- 连接数据库
# 代码11-1 import os import pandas as pd # 修改工作路径到指定文件夹 os.chdir("D:/人工智能&软件工程/数据挖掘与分析/tmp") # 第一种连接方式 from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:mmwan0825@127.0.0.1:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) # 第二种连接方式 import pymysql as pm con = pm.connect(host='127.0.0.1', user='root', password='mmwan0825', db='test', port=3306) data = pd.read_sql('select * from all_gzdata',con=con) con.close() #关闭连接 # 保存读取的数据 data.to_csv('D:/人工智能&软件工程/数据挖掘与分析/tmp/all_gzdata学号:3041.csv', index=False, encoding='utf-8')
- 分析网页类型
# 代码11-2 import pandas as pd from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:mmwan0825@127.0.0.1:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) # 分析网页类型 counts = [i['fullURLId'].value_counts() for i in sql] #逐块统计 counts = counts.copy() counts = pd.concat(counts).groupby(level=0).sum() # 合并统计结果,把相同的统计项合并(即按index分组并求和) counts = counts.reset_index() # 重新设置index,将原来的index作为counts的一列。 counts.columns = ['index', 'num'] # 重新设置列名,主要是第二列,默认为0 counts['type'] = counts['index'].str.extract('(\d{3})') # 提取前三个数字作为类别id counts_ = counts[['type', 'num']].groupby('type').sum() # 按类别合并 counts_.sort_values(by='num', ascending=False, inplace=True) # 降序排列 counts_['ratio'] = counts_.iloc[:,0] / counts_.iloc[:,0].sum() print("学号:3041") print(counts_)
学号:3041 num ratio type 101 39767 0.471995 199 20233 0.240146 107 19717 0.234021 102 2057 0.024415 301 1636 0.019418 106 577 0.006848 103 266 0.003157 - 分类,计算各个部分的占比
# 代码11-3 # 因为只有107001一类,但是可以继续细分成三类:知识内容页、知识列表页、知识首页 def count107(i): #自定义统计函数 j = i[['fullURL']][i['fullURLId'].str.contains('107')].copy() # 找出类别包含107的网址 j['type'] = None # 添加空列 j['type'][j['fullURL'].str.contains('info/.+?/')]= '知识首页' j['type'][j['fullURL'].str.contains('info/.+?/.+?')]= '知识列表页' j['type'][j['fullURL'].str.contains('/\d+?_*\d+?\.html')]= '知识内容页' return j['type'].value_counts() # 注意:获取一次sql对象就需要重新访问一下数据库(!!!) #engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) counts2 = [count107(i) for i in sql] # 逐块统计 counts2 = pd.concat(counts2).groupby(level=0).sum() # 合并统计结果 print(counts2) #计算各个部分的占比 res107 = pd.DataFrame(counts2) # res107.reset_index(inplace=True) res107.index.name= '107类型' res107.rename(columns={'type':'num'}, inplace=True) res107['比例'] = res107['num'] / res107['num'].sum() res107.reset_index(inplace = True) print("学号:3041") print(res107)
知识内容页 18096 知识列表页 949 知识首页 672 Name: type, dtype: int64 学号:3041 107类型 num 比例 0 知识内容页 18096 0.917787 1 知识列表页 949 0.048131 2 知识首页 672 0.034082
- 求各个类型的占比并保存数据
# 代码11-4 def countquestion(i): # 自定义统计函数 j = i[['fullURLId']][i['fullURL'].str.contains('\?')].copy() # 找出类别包含107的网址 return j #engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) counts3 = [countquestion(i)['fullURLId'].value_counts() for i in sql] counts3 = pd.concat(counts3).groupby(level=0).sum() print(counts3) # 求各个类型的占比并保存数据 df1 = pd.DataFrame(counts3) df1['perc'] = df1['fullURLId']/df1['fullURLId'].sum()*100 df1.sort_values(by='fullURLId',ascending=False,inplace=True) print("学号:3041") print(df1.round(4))
101003 9 107001 52 1999001 6064 301001 27 Name: fullURLId, dtype: int64 学号:3041 fullURLId perc 1999001 6064 98.5696 107001 52 0.8453 301001 27 0.4389 101003 9 0.1463 - 求各个部分的占比并保存数据
# 代码11-5 def page199(i): #自定义统计函数 j = i[['fullURL','pageTitle']][(i['fullURLId'].str.contains('199')) & (i['fullURL'].str.contains('\?'))] j['pageTitle'].fillna('空',inplace=True) j['type'] = '其他' # 添加空列 j['type'][j['pageTitle'].str.contains('法律快车-律师助手')]= '法律快车-律师助手' j['type'][j['pageTitle'].str.contains('咨询发布成功')]= '咨询发布成功' j['type'][j['pageTitle'].str.contains('免费发布法律咨询' )] = '免费发布法律咨询' j['type'][j['pageTitle'].str.contains('法律快搜')] = '快搜' j['type'][j['pageTitle'].str.contains('法律快车法律经验')] = '法律快车法律经验' j['type'][j['pageTitle'].str.contains('法律快车法律咨询')] = '法律快车法律咨询' j['type'][(j['pageTitle'].str.contains('_法律快车')) | (j['pageTitle'].str.contains('-法律快车'))] = '法律快车' j['type'][j['pageTitle'].str.contains('空')] = '空' return j # 注意:获取一次sql对象就需要重新访问一下数据库 #engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)# 分块读取数据库信息 #sql = pd.read_sql_query('select * from all_gzdata limit 10000', con=engine) counts4 = [page199(i) for i in sql] # 逐块统计 counts4 = pd.concat(counts4) d1 = counts4['type'].value_counts() print(d1) d2 = counts4[counts4['type']=='其他'] print(d2) # 求各个部分的占比并保存数据 df1_ = pd.DataFrame(d1) df1_['perc'] = df1_['type']/df1_['type'].sum()*100 df1_.sort_values(by='type',ascending=False,inplace=True) print("学号:3041") print(df1_)
法律快车-律师助手 4463 法律快车法律咨询 756 咨询发布成功 507 快搜 168 法律快车 148 其他 19 法律快车法律经验 3 Name: type, dtype: int64 fullURL \ 1448 http://www.lawtime.cn/spelawyer/index.php?py=g... 1449 http://www.lawtime.cn/spelawyer/index.php?py=g... 6210 http://m.baidu.com/from=0/bd_page_type=1/ssid=... 1397 http://www.lawtime.cn/lawyer/lll25879862593080... 7515 http://m.baidu.com/from=844b/bd_page_type=1/ss... 5716 http://www.lawtime.cn/ask/exp/taglist.html?key... 7431 http://www.lawtime.cn/ask/exp/taglist.html?key... 8584 http://m.sogou.com/web/uID=Ez0EHKP0A-tosu9r/v=... 8586 http://m.sogou.com/web/uID=Ez0EHKP0A-tosu9r/v=... 8699 http://www.youdao.com/cache?q=%E5%8A%9E%E5%85%... 9081 http://m.baidu.com/from=0/bd_page_type=1/ssid=... 7799 http://www.lawtime.cn/ask/exp/taglist.html?key... 7803 http://www.lawtime.cn/ask/exp/taglist.html?key... 7879 http://www.lawtime.cn/ask/exp/taglist.html?key... 2086 http://www.lawtime.cn/ask/exp/taglist.html?key... 1469 http://www.lawtime.cn/newlawyer/index.php?m=in... 1490 http://www.lawtime.cn/newlawyer/index.php?m=in... 1525 http://www.lawtime.cn/newlawyer/index.php?m=index 1556 http://www.lawtime.cn/newlawyer/index.php?m=index pageTitle type 1448 个旧律师成功案例 - 法律快车提供个旧知名律师、优秀律师、专业律师的咨询和推荐 其他 1449 个旧律师成功案例 - 法律快车提供个旧知名律师、优秀律师、专业律师的咨询和推荐 其他 6210 什么是机动车?什么是非机动车? - 法律快车交通事故 其他 1397 404错误提示页面 - 法律快车 其他 7515 婚姻法禁止哪些妨害婚姻自由行为 - 法律快车婚姻法 其他 5716 法律经验标签列表页 - 法律经验 其他 7431 法律经验标签列表页 - 法律经验 其他 8584 汕尾律师事务所--找汕尾知名律师事务所电话、地址查询与法律咨询服务 其他 8586 汕尾律师事务所--找汕尾知名律师事务所电话、地址查询与法律咨询服务 其他 8699 办公设备租用合同 - 法律快车工程纠纷 其他 9081 离婚财产分割 - 法律快车婚姻法 其他 7799 法律经验标签列表页 - 法律经验 其他 7803 法律经验标签列表页 - 法律经验 其他 7879 法律经验标签列表页 - 法律经验 其他 2086 法律经验标签列表页 - 法律经验 其他 1469 404错误提示页面 - 法律快车 其他 1490 404错误提示页面 - 法律快车 其他 1525 404错误提示页面 - 法律快车 其他 1556 404错误提示页面 - 法律快车 其他 学号:3041 type perc 法律快车-律师助手 4463 73.598285 法律快车法律咨询 756 12.467018 咨询发布成功 507 8.360818 快搜 168 2.770449 法律快车 148 2.440633 其他 19 0.313325 法律快车法律经验 3 0.049472 - 求各个部分的占比
# 代码11-6 def xiaguang(i): #自定义统计函数 j = i.loc[(i['fullURL'].str.contains('\.html'))==False, ['fullURL','fullURLId','pageTitle']] return j # 注意获取一次sql对象就需要重新访问一下数据库 engine = create_engine('mysql+pymysql://root:mmwan0825@127.0.0.1:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)# 分块读取数据库信息 counts5 = [xiaguang(i) for i in sql] counts5 = pd.concat(counts5) xg1 = counts5['fullURLId'].value_counts() print(xg1) # 求各个部分的占比 xg_ = pd.DataFrame(xg1) xg_.reset_index(inplace=True) xg_.columns= ['index', 'num'] xg_['perc'] = xg_['num']/xg_['num'].sum()*100 xg_.sort_values(by='num',ascending=False,inplace=True) xg_['type'] = xg_['index'].str.extract('(\d{3})') #提取前三个数字作为类别id xgs_ = xg_[['type', 'num']].groupby('type').sum() #按类别合并 xgs_.sort_values(by='num', ascending=False,inplace=True) #降序排列 xgs_['percentage'] = xgs_['num']/xgs_['num'].sum()*100 print("学号:3041") print(xgs_.round(4))
1999001 11180 102002 1635 107001 1559 106001 577 101001 516 102001 171 102003 109 301001 86 101009 82 102005 35 101008 27 102007 26 102009 24 102008 24 102004 24 101004 12 101006 11 102006 9 101005 1 Name: fullURLId, dtype: int64 学号:3041 num percentage type 199 11180 69.4065 102 2057 12.7701 107 1559 9.6784 101 649 4.0291 106 577 3.5821 301 86 0.5339 - 分析网页点击次数
# 代码11-7 # 分析网页点击次数 # 统计点击次数 engine = create_engine('mysql+pymysql://root:mmwan0825@127.0.0.1:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)# 分块读取数据库信息 counts1 = [i['realIP'].value_counts() for i in sql] # 分块统计各个IP的出现次数 counts1 = pd.concat(counts1).groupby(level=0).sum() # 合并统计结果,level=0表示按照index分组 print(counts1) counts1_ = pd.DataFrame(counts1) counts1_ counts1['realIP'] = counts1.index.tolist() counts1_[1]=1 # 添加1列全为1 hit_count = counts1_.groupby('realIP').sum() # 统计各个“不同点击次数”分别出现的次数 # 也可以使用counts1_['realIP'].value_counts()功能 hit_count.columns=['用户数'] hit_count.index.name = '点击次数' # 统计1~7次、7次以上的用户人数 hit_count.sort_index(inplace = True) hit_count_7 = hit_count.iloc[:7,:] time = hit_count.iloc[7:,0].sum() # 统计点击次数7次以上的用户数 hit_count_7 = hit_count_7.append([{'用户数':time}], ignore_index=True) hit_count_7.index = ['1','2','3','4','5','6','7','7次以上'] hit_count_7['用户比例'] = hit_count_7['用户数'] / hit_count_7['用户数'].sum() print("学号:3041") print(hit_count_7)
226318 2 270457 1 503676 1 857460 1 954894 3 .. 4293465716 2 4293497102 1 4293738865 1 4294510713 2 4294721082 1 Name: realIP, Length: 30923, dtype: int64 学号:3041 用户数 用户比例 1 19616 0.634350 2 5540 0.179155 3 2082 0.067329 4 1084 0.035055 5 652 0.021085 6 442 0.014294 7 251 0.008117 7次以上 1256 0.040617 - 分析浏览一次的用户行为
# 代码11-8 # 分析浏览一次的用户行为 #engine = create_engine('mysql+pymysql://root:2262kwy@127.0.0.1:3306/test?charset=utf8') all_gzdata = pd.read_sql_table('all_gzdata', con = engine) # 读取all_gzdata数据 #对realIP进行统计 # 提取浏览1次网页的数据 real_count = pd.DataFrame(all_gzdata.groupby("realIP")["realIP"].count()) real_count.columns = ["count"] real_count["realIP"] = real_count.index.tolist() user_one = real_count[(real_count["count"] == 1)] # 提取只登录一次的用户 # 通过realIP与原始数据合并 real_one = pd.merge(user_one, all_gzdata, right_on = 'realIP',left_index=True,how ='left') # 统计浏览一次的网页类型 URL_count = pd.DataFrame(real_one.groupby("fullURLId")["fullURLId"].count()) URL_count.columns = ["count"] URL_count.sort_values(by='count', ascending=False, inplace=True) # 降序排列 # 统计排名前4和其他的网页类型 URL_count_4 = URL_count.iloc[:4,:] time = hit_count.iloc[4:,0].sum() # 统计其他的 URLindex = URL_count_4.index.values URL_count_4 = URL_count_4.append([{'count':time}], ignore_index=True) URL_count_4.index = [URLindex[0], URLindex[1], URLindex[2], URLindex[3], '其他'] URL_count_4['比例'] = URL_count_4['count'] / URL_count_4['count'].sum() print("学号:3041") print(URL_count_4)
学号:3041 count 比例 101003 14600 0.658221 107001 3279 0.147829 1999001 1614 0.072765 301001 87 0.003922 其他 2601 0.117263 - 在浏览1次的前提下, 得到的网页被浏览的总次数
# 代码11-9 # 在浏览1次的前提下, 得到的网页被浏览的总次数 fullURL_count = pd.DataFrame(real_one.groupby("fullURL")["fullURL"].count()) fullURL_count.columns = ["count"] fullURL_count["fullURL"] = fullURL_count.index.tolist() fullURL_count.sort_values(by='count', ascending=False, inplace=True) # 降序排列
- 其他相关处理
# 代码11-10 import os import re import pandas as pd import pymysql as pm from random import sample # 修改工作路径到指定文件夹 os.chdir("D:/人工智能&软件工程/数据挖掘与分析/tmp") # 读取数据 con = pm.connect(host='127.0.0.1', user='root', password='mmwan0825', db='test', port=3306) data = pd.read_sql('select * from all_gzdata',con=con) con.close() # 关闭连接 # 取出107类型数据 index107 = [re.search('107',str(i))!=None for i in data.loc[:,'fullURLId']] data_107 = data.loc[index107,:] # 在107类型中筛选出婚姻类数据 index = [re.search('hunyin',str(i))!=None for i in data_107.loc[:,'fullURL']] data_hunyin = data_107.loc[index,:] # 提取所需字段(realIP、fullURL) info = data_hunyin.loc[:,['realIP','fullURL']] # 去除网址中“?”及其后面内容 da = [re.sub('\?.*','',str(i)) for i in info.loc[:,'fullURL']] info.loc[:,'fullURL'] = da # 将info中‘fullURL’那列换成da # 去除无html网址 index = [re.search('\.html',str(i))!=None for i in info.loc[:,'fullURL']] index.count(True) # True 或者 1 , False 或者 0 info1 = info.loc[index,:] # 代码11-11 # 找出翻页和非翻页网址 index = [re.search('/\d+_\d+\.html',i)!=None for i in info1.loc[:,'fullURL']] index1 = [i==False for i in index] info1_1 = info1.loc[index,:] # 带翻页网址 info1_2 = info1.loc[index1,:] # 无翻页网址 # 将翻页网址还原 da = [re.sub('_\d+\.html','.html',str(i)) for i in info1_1.loc[:,'fullURL']] info1_1.loc[:,'fullURL'] = da # 翻页与非翻页网址合并 frames = [info1_1,info1_2] info2 = pd.concat(frames) # 或者 info2 = pd.concat([info1_1,info1_2],axis = 0) # 默认为0,即行合并 # 去重(realIP和fullURL两列相同) info3 = info2.drop_duplicates() # 将IP转换成字符型数据 info3.iloc[:,0] = [str(index) for index in info3.iloc[:,0]] info3.iloc[:,1] = [str(index) for index in info3.iloc[:,1]] len(info3) # 代码11-12 # 筛选满足一定浏览次数的IP IP_count = info3['realIP'].value_counts() # 找出IP集合 IP = list(IP_count.index) count = list(IP_count.values) # 统计每个IP的浏览次数,并存放进IP_count数据框中,第一列为IP,第二列为浏览次数 IP_count = pd.DataFrame({'IP':IP,'count':count}) # 3.3筛选出浏览网址在n次以上的IP集合 n = 2 index = IP_count.loc[:,'count']>n IP_index = IP_count.loc[index,'IP'] # 代码11-13 # 划分IP集合为训练集和测试集 index_tr = sample(range(0,len(IP_index)),int(len(IP_index)*0.8)) # 或者np.random.sample index_te = [i for i in range(0,len(IP_index)) if i not in index_tr] IP_tr = IP_index[index_tr] IP_te = IP_index[index_te] # 将对应数据集划分为训练集和测试集 index_tr = [i in list(IP_tr) for i in info3.loc[:,'realIP']] index_te = [i in list(IP_te) for i in info3.loc[:,'realIP']] data_tr = info3.loc[index_tr,:] data_te = info3.loc[index_te,:] print(len(data_tr)) IP_tr = data_tr.iloc[:,0] # 训练集IP url_tr = data_tr.iloc[:,1] # 训练集网址 IP_tr = list(set(IP_tr)) # 去重处理 url_tr = list(set(url_tr)) # 去重处理 len(url_tr)
- 模型训练
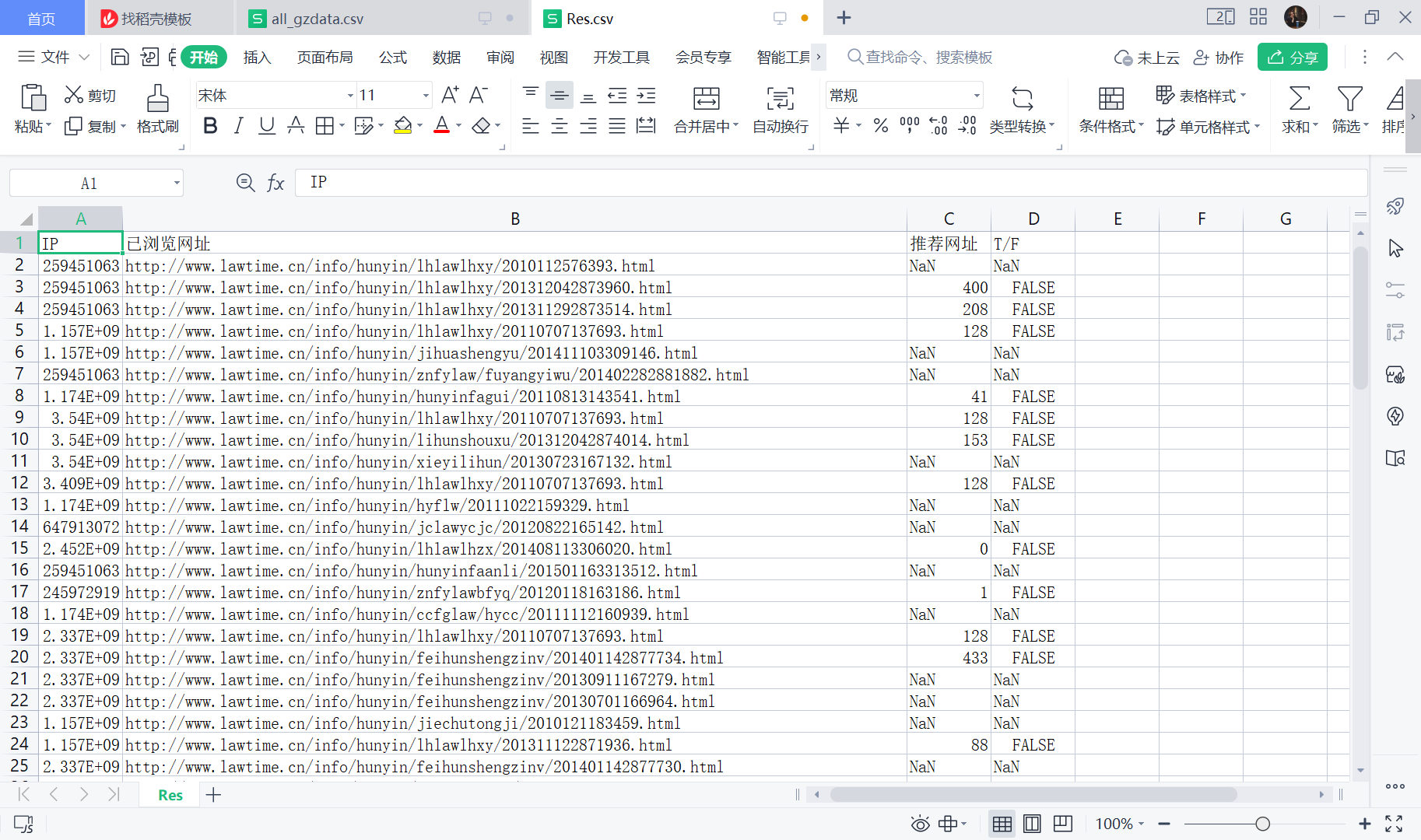
# 代码11-14 import pandas as pd # 利用训练集数据构建模型 UI_matrix_tr = pd.DataFrame(0,index=IP_tr,columns=url_tr) # 求用户-物品矩阵 for i in data_tr.index: UI_matrix_tr.loc[data_tr.loc[i,'realIP'],data_tr.loc[i,'fullURL']] = 1 sum(UI_matrix_tr.sum(axis=1)) # 求物品相似度矩阵(因计算量较大,需要耗费的时间较久) Item_matrix_tr = pd.DataFrame(0,index=url_tr,columns=url_tr) for i in Item_matrix_tr.index: for j in Item_matrix_tr.index: a = sum(UI_matrix_tr.loc[:,[i,j]].sum(axis=1)==2) b = sum(UI_matrix_tr.loc[:,[i,j]].sum(axis=1)!=0) Item_matrix_tr.loc[i,j] = a/b # 将物品相似度矩阵对角线处理为零 for i in Item_matrix_tr.index: Item_matrix_tr.loc[i,i]=0 # 利用测试集数据对模型评价 IP_te = data_te.iloc[:,0] url_te = data_te.iloc[:,1] IP_te = list(set(IP_te)) url_te = list(set(url_te)) # 测试集数据用户物品矩阵 UI_matrix_te = pd.DataFrame(0,index=IP_te,columns=url_te) for i in data_te.index: UI_matrix_te.loc[data_te.loc[i,'realIP'],data_te.loc[i,'fullURL']] = 1 # 对测试集IP进行推荐 Res = pd.DataFrame('NaN',index=data_te.index, columns=['IP','已浏览网址','推荐网址','T/F']) Res.loc[:,'IP']=list(data_te.iloc[:,0]) Res.loc[:,'已浏览网址']=list(data_te.iloc[:,1]) # 开始推荐 for i in Res.index: if Res.loc[i,'已浏览网址'] in list(Item_matrix_tr.index): Res.loc[i,'推荐网址'] = Item_matrix_tr.loc[Res.loc[i,'已浏览网址'], :].argmax() if Res.loc[i,'推荐网址'] in url_te: Res.loc[i,'T/F']=UI_matrix_te.loc[Res.loc[i,'IP'], Res.loc[i,'推荐网址']]==1 else: Res.loc[i,'T/F'] = False # 保存推荐结果 Res.to_csv('D:/人工智能&软件工程/数据挖掘与分析//tmp/Res.csv',index=False,encoding='utf8')

- 计算F1指标
# 代码11-15 import pandas as pd # 读取保存的推荐结果 Res = pd.read_csv('D:/人工智能&软件工程/数据挖掘与分析/tmp/Res.csv',keep_default_na=False, encoding='utf8') # 计算推荐准确率 Pre = round(sum(Res.loc[:,'T/F']=='False') / (len(Res.index)-sum(Res.loc[:,'T/F']=='NaN')), 3) print(Pre) # 计算推荐召回率 Rec = round(sum(Res.loc[:,'T/F']=='False') / (sum(Res.loc[:,'T/F']=='False')+sum(Res.loc[:,'T/F']=='NaN')), 3) print(Rec) # 计算F1指标 F1 = round(2*Pre*Rec/(Pre+Rec),3) print("学号:3041") print(F1)
1.0 0.376 学号:3041 0.547
数据分析-电子商务网站行为分析
发布时间 2023-04-03 00:54:38作者: Binnie