以下主要是记录自己看曹大的《Go语言高级编程》一书,记录下自己的学习记录以及自己的理解,仅做记录使用。
1、语言基础
1.3 数组、字符串和切片
1.3.1 数组
var c = [...]int{2: 3, 1: 2} // 定义长度为 3 的 int 型数组, 元素为 0, 2, 3
var d = [...]int{1, 2, 4: 5, 6} // 定义长度为 6 的 int 型数组, 元素为 1, 2, 0, 0, 5, 6
第三种方式是以索引的方式来初始化数组的元素,因此元素的初始化值出现顺序比较随意。这种初始化方式和 map[int]Type 类型的初始化语法类似。数组的长度以出现的最大的索引为准,没有明确初始化的元素依然用零值初始化。
实际开发中用到比较少,不注意一开始还有点蒙呢
1.3.2 字符串
Go 语言的字符串中可以存放任意的二进制字节序列,而且即使是 UTF8 字符序列也可能会遇到坏的编码。如果遇到一个错误的 UTF8 编码输入,将生成一个特别的 Unicode 字符‘\uFFFD’,这个字符在不同的软件中的显示效果可能不太一样,在印刷中这个符号通常是一个黑色六角形或钻石形状,里面包含一个白色的问号‘�’。
下面的字符串中,我们故意损坏了第一字符的第二和第三字节,因此第一字符将会打印为“�”,第二和第三字节则被忽略,后面的“abc”依然可以正常解码打印(错误编码不会向后扩散是 UTF8 编码的优秀特性之一)。
fmt.Println("\xe4\x00\x00\xe7\x95\x8cabc") // �界abc
1.3.3 切片(slice)
避免切片内存泄漏
在删除切片元素时可能会遇到。假设切片里存放的是指针对象,那么下面删除末尾的元素后,被删除的元素依然被切片底层数组引用,从而导致不能及时被自动垃圾回收器回收(这要依赖回收器的实现方式):
var a []*int{ ... }
a = a[:len(a)-1] // 被删除的最后一个元素依然被引用, 可能导致 GC 操作被阻碍
保险的方式是先将需要自动内存回收的元素设置为 nil,保证自动回收器可以发现需要回收的对象,然后再进行切片的删除操作:
var a []*int{ ... }
a[len(a)-1] = nil // GC 回收最后一个元素内存
a = a[:len(a)-1] // 从切片删除最后一个元素
当然,如果切片存在的周期很短的话,可以不用刻意处理这个问题。因为如果切片本身已经可以被 GC 回收的话,切片对应的每个元素自然也就是可以被回收的了。
1.4 函数、方法和接口
在 main.main 函数执行之前所有代码都运行在同一个 Goroutine 中,也是运行在程序的主系统线程中。如果某个 init 函数内部用 go 关键字启动了新的 Goroutine 的话,新的 Goroutine 和 main.main 函数是并发执行的。
1.4.1 函数
defer 语句延迟执行了一个匿名函数,因为这个匿名函数捕获了外部函数的局部变量 v,这种函数我们一般叫闭包。闭包对捕获的外部变量并不是传值方式访问,而是以引用的方式访问。
Go 语言中,如果以切片为参数调用函数时,有时候会给人一种参数采用了传引用的方式的假象:因为在被调用函数内部可以修改传入的切片的元素。其实,任何可以通过函数参数修改调用参数的情形,都是因为函数参数中显式或隐式传入了指针参数。函数参数传值的规范更准确说是只针对数据结构中固定的部分传值,例如字符串或切片对应结构体中的指针和字符串长度结构体传值,但是并不包含指针间接指向的内容。将切片类型的参数替换为类似 reflect.SliceHeader 结构体就很好理解切片传值的含义了.
1.4.2 方法
在传统的面向对象语言(eg.C++ 或 Java)的继承中,子类的方法是在运行时动态绑定到对象的,因此基类实现的某些方法看到的 this 可能不是基类类型对应的对象,这个特性会导致基类方法运行的不确定性。而在 Go 语言通过嵌入匿名的成员来“继承”的基类方法,this 就是实现该方法的类型的对象,Go 语言中方法是编译时静态绑定的。如果需要虚函数的多态特性,我们需要借助 Go 语言接口来实现。
1.4.3 接口
Go 的接口类型是对其它类型行为的抽象和概括;因为接口类型不会和特定的实现细节绑定在一起,通过这种抽象的方式我们可以让对象更加灵活和更具有适应能力。很多面向对象的语言都有相似的接口概念,但 Go 语言中接口类型的独特之处在于它是满足隐式实现的鸭子类型。所谓鸭子类型说的是:只要走起路来像鸭子、叫起来也像鸭子,那么就可以把它当作鸭子。Go 语言中的面向对象就是如此,如果一个对象只要看起来像是某种接口类型的实现,那么它就可以作为该接口类型使用。这种设计可以让你创建一个新的接口类型满足已经存在的具体类型却不用去破坏这些类型原有的定义;当我们使用的类型来自于不受我们控制的包时这种设计尤其灵活有用。Go 语言的接口类型是延迟绑定,可以实现类似虚函数的多态功能。
Go 语言中,对于基础类型(非接口类型)不支持隐式的转换,我们无法将一个 int 类型的值直接赋值给 int64 类型的变量,也无法将 int 类型的值赋值给底层是 int 类型的新定义命名类型的变量。Go 语言对基础类型的类型一致性要求可谓是非常的严格,但是 Go 语言对于接口类型的转换则非常的灵活。对象和接口之间的转换、接口和接口之间的转换都可能是隐式的转换。可以看下面的例子:
var (
a io.ReadCloser = (*os.File)(f) // 隐式转换, *os.File 满足 io.ReadCloser 接口
b io.Reader = a // 隐式转换, io.ReadCloser 满足 io.Reader 接口
c io.Closer = a // 隐式转换, io.ReadCloser 满足 io.Closer 接口
d io.Reader = c.(io.Reader) // 显式转换, io.Closer 不满足 io.Reader 接口
)
有时候对象和接口之间太灵活了,导致我们需要人为地限制这种无意之间的适配。常见的做法是定义一个含特殊方法来区分接口。比如 runtime 包中的 Error 接口就定义了一个特有的 RuntimeError 方法,用于避免其它类型无意中适配了该接口:
type runtime.Error interface {
error
// RuntimeError is a no-op function but
// serves to distinguish types that are run time
// errors from ordinary errors: a type is a
// run time error if it has a RuntimeError method.
RuntimeError()
}
在 protobuf 中,Message 接口也采用了类似的方法,也定义了一个特有的 ProtoMessage,用于避免其它类型无意中适配了该接口:
type proto.Message interface {
Reset()
String() string
ProtoMessage()
}
不过这种做法只是君子协定,如果有人刻意伪造一个 proto.Message 接口也是很容易的。再严格一点的做法是给接口定义一个私有方法。只有满足了这个私有方法的对象才可能满足这个接口,而私有方法的名字是包含包的绝对路径名的,因此只能在包内部实现这个私有方法才能满足这个接口。测试包中的 testing.TB 接口就是采用类似的技术:
type testing.TB interface {
Error(args ...interface{})
Errorf(format string, args ...interface{})
...
// A private method to prevent users implementing the
// interface and so future additions to it will not
// violate Go 1 compatibility.
private()
}
不过这种通过私有方法禁止外部对象实现接口的做法也是有代价的:首先是这个接口只能包内部使用,外部包正常情况下是无法直接创建满足该接口对象的;其次,这种防护措施也不是绝对的,恶意的用户依然可以绕过这种保护机制。
可以通过匿名嵌套接口来避开这种限制,因为接口是在运行时绑定的,编译期间并不会做检查。
具体可以看看这个章节的原文: 1.4.3 接口
1.5 面向并发的内存模型
常见的并行编程有多种模型,主要有多线程、消息传递等。从理论上来看,多线程和基于消息的并发编程是等价的。由于多线程并发模型可以自然对应到多核的处理器,主流的操作系统因此也都提供了系统级的多线程支持,同时从概念上讲多线程似乎也更直观,因此多线程编程模型逐步被吸纳到主流的编程语言特性或语言扩展库中。而主流编程语言对基于消息的并发编程模型支持则相比较少,Erlang 语言是支持基于消息传递并发编程模型的代表者,它的并发体之间不共享内存。Go 语言是基于消息并发模型的集大成者,它将基于 CSP 模型的并发编程内置到了语言中,通过一个 go 关键字就可以轻易地启动一个 Goroutine,与 Erlang 不同的是 Go 语言的 Goroutine 之间是共享内存的。
1.5.1 Goroutine和系统线程
每个系统级线程都会有一个固定大小的栈(一般默认可能是 2MB),这个栈主要用来保存函数递归调用时参数和局部变量。固定了栈的大小导致了两个问题:一是对于很多只需要很小的栈空间的线程来说是一个巨大的浪费,二是对于少数需要巨大栈空间的线程来说又面临栈溢出的风险。针对这两个问题的解决方案是:要么降低固定的栈大小,提升空间的利用率;要么增大栈的大小以允许更深的函数递归调用,但这两者是没法同时兼得的。相反,一个 Goroutine 会以一个很小的栈启动(可能是 2KB 或 4KB),当遇到深度递归导致当前栈空间不足时,Goroutine 会根据需要动态地伸缩栈的大小(主流实现中栈的最大值可达到1GB)。
Go 调度器的工作和内核的调度是相似的,但是这个调度器只关注单独的 Go 程序中的 Goroutine。Goroutine 采用的是半抢占式的协作调度,只有在当前 Goroutine 发生阻塞时才会导致调度;同时发生在用户态,调度器会根据具体函数只保存必要的寄存器,切换的代价要比系统线程低得多。运行时有一个 runtime.GOMAXPROCS 变量,用于控制当前运行正常非阻塞 Goroutine 的系统线程数目。
1.5.2 原子操作
一般情况下,原子操作都是通过“互斥”访问来保证的,通常由特殊的 CPU 指令提供保护。
单体原子方式:1、sync.Mutex 2、atomic包提供的方法。
sync/atomic 包对基本的数值类型及复杂对象的读写都提供了原子操作的支持。atomic.Value 原子对象提供了 Load 和 Store 两个原子方法,分别用于加载和保存数据,返回值和参数都是 interface{} 类型,因此可以用于任意的自定义复杂类型。
1.5.3 顺序一致性内存模型
确实存在在一个Goroutine中看不到另一个Goroutine的写入操作的情况。这是因为编译器和CPU的优化可能导致某些写入操作在其他Goroutines中看不到。
这里不太懂
解决方法:通过同步原语来给两个事件明确排序。比如 chan、sync.Mutex.
用前面的原子操作并不能解决问题,因为我们无法确定两个原子操作之间的顺序。(atomic包)
1.5.4 初始化顺序
因为所有的 init 函数和 main 函数都是在主线程完成,它们也是满足顺序一致性模型的。
1.5.5 Goroutine的创建
go 语句会在当前 Goroutine 对应函数返回前创建新的 Goroutine。
1.5.6 基于 Channel 的通信
无缓存的 Channel 上的发送操作总在对应的接收操作完成前发生.
对于带缓冲的Channel,对于 Channel 的第 K 个接收完成操作发生在第 K+C 个发送操作完成之前,其中 C 是 Channel 的缓存大小。 如果将 C 设置为 0 自然就对应无缓存的 Channel,也即使第 K 个接收完成在第 K 个发送完成之前。因为无缓存的 Channel 只能同步发 1 个,也就简化为前面无缓存 Channel 的规则:对于从无缓冲 Channel 进行的接收,发生在对该 Channel 进行的发送完成之前。
有点绕,总的含义是 chan 塞满后的发送操作,是发生在接受到这个数据之前的。
1.5.7 不靠谱的同步
严谨的并发程序的正确性不应该是依赖于 CPU 的执行速度和休眠时间等不靠谱的因素的。严谨的并发也应该是可以静态推导出结果的:根据线程内顺序一致性,结合 Channel 或 sync 同步事件的可排序性来推导,最终完成各个线程各段代码的偏序关系排序。如果两个事件无法根据此规则来排序,那么它们就是并发的,也就是执行先后顺序不可靠的。
解决同步问题的思路是相同的:使用显式的同步。
写代码的严谨性,继续努力。
1.6 常见的并发模式
对不同状态下的通道执行相应操作的结果。
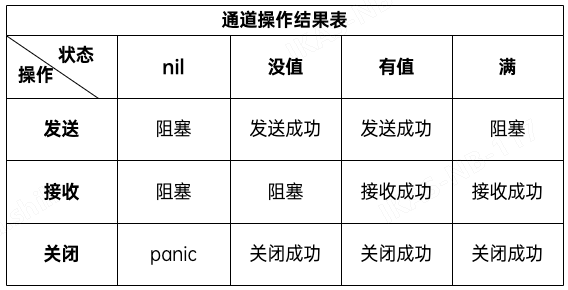
注意:对已经关闭的通道再执行 close 也会引发 panic。
1.6.6 素数筛 的代码中存在 goroutine 泄漏的风险,原因是:在 primeFilter 函数中,启动的goroutine没有退出条件,是一个死循环,存在 main 函数中的循环停止时,启动的 goroutine 也不会结束。解决办法是增加退出条件,比如使用 chan、context 来退出。
方式一:
func primeFilter(prime int, ch chan int, done chan struct{}) chan int {
out := make(chan int)
go func() {
// 不是必须关掉 out 这个chan,但是最好关掉,这样可以通知接受这个chan的goroutine可以知道此chan已经关闭掉了
defer close(out)
for {
select {
case i := <-ch:
if i%prime != 0 {
out <- i
}
case <-done:
return
}
}
}()
return out
}
1.6.8 context 包 案例中,说到了添加context后,会形成死锁,死锁形成的原因是: primeFilter 函数中的 返回参数 out chan 是一个无缓存的chan,当没有其他goroutine 时读取这个chan时,则会导致 if i := <-in; i%prime != 0 中的 <-in 一直阻塞,那这个时候,下面的 select 监听是无法执行到的,也就是说当前 goroutine 不能正常退出,可能发生死锁。 使用 sync.WaitGroup 可以复现,具体看原文。
比如循环到第99次时,primeFilter 等待 in chan 中数据来源,但是main函数中,已经执行了 cancel(),这个时候第98次循环产生的goroutine退出,out chan 则不会在有数据写入,那 99次的 in chan 也就不会再读取到值了,所以判断不会成立,从而形成了死锁。
解决办法:1、将 primeFilter 中的select移到 if 判断之外。 2、使用 close 函数关闭 out chan(和上面的注释对应上了)。