vert = 0x01 # 垂直居中
104 style.alignment = align
105 # 5、设置表头信息, 遍历写入数据, 保存数据
106 header = ('商品ID','商品','佣金比例', '30日销量', '直播销量', '视频销量','转化率','关联达人','关联直播','关联视频','售价',
107 '品牌名','商品lojo','店铺','商品评分')
108 for i in range(0, len(header)):
109 sheet.col(i).width = 2560 * 3
110 # 行,列, 内容, 样式
111 sheet.write(0, i, header[i], style)
112 wb.save('电商数据.xls')
113 # 判断工作表是否存在
114 if os.path.exists('电商数据.xls'):
115 # 打开工作薄
116 wb = xlrd.open_workbook('电商数据.xls')
117 # 获取工作薄中所有表的个数
118 sheets = wb.sheet_names()
119 for i in range(len(sheets)):
120 for name in data.keys():
121 worksheet = wb.sheet_by_name(sheets[i])
122 # 获取工作薄中所有表中的表名与数据名对比
123 if worksheet.name == name:
124 # 获取表中已存在的行数
125 rows_old = worksheet.nrows
126 # 将xlrd对象拷贝转化为xlwt对象
127 new_workbook = copy(wb)
128 # 获取转化后的工作薄中的第i张表
129 new_worksheet = new_workbook.get_sheet(i)
130 for num in range(0, len(data[name])):
131 new_worksheet.write(rows_old, num, data[name][num])
132 new_workbook.save('电商数据.xls')
133
134
135
136 if __name__ == '__main__':
137 d=DouYinShop()
138 d.spider()
139
140
141 import pandas as pd
142 # 读取excel文件
143 df = pd.read_excel('电商数据.xls')
144 # 输出清洗前信息
145 print(df.info())
146 # 将商品ID改为字符型
147 df["商品ID"] = df["商品ID"].astype("str")
148 # 删除重复值
149 df.drop_duplicates(inplace=True)
150 # 填充品牌名缺失值
151 df["品牌名"].fillna("未知品牌", inplace=True)
152 # 输出清洗后信息
153 print(df.info())
154
155
156 import pandas as pd
157 from pyecharts.charts import Line, Bar
158 from pyecharts import options as opts
159
160 # 读取Excel文件
161 df = pd.read_excel('电商数据.xls')
162
163 # 提取数据
164 brands = df['品牌名'].tolist()
165 prices = df['售价'].tolist()
166 daren = df['关联达人'].tolist()
167 # 创建折线图
168 line_chart = Line()
169 line_chart.add_xaxis(brands)
170 line_chart.add_yaxis("关联达人", daren)
171 line_chart.set_global_opts(
172 title_opts=opts.TitleOpts(title="品牌关联达人折线图"),
173 toolbox_opts=opts.ToolboxOpts(),
174 tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
175 yaxis_opts=opts.AxisOpts(name="品牌关联达人折线图"),
176 xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=0)),
177 datazoom_opts=[
178 opts.DataZoomOpts(type_="slider", is_show=True),
179 opts.DataZoomOpts(type_="inside", is_show=True),
180 ],
181
182 )
183
184 # 渲染图表到HTML文件
185 line_chart.render('折线关联达人可视化.html')
186
187
188
189 import pandas as pd
190 from pyecharts.charts import Line, Bar
191 from pyecharts import options as opts
192
193 # 读取Excel文件
194 df = pd.read_excel('电商数据.xls')
195
196 # 提取数据
197 brands = df['品牌名'].tolist()
198 prices = df['售价'].tolist()
199 daren = df['关联达人'].tolist()
200
201 # 创建柱状图
202 bar_chart = Bar()
203 bar_chart.add_xaxis(brands)
204 bar_chart.add_yaxis("价格", prices)
205 bar_chart.set_global_opts(
206 title_opts=opts.TitleOpts(title="品牌售价柱状图"),
207 toolbox_opts=opts.ToolboxOpts(),
208 tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
209 yaxis_opts=opts.AxisOpts(name="品牌售价柱状图"),
210 xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=0)),
211 datazoom_opts=[
212 opts.DataZoomOpts(type_="slider", is_show=True),
213 opts.DataZoomOpts(type_="inside", is_show=True),
214 ],
215 )
216
217 # 渲染图表到HTML文件
218 bar_chart.render('品牌售价柱状图可视化.html')
219
220
221 from pyecharts.charts import WordCloud
222 from pyecharts import options as opts
223 from pyecharts.globals import SymbolType
224 import jieba
225 import pandas as pd
226 from collections import Counter
227
228 # 读取Excel文件
229 df = pd.read_excel('电商数据.xls')
230 # 提取商品名
231 goods_name = df["商品"].tolist()
232 # 提取关键字
233 seg_list = [jieba.lcut(text) for text in goods_name]
234 words = [word for seg in seg_list for word in seg if len(word) > 1]
235 word_counts = Counter(words)
236 word_cloud_data = [(word, count) for word, count in word_counts.items()]
237
238 # 创建词云图
239 wordcloud = (
240 WordCloud(init_opts=opts.InitOpts(bg_color='#00FFFF'))
241 .add("", word_cloud_data, word_size_range=[20, 100], shape=SymbolType.DIAMOND,
242 word_gap=5, rotate_step=45,
243 textstyle_opts=opts.TextStyleOpts(font_family='cursive', font_size=15))
244 .set_global_opts(title_opts=opts.TitleOpts(title="商品名词云图",pos_top="5%", pos_left="center"),
245 toolbox_opts=opts.ToolboxOpts(
246 is_show=True,
247 feature={
248 "saveAsImage": {},
249 "dataView": {},
250 "restore": {},
251 "refresh": {}
252 }
253 )
254
255 )
256 )
257
258 # 渲染词图到HTML文件
259 wordcloud.render("商品名词云图.html")
260
261
262
263 import pandas as pd
264 from pyecharts import options as opts
265 from pyecharts.charts import Scatter, Line
266 from pyecharts.globals import ThemeType
267 from scipy import stats
268
269 # 读取excel文件
270 df = pd.read_excel("电商数据.xls")
271 # 重新排序
272 df.sort_values(by='关联直播', inplace=True)
273 # 处理直播销量数据
274 def filter_sales_pz(sales):
275 acount = sales.split("~")
276 res = list()
277 for i in acount:
278 if i.find("w") != -1:
279 i = float(i.replace("w", "")) * 10000
280 res.append(int(i))
281 return res
282
283 def filter_sales(sales):
284 acount = filter_sales_pz(sales)
285 num = acount[0]
286 if len(acount) > 1:
287 num = acount[0] + ((acount[1] - acount[0]) // 2)
288 return num
289
290
291 live_count = df["关联直播"].tolist()
292 live_sales = df["直播销量"].apply(lambda x: filter_sales(x)).tolist()
293
294 # 初始化散点图
295 scatter = Scatter()
296 scatter.add_xaxis(live_count)
297 scatter.add_yaxis("直播销量",live_sales)
298 scatter.set_global_opts(title_opts=opts.TitleOpts(title="直播销量与关联直播关系",pos_top="5%", pos_left="center"),
299 toolbox_opts=opts.ToolboxOpts(
300 is_show=True,
301 feature={
302 "saveAsImage": {},
303 "dataView": {},
304 "restore": {},
305 "refresh": {}
306 }
307 )
308 )
309 # 渲染图表到HTML文件
310 scatter.render("直播销量和关联直播的关系.html")
七、总结
-
用户行为分析:通过大数据分析,可以深入了解用户在达多多和抖音电商平台上的行为,包括浏览商品、加入购物车、下单购买等行为。通过分析用户行为数据,可以发现用户的偏好和购买习惯,为电商平台和品牌商提供精准的营销策略和产品推荐。
-
商品销售分析:通过大数据分析,可以对达多多和抖音电商平台上的商品销售数据进行分析,包括热门商品、销售趋势、价格分布等。通过分析商品销售数据,可以帮助品牌商了解市场需求,优化产品组合和定价策略。
-
用户画像分析:通过大数据分析,可以对达多多和抖音电商平台的用户进行画像分析,包括性别、年龄、地域分布、消费能力等。通过用户画像分析,可以为品牌商提供更精准的目标用户定位和营销策略。
-
营销效果分析:通过大数据分析,可以对达多多和抖音电商平台上的营销活动进行效果分析,包括促销活动、广告投放等。通过分析营销活动的效果,可以评估营销策略的有效性,为品牌商提供营销决策的参考。
-
用户留存和流失分析:通过大数据分析,可以对达多多和抖音电商平台上的用户留存和流失情况进行分析,了解用户的活跃度和忠诚度。通过分析用户留存和流失数据,可以为电商平台和品牌商提供用户留存策略和用户回流策略。
技术总结:通过这门课程的学习,我掌握了数据爬取和大数据分析的基本技能,为未来从事相关领域的工作做好准备。同时,也能够了解数据爬取和分析过程中的伦理和法律规范,培养良好的职业道德和法律意识。