clang前端基础系统概要
4.1编译器Clang会代替GCC吗?
Clang是一个C语言、C++、Objective-C语言的轻量级编译器,遵循BSD协议。
Clang编译速度快、内存占用小、兼容GCC等一些优秀的特点使得很多工具都在使用它。
现在Clang和GCC的异同。
4.1.1 GCC概念
GCC:GNU(Gnu's Not Unix)编译器套装(GNU Compiler Collection,GCC),指一套编程语言编译器,以GPL及LGPL许可证所发行的自由软件,也是GNU项目的关键部分,也是GNU工具链的主要组成部分之一。GCC(特别是其中的C语言编译器)也常被认为是跨平台编译器的事实标准。1985年由理查德·马修·斯托曼开始发展,现在由自由软件基金会负责维护工作。GCC原本用C开发,后来因为LLVM、Clang的崛起,它更快地将开发语言转换为C++。
GCC支持的语言:原名为GNU C语言编译器(GNU C Compiler),因为它原本只能处理C语言。GCC在发布后很快地得到扩展,变得可处理C++。之后也变得可处理Fortran、Pascal、Objective-C、Java、Ada、Go与其他语言。
许多操作系统,包括许多类Unix系统,如Linux及BSD家族都采用GCC作为标准编译器。苹果电脑预装的Mac OS X操作系统也采用这个编译器。
GCC目前由世界各地不同的数个程序员小组维护。它是移植到最多中央处理器架构以及最多操作系统的编译器。由于GCC已成为GNU系统的官方编译器(包括GNU/Linux家族),它也成为编译与创建其他操作系统的主要编译器,包括BSD家族、Mac OS X、NeXTSTEP与BeOS。
GCC通常是跨平台软件的编译器首选。有别于一般局限于特定系统与运行环境的编译器,GCC在所有平台上都使用同一个前端处理程序,产生一样的中介码,因此此中介码在各个其他平台上使用GCC编译,有很大的机会可得到正确无误的输出程序。
GCC支持的主要处理器架构:ARM、x86、x86-64、MIPS、PowerPC等。
GCC结构:GCC的外部接口长得像一个标准的Unix编译器。用户在命令行下键入gcc之程序名,以及一些命令参数,以便决定每个输入文件使用的个别语言编译器,并为输出代码使用适合此硬件平台的汇编语言编译器,并且选择性地运行连接器以制造可执行的程序。每个语言编译器都是独立程序,此程序可处理输入的源代码,并输出汇编语言码。全部的语言编译器都拥有共同的中介架构:一个前端解析匹配此语言的源代码,并产生抽象语法树,以及翻译此语法树成为GCC的寄存器转换语言的后端。编译器最优化与静态代码解析技术在此阶段应用于代码上。最后,适用于此硬件架构的汇编语言代码以杰克·戴维森与克里斯·弗雷泽发明的算法产出。
几乎全部的GCC都由C/C++写成,除了Ada前端大部分以Ada写成。
4.1.2 Clang概念
Clang:是一个C、C++、Objective-C和Objective-C++编程语言的编译器前端。它采用了底层虚拟机(LLVM)作为其后端。它的目标是提供一个GNU编译器套装(GCC)的替代品。作者是克里斯·拉特纳(Chris Lattner),在苹果公司的赞助支持下进行开发,而源代码授权是使用类BSD的伊利诺伊大学厄巴纳-香槟分校开源码许可。Clang主要由C++编写。
Clang项目包括Clang前端和Clang静态分析器等。这个软件项目在2005年由苹果电脑发起,是LLVM(Low Level Virtual Machine)编译器工具集的前端(front-end),目的是输出代码对应的抽象语法树(Abstract Syntax Tree, AST),并将代码编译成LLVM Bitcode。接着在后端(back-end)使用LLVM编译成平台相关的机器语言。
Clang本身性能优异,其生成的AST所耗用掉的内存仅仅是GCC的20%左右。2014年1月发行的FreeBSD10.0版将Clang/LLVM作为默认编译器。
Clang性能:测试证明Clang编译Objective-C代码时速度为GCC的3倍,还能针对用户发生的编译错误准确地给出建议。
4.1.3 GCC与Clang区别
GCC特性:除支持C/C++/ Objective-C/Objective-C++语言外,还支持Java/Ada/Fortran/Go等;当前的Clang的C++支持落后于GCC;支持更多平台;更流行,广泛使用,支持完备。
Clang特性:编译速度快;内存占用小;兼容GCC;设计清晰简单、容易理解,易于扩展增强;基于库的模块化设计,易于IDE集成;出错提示更友好。
Clang采用的license是BSD,而GCC是GPLv3。
GCC相比Clang:
1)GCC支持clang不支持的语言,如Java、Ada、FORTRAN、Go等。
2)GCC比LLVM支持更多的目标。
3)GCC支持许多语言扩展,其中有些Clang不能实现。
使用的宏不同:
1)GCC定义的宏包括:
__GNUC__
__GNUC_MINOR__
__GNUC_PATCHLEVEL__
__GNUG__
2)Clang除了支持GCC定义的宏之外还定义了:
__clang__
__clang_major__
__clang_minor__
__clang_patchlevel__
4.2使用 Clang 静态分析器分析调试
4.2.1 静态分析器概述
Clang 是 LLVM 的一个前端,底层依赖于 LLVM 架构,而Xcode使用Clang。
LLVM 不是一个缩写,它是一个工具集,用于构建编译器、优化器、运行时环境。Clang 只是在其基础上建立的 C语系(C/C++/Objective C)编译器,该计划最初设想提供一种基于SSA编译策略的,支持任意编程语言的静态和动态编译,现今该计划已经发展出多个模块化的子项目,成为编译器和相关工具链的合集。
Clang Static Analyzer(静态分析器)是 Clang 项目的一部分,在 Clang 基础上构建,静态分析引擎被实现为可重用的C++库,可以在多种环境下使用(Xcode、命令行、接口调用等)。静态分析会自动检查源代码中的隐含bug,并产生编译器警告。随着静态分析技术的发展,其已经从简单的语法检查,步进到深层的代码语义分析。由于使用最新的技术深入分析代码,因此静态分析可能比编译慢得多(即使启用编译优化),查找错误所需的某些算法在最坏的情况下需要指数时间。静态分析还可能会存在假阳性问题(False Positives)。如果需要更多 Checker 来让静态分析引擎执行特定检查,需要在源码中实现。
4.2.2 静态分析器库结构
分析库包含 2 层:
1)静态分析引擎(GRExprEngine.cpp 以及其它)。
2)多个静态检查器(*Checker.cpp)。
后者通过 Checker 和 CheckerVisitor 接口(Checker.h 和 CheckerVisitor.h)构建在前者之上。
Checker 接口设计的足够简洁以便增加更多检查器,并尽量避免涉及到引擎内部繁杂的细节。
4.2.3静态分析器工作原理
简而言之,分析器是一个源码的模拟器,追踪其可能的执行路径。程序状态(变量和表达式的值)被封装为 ProgramState。程序中的位置被叫做 ProgramPoint。state 和 program point 的组合是 ExplodedGraph 中的节点。术语“exploded”来自控制流图(control-flow graph,CFG)中爆炸式增长的控制流连边。
概念上讲,分析器会沿着 ExplodedGraph 执行可达性分析(reachability analysis)。从具有程序入口点和初始状态的根节点开始,分析模拟每个单独表达式的转移。表达式分析会产生状态改变,使用更新后的程序点和状态创建新节点。当满足某些 bug 条件时(违反检测不变量,checking invariant),就认为发现了bug。
分析器通过推理分支(branches)追踪多条路径(paths),分叉状态:在 true 分支上认为分支条件为 true,在 false 分支上认为分支条件为 false。这种假设创建了程序中的值约束(constraints),这些约束被记录在 ProgramState 对象(通过 ConstraintManager 修改)。如果假设分支条件会导致不能满足约束,这条分支就被认为不可行,路径也不会被选取。这就是实现路径敏感(path-sensitivity)的方式。降低了缓存节点的指数爆炸。如果和已存在节点含相同状态和程序点的新节点将被生成,路径会出缓存(caches out),只简单重用已有节点。因此 ExplodedGraph 不是有向无环图(DAG),它可以包含圈(cycles),路径相互循环,以及出缓存。
ProgramState 和 ExploledNodes 在创建后基本上是不可变的。当产生新状态时,需要创建一个新的 ProgramState。这种不变性是必要的,因为 ExplodedGraph 表示了从入口点开始分析的程序的行为。为了高效表达,使用了函数式数据结构(比如 ImmutableMaps )在实例间共享数据。
最终,每个单独检查器(Checkers)也通过操作分析状态来工作。分析引擎通过访问者接口(visitor interface)与之沟通。比如,PreVisitCallExpr() 方法被 GRExprEngine 调用,来告诉 Checker 将要分析一个 CallExpr,然后这个检查器被请求检查任意前置条件,这些条件可能不会被满足。检查器不会做除此之外的任何事情:生成一个新的 ProgramState 和包含更新后的检查器状态的 ExplodedNode。如果发现了一个 bug,会把错误告诉 BugReporter 对象,提供引发该问题的路径上的最后一个 ExplodedNode 节点。
4.2.3 内部检查器Inside Checker
静态分析引擎按下图所示流程运行。所有 Checker 都由 CheckerManager 管理调度,而CheckerManager 由分析引擎内核管理。
图4.1 表示静态分析checker示例。

图4.1 静态分析checker示例
Checker 内部沿 ExplodedGraph 构造节点,遇到违反约束条件的状态时汇报错误。图4.2 表示静态分析checker汇报错误示例。

图4.2 静态分析checker汇报错误示例
4.2.4 检测器与检测器管理Checker & CheckerManager
首先查看 Checker 种类和接口,其规范了所有检查器行为,并交由 CheckerManager 管理。
在 Checker.h,clang::ento::check:: 命名空间下包含所有 CHECK 种类的定义,例如 PreStmt,表示语句(Statement)返回前执行的类型,代码如下。
所有的这些 CHECK 种类都包含模板静态方法 _checkXXX(),其调用实际的 checker 的一个固定方法(这里是 checkPreStmt(),所有派生自该类的 Checker 类都应该默认实现该方法(类似 virtual=0 )。
并且包含公开静态方法 _register() 用于将实际的 checker 注册到 CheckerManager。
template <typename STMT>
class PreStmt {
template <typename CHECKER>
static void _checkStmt(void *checker, const Stmt *S, CheckerContext &C) {
((const CHECKER *)checker)->checkPreStmt(cast<STMT>(S), C);
}
static bool _handlesStmt(const Stmt *S) {
return isa<STMT>(S);
}
public:
template <typename CHECKER>
static void _register(CHECKER *checker, CheckerManager &mgr) {
mgr._registerForPreStmt(CheckerManager::CheckStmtFunc(checker, _checkStmt<CHECKER>), _handlesStmt);
}
};
Checker 类是实际的检查器的接口类,负责转发其继承的所有的 CHECKs 的静态注册方法 CHECK::_register() (通过折叠表达式,Fold Expressions),把实际的 checker 作为这种 CHECK 类型注册给 Manager,这样在 Manager 遇到对应情形时,可以遍历所有在这一类别下需要执行检查的 Checker。
Checker 还继承 CheckerBase,包含检查器名称和其它实用方法。
template <typename CHECK1, typename... CHECKs>
class Checker : public CHECK1, public CHECKs..., public CheckerBase {
public:
template <typename CHECKER>
static void _register(CHECKER *checker, CheckerManager &mgr) {
CHECK1::_register(checker, mgr);
Checker<CHECKs...>::_register(checker, mgr);
}
};
template <typename CHECK1>
class Checker<CHECK1> : public CHECK1, public CheckerBase {
public:
template <typename CHECKER>
static void _register(CHECKER *checker, CheckerManager &mgr) {
CHECK1::_register(checker, mgr);
}
};
一个简单的接口使用样例如下。自定义 Checker 需要继承 Checker<SOMECHECK>,并且必须包含由 SOMECHECK 要求的方法声明和实现。
class DivZeroChecker : public Checker< check::PreStmt<BinaryOperator> > {
public:
void checkPreStmt(const BinaryOperator *B, CheckerContext &C) const;
};
CheckerManager 就是文档中所说的 CheckerVisitor。其负责管理所有 Checkers 的生命周期。实际上可以看做一个 Bucket System(装桶系统)。
在 CheckerManager.h,CheckerFn 封装 Checker 的调用函数,以及对象指针,然后作为 Manager 的内部注册的函数,将其装入容器(就是一个 vector)。需要装入容器的不仅包括 Checker 的实际作用函数(比如之前的 checkPreStmt(),还包括析构器(Dtor)。
CheckerManager 类的 registerChecker() 方法构造 Checker 实例(通过完美转发,Perfect Forwarding),并调用其静态方法 _register(),将 Checker 的指针绑定到所有的检查器种类,用于特定种类的遍历调用(一个 Checker 可以是多种类型,在每种情形下都发挥特定作用)。代码中的 CheckerDtors 收集了所有检查器的析构函数(包裹为 CheckerFn ),用于程序退出时销毁检查器对象。
如前所示,Checker 的对象指针会按所有类型注册给 Manager 对象,对于 PreStmt 类型,会调用 mgr._registerForPreStmt(),对于 PostStmt 类型,会调用mgr._registerForPostStmt(),这些内部注册方法都把实际作用函数(比如之前的 checkPreStmt())包裹为 CheckerFn (这里是 CheckStmtFunc ),然后装入内部容器(这里是 std::vector<T> StmtCheckers )。
然后,在需要执行特定类型检查器时,比如下面代码中的 runCheckersForPreStmt(),其内部实现会遍历内部容器,容器中每个对象就是一个 CheckerFn,封装了对象指针和方法,可以直接调用。
在 ExprEngine.h,ExprEngine 会获取 Manager 对象,并在合适的时机执行 runCheckersForXXX 方法。
template <typename T> class CheckerFn;
class CheckerManager {
// ...
using CheckerDtor = CheckerFn<void ()>;
// Checker registration.
template <typename CHECKER, typename... AT>
CHECKER *registerChecker(AT &&... Args) {
CheckerTag tag = getTag<CHECKER>();
CheckerRef &ref = CheckerTags[tag];
assert(!ref && "Checker already registered, use getChecker!");
CHECKER *checker = new CHECKER(std::forward<AT>(Args)...);
checker->Name = CurrentCheckerName;
CheckerDtors.push_back(CheckerDtor(checker, destruct<CHECKER>));
CHECKER::_register(checker, *this);
ref = checker;
return checker;
}
// Functions for running checkers
void runCheckersForPreStmt(ExplodedNodeSet &Dst,
const ExplodedNodeSet &Src,
const Stmt *S,
ExprEngine &Eng) {
runCheckersForStmt(/*isPreVisit=*/true, Dst, Src, S, Eng);
}
// ...
// Internal registration functions
using CheckStmtFunc = CheckerFn<void (const Stmt *, CheckerContext &)>;
// ...
void _registerForPreStmt(CheckStmtFunc checkfn,
HandlesStmtFunc isForStmtFn);
void _registerForPostStmt(CheckStmtFunc checkfn,
HandlesStmtFunc isForStmtFn);
// ...
private:
template <typename CHECKER>
static void destruct(void *obj) { delete static_cast<CHECKER *>(obj); }
std::vector<CheckerDtor> CheckerDtors;
struct StmtCheckerInfo {
CheckStmtFunc CheckFn;
HandlesStmtFunc IsForStmtFn;
bool IsPreVisit;
};
std::vector<StmtCheckerInfo> StmtCheckers;
}
之后查看具体的一些 Checker 的实现,这里不会过渡深入,分析点到为止,以完成目标优先。
并且注意,只使用稳定的可用的Checkers,不使用实验性的 Alpha Checkers。后者目前可能还有很多问题。
4.2.5 关于 Clang 静态分析器
1. 静态分析器快速使用
静态分析器是一个 Xcode 内置的工具,使用它可以在不运行源代码的状态下进行静态的代码分析,并且找出其中的 Bug,为 app 提供质量保证。
静态分析器工作的时候并不会动态地执行代码,它只是进行静态分析,因此它甚至会去分析代码中没有被常规的测试用例覆盖到的代码执行路径。
静态分析器只支持 C/C++/Objective-C 语言,因为静态分析器隶属于 Clang 体系中。不过即便如此,它对于 Objective-C 和 Swift 混编的工程也可以很好地支持。
下面是一个实际的使用案例,使用 Objective-C 和 Swift 混编的工程。通过点击 Xcode 的 Product 菜单栏中的 Analyze 选项,就可以让分析器开始工作。
图4.3 所示表示Xcode的Product的 Analyze 选项。

图4.3 Xcode的Product的 Analyze 选项
Clang 静态分析器的目标是提供一个工业级别的静态分析框架,用于分析 C、C++ 和 Objective-C 程序代码,它是免费可用的、可扩展的,并且拥有极高的代码质量。
Clang 静态分析器基于 Clang 和 LLVM 之上,LLVM 之父 Chris Lattner 对外介绍 LLVM 称之为一系列接口清晰的可重用库,Clang 就是这些库中的一个,所以它也具备很好的可重用性。
Clang 是 LLVM 体系中的编译器独立前端,为 C/C++/Objective-C 三种语言(Clang 就是 C Language 的意思),Clang 的 Static Analyzer是 Clang 的子工具,编译 Clang 后可独立运行,目的就是为了对代码进行静态检查、捕获问题然后报告问题。
2. 静态分析器源码结构
图4.4 所示表示StaticAnalyzer与checker源码结构,这是在 LLVM 中的模块位置:
/clang/lib/StaticAnalyzer

图4.4 StaticAnalyzer与checker源码结构
LLVM中Clang静态分析器模块源码位置
可以看到,这个 Checkers 目录下就是一个又一个的检查器,每一个检查器负责一个独立的检查项目,很多的复用结构,共用逻辑部分下沉到 Core 模块中。
因为整个模块位于 Clang 和 LLVM 的上层,所以 Core 模块中大量依赖了 LLVM、Clang 中的库。
woboq是一个在线的源码阅读工具,点击链接可以可以看到 Checkers 路径下的所有 Checkers 文件源码,以及上一级的 Core & Frontend。
3. scan-build 和 scan-view
scan-build 负责对目标代码进行分析,并生成 html 样式的分析报告。
scan-view 负责在本地运行一个简易的 web server,用来让使用者方便的查看生成的报告。
图4.5 所示表示编译后的scan-build和view,编译 LLVM 编译后生成的scanbuild 和view两个命令的位置:
/build/tools/clang/tools/scam-build
/build/tools/clang/tools/scam-view

图4.5 编译后的scan-build和view
4.3 Swift 与 Objective-C 混编时,如何将编译时间优化35%?
2019 年 3 月 25 日,苹果发布了 Swift 5.0 版本,宣布了 ABI 稳定,并且Swift runtime 和标准库已经植入系统中,而且苹果新出文档都用 Swift,Sample Code 也是 Swift,可以看出 Swift 是苹果扶持与研发的重点方向。
国内外各大公司都在相继试水,只要关注 Swift 在国内 iOS 生态圈现状,就会发现,Swift 在国内 App 应用的比重逐渐升高。对于新 App 来说,可以直接用纯 Swift 进行开发,而对于老 App 来说,绝大部分以前都是用 OC 开发的,因此 Swift/OC 混编是一个必然面临的问题。
4.3.1 Swift 和 OC 混编开发
关于 Swift 和 OC 间如何混编,业内也已经有很多相关文章详细讲解,简单来说 OC/Swift 调用 Swift,最终通过 Swift Module 进行,而 Swift 调用 OC 时,则是通过 Clang Module,当然也可以通过 Clang Module 进行 OC 对 OC 的调用。
在 Module 化实践中发现,实际数据与苹果官方 Module 编译时间数据不一致,于是通过 Clang 源码和数据相结合的方式对 Clang Module 进行了深入研究,找到了耗时的原因。由于 Swift/OC 混编下需要 Module 化的支持,同时借鉴业内 HeaderMap 方案让 OC 调用 OC 时避开 Module 化调用,将编译时间优化了约 35%,较好地解决了在 Module 化下的编译时间问题。
Clang Module 初探
Clang Module 在 2012 LLVM 开发者大会上第一次被提出,主要用来解决 C 语言预处理的各种问题。Modules 试图通过隔离特定库的接口并且编译一次生成高效的序列化文件来避免 C 预处理器重复解析 Header 的问题。在探究 Clang Module 之前,先了解一下预处理的前世今生。图4.6所示表示编译输出为目标文件流程,一个源代码文件到经过编译输出为目标文件主要分为下面几个阶段:

图4.6 编译输出为目标文件流程
源文件在经过 Clang 前端包含:词法分析(Lexical analysis) 、语法分析(Syntactic analysis) 、语义分析(Semantic analysis)。最后输出与平台无关的 IR(LLVM IR generator),进而交给后端进行优化生成汇编输出目标文件。
词法分析(Lexical analysis)作为前端的第一个步骤负责处理源代码的文本输入,具体步骤就是将语言结构拆分为一组单词和记号(token),跳过注释,空格等无意义的字符,并将一些保留关键字转义为定义好的类型。词法分析过程中遇到源代码 “#“ 的字符,且该字符在源代码行的起始位置,则认为它是一个预处理指令,会调用预处理器(Preprocessor)处理后续。在开发中引入外部文件的 include/import 指令,定义宏 define 等指令均是在预处理阶段交由预处理器进行处理。Clang Module 机制的引入带来的改变着重于解决常规预处理阶段的问题,可以重点探究一下其中的区别和实现原理。
4.3.2 普通 import 的机制
Clang Module 机制引入之前,在日常开发中,如果需要在源代码中引入外部的一些定义或者声明,常见的做法就是使用 #import 指令来使用外部的 API。那么这些使用的方式在预处理阶段是怎么处理的呢?针对编译器遇到 #import<PodName/header.h> 或者 #import ”header.h” 这种导入方式时候,#开头在词法分析阶段会触发预处理(Preprocessor)。而对于 Clang 的预处理器 import 与 include 指令都属于它的关键词。预处理器在处理输入口令时候主要工作为通过导入的 header 名称去查找文件的磁盘所在路径,然后进入该文件创建新的词法分析器对导入的头文件进行词法分析。如图4.7所示:编译器在遇到 #import 或者 #include 指令时,触发预处理机制查询头文件的路径,进入头文件对头文件的内容进行解析的流程。
图4.7所示表示对头文件的内容进行解析的流程。
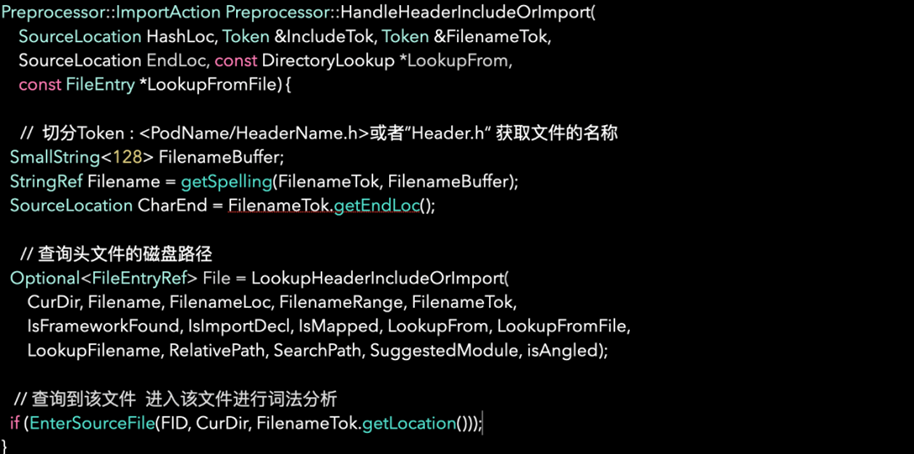
图4.7 对头文件的内容进行解析的流程
以单个文件编译过程为维度举例:在针对一个文件编译输出目标文件的过程中,可能会引入多个外界的头文件,而被引入多个外界头文件也有可能存在引入外界头文件。这样的情况就导致,虽然只是在编译单个文件,但是预处理器会对引入的头文件进行层层展开。这也是很多人称 #import 与 include 是一种特殊复制效果的原因。
那么在这种预处理器的机制在工程中编译中会存在什么问题呢?苹果官方在 2012 的 WWDC 视频上同样给了解答:Header Fragility(健壮性)和 Inherently Non-Scalable(不可扩展性)。来看下面一段代码,在 PodBTestObj 类的文件中定义一个 ClassName 字符串的宏,然后在导入 PoBClass1.h 头文件,在 PoBClass1.h 的头文件中同样定义一个结构体名为 ClassName,这里与在 PodBTestObj 类中定义的宏同名。预处理的特殊的复制机制,在预处理阶段会发生如图4.8所见的结果:

图4.8 预处理阶段的copy机制
这样的问题相信在日常开发中并不罕见,而为了解决这种重名的问题,常规的手法只能通过增加前缀或者提前约定规则等方式来解决。
同时指出这种机制在应对大型工程编译过程中的所带来的消耗问题。假设有 N 个源文件的工程,那么每个源文件引用 M 个头文件,由于预处理的这种机制,在针对处理每个源文件的编译过程中会对引入的 M 个头文件进行展开,经历一遍遍的词法分析-语法分析-语义分析的过程。那么能想象一下针对系统头文件的引入在预处理阶段将会是一个多么庞大的开销!
图4.9所示表示头文件的引入在预处理阶段开销

图4.9 头文件的引入在预处理阶段开销
那么针对 C 语言预处理器存在的问题,苹果有哪些方案可以优化这些存在的问题呢?
4.3.3 PCH (Precompiled Headers)
PCH(Precompile Prefix Header File)文件,也就是预编译头文件,其文件里的内容能被项目中的其他所有源文件访问。日常开发中,通常放一些通用的宏和头文件,方便编写代码,提高效率。关于 PCH 的概述,苹果是这样定义的:使用 Clang 内部数据结构序列化表示,采用的 LLVM 字节流表示。它的设计理念是:当项目中几乎每个源文件中都包含一组通用的头文件时,将该组头文件写入 PCH 文件中。
在编译项目中的流程中,每个源文件的处理都会首先去加载 PCH 文件的内容,所以一旦 PCH 编译完成,后续源文件在处理引入的外部文件时,会复用 PCH 编译后的内容,从而加快编译速度。PCH 文件中存放所需要的外部头文件的信息(包括不局限于声明、定义等)。它以特殊二进制形式进行存储,而在每个源代码编译处理外部头文件信息时,不需要每次进行头文件的展开和复制的重复操作。而只需要懒加载预编译好的 PCH 内容即可。
存储内容方面它存放着序列化的 AST 文件。AST 文件本身包含 Clang 的抽象语法树和支持数据结构的序列化表示,它们使用与 LLVM的位码文件格式相同的压缩位流进行存储。关于 AST File 文件的存储结构可以在官方文档有详细的了解。它作为苹果一种优化方案被提出,但是实际的工程中源代码的引用关系是很复杂的,所以找出一组几乎所有源文件都包含的头文件基本不可能,同时对于代码更新维护更是一个挑战。其次在被包含头文件改动下,因为 PCH 会被所有源文件引入,会带来代码污染的问题。同时一旦 PCH 文件发生改动,会导致大面积的源代码重编造成编译时间的浪费。
4.3.5 Modules组件的抽象描述
上述简单回顾了一些 C 语言预处理的机制以及为解决编译消耗引入 PCH 的方案,但是在一定程度上 PCH 方案也存在很大的缺陷。因此在 2012 LLVM Developer’s Meeting 首
次提出了 Modules 的概念。那么 Module 到底是什么呢?图4.10所示表示Module包描述库。

图4.10 Module包描述库
Module 简单来说可以认为它是对一个组件的抽象描述,包含组件的接口和实现。
Module 机制推出主要用来解决上述所阐述的预处理问题,想要探究 Clang Module 的实
现,首先需要去开启 Module。那么针对 iOS 工程怎么开启 Module 呢?
仅仅需要在 Xcode 的编译选项中修改配置即可。而在代码的使用上几乎可以不用修改代码,开启 Module 之后,通过引用头文件的方式可以继续沿用 #import <PodName/Header.h> 方式。当然对于开发者也可以采用新的方式 @import ModuleName.SubModuleName,以及 @import ModuleName这几种方式。更为详细的信息和使用方法可以在苹果的官方文档中查看。
4.3.6 苹果对 Module 的解读
上文提到过基于 C 语言预处理器提供的,#include 机制提供的,访问外界库 API 的方式存在的伸缩性和健壮性的问题。Modules 提供了更为健壮,更高效的语义模型来替换之前文本预处理器,改进对库的 API 访问方式。苹果官方文档中针对 Module 的解读有以下几个优势:
1)扩展性:每个 Module 只会编译一次,将 Module 导入翻译单元的时间是恒定的。对于库 API 的访问只会解析一次,将 #include 的机制下的由 M x N 编译问题简化为 M + N。
2)健壮性:每个 Module 作为一个独立的实体,具备一个一致的预处理环境。不需要去添加下划线,或者前缀等方式解决命名的问题。每个库不会影响另外一个库的编译方式。
翻阅了苹果 WWDC 2013 的 Advances in Objective-C 视频,视频中针对编译时间性能方面进行了 PCH 和 Module 编译速度的数据分析。苹果给出的结论是小项目中 Module 比 PCH 能提升 40% 的编译时间,并且随着工程规模的不断增大,如增大到 Xcode 级别,Module 的编译速度也会比 PCH 稍快。PCH 也是为了加速编译而存在的,由此也可以间接得出结论,Module的编译速度要比没有 PCH 的情况下更快,如在 Mail 下,应该提升 40% 以上。
4.4 Clang Module 原理深究
Clang Module 机制的引入主要是为了解决预处理器的各种问题,那么工程在开启 Module 之后,工程上会有哪些变化呢?同时在编译过程中编译器工作流程与之前又有哪些不同呢?
4.4.1 ModuleMap 与 Umbrella
以基于 cocoapods 作为组件化管理工具为例,开启 Module 之后工程上带来最直观的改变是pod组件下支持文件目录新增几个文件:podxxx.moduleMap , podxxx-
umbrella.h。图4.11所示表示iOS ModuleMap 与 Umbrella工程。

图4.11 iOS ModuleMap 与 Umbrella工程
Clang 官方文档指出如果要支持 Module,必须提供一个 ModuleMap 文件用来描述从头文件到模块逻辑结构的映射关系。ModuleMap 文件的书写使用模块映射语言。通过示例可以发现它定义了 Module 的名字,umbrella header 包含了其目录下的所有头文件。module * 通配符的作用是为每个头文件创建一个 subModule。图4.12所示表示umbrella header到subModule的工程。

图4.12 umbrella header到subModule的工程
简单来说,可以认为 ModuleMap 文件为编译器提供了构建 Clang Module 的一张地图。它描述了要构建的 Module 的名称,以及 Module 结构中要暴露供外界访问的 API。
为编译器构建 Module 提供必要条件。
除了上述开启 Module 的组件会新增
ModuleMap 与 Umbrella 文件之外。在使用开启
Module 的组件时候也有一些改变,使用 Module 组件的 target,BuildSetting 中
其他C标志中会增加 -fmodule-map-file
的参数。
对该参数的解释为:当加载一个头文件属于 ModuleMap 的目录或者子目录时,则去加载 ModuleMap文件。
4.4.2 Module 的构建
了解完 ModuleMap 与 Umbrella 文件和新增的参数之后,决定深入去跟踪一下这些文件与参数的在编译期间的使用状态。上文提到过在词法分析阶段,以“#”开头的预处理指令,针对 HeaderName 文件进行真实路径查找,并对要导入的文件进行同样的词法,语法,语义等操作。在开启 Module 化之后,头文件查找流程与之前有什么区别呢?在不修改代码的基础上,编译器又是怎么识别为语义化模型导入(Module import)呢?如图4.15所示:在初始化预处理之前,会针对 buildsetting 中设置的 Header Search path,Framework Search Path 等编译参数解析赋值给 SearchDirs。
这里大家对 ModuleMap、Umbrella 文件以及 -fmodule-map-path 有了一定的认知。
而且也跟踪了为什么编译器可以做到不修改代码的“智能”的帮助代码在 # import 和 Module Import 之间切换。
与非 module 不同,来继续追踪一下
LoadModule 的后续发生了什么?ModuleLoader 进行指定的 Module 的加载,而这里的 LoadModule 正是 Module 机制的差异之处。Module 的编译与加载是在第一次遇到 ModuleImport 类型的 importAction 时候进行缓存查找和加载,Module 的编译依赖 moduleMap 文件的存在,也是编译器编译 Module 的读取文件的入口,编译器在查找过程中命中不了缓存,则会在开启新的
compilerInstance,并具备新的预处理上下文,处理该 Module 下的头文件。产生抽象语法树然后以二进制形式持久化保存到后缀为 .pcm 的文件中(有关 pcm 文件后文有详细讲解),遇到需要 Module 导入的地方反序列化 PCM 文件中的 AST 内容,将需要的 Type
定义,声明等节点加载到当前的翻译单元中。图4.13所示表示加载节点到翻译单元中。

图4.13 加载节点到翻译单元中
Module 持有对 Module 构建中每个头文件的引用,如果其中任何一个头文件发生变化,或者 Module 依赖的任何 Module 发生变化,则该 Module 会自动重新编译,该过程不需要开发人员干预。
4.4.3 Clang Module 复用机制
Clang Module 机制的引入,不仅仅从之前的文本复制到语义化模型导入的转变。它的设计理念同时也着重在复用机制,做到一次编译写入缓存 PCM 文件,在此后其他的编译实体中复用缓存。关于 Module 都是编译和缓存探究的验证,可以在 build log 中通过 -fmodules-cache-path 来查看获取到 Module 缓存路径(例如,/Users/xxx/Library/Developer/Xcode/DerivedData/ModuleCache.noindex/
)。当前如果想自定义缓存路径,可以通过添加 -fmodules-cache-path 指定缓存路径。图4.14所示表示添加 -fmodules-cache-path 指定缓存路径。

图4.14 添加 -fmodules-cache-path 指定缓存路径
针对已有组件化工程,每个 pod 库都可能存在复杂的依赖关系,以图4.15所示工程示例:

图4.15 每个 pod 库存在复杂的依赖关系
在多组件工程中,会发现不同的组件之间会存在相同的依赖情况。针对复杂的 Module 依赖的场景,通过 Clang源码发现,在编译 Module-lifeCirclePod(上述示例)时, lifeCirclePod 依赖于 Module-UIKitPod。在编译 Module-lifeCirclePod 遇到需要 Module-UIKitPod 导入时,那么此时则会挂起该编译实体的线程,开辟新的线程进行 Module-UIKitPod 的编译。
当 Module-UIKitPod 编译完成时,才会恢复 lifeCirclePod 的任务。而开启 Module 之后,每个组件都会作为一个 Module 编译并缓存,而当 MainPagePod 后续编译过程中遇到 Module-UIKitPodModule
的导入时,复用机制就可以触发。编译器可以通过读取 pcm 文件,反序列化 AST 文件直接使用。编译器不用每次重复的去解析外界头文件内容。上述基本对
Module 的本质及其复用机制有一定的了解,是不是随意开启 Moudle 就可以了呢?其实不然!在实践中发现(以基于 cocoapods 管理为例)在 fmodules-cache-path 的路径下存在很多份的 pcm 缓存文件,针对同一个工程就会发现存在多个下面的现象如图4.16所示:

图4.16 在 fmodules-cache-path存在很多pcm 缓存文件
可以发现在工程的一次编译下,会出现多个目录出现同一个 module 的缓存情况(eg:lifeCirclePod-1EBT2E5N8K8FN.pcm)。之前讲过 Module 机制是一次编译后续复用的吗?实际情况好像与理论冲突!这就要求去深入探究
Module 复用的机制。
追寻 Clang 的源码发现编译器进行预处理器 Preprocessor 的创建时,会根据自身工程的参数来设定 Module 缓存的路径。
如图4.17所示,将影响 Module 缓存的产生的 hash 目录的主要受编译参数分为下面几大类:

图4.17 Module 缓存的产生的 hash分类
在实际的工程中,常常不同 pod 间的 build settting 不同,导致在编译过程中会生成不同的 hash 目录,从而缓存查找时,会出现查找不到 pcm 缓存而重复生成 Module 缓存的现象。这也解释了上面发现不同的缓存 hash 目录下会出现相同名字的 pcm 缓存。了解 Module 缓存的因素,可以有助于在复杂的工程场景中,提高 Module 的复用率减少 Module Complier 的时间。
Tips:除了上述的缓存 hash 目录外,会发现在此目录下存在以 ModuleName-hashxxxxxx.pcm 的命名,那么缓存文件的命名方式发现是 ModuleName+hash 值的方式,hash 值的生成来自 ModuleMap 文件的路径,所以保持工程路径的一致性也是 Module 复用的关键因素。
4.4.4 PCM文件
上文提到了一个很重要的文件 PCM,那么 PCM 文件作为
Module 的缓存存放,它的内容又是怎么样的呢?提到 PCM 文件,第一时间很容易联想到 PCH。PCH 文件的应用大家应该都很熟悉,根据苹果在介绍 PCH 的官方文档中结构如图4.18所示:
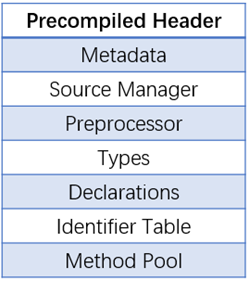
图4.18 PCH 文件结构
PCH 中存放着不同的模块,每个模块都包含 Clang 内部数据的序列化表示。采用 LLVM’s bitstream format 的方式存储。其中
1)Metadata 块主要用于验证 AST 文件的使用;
2)SourceManager 块它是前端
SourceManager 类的序列化,它主要用来维护 SourceLocation 到源文件或者宏实例化的实际行/列的映射关系;
3)Types: 包含
TranslationUnit 引用的所有类型的序列化数据,在 Clang 类型节点中,每个节点都有对应的类型;
4)Declarations: 包含
TranslationUnit 引用的所有声明的序列化表示;
5)Identifier Table: 它包含一个 hash Table,该表记录了 ASTfile 中每个标识符到标识符信息的序列化表示;
6)Method Pool: 它与
Identifier Table 类似,也是 Hash Table,提供了 OC 中方法选择器和具体类方法和实例方方法的映射。Module 实现机制与 PCH 相同,也是序列化的 AST 文件,可以通过 llvm-bcanalyzer 把 pcm 文件的内容 dump 出来。
Module 的编译是独立的线程,独立的编译实体过程,与输出目标文件对应的前端 action 不同,它所对应的FrontAction为GenerateModuleAction。Module 的机制主要是提供一种语义化的模块导入方式。所以 PCM 的缓存内容同样会经过词法,语法,语义分析的过程,PCM 文件中的 AST 模块的序列化保存是在发现在语义分析之后。
利用了 Clang AST 基类中的
ASTConsumer 类,该类提供了若干可以 override 的方法,用来接收 AST 解析过程中的回调,当编译单元TranslationUnit的AST完整解析后,可以通过调用 HandleTranslationUnit 在获取到完整抽象语法树上的所有节点。PCM 文件的写入由 ASTWriter 类提供 API,这些具体的流程可以在 ASTWriter 类中具体跟踪。在该过程中主要分为 ControlBlock 信息的写入,该步骤包含 Metadata,InputFiles,Header search path 等信息的记录。
通过上面源码等流程,相信掌握了以下内容:
1)ModuleMap 文件用来描述从头文件到模块逻辑结构的映射关系,Umbrella 或者Umbrella Header 描述了子Module的概念;
2)Module 的构建是“独立”进行的,Module 间存在依赖时,优先编译完成被依赖的Module;
3)Clang 提供了 Module 的新用法(@import ModuleName),但是针对项目无需改造,Clang 在预处理时提供了 Module 与非 Module 的转换;
4)Module 提供了复用的机制,它将暴露外界的 API 以 ASTFile 格式存储,在代码未发生变化时,直接读取缓存。而在代码变动时,Xcode
会在合适的时机对 Module 进行更新,开发者无需额外干预。
4.5 使用Clang大杀器校验语法树
作为iOS开发,clang和LLVM应该都挺熟悉了,可用Clang制作一个代码扫描的小工具,把Clang命令行工具开发的流程记录于此。
4.5.1 制作clang命令行工具
Clang作为前端编译器,对iOS源代码进行词法、语法的分析,实现万千代码,终归一体的效果,以便可以从词法、语法的角度实现对工程质量的保证。
制作Clang命令行工具的初衷有两个:
1)业务代码定制扫描,提供工程代码质量,比如检测项目里危险代码调用、敏感代码调用和成对代码调用等。
2)代码自动化生成,提升开发效率,避免不必要的犯错,比如PBCoding代码生成。
4.5.2 Clang命令行工具主要内容
如表4.1所示,经过摸索,把学习
Clang命令行工具的步骤用下面5个步骤概括:

表4.1 Clang命令行工具的步骤
预备知识中,如果能看懂下面如图4.19所示表达的含义,那么可以说是具备iOS工程编译流程的知识储备的:
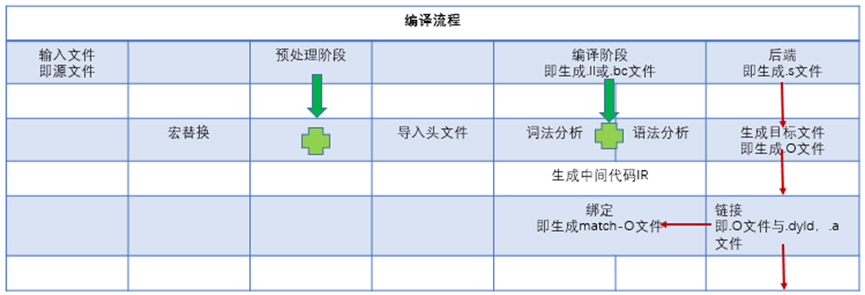
图4.19 iOS工程编译流程示例
如果想再验证一下自己掌握的iOS工程编译流程知识是否扎实,可以试着回答这样几个问题:
1)如果动手制作一个 framework,会怎么做,有哪些条件是开始制作 framework 前要商定好的?
2)什么情况下,framework 开发只能给二进制包,而不能使用 submodule 协同开发?
3)clang 是 LLVM 的子集吗?clang 和 LLVM 是什么关系?
4)Injection 等热加载工具的原理
这几个问题是在iOS工程编译上遇到的问题。
基于iOS工程编译流程的预备知识已经略去不讲,所以这里从环境搭建开始,描述 Clang命令行工具开发的流程。
4.5.3 环境搭建
1. clone LLVM项目
clone llvm 项目工程:git
clone https://github.com/llvm/llvm-project.git
2. 编译LLVM
在 llvm-project 项目中新建
build 目录,并执行cd build,使用cmake命令编译LLVM工程,生成Xcode可以编译的文件格式。
cmake -G Xcode -DLLVM_ENABLE_PROJECTS=clang ../llvm
3. 文件概览
查看 llvm-project 工程,重点可以看下 build、clang(前端编译器)、lld(链接器)、lldb(调试器)、llvm(optimization代码优化 + 生成平台相关的汇编代码)。
4. Xcode编译LLVM
打开 build - LLVM.Xcodeproj,选择 Autocreat Schemes,添加 schemes All_BUILD,开始编译。
cmd + B 开始进行编译。
5. 生成结构概览
编译完成后,可以在 llvm-project - build - Debug - bin 看到编译生成的命令行工具。其中有一些是非常有用的,比如 clang-format 可以实现代码格式化。
6. 新建clang开发文件
下面开始通过 clang 构建工具,进入
llvm-project - clang - tools
1)新建 AddCodePlugin 文件夹,在文件夹中添加 AddCodePlugin.cpp 和 CMakeLists.txt
Tips:AddCodePlugin.cpp
是编写工具代码的地方,CMakeLists.txt 是使用
CMake 编译时,添加依赖的文件
2)在 llvm-project - clang - tools 目录下 CMakeLists.txt 文件中新增:add_clang_subdirectory(AddCodePlugin)
7. 重新编译
编写完 AddCodePlugin.cpp,配置好 CMakeLists.txt 后,开启重编:
返回 build 文件夹,执行 cmake
-G Xcode -DLLVM_ENABLE_PROJECTS=clang ../llvm
如此,可以看到文件编译出来了。
8. Xcode打开项目
接着重新打开 LLVM.xcodeproj,这时在 LLVM.xcodeproj 中已经能看到刚才新增的项目文件了。到此,开发Clang命令行工具的环境已经准备完毕了,可以使用Xcode进入开发流程了。
4.5.4 开发框架选择
现在有了 AddCodePlugin.cpp 这个文件,接下来的问题是:怎么开发呢?iOS画UI有UIKit框架,新建对象有NSObject类,那么,开发Clang命令行工具有框架可以选择吗?可以的。
一共有 LibClang(ClangKit)、LibTooling两个工具库可供开发使用,下面是对这两个库的描述:
1. LibClang
LibClang 提供了一个稳定的高级 C
接口,Xcode 使用的就是 LibClang。LibClang 可以访问 Clang 的上层高级抽象的能力,比如获取所有 Token、遍历语法树、代码补全等。由于 API 很稳定,Clang 版本更新对其影响不大。但是,LibClang 并不能完全访问到 Clang AST 信息。
使用 LibClang 可以直接使用它的 C
API。官方也提供了 Python binding 脚本供调用。还有开源的 node-js/ruby binding。要是不熟悉其他语言,还有个第三方开源的
Objective-C 写的ClangKit 库可供使用。
2. LibTooling
LibTooling 是一个 C++ 接口,通过 LibTooling 能够编写独立运行的语法检查和代码重构工具。LibTooling 的优势如下:
1)所写的工具不依赖于构建系统,可以作为一个命令单独使用,比如 clang-check、clang-fixit、clang-format;
2)可以完全控制 Clang AST,能够和
Clang Plugins 共用一份代码;
3)与 Clang Plugins 相比,LibTooling
无法影响编译过程;
与 LibClang 相比,LibTooling
的接口没有那么稳定,也无法开箱即用,当 AST 的 API 升级后需要更新接口的调用。但是,LibTooling 基于能够完全控制 Clang AST 和可独立运行的特点,可以做的事情就非常多了。比如代码语言转换、坚持代码规范、分析甚至重构代码等。
在 LibTooling 的基础之上有个开发工具合集 Clang tools,Clang tools 作为 Clang 项目的一部分,已经提供了一些工具,主要包括:
1)语法检查工具 clang-check;
2)自动修复编译错误工具 clang-fixit;
3)自动代码格式工具 clang-format;
4)新语言和新功能的迁移工具;
5)重构工具。
针对 AST 进行操作,LibClang 不能完全访问到 Clang AST 的信息,担心会成为未来的一个瓶颈,LibTooling库使用起来也挺方便,只是 AST 的 API 升级确实会造成代码变动的情况,但Clang命令行的使用场景是接受2-3天buffer对接新API的,所以使用 LibTooling也不错。
4.5.5代码开发
1. 新建城市目标
新建一个 callMethod.m测试类,代码如下:
#import "ViewController.h"
@interface ViewController ()
@property (nonatomic, strong) NSString *test;
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
}
- (void)hello {
[self
viewDidLoad];
[self
exit];
}
- (void)exit {
}
@end
可能会觉得这份测试类代码有点问题,怎么在 hello方法里主动调用了 viewDidLoad呢?其实是故意这样处理的,目标就是:编写 clang命令行工具,检测出主动调用了 viewDidLoad 的方法。
2. AST(Abstract Syntax Tree 抽象语法树) 结构
在具体开发Clang插件前,先来看看要分析的AST的结构是怎么样的,输入如下命令:
clang -Xclang
-ast-dump -fsyntax-only /Users/binbinwang/Desktop/callMethod.m
发现生成了如下的AST:
#import "ViewController.h"
^~~~~~~~~~~~~~~~~~
TranslationUnitDecl 0x7fd098037608
<<invalid sloc>> <invalid sloc>
|-TypedefDecl 0x7fd098037ed8 <<invalid
sloc>> <invalid sloc> implicit __int128_t '__int128'
| `-BuiltinType 0x7fd098037ba0 '__int128'
|-TypedefDecl 0x7fd098037f48 <<invalid
sloc>> <invalid sloc> implicit __uint128_t 'unsigned __int128'
| `-BuiltinType 0x7fd098037bc0 'unsigned
__int128'
|-TypedefDecl 0x7fd098037ff0 <<invalid
sloc>> <invalid sloc> implicit SEL 'SEL *'
| `-PointerType 0x7fd098037fa0 'SEL *'
|
`-BuiltinType 0x7fd098037e00 'SEL'
|-TypedefDecl 0x7fd0980380f0 <<invalid
sloc>> <invalid sloc> implicit id 'id'
| `-ObjCObjectPointerType 0x7fd098038090 'id'
|
`-ObjCObjectType 0x7fd098038050 'id'
|-TypedefDecl 0x7fd0980381f0 <<invalid
sloc>> <invalid sloc> implicit Class 'Class'
| `-ObjCObjectPointerType 0x7fd098038190
'Class'
|
`-ObjCObjectType 0x7fd098038150 'Class'
|-ObjCInterfaceDecl 0x7fd098038248
<<invalid sloc>> <invalid sloc> implicit Protocol
|-TypedefDecl 0x7fd09806ec00 <<invalid
sloc>> <invalid sloc> implicit __NSConstantString 'struct
__NSConstantString_tag'
| `-RecordType 0x7fd098038390 'struct
__NSConstantString_tag'
|
`-Record 0x7fd098038308 '__NSConstantString_tag'
|-TypedefDecl 0x7fd09806ecb0 <<invalid
sloc>> <invalid sloc> implicit __builtin_ms_va_list 'char *'
| `-PointerType 0x7fd09806ec60 'char *'
|
`-BuiltinType 0x7fd0980376a0 'char'
|-TypedefDecl 0x7fd09806efb0 <<invalid
sloc>> <invalid sloc> implicit __builtin_va_list 'struct
__va_list_tag [1]'
| `-ConstantArrayType 0x7fd09806ef50 'struct
__va_list_tag [1]' 1
|
`-RecordType 0x7fd09806ed90 'struct __va_list_tag'
|
`-Record 0x7fd09806ed08 '__va_list_tag'
|-ObjCCategoryDecl 0x7fd09806f020
</Users/binbinwang-air/Desktop/callMethod.m:10:1, line:14:2> line:10:12
invalid
|-ObjCInterfaceDecl 0x7fd09806f140
<line:16:1, <invalid sloc>> col:17 implicit ViewController
| `-ObjCImplementation 0x7fd09806f250
'ViewController'
`-ObjCImplementationDecl 0x7fd09806f250
<col:1, line:31:1> line:16:17 ViewController
|-ObjCInterface 0x7fd09806f140 'ViewController'
|-ObjCMethodDecl 0x7fd09806f3a8 <line:18:1, line:20:1> line:18:1 -
viewDidLoad 'void'
|
|-ImplicitParamDecl 0x7fd09806f860 <<invalid sloc>> <invalid
sloc> implicit self 'ViewController *'
|
|-ImplicitParamDecl 0x7fd09806f8c8 <<invalid sloc>> <invalid
sloc> implicit _cmd 'SEL':'SEL *'
|
`-CompoundStmt 0x7fd09806f930 <col:21, line:20:1>
|-ObjCMethodDecl 0x7fd09806f580 <line:22:1, line:25:1> line:22:1 -
hello 'void'
|
|-ImplicitParamDecl 0x7fd09806f940 <<invalid sloc>> <invalid
sloc> implicit used self 'ViewController *'
|
|-ImplicitParamDecl 0x7fd09806f9a8 <<invalid sloc>> <invalid
sloc> implicit _cmd 'SEL':'SEL *'
|
`-CompoundStmt 0x7fd09806fae0 <col:15, line:25:1>
| |-ObjCMessageExpr 0x7fd09806fa48
<line:23:5, col:22> 'void' selector=viewDidLoad
| | `-ImplicitCastExpr 0x7fd09806fa30
<col:6> 'ViewController *' <LValueToRValue>
| |
`-DeclRefExpr 0x7fd09806fa10 <col:6> 'ViewController *' lvalue
ImplicitParam 0x7fd09806f940 'self' 'ViewController *'
| `-ObjCMessageExpr 0x7fd09806fab0
<line:24:5, col:15> 'void' selector=exit
| `-ImplicitCastExpr 0x7fd09806fa98
<col:6> 'ViewController *' <LValueToRValue>
| `-DeclRefExpr 0x7fd09806fa78
<col:6> 'ViewController *' lvalue ImplicitParam 0x7fd09806f940 'self'
'ViewController *'
`-ObjCMethodDecl 0x7fd09806f6f8 <line:27:1, line:29:1> line:27:1 -
exit 'void'
|-ImplicitParamDecl 0x7fd09806fb00 <<invalid sloc>>
<invalid sloc> implicit self 'ViewController *'
|-ImplicitParamDecl 0x7fd09806fb68 <<invalid sloc>>
<invalid sloc> implicit _cmd 'SEL':'SEL *'
`-CompoundStmt 0x7fd09806fbd0 <col:14, line:29:1>
这种结构是一种类似Node的结构。
在AST中搜索一下关心的 viewDidLoad方法,可以发现有两个地方被检索到了(一处是ViewDidLoad方法本身,一处是调用ViewDidLoad方法)。
在viewDidLoad方法中打印了注册通知的线程,当然这是主线程了。然后在子线程中异步的发送一条通知,具体代码如图4.20所示:
图4.20 viewDidLoad线程示例
其中:
1)TranslationUnitDecl:根节点,表示一个编译单元。
2)TypedefDecl:表示一个声明。
3)CompoundStmt:表示陈述。
4)DeclRefExpr:表示的是表达式。
5)IntegerLiteral:表示的是字面量,是一种特殊的expr。
Clang 里,节点主要分成
Type 类型、Decl 声明、Stmt 陈述这三种,其他的都是这三种的派生。通过扩展这三类节点,就能够将无限的代码形态用有限的形式来表现出来了。
在iOS编译流程上,AST生成后就要交给LLVM做优化和后端编译了,可以说AST是一个和平台无关的中间代码。
3. 开发流程介绍
如图4.21所示表示iOS工程clang开发示例。

图4.21 iOS工程clang开发示例
1)入口
像iOS工程一样,clang工具的开发,也有一个main入口:
// 入口main函数
int main(int argc, const char **argv) {
CommonOptionsParser OptionsParser(argc, argv, ObfOptionCategory);
ClangTool
Tool(OptionsParser.getCompilations(),OptionsParser.getSourcePathList());
return
Tool.run(newFrontendActionFactory<ObfASTFrontendAction>().get());
}
main入口的作用主要是将要声明的AST匹配器return出去,比如这里要构建的AST匹配器叫ObfASTFrontendAction。
2)获取数据源
接着,需要获取AST的数据源,获取AST数据源的方式比较简单,只要声明一个类继承自ASTFrontendAction即可,如下:
class ObfASTFrontendAction : public ASTFrontendAction {
public:
//创建AST Consumer
std::unique_ptr<ASTConsumer> CreateASTConsumer(clang::CompilerInstance &CI, StringRef file) override {
return std::make_unique<ObfASTConsumer>(&CI);
}
void EndSourceFileAction() override {
cout << "处理完成" << endl;
}
};
3)声明处理人(AST Consumer)
在构建ASTFrontendAction时构建了 AST Consumer,AST Consumer中会构建匹配方法:
class ObfASTConsumer : public ASTConsumer {
private:
ClangAutoStatsVisitor Visitor;
public:
void HandleTranslationUnit(ASTContext &context) {
TranslationUnitDecl *decl = context.getTranslationUnitDecl();
Visitor.TraverseTranslationUnitDecl(decl);
}
};
这里可以通过 RecursiveASTVisitor构建匹配方法,也可以通过 AST Matcher制定匹配规则。
上面是采用了 ASTConsumer + RecursiveASTVisitor 的匹配方式,如果使用 ASTConsumer + AST Matcher的匹配方式,应声明如下:
class ObfASTConsumer : public ASTConsumer {
public:
ObfASTConsumer(CompilerInstance *aCI) :handlerMatchCallback(aCI) {
//添加匹配器
matcher.addMatcher(objcMessageExpr().bind("objCMessageExpr"),&handlerMatchCallback);
}
void HandleTranslationUnit(ASTContext &Context) override {
//运行匹配器
matcher.matchAST(Context);
}
private:
MatchFinder matcher;
MatchCallbackHandler handlerMatchCallback;
};
4)匹配规则
使用 RecursiveASTVisitor进行匹配时,重写下面这三个方法就行:
bool ObfuscatorVisitor::VisitObjCMessageExpr(ObjCMessageExpr *messageExpr) {
//遇到了一个消息表达式,例如:[self getName];
return true;
}
bool ObfuscatorVisitor::VisitObjCImplementationDecl(ObjCImplementationDecl *D) {
//遇到了一个类的定义,例如:@implementation ViewController
return true;
}
bool ObfuscatorVisitor::VisitObjCInterfaceDecl(ObjCInterfaceDecl *iDecl {
//遇到了一个类的声明,例如:@interface ViewController : UIViewController
return true;
}
比如这里可以写做:
class ClangAutoStatsVisitor : public RecursiveASTVisitor<ClangAutoStatsVisitor> {
private:
Rewriter &rewriter;
public:
explicit ClangAutoStatsVisitor(Rewriter &R) : rewriter{R} {} // 创建方法
bool VisitObjCMessageExpr(ObjCMessageExpr *messageExpr) {
cout << "调用的方法:" + messageExpr->getSelector().getAsString() << endl;
return true;
}
};
4.6 iOS底层原理之LLVM & Clang
4.6.1 Clang插件前言
现在对编译器架构系统LLVM进行一个简单的了解和分析,了解完LLVM的编译流程之后,简单实现一个Clang插件。下面就开始今天的内容。
研究编译器之前,先了解下解释型语言和编译型语言的区别。
1)解释型语言:程序不需要编译,程序在运行时才翻译成机器语言,每执行一次都要翻译一次。效率比较低,依赖解释器,跨平台性好。
2)编译型语言:程序在执行之前需要一个专门的编译过程,把程序编译成为机器语言的文件,运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差些。
那么有没有什么办法能让程序执行效率高的同时,还能保证跨平台性好呢?
要探索的LLVM就提出了相应的解决方案。
4.6.2 LLVM1.1 LLVM概述
LLVM是架构编译器(compiler)的框架系统,以C++编写而成,用于优化以任意程序语言编写的程序的编译时间(compile-time)、链接时间(link-time)、运行时间(run-time)以及空闲时间(idle-time),对开发者保持开放,并兼容已有脚本。
LLVM计划启动与2000年,最初由美国UIUC大学的Chris Lattner博士主持开展。2006年Chris Lattner加盟Apple Inc.并致力于LLVM在Apple开发体系中的应用。Apple也是LLVM计划的主要资助者。
目前LLVM已经被苹果iOS开发工具、Xilinx Vivado、Facebook、Google等各大公司采用。
4.6.3 传统编译器设计
如图4.22所示表示传统编译器开发流程

图4.22 传统编译器开发流程
1. 编译器前端(Frontend)
编译器前端的任务是解析源代码。它会进行:词法分析,语法分析,语义分析,检查源代码是否存在错误,然后构建抽象语法树(Abstract Syntax Tree,AST),LLVM的前端还会生成中间代码(intermediate representation,IR)。
2. 优化器(Optimizer)
优化器负责进行各种优化。缩小包的体积(剥离符号)、改善代码的运行时间(消除冗余计算、减少指针跳转次数等)。
3. 后端(Backend)/代码生成器(CodeGenerator)
后端将代码映射到目标指令集。生成机器语言,并且进行机器相关的代码优化。
由于传统的编译器(如GCC)是作为整体的应用程序设计的,不支持多种语言或者多种硬件架构,所以它们的用途受到了很大的限制。
4.6.4 LLVM的设计
当编译器决定支持多种源语言或多种硬件架构时,LLVM最重要的地方就来了。
LLVM设计的最重要方面是,使用通用的代码表示形式(IR),用来在编译器中表示代码的形式。LLVM可以为任何编程语言独立编写前端,并且可以为任意硬件架构独立编写后端。
在需要支持一种新语言时,只需要再对应编写一个可以产生IR的独立前端;需要支持一种新硬件架构时,只需要再对应编写一个可以接收IR的独立后端。如图4.23 LLVM编译
器IR流程。
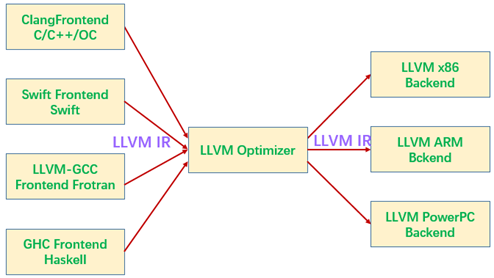
图4.23 LLVM编译器IR流程
1. iOS的编译器架构
Objective-C/C/C++使用的编译器前端是Clang,苹果Swift开发语言,后端都是LLVM。
4.6.5 Clang前端
Clang是LLVM项目中的一个子项目。它是基于LLVM架构的轻量级编译器,诞生之初是为了替代GCC,提供更快的编译速度。它是负责编译Objective-C/C/C++语言的编译器,它属于整个LLVM架构中的编译器前端。对于开发者来说,研究Clang可以带来很多好处。
1. 编译流程
通过下面命令可以打印源码的编译阶段:
clang -ccc-print-phases main.m
1)输入文件:找到源文件。
2)预处理阶段:这个过程处理包括宏的替换,头文件的导入。
3)编译阶段:进行词法分析、语法分析、检测语法是否正确,最终生成IR(或bitcode)。
4)后端:这里LLVM会通过一个一个的Pass(环节、片段)去优化,每个Pass完成一些功能,最终生成汇编代码。
5)生成目标文件。
6)链接:链接需要的动态库和静态库,生成可执行文件。
7)根据不同的硬件架构(此处是M1版iMAC,arm64),生成对应的可执行文件。
如图4.24所示,整个过程中,没有明确指出优化器,这是因为优化已经分布在前后端里面了。

图4.24 LLVM clang编译器全流程
1)输入源文件
找到源文件。
2)预处理阶段
执行预处理指令,包括进行宏替换、头文件的导入、条件编译,产生新的源码传给编译器。
通过下面命令,可以看到执行预处理指令后的代码:
// 直接在终端查看clang -E main.m
// 生成mian1.m文件查看clang -E main.m
>> main1.m
3)编译阶段
这个阶段包括进行词法分析、语法分析、语义分析、检测语法是否正确、生成AST、生成IR(.ll)或者bitcode(.bc)文件。
2. 词法分析
预处理完成后就会进行词法分析,将代码分割成一个个Token及标明其所在的行数和列数,包括关键字、类名、方法名、变量名、括号、运算符等。
使用下面命令可以,可以看到词法分析后的结果:
clang -fmodules -fsyntax-only -Xclang -dump-tokens main.m
3. 语法分析
词法分析完成之后就是语法分析,它的任务是验证源码的语法结构的正确性。在词法分析的基础上,将单词序列组合成各类语法短语,如“语句”,“表达式”等,然后将所有节点组成抽象语法树(Abstract Syntax Tree,AST)。
通过下面命令,可以查看语法分析后的结果:
clang -fmodules -fsyntax-only
-Xclang -ast-dump main.m
// 如果导入头文件找不到,可以指定SDK
clang -isysroot sdk路径 -fmodules -fsyntax-only -Xclang
-ast-dump main.m
语法树分析:
// 这里的地址都是虚拟地址(当前文件的偏移地址),运行时才会开辟真实地址
// Mach-O反编译拿到的地址就是这个虚拟地址
// typedef 0x1298ad470 虚拟地址
-TypedefDecl 0x1298ad470 <line:12:1, col:13> col:13 referenced XJ_INT_64 'int'
| `-BuiltinType 0x12a023500 'int'
// main函数,返回值int,第一个参数int,第二个参数const char **
`-FunctionDecl 0x1298ad778 <line:15:1, line:22:1> line:15:5 main 'int (int, const char **)'
// 第一个参数
|-ParmVarDecl
0x1298ad4e0 <col:10, col:14> col:14 argc 'int'
// 第二个参数
|-ParmVarDecl
0x1298ad628 <col:20, col:38> col:33 argv 'const
char **':'const
char **'
// 复合语句,当前行 第41列 到 第22行第1列
// 即main函数 {} 范围
/*
{
XJ_INT_64 a =
10;
XJ_INT_64 b =
20;
printf("%d", a + b + C);
return 0;
}
*/
`-CompoundStmt
0x12a1aa560 <col:41, line:22:1>
// 声明 第17行第5列 到 第21列,即
XJ_INT_64 a = 10
|-DeclStmt 0x1298ad990 <line:17:5, col:21>
// 变量 a,0x1298ad908 虚拟地址
| `-VarDecl 0x1298ad908 <col:5, col:19> col:15 used a 'XJ_INT_64':'int' cinit
// 值是 10
| `-IntegerLiteral 0x1298ad970 <col:19> 'int' 10
// 声明 第18行第5列 到 第21列,即XJ_INT_64
b = 20
|-DeclStmt 0x1298adeb8 <line:18:5, col:21>
// 变量 b,0x1298ad9b8 虚拟地址
| `-VarDecl 0x1298ad9b8 <col:5, col:19> col:15 used b 'XJ_INT_64':'int' cinit
// 值是 20
| `-IntegerLiteral 0x1298ada20 <col:19> 'int' 20
// 调用
printf 函数
|-CallExpr 0x12a1aa4d0 <line:19:5, col:27> 'int'
//函数指针类型,即
int printf(const char * __restrict, ...)
| |-ImplicitCastExpr
0x12a1aa4b8 <col:5> 'int
(*)(const char *, ...)' <FunctionToPointerDecay>
// printf函数,0x1298ada48
虚拟地址
| | `-DeclRefExpr
0x1298aded0 <col:5> 'int (const
char *, ...)' Function 0x1298ada48 'printf' 'int (const char *, ...)'
// 第一个参数,""里面内容
| |-ImplicitCastExpr
0x12a1aa518 <col:12> 'const
char *' <NoOp>
// 类型说明
| | `-ImplicitCastExpr
0x12a1aa500 <col:12> 'char *' <ArrayToPointerDecay>
// %d
| | `-StringLiteral 0x1298adf30 <col:12> 'char [3]' lvalue "%d"
// 加法运算,a +
b 的值作为第一个值 + 第二个值 30
| `-BinaryOperator
0x12a1aa440 <col:18, line:10:11> 'int' '+'
// 加法运算,a +
b
| |-BinaryOperator 0x12a1aa400 <line:19:18, col:22> 'int' '+'
// 类型说明
| | |-ImplicitCastExpr 0x1298adfc0 <col:18> 'XJ_INT_64':'int' <LValueToRValue>
// a
| | | `-DeclRefExpr 0x1298adf50 <col:18> 'XJ_INT_64':'int' lvalue Var 0x1298ad908 'a' 'XJ_INT_64':'int'
// 类型说明
| | `-ImplicitCastExpr 0x1298adfd8 <col:22> 'XJ_INT_64':'int' <LValueToRValue>
// b
| | `-DeclRefExpr
0x1298adf88 <col:22> 'XJ_INT_64':'int' lvalue
Var 0x1298ad9b8 'b' 'XJ_INT_64':'int'
// 宏替换后的 30
| `-IntegerLiteral 0x12a1aa420 <line:10:11> 'int' 30
// return
0
`-ReturnStmt
0x12a1aa550 <line:21:5, col:12>
`-IntegerLiteral
0x12a1aa530 <col:12> 'int' 0
\
4. 生成中间代码IR(intermediate representation)
完成以上步骤后就开始生成中间代码IR了,代码生成器(Code
Generation)会将语法树自顶向下遍历逐步翻译成LLVM IR。OC代码在这一步会进行runtime的桥接,比如property合成、ARC处理等。
这是IR的基本语法格式:
@ 全局标识
% 局部标识
alloca 开辟空间
align 内存对齐
i32 32个bit,4个字节
store 写入内存
load 读取数据
call 调用函数
ret 返回
通过下面命令,可以生成.ll的文本节件,查看IR代码。
clang -S -fobjc-arc -emit-llvm main.m
4.6.5 IR的优化
在上面的IR代码中,可以看到,通过一点一点翻译语法树,生成的IR代码,看起来有点粗糙,其实是可以优化的。
LLVM的优化级别分别是-O0、-O1、-O2、-O3、-Os、-Ofast、-Oz(第一个是大写英文字母O)。
可以使用命令进行优化:
clang -Os -S -fobjc-arc -emit-llvm main.m -o main.ll
优化后的IR代码,简洁明了(优化等级并不是越高越好,release模式下为-Os,这也是最推荐的)。
也可以在 xcode 中设置:target -> build
Setting -> Optimization Level
4.6.6 bitCode
Xcode 7以后,如果开启bitcode,苹果会对.ll的IR文件做进一步的优化,生成.bc文件的中间代码。
通过下面命令,使用优化后的IR代码生成.bc代码:
clang -emit-llvm -c main.ll -o main.bc
1. 后端阶段(生成汇编.s)
后端将接收到的IR结构转化成不同的处理对象,并将其处理过程实现为一个个的Pass类型。通过处理Pass,来完成对IR的转换、分析和优化。然后生成汇编代码(.s)。
通过下面命令,使用.bc或者.ll代码生成汇编代码:
// bitcode -> .sclang -S
-fobjc-arc main.bc -o main.s
// IR -> .sclang -S
-fobjc-arc main.ll -o main.s
// 也可以对汇编代码进行优化 clang -Os -S -fobjc-arc
main.ll -o main.s
2. 汇编阶段(生成目标文件.o)
目标文件的生成,是汇编器以汇编代码作为输入,将汇编代码转换为机器代码,最后输出目标文件(.o)。
命令如下:
clang -fmodules -c main.s -o main.o
通过nm命令,查看main.o中的符号:
xcrun nm -nm main.o
可以看到执行命令后,报了一个错:找不到外部的_printf符号。因为这个函数是从外部引入的,需要将使用的对应的库链接进来。
3. 链接阶段(生成可执行文件Mach-O)
链接器把编译产生的.o文件、需要的动态库.dylib和静态库.a链接到一起,生成可执行文件(Mach-O文件)。
命令如下:
clang main.o -o main
查看链接之后的符号:
baypac@JustindeiMac Clang %
xcrun nm -nm main
(undefined) external
_printf(from libSystem)
(undefined) external dyld_stub_binder(from
libSystem)
(__TEXT, __text) [referenced
dynamically] external __mh_execute_header
(__TEXT, __text) external
_test
(__TEXT, __text) external
_main
(__DATA, __data) non-external
__dyld_private
可以看到输出结果中依然显示找不到外部符号_printf,但是后面多了(from libSystem),指明了_printf所在的库是libSystem。这是因为libSystem动态库需要在运行时动态绑定。
test函数和main函数也已经生成了文件的偏移位置。目前这个文件已经是一个正确的可执行文件了。
同时还多了一个dyld_stub_binder符号,其实只要链接就会有这个符号,这个符号是负责动态绑定的,在Mach-O进入内存后(即执行),dyld立刻将libSystem中dyld_stub_binder的函数地址与Mach-O中的符号进行绑定。
dyld_stub_binder符号是非懒绑定。其他的懒绑定符号,比如此处的_printf,在首次使用的时候通过dyld_stub_binder来将真实的函数地址与符号进行绑定,调用的时候就可以通过符号找到对应库里面的函数地址进行调用了。外部函数绑定图解如图4.25所示:
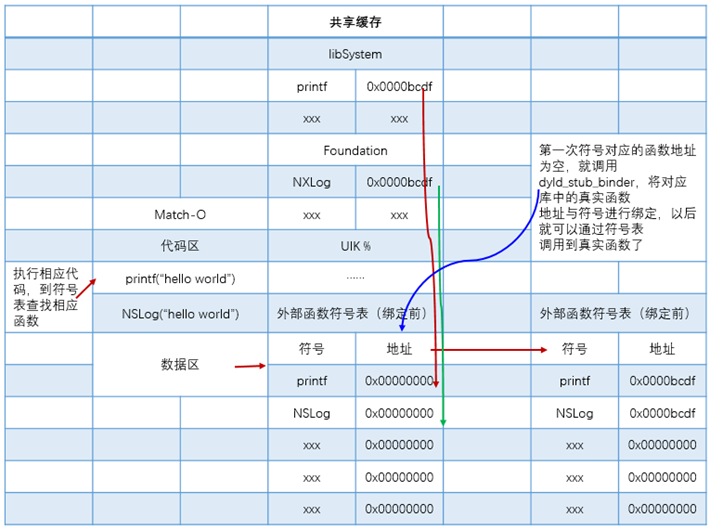
图4.25 外部函数绑定图解
链接和绑定的区别:
1)链接,编译时,标记符号在哪个库,只是做了一个标记。
2)绑定,运行时,将外部函数地址与Mach-O中的符号进行绑定。
使用如下命令执行Mach-O文件:./main
4. 绑定硬件架构
根据不同的硬件架构(此处是M1版iMAC,arm64),生成对应的可执行文件。
4.6.7 总结编译流程
\
////
====== 前端 开始=====
// 1. 词法分析 clang -fmodules
-fsyntax-only -Xclang -dump-tokens main.m
// 2. 语法分析
clang
-fmodules -fsyntax-only -Xclang -ast-dump main.m // 3. 生成IR文件 clang -S -fobjc-arc -emit-llvm main.m
// 3.1 指定优化级别生成IR文件
clang -Os
-S -fobjc-arc -emit-llvm main.m -o main.ll
// 3.2 (根据编译器设置) 生成bitcode 文件
clang
-emit-llvm -c main.ll -o main.bc
////
====== 后端 开始=====
// 1. 生成汇编文件
// bitcode
-> .s
clang -S
-fobjc-arc main.bc -o main.s
// IR
-> .s
clang -S
-fobjc-arc main.ll -o main.s
// 指定优化级别生成汇编文件
clang -Os
-S -fobjc-arc main.ll -o main.s
// 2. 生成目标Mach-O文件
clang
-fmodules -c main.s -o main.o
// 2.1 查看Mach-O文件
xcrun nm
-nm main.o
// 3. 生成可执行Mach-O文件
clang
main.o -o main
////
====== 执行 开始=====
// 4. 执行可执行Mach-O文件
./main
生成汇编文件就已经是编译器后端的工作了,为什么还是使用的clang命令呢?这是因为使用clang提供的接口启动后端相应的功能。
4.7 自定义Clang命令,利用LLVM Pass实现对OC函数的静态插桩
Objective-C在函数hook的方案比较多,但通常只实现了函数切片,也就是对函数的调用前或调用后进行hook,这里介绍一种利用llvm pass进行静态插桩的另外一种思路。
4.7.1 Objective-C中的常见的函数Hook实现思路
Objective-C是一门动态语言,具有运行时的特性,所以能选择的方案比较多,常用的有:method swizzle,message forward(aspectku),libffi,fishhook。但列举的这些方案只能实现函数切片,也就是在函数的调用前或者调用后进行Hook。但比如想在这函数的逻辑中插入桩函数(如下代码所示),常见的hook思路就没办法实现了。
- (NSInteger)foo:(NSInteger)num {
NSInteger result = 0;
if (num > 0) {
// 往这里插入一个桩函数:__hook_func_call(int,...)
result = num + 1;
}else {
// 往这里插入一个桩函数:__hook_func_call(int,...)
result = num + 2;
}
return result;
}
为了解决上述问题,接下来介绍如何利用在编译的过程中修改对应的文件,实现把桩函数插入到指定的函数实现中。例如以上的函数,插入桩函数之后的效果(在函数打个断点,然后查看汇编代码,就能看到对应的自定义桩函数)。
那么如何自定义Clang命令,利用llvm Pass实现对函数的静态插桩呢?下面分为两部分,一部分是llvmpass,另外一部分是自定义Clang的编译参数。两者合起来实现这个功能。
4.7.2什么是LLVM Pass
LLVM Pass是一个框架设计,是LLVM系统里重要的组成部分,一系列的Pass组合,构建了编译器的转换和优化部分,抽象成结构化的编译器代码。LLVM Pass分为两种Analysis pass(分析流程)和Transformation pass(变换流程)。前者进行属性和优化空间相关的分析,同时产生后者需要的数据结构。两都都是LLVM编译流程,并且相互依赖。
由于 LLVM 良好的模块化,因此直接写一个优化遍来实现优化算法的方法是可行
的,也是相对容易的。编写pass的流程是:
1)挑选测试用例 foo.c 作为 LLVM 编译器的输入。
2)利用 clang 前端生成 LLVM 中间表示 foo.ll,通过 LLVM 后端的 CodeGen 生
成 Target 代码(Target 是目标平台)。命令是 clang -emit-llvm foo.c –S –o foo.ll,需要参考的文档可能包括 LLVM Command Guide。
3)生成目标平台的汇编代码,命令是 llc foo.ll –march=Target –o foo.s。
4)使用汇编器和链接器,将 foo.s 编译成平台可执行 exe 文件。执行测试程序的
执行时间。
5)用 profile 等性能分析工具对程序做 profiling,找出程序的热点,也就是程序
的性能瓶颈,看汇编中哪段代码耗时比较多,有可提升的空间。
6)在分析 foo.s 后,找出程序的缺陷,分析一般形式,提出改进后的目标代码
foo_opt.s。
7)找出与热点代码相对应的 IR,在对 IR 实现的基础上,结合改进的目标代码,写出改进后的 IR。这是最关键的一步,因为 IR 到目标代码之间还要进行很多的优化、转化,必须对程序以及 IR 进行足够的分析,才能知道什么样的 IR 可以生成期望的汇编代码。这需要参考一些 LLVM 的文档,包括 LLVM Language Reference Manual,
LLVM’s Analysis and Transform Passes。
8)编写 LLVM 转化pass,参考文档 LLVM Programmer’s Manual,LLVM Coding
Standards,Doxygen generated documentation,Writing an LLVMpass。
该过程在图 4.26 中给出。通过这些步骤就可以实现一个优化遍。该优化算法最重
要解决的问题就是如何使数组地址能够实现自增,以及在何处插入Phi结点。

图4.26 编写pass流程
常见的应用场景有代码混淆、单测代码覆盖率、代码静态分析等。
4.7.2编译过程
如图4.27所示表示Objective-C的编译流程。

图4.27 Objective-C的编译流程
这里“插桩”的思路就是利用OC编译过程中,使用自定义的Pass(这里使用的是transformation pass),来篡改IR文件。比如图4.28 所示的LLVM代码,如果不加入自定义的Pass(左图)与加入自定义的Pass(右图)编译出来的IR文件对比,可以看到两者在对应的基础块不同的地方。
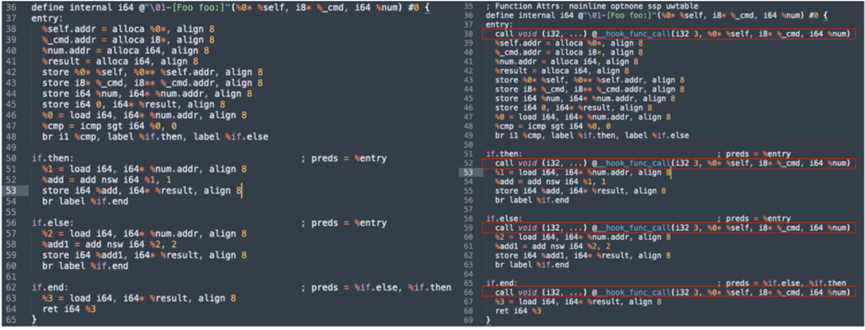
图4.28 函数插桩前后对比
4.8 LLVM IR文件的描述
LLVM IR(Intermediate Representation)直译过来是中间表示,它是连接编译器中前端和后端的桥梁,它使得LLVM可以解析多种源语言,并为多个目标机器生成代码。前端产生IR,而后端消费它。
4.8.1下载LLVM
苹果fork分支https://github.com/apple/llvm-project选择一个新apple/main那个分支即可。
clone下来之后,在编译之前,要实现想要的效果,需要处理两个问题:
4.8.2写自定义的Pass
1.编写插桩的代码
也就是llvmpass,这里主要是要插入代码,所以用的是transformationpass。
在llvm/include/llvm/Transforms/新增一个文件夹(InjectFuncCall),然后上面放着LLVM Pass的头文件声明
新建头文件:
namespace llvm {
class InjectFuncCallPass : public PassInfoMixin {
public:
/// 构造函数
/// AllowlistFiles 白名单
/// BlocklistFiles 黑名单
explicit InjectFuncCallPass(const std::vector &AllowlistFiles,const std::vector &BlocklistFiles) {
if (AllowlistFiles.size() > 0)
Allowlist = SpecialCaseList::createOrDie(AllowlistFiles, *vfs::getRealFileSystem());
if (BlocklistFiles.size() > 0)
Blocklist = SpecialCaseList::createOrDie(BlocklistFiles, *vfs::getRealFileSystem());
}
PreservedAnalyses run(Module &M, ModuleAnalysisManager &MAM);
bool runOnModule(llvm::Module &M);
private:
std::unique_ptr Allowlist;
std::unique_ptr Blocklist;
};
} // namespace llvm
在llvm/lib/Transforms新增一个文件夹(InjectFuncCall),然后上面放着对应的LLVM Pass的新建cpp文件:llvm/lib/Transforms/InjectFuncCall/InjectFuncCall.cpp
using namespace llvm;
bool InjectArgsFuncCallPass::runOnModule(Module &M) {
bool Inserted = false;
auto &CTX = M.getContext();
for (Function &F : M) {
if (F.empty())
continue;;
if (F.isDeclaration()) {
continue;
}
if (F.getLinkage() == GlobalValue::AvailableExternallyLinkage)
continue;
if (isa(F.getEntryBlock().getTerminator()))
continue;;
if (Allowlist && !Allowlist->inSection("Inject-Args-Stub", "fun", F.getName())) {
continue;
}
if (Blocklist && Blocklist->inSection("Inject-Args-Stub", "fun", F.getName())) {
continue;
}
IntegerType *IntTy = Type::getInt32Ty(CTX);
PointerType* PointerTy = PointerType::get(IntegerType::get(CTX, 8), 0);
FunctionType *FuncTy = FunctionType::get(Type::getVoidTy(CTX), IntTy, /*IsVarArgs=*/true);
FunctionCallee FuncCallee = M.getOrInsertFunction("__afp_capture_arguments", FuncTy); // 取到一个callee
for (auto &BB : F) {
SmallVector<value*, 16=""> CallArgs;
for (Argument &A : F.args()) {
CallArgs.push_back(&A);
}
Builder.CreateCall(FuncCallee, CallArgs);
}
Inserted = true;
}
return Inserted;
}
PreservedAnalyses InjectArgsFuncCallPass::run(Module &M,
ModuleAnalysisManager &MAM) {
bool Changed = runOnModule(M);
return (Changed ? llvm::PreservedAnalyses::none()
: llvm::PreservedAnalyses::all());
2. CMake相关声明和配置
llvm/utils/gn/secondary/llvm/lib/Transforms/InjectArgsFuncCall/BUILD.gn中需要添加以下声明,才会创建一个对应的静态库。
static_library("InjectFuncCall") {
output_name = "LLVMInjectFuncCall"
deps = [
"//llvm/lib/Analysis",
"//llvm/lib/IR",
"//llvm/lib/Support",
]
sources = [ "InjectFuncCall.cpp" ]
}
llvm/utils/gn/secondary/llvm/lib/Passes/BUILD.gn添加一行:“//llvm/lib/Transforms/InjectFuncCall”
"//llvm/lib/Transforms/Scalar",
"//llvm/lib/Transforms/Utils",
"//llvm/lib/Transforms/Vectorize",
"//llvm/lib/Transforms/InjectFuncCall",
]
sources = [
"PassBuilder.cpp",
llvm/lib/Transforms/CMakeLists.txt添加一行代码。cmake声明工程新增一个子目录。
add_subdirectory(ObjCARC)
add_subdirectory(Coroutines)
add_subdirectory(CFGuard)
add_subdirectory(InjectArgsFuncCall)
llvm/lib/Passes/CMakeLists.txt添加一行代码。声明Pass Build会链接InjectFuncCall COMPONENTS
add_llvm_component_library(LLVMPasses
PassBuilder.cpp
PassBuilderBindings.cpp
PassPlugin.cpp
StandardInstrumentations.cpp
ADDITIONAL_HEADER_DIRS
${LLVM_MAIN_INCLUDE_DIR}/llvm
${LLVM_MAIN_INCLUDE_DIR}/llvm/Passes
DEPENDS
intrinsics_gen
LINK_COMPONENTS
AggressiveInstCombine
Analysis
Core
Coroutines
InjectArgsFuncCall
IPO
InstCombine
ObjCARC
Scalar
Support
Target
TransformUtils
Vectorize
Instrumentation
)
4.8.3自定义Clang命令
如何让Clang识别到自定义的命令和根据需要,要加载对应的代码,需要修改以下模块。
在llvm-project/clang/include/clang/Driver/Options.td文件里面:
1. 添加命令到Driver
文件很长,一般加在sanitize相关的配置后面。搜索end-fno-sanitize* flags,往下一行插入。
// 开始自定义的命令到Driver
def inject_func_call_stub_EQ : Joined<["-","--"],"add-inject-func-call=">, Flags<[NoXarchOption]>,HelpText<"Add Inject Func Call">;
def inject_func_call_allowlist_EQ : Joined<["-","--"],"add-inject-allowlist=">, Flags<[NoXarchOption]>,HelpText<"Enable Inject Func Call From AllowList">;
def inject_func_call_blocklist_EQ : Joined<["-","--"],"add-inject-blocklist=">, Flags<[NoXarchOption]>,HelpText<"Disable Inject Func Call From BlockList">;
def inject_func_call : Flag<["-","--"],"add-inject-func-call">, Flags<[NoXarchOption]>, Alias, AliasArgs<["none"]>, HelpText<"[None] Add Inject Func Call.">;
// 结束自定义的命令到Driver
2. 添加命令到Fronted
//===----------------------------------------------------------------------===//
// 自定义插桩 Options
//===----------------------------------------------------------------------===//
def inject_func_call_type : Joined<["-"],"inject_func_call_type=">, HelpText<"CC1 add args stub [bb,func]">;
def inject_func_call_allowlist : Joined<["-"],"inject_func_call_allowlist=">, HelpText<"CC1 add args from allow list">;
def inject_func_call_blocklist : Joined<["-"],"inject_func_call_blocklist=">,
llvm-project/clang/lib/Driver/ToolChains/Clang.cpp
3.添加Driver到Fronted之间的命令链接
在ConstructJob函数里添加Driver到Fronted之间的命令链接。
void Clang::ConstructJob(Compilation &C, const JobAction &JA,const InputInfo &Output,
const InputInfoList &Inputs,const ArgList &Args,
const char *LinkingOutput) const {
...
...
const SanitizerArgs &Sanitize = TC.getSanitizerArgs();
Sanitize.addArgs(TC, Args, CmdArgs, InputType);
/// 添加Driver 到Fronted之间的命令的链接
if(const Arg *arg = Args.getLastArg(options::OPT_inject_func_call_stub_EQ)){
StringRef val = arg->getValue();
if (val != "none") {
CmdArgs.push_back(Args.MakeArgString("-inject_func_call_type=" + Twine(val)));
StringRef allowedFile = Args.getLastArgValue(options::OPT_inject_func_call_allowlist_EQ);
llvm::errs().write_escaped("Clang:allowedFile:") << allowedFile << '\\n';
CmdArgs.push_back(Args.MakeArgString("-inject_func_call_allowlist=" + Twine(allowedFile)));
StringRef blockFile = Args.getLastArgValue(options::OPT_inject_func_call_blocklist_EQ);
llvm::errs().write_escaped("Clang:blockFile:") << blockFile << '\\n';
CmdArgs.push_back(Args.MakeArgString("-inject_func_call_blocklist=" + Twine(blockFile)));
}
}
...
...
}
这文件/llvm-project/clang/lib/Frontend/CompilerInvocation.cpp中处理第四步。
4. 参数赋值给Option
把解析逻辑中,真正拿到clang传进来的参数赋值给Option,需要给Option新增几个变量。
在对应的文件/clang/include/clang/Basic/CodeGenOptions.h
/// type of inject func call std::string InjectFuncCallOption; /// inject func allow list std::vector InjectFuncCallAllowListFiles; /// inject func block list std::vector InjectFuncCallBlockListFiles;bool CompilerInvocation::ParseCodeGenArgs(CodeGenOptions &Opts, ArgList &Args, InputKind IK, DiagnosticsEngine &Diags, const llvm::Triple &T, const std::string &OutputFile, const LangOptions &LangOptsRef) {...for (const auto &Arg : Args.getAllArgValues(OPT_inject_args_stub_type)) { StringRef Val(Arg); Opts.InjectArgsOption = Args.MakeArgString(Val); } Opts.InjectArgsAllowListFiles = Args.getAllArgValues(OPT_inject_args_stub_allowlist); Opts.InjectArgsBlockListFiles = Args.getAllArgValues(OPT_inject_args_stub_blocklist);...}
5. 将自定义的Pass添加到Backend
在emit assembly的时机,判断Option,然后执行Model Pass管理器的添加Pass操作。
对应的文件/clang/lib/CodeGen/BackendUtil.cpp
#include "llvm/Transforms/InjectArgsFuncCall/InjectArgsFuncCall.h"
// 最后添加 Inject Args Functionpass。
if (CodeGenOpts.InjectArgsOption.size() > 0) {
MPM.addPass(InjectArgsFuncCallPass(CodeGenOpts.InjectArgsAllowListFiles, CodeGenOpts.InjectArgsBlockListFiles));
}
4.8.4重新编译llvm
上述的配置和代码都执行完后,接下来编译,编译的过程直接看github的readme,安装必要的工具cmake,najia等。
cd llvm-project
// 新建一个build文件夹来生成工程
mkdir build
cd build
// -G Xcode会cmake出来一个xcode工程,也可以选择ninja
cmake -DLLVM_ENABLE_PROJECTS=clang -G Xcode ../llvm
// 执行结束后,会在build文件夹生成完整的工程目录
目前LLVM,只能用Legacy Build系统。所以需要在文件→项目设置→构建系统里面切换一下。
4.8.5执行结果验证
1.生成IR文件调试效果
打开llvm的工程,选择clang的target,设置Clang的运行参数。
2.把上述的的路径替换成自己的路径
// 指定使用newpassmanager,llvm里面有两套写自定pass的接口,现在是使用新的接口。
-fexperimental-new-pass-manager
// 启动功能,以基础块级别地插入函数
-add-inject-func-call=bb
// 设置白名单,只有在白名单里面的文件/函数才会插桩
-add-inject-allowlist=$(SRCROOT)/config/allowlist.txt
// 设置黑名单,黑名单里指定的文件/函数会忽略掉
-add-inject-blocklist=$(SRCROOT)/config/blocklist.txt
3.白名单&黑名单
简单的格式:
#指定对应的section
[InjectFuncCallSection]
# 指定对应的文件
src:/OC-Hook-Demo/OC-Hook-Demo/Foo.m
# 指定对应的函数名,*号可支持模糊匹配
func:*foo*
白名单和黑名单是参考Clang Sanitizer配置文件的格式。
4.9 iOS前端编译器扩展——Clang
4.9.1了解Clang
众所周知,编译器一般分为前端和后端,编译器前端主要负责预处理、词法分析、语法分析、语法检查、生成中间代码等与底层计算机架构无关的工作。
后端以中间代码为输入,首先进行架构无关的代码优化,之后针对不同的机器架构生成不同的机器码,进行汇编链接。图4.29 所示表示LLVM编译器前后段流程。
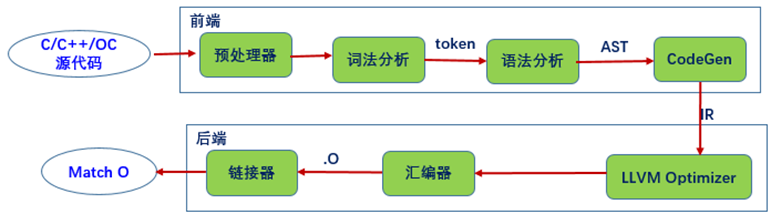
图4.29 LLVM编译器前后段流程
Clang在iOS代码编译中主要用于C/C++、Objective-C的前端编译工作,Clang属于llvm编译链的一部分,是llvm的前端编译器。可以通过Clang开放出来的API接口对源码进行自定义处理,如静态代码检查、编译流程控制、代码查找提示补全等功能。Clang工具针对的对象正是AST——语法分析的结果,即抽象语法树(abstract syntax tree)。
一个AST的简单例子:
`-FunctionDecl 0x7f9c93875ec0 </Users/zhoubinhan/Desktop/test.m:1:1, line:4:1> line:1:5 fun 'int (int, int)'
|-ParmVarDecl 0x7f9c93875d68 <col:9, col:13> col:13 used a 'int'
|-ParmVarDecl 0x7f9c93875de8 <col:16, col:20> col:20 used b 'int'
`-CompoundStmt 0x7f9c93876128 <col:23, line:4:1>
|-DeclStmt 0x7f9c938760c8 <line:2:3, col:16>
| `-VarDecl 0x7f9c93875fd0 <col:3, col:15> col:7 used c 'int' cinit
| `-BinaryOperator 0x7f9c938760a8 <col:11, col:15> 'int' '+'
| |-ImplicitCastExpr 0x7f9c93876078 <col:11> 'int' <LValueToRValue>
| | `-DeclRefExpr 0x7f9c93876038 <col:11> 'int' lvalue ParmVar 0x7f9c93875d68 'a' 'int'
| `-ImplicitCastExpr 0x7f9c93876090 <col:15> 'int' <LValueToRValue>
| `-DeclRefExpr 0x7f9c93876058 <col:15> 'int' lvalue ParmVar 0x7f9c93875de8 'b' 'int'
`-ReturnStmt 0x7f9c93876118 <line:3:3, col:10>
`-ImplicitCastExpr 0x7f9c93876100 <col:10> 'int' <LValueToRValue>
`-DeclRefExpr 0x7f9c938760e0 <col:10> 'int' lvalue Var 0x7f9c93875fd0 'c' 'int'
Clang工具可以遍历读取AST上的每一个节点,并对节点对应的代码进行查询、修改操作。Clang插件更能够直接集成进iOS的编译流程中,控制输出自定义的编译警告、错误,控制编译流程。
4.9.2 Clang的具体应用
在Clang的应用正在初步展开,使用libClang遍历项目中的每一个源文件,找到项目中所有关于图片名称的字符串描述,图片名称往往以固定字符串的形式出现,从而判断在工程中,哪些图片已经被使用而哪些已经没有在用了,进行包的大小优化。
使用Clang插件对已在工程中定义的却没有在工程中使用的类、方法进行告警提示。方法是:首先利用Clang插件的VisitObjCInterfaceDecl和VisitObjCMethodDecl方法找出工程中所有的类定义和方法定义,再利用VisitObjCMessageExpr和VisitObjCSelectorExpr找到所有的消息发送,在iOS中方法的调用是通过消息发送的形式进行的,对于那些没有在消息发送列表中出现的类和方法,认为这些类和方法未被使用,从而直接在编译的时候进行告警提示。将插件在编译器中集成即可使用。
4.10 Clang工具那些事
Clang主要用于C/C++、Objective-C的编译工作,在iOS中Clang属于llvm编译链的一部分,是llvm的前端编译器。可以通过Clang开放出来的API接口对Objective-C的代码进行自定义处理,如静态代码检查、编译流程控制、代码查找提示补全等功能。要想了解Clang,先得了解Objective-C编译。
4.10.1 ObjC编译流程
编译器一般分为前端和后端,编译器前端主要负责预处理、词法分析、语法分析、语法检查、生成中间代码等与底层计算机架构无关的工作。后端以中间代码为输入,首先进行架构无关的代码优化,之后针对不同的机器架构生成不同的机器码,进行汇编链接。如图4.30所示表示 Objective-C编译器前后段流程。

图4.30 Objective-C编译器前后段流程
1)预处理:预处理代码,宏替换、删除注释等。
2)词法分析:输入预处理好的源文件,生成词法单元token,同时记录位置信息。
3)语法分析:输入词法分析结果,解析生成抽象语法树(abstract syntax tree -- AST),Clang工具针对的处理对象正是AST。
4)静态分析:得到抽象语法树AST之后,编译器就可以对这个树进行静态分析处理。代码语法检查,为定义方法和未使用变量告警等,Clang工具可以在这个过程中添加自定义操作,增加代码提示或者错误、警告,插入代码。最后AST会生成架构无关的中间语言IR。
5)中间代码生成和优化:生成架构无关的中间语言IR,对代码进行优化。
6)生成汇编代码:llvm会将汇编码转为机器码,生成一个个.o文件。
7)链接:把生成的.o文件和静态库等文件,合成一个mach-o文件。
4.10.2 什么是Clang AST
通过上面的编译流程的描述可知,Clang工具操作的时机是在编译前端生成抽象语法树AST之后,操作对象是AST。那么什么是AST呢?通过命令关键字-ast-dump,即clang -Xclang -ast-dump -fsyntax-only (文件名) ,可以得到某个文件的Clang AST,举个例子:
// test.m源码:
int fun(int a, int b) {
int c = a + b;
return c;
}
生成语法树:
TranslationUnitDecl 0x7f9c9383ba08 <<invalid sloc>> <invalid sloc>
|-TypedefDecl 0x7f9c9383c2a0 <<invalid sloc>> <invalid sloc> implicit __int128_t '__int128'
| `-BuiltinType 0x7f9c9383bfa0 '__int128'
|-TypedefDecl 0x7f9c9383c310 <<invalid sloc>> <invalid sloc> implicit __uint128_t 'unsigned __int128'
| `-BuiltinType 0x7f9c9383bfc0 'unsigned __int128'
|-TypedefDecl 0x7f9c9383c3b0 <<invalid sloc>> <invalid sloc> implicit SEL 'SEL *'
| `-PointerType 0x7f9c9383c370 'SEL *'
| `-BuiltinType 0x7f9c9383c200 'SEL'
|-TypedefDecl 0x7f9c9383c498 <<invalid sloc>> <invalid sloc> implicit id 'id'
| `-ObjCObjectPointerType 0x7f9c9383c440 'id'
| `-ObjCObjectType 0x7f9c9383c410 'id'
|-TypedefDecl 0x7f9c9383c578 <<invalid sloc>> <invalid sloc> implicit Class 'Class'
| `-ObjCObjectPointerType 0x7f9c9383c520 'Class'
| `-ObjCObjectType 0x7f9c9383c4f0 'Class'
|-ObjCInterfaceDecl 0x7f9c9383c5d0 <<invalid sloc>> <invalid sloc> implicit Protocol
|-TypedefDecl 0x7f9c9383c928 <<invalid sloc>> <invalid sloc> implicit __NSConstantString 'struct __NSConstantString_tag'
| `-RecordType 0x7f9c9383c700 'struct __NSConstantString_tag'
| `-Record 0x7f9c9383c680 '__NSConstantString_tag'
|-TypedefDecl 0x7f9c93875a00 <<invalid sloc>> <invalid sloc> implicit __builtin_ms_va_list 'char *'
| `-PointerType 0x7f9c9383c980 'char *'
| `-BuiltinType 0x7f9c9383baa0 'char'
|-TypedefDecl 0x7f9c93875cf8 <<invalid sloc>> <invalid sloc> implicit __builtin_va_list 'struct __va_list_tag [1]'
| `-ConstantArrayType 0x7f9c93875ca0 'struct __va_list_tag [1]' 1
| `-RecordType 0x7f9c93875ae0 'struct __va_list_tag'
| `-Record 0x7f9c93875a58 '__va_list_tag'
`-FunctionDecl 0x7f9c93875ec0 </Users/xxx/Desktop/test.m:1:1, line:4:1> line:1:5 fun 'int (int, int)'
|-ParmVarDecl 0x7f9c93875d68 <col:9, col:13> col:13 used a 'int'
|-ParmVarDecl 0x7f9c93875de8 <col:16, col:20> col:20 used b 'int'
`-CompoundStmt 0x7f9c93876128 <col:23, line:4:1>
|-DeclStmt 0x7f9c938760c8 <line:2:3, col:16>
| `-VarDecl 0x7f9c93875fd0 <col:3, col:15> col:7 used c 'int' cinit
| `-BinaryOperator 0x7f9c938760a8 <col:11, col:15> 'int' '+'
| |-ImplicitCastExpr 0x7f9c93876078 <col:11> 'int' <LValueToRValue>
| | `-DeclRefExpr 0x7f9c93876038 <col:11> 'int' lvalue ParmVar 0x7f9c93875d68 'a' 'int'
| `-ImplicitCastExpr 0x7f9c93876090 <col:15> 'int' <LValueToRValue>
| `-DeclRefExpr 0x7f9c93876058 <col:15> 'int' lvalue ParmVar 0x7f9c93875de8 'b' 'int'
`-ReturnStmt 0x7f9c93876118 <line:3:3, col:10>
`-ImplicitCastExpr 0x7f9c93876100 <col:10> 'int' <LValueToRValue>
`-DeclRefExpr 0x7f9c938760e0 <col:10> 'int' lvalue Var 0x7f9c93875fd0 'c' 'int'
最上层声明一直都是编译单元 declaration(翻译单元声明),在这个例子中,前面定义了一堆的TypedefDecl类型描述,由于编译的是.m即OC源代码,系统事先插入了其他代码,暂时忽略。在源码里只定义了一个函数,可以看到这一行:`-FunctionDecl 0x7f9c93875ec0 </Users/xxx/Desktop/test.m:1:1, line:4:1> line:1:5 fun 'int (int, int)' 定义了函数,FunctionDecl标识这是个函数,</Users/xxx/Desktop/test.m:1:1, line:4:1> line:1:5描述了函数在源文件中的位置。接下来包含了两个ParmVarDecl参数声明和CompoundStmt混合声明(函数体和返回值),DeclStmt描述函数体,ReturnStmt描述函数返回值。
4.11 理解 Clang Module 和 Module Map 语法
Clang Module 是大概 2013 年左右出现的,它的出现是为了解决传统基于 C 语言的编程语言的头文件包含的弊端。也是现代 Apple 平台软件开发一定会用到的一个技术,了解 Clang Module 对组织代码结构,理解 Xcode 编译流程,优化编译速度,定位编译错误等都会有帮助。
4.11.1传统头文件包含的弊端
传统的头文件包含,存在以下几个主要的问题:
1.编译性能问题
对于传统头文件包含,预处理器会将头文件的内容复制粘贴过来替换 #include 预处理指令。而很多头文件内都会包含相同的其它头文件,例如底层依赖,系统库等,这样造成了不同的源文件中会出现重复的内容。也就是说,对于 M 个源文件,如果有 N 个头文件,复杂度量级是 M x N 的,编译器会对每个重复的内容都进行一次文本分析,做了大量重复的工作,拖慢了编译时间。
例如系统的 Foundation 框架,框架内嵌套包含了 800 个以上的其它头文件,整个框架的大小在 9MB 以上,作为最基础的框架,几乎每个源文件都会包含 Foundation.h。对于传统的头文件包含,Foundation.h 的内容及其包含的其它头文件会被不断地重复进行词法分析语义分析,拖慢编译速度。
2.脆弱性
脆弱性是因为 #include 替换得到的内容会受到其它预处理指令的影响。例如头文件中有某个符号 XXX,如果在包含这个头文件之前,存在类似 #define XXX "other text" 这样的宏定义,就会导致头文件中的所有 XXX 都被替换为 "other text",从而导致编译错误。
#define XXX "other text"
#include "XXX.h
3.使用惯例方案解决问题
传统的头文件包含无法解决头文件重复包含的问题,因此大家都用一种惯例来避免重复包含。
#ifndef __XXXX_H__
#define __XXXX_H__
// 头文件内容
#endif
"
虽然现代开发工具都能自动生成这些信息,但还是存在一定的不便。
此外,为了解决宏在多个库之间重名的问题,大家都会把宏的名称起的很长,增加了前缀和后缀。
4.对工具的迷惑性
在 C 语言为基础的语言中,软件库的边界不是很清晰,比如很难辨别一个头文件到底是哪个语言的,因为 C、C++、Objective-C 等语言的头文件都是 .h。也很难弄清楚一个头文件到底是属于哪个库的。这对于开发基于这些软件库的工具带来了一定的难度。
4.11.2 Clang Module 能解决什么问题?
1. 语义导入
Clang Module 从传统头文件包含的文本导入改进成了更健壮,效率更高的语义导入。当编译器看到一个 Module 导入指令时,编译器会去加载一个二进制文件,这个二进制文件提供了这个模块所有 API 的信息,这些 API 可以直接给其它代码使用。
2. 编译性能提升
Clang Module 提升了编译性能,每个模块只需要编译一次,然后会生成一个模块的二进制表示(.pcm,预编译模块),并缓存到磁盘上。下次遇到 import 这个模块时,编译器不需要再次编译 Module,而是直接读取这个缓存的二进制表示即可。
3. 上下文无关
Clang Module 解决了脆弱性的问题,每个 Module 都是一个独立的实体,会被隔离地、独立的编译,是上下文无关的。当 import 模块时,会忽略 import 上下文的其它的预处理指令,这样 import 之前的预处理指令不会对模块导入产生任何影响。
每个模块都是一个自包含的个体,他们上下文无关,相互隔离,因此不再需要使用一些惯例方法来避免出现一些问题,因为这些问题已经不会出现了。
4. 制作一个模块
为了能有一个直观的了解,可以自己动手制作一个模块。用 Xcode 创建一个新的 iOS app 工程作为测试使用。然后在工程根目录下新建一个 group 命名为 Frameworks。
在命令行中进入 Frameworks 文件夹,新建一个 Dog.framework 文件夹,名字可以随意,这里是随便起的。
mkdir Dog.framework
然后回到 Xcode 中,在 Frameworks 目录上右击鼠标,选择 Adds files to ... 把 Dog.framework 添加到 Frameworks 目录内。此时编译会报错 Framework not found Dog,接下来看看怎样制作出一个 Xcode 能正确识别并编译的模块。
在 Dog.framework 中新建 Dog.swift 文件并添加以下内容:
public class Dog: NSObject {
public func bark() {
print("bark")
}
@objc func objcBark() {
print("objc bark")
}
}
接下来来为这个 framework 生成接口文件。在命令行中执行以下命令:
swiftc -module-name Dog -c Dog.swift -target arm64-apple-ios16.2-simulator -sdk /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator16.2.sdk -emit-module -emit-objc-header -emit-objc-header-path Dog-Swift.h
swiftc 是 Swift 语言的编译器,它底层也调用了 clang。下面对参数一一进行说明:
1)-module-name Dog 模块的名称,可以通过 import + 这个名称来引入模块。
2)-c Dog.swift 指定要编译的源文件。
3) -target arm64-apple-ios16.2-simulator 指定生成目标的架构。
4) -sdk /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator16.2.sdk 指定要链接进来的 SDK,这里使用的是 iOS 16.2 的模拟器版本。
5) -emit-module 会生成一个 .swiftdoc 文件和一个 .swiftmodule 文件。
6) -emit-objc-header 生成 Objective-C 头文件,仅包含被标记为 @objc 的符号。
7)-emit-objc-header-path 指定 Objective-C 头文件的路径,这里遵循了 Xcode 的惯例,使用 ”模块名+Swift.h“ 来命名。
虽然需要的文件已经生成了,但是并不是 Xcode 支持的 module 目录结构,无法被 Xcode 读取。可以通过观察 Xcode 创建的 Framework 来了解这种结构,来创建正确的结构。
在 Dog.framework 文件夹中创建 Headers 文件夹,然后把 Dog-Swift.h 移动到 Headers 文件夹中。在 Dog.framework 文件夹中再创建一个 Modules 文件夹,然后在 Modules 文件夹中创建 Dog.swiftmodule 文件夹,把 Dog.swiftdoc 和 Dog.swiftmodule 转移到 Dog.swiftmodule 文件夹中。最后把这两个文件重命名为 arm64.swiftdoc 和 arm64.swiftmodule。
当前 Dog.framework 的目录结构为:
Dog.framework/
|---- Dog
|---- Headers
| |---- Dog-Swift.h
|---- Modules
|---- Dog.swiftmodule
|---- arm64.swiftdoc
|---- arm64.swiftmodule
现在接口已经有了,但是还没有二进制库文件,依然无法编译通过,下面来生成二进制库文件。
执行以下命令:
swiftc -module-name Dog -parse-as-library -c Dog.swift -target arm64-apple-ios16.2-simulator -sdk /Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator16.2.sdk -emit-object
这个命令中有很多参数跟上一个命令是一样的,下面是上个命令中没有包括的参数。
1) -parse-as-library 让编译器把文件解释为一个库,而不是一个可执行文件。
2) -emit-object 输出目标文件。
这个命令执行完以后会生成 Dog.o 这个目标文件,然后需要把目标文件归档为库。
libtool -static Dog.o -arch_only arm64 -o Dog
这里为了简化流程选择了创建静态库,而不是动态链接库,因此使用 -static。这时在 Dog.framework 中会出现 Dog 这个二进制静态库文件。此时在 ViewController 中 import Dog 然后编译工程,就能编译通过了。说明当前这种目录结构可以让 Xcode 正确找到模块所需文件。
Module map
接下来,试一试用 Objective-C 来调用 Dog 模块会怎样。
在上面的工程中再创建一个 Objective-C 类,命名为 OCObject,并让 Xcode 自动创建头文件桥接文件,并添加以下代码:
// Dog.swift
import Foundation
// OCObject.h
@interface OCObject : NSObject
- (void)doSomething;
@end
// OCObject.m
#import "OCObject.h"
#import <Dog/Dog-Swift.h>
@implementation OCObject
- (void)doSomething {
Dog *dog = [[Dog alloc] init];
[dog objcBark];
}
@end
会发现此时是可以打印出 objc mark 的。然后把 #import <Dog/Dog-Swift.h> 替换成标准的模块导入语法 @import Dog,编译却报错了,提示 ”Module 'Dog' not found“。
这时因为 framework 中缺少了一个重要的 modulemap 文件,Xcode 就无法找到模块。#import <Dog/Dog-Swift.h> 之所以有效是因为它本身是一个向前兼容的语句,如果 framework 支持模块,则导入模块,如果 framework 不支持模块,它会像 #include 一样去搜索路径中找到这个头文件,直接把文本内容粘贴到这里。
Module map 指明了 framework 中的头文件逻辑结构应该如何映射为模块。参考用 Xcode 创建 framework 时自动创建的 module map 文件,会发现在 Modules 文件夹下有一个 module.modulemap 文件,其内容如下:
framework module ObserveModuleStructure {
umbrella header "ObserveModuleStructure.h"
export *
module * { export * }
}
module ObserveModuleStructure.Swift {
header "ObserveModuleStructure-Swift.h"
requires objc
}
通过参考 clang 的文档,来对这个语法一一进行说明:
1) framework module XXXX 定义了一个 framework 语义的模块。
2)umbrella header "XXXX.h" 说明把 XXXX.h 文件作为模块的 unbrella header,伞头文件相当于模块中所有公共头文件的一个集合,方便使用者导入。
1)export * 将所有子模块中的符号进行重导出到主模块中。
2)module * { export * } 定义子模块,这里为 * 是为 umbrella header 中的每个头文件都创建一个子模块。
根据这个语法编写自己的 module map 文件:
Dog.framework/Modules/module.modulemap:
// Dog.framework/Modules/module.modulemap
framework module Dog {
umbrella header "Dog.h"
export *
module * { export * }
}
module Dog.Swift {
header "Dog-Swift.h"
requires objc
}
此时依然编译报错,还需要一个 unbrella header 文件,创建一个 Dog.h 文件放到 Dog.framework/Headers/ 中,内容为空即可。然后就可以编译通过,打印出 bark objc。
4.11.3 Module Map 语言语法
官方把这种语法叫做模块映射语言(Module Map Language)。
根据 Clang 的文档,模块映射语言在 Clang 的大版本之间可能不会保持稳定,因此在平常的开发中,让 Xcode 去自动生成就好。
1. 模块声明
[framework] module module-id [extern_c] [system] {
module-member
}
framework
framework 代表这个模块是是一个 Darwin 风格的 framework。Darwin 风格的 framework 主要出现在 macOS 和 iOS 操作系统中,它的全部内容都包含在一个 Name.framework 文件夹中,这个 Name 就是 framework 的名字,这个文件夹的内容布局如下:
Name.framework/
Modules/module.modulemap framework 的模块映射
Headers/ 包含了 framework 中的头文件
PrivateHeaders/ 包含了 framework 中私有的头文件
Frameworks/ 包含嵌入的其它 framework
Resources/ 包含额外的资源
Name 指向共享库的符号链接
system
system 指定了这个模块是一个系统模块。当一个系统模块被重编译后,模块的所有头文件都会被当做系统头文件,这样一些警告就不会出现。这和在头文件中放置 #pragma GCC system_header 等效。
extern_c
extern_c 指明了模块中包含的 C 代码可以被 C++ 使用。当这个模块被编译用来给 C++ 调用时,所有模块中的头文件都会被包含在一个隐含的 extern "C" 代码块中。
2. 模块体
模块体包含了 header、requires 等常见的声明和子模块声明,例如:
framework module Dog {
umbrella header "Dog.h"
requires objc
module * { export * }
}
header
header 指定了要把哪些头文件映射为模块。umbrella header 则是指定了综合性伞头文件。
requires
requires 声明指定了导入这个模块的编译单元需要满足的条件。这个条件有语言、平台、编译环境和目标特定功能等。例如 requires cplusplus11 表示模块需要在支持 C++11 的环境中使用,requires objc 表示模块需要在支持 Objective-C 语言的环境中使用。
module
module 用来声明模块中的子模块,如果是 module * 则代表模块中的每个头文件都会作为一个子模块。
3. 子模块声明
在主模块的模块体中嵌套地声明模块就是子模块。例如在 MyLib 模块中声明一个子模块 A,写法如下:
module MyLib {
module A {
header "A.h"
export *
}
}
explicit
explicit 修饰符是用来修饰子模块的。如果想使用被 explicit 修饰的子模块,必须在 import 时指定子模块的名字,像这样 import modulename.submodulename,或者这个子模块已经被其它已导入的模块重新导出过。
export
export 指定了将哪个模块的 API 进行重新导出,成为 export 所在的模块的 API。
export_as
export_as 将当前模块的 API 通过另一个指定的模块导出。
module MyFrameworkCore {
export_as MyFramework
}
上面的例子中,MyFrameworkCore 中的 API 将通过 MyFramework 导出。
模块映射语言还包含很多其它的声明语句,例如 use、config_macrs、link、conflict等。
4.11.4 Clang Module 的缓存机制
Clang 可以通过读取 modulemap 文件的内容,将 modulemap 中指定的模块编译成预编译模块(Precompiled Module),后缀名是 .pcm。
clang -cc1 -emit-obj use.c -fmodules -fimplicit-module-maps -fmodules-cache-path=prebuilt -fdisable-module-hash
上面的命令通过指定参数 implicit-module-maps,让编译器根据一定的规则自己去查找 modulemap 文件,通过指定参数 modules-cache-path,告诉编译器预编译模块的缓存路径。Clang 会根据 modulemap 中的信息编译各个模块,将生成的 .pcm 文件放到 prebuilt 目录下。
.pcm 文件以一种编译器可以轻松读取并解析的格式,保存了模块的信息,之后编译器在编译其它模块时,如果遇到了需要依赖这个模块,则可以快速的从 .pcm 中读取模块信息,而不需要重新编译模块。
4.11.5在 Xcode 中使用 Clang Module
用 Xcode 创建的框架或库都是默认开启 Clang Module 支持的,也就是在 Build Settings 中,Defines Module 的设置为 YES。如果是很老的库可能没有开启,手动把 Defines Module 设置为 YES 即可。
当 Defines Modules 是 YES 时,Xcode 在编译工程时会给 clang 命令增加 -fmodules 等模块相关参数,开启模块支持。
如表4.2所示,开发工具都隐藏了很多底层的细节,了解这些细节,可以帮助了解底层的原理,分析并解决一些棘手的问题。Clang 是 Apple 平台上重要的工具,值得去研究探索。

表4.2隐藏了很多底层的细节的开发工具
如此丰富多样的技术栈为软件提供商带来了的挑战:如何快速覆盖这些系统/技术栈以满足不同背景的用户的需求?
以网易云信IM 为例,它的研发流程大致如图4.31所示:

图4.31网易云信IM开发示例
随着业务发展,网易云信IM 的 API 越来越多(有几百个),为适配其他平台,需要投入大量的时间来编写语言绑定,这部分工作冗杂、耗时、且重复性极大;在维护阶段,对 C++ 接口的修改都需要同步到各个语言绑定中,稍有遗漏则会导致问题。为提高生产力和研发效率,将从重复且繁重的体力活中解放出来,让其更专注于重要功能的研发,网易云信的大前端研发了基于 clang 的源到源转译工具 NeCodeGen,本节将对 NeCodeGen 进行介绍,以便为面临相同问题的提供解决问题的方法与思路。
4.11.6为什么要重造轮子?
网易云信团队对语言绑定有很多灵活的自定义需求:
1)从实现层面:需要能够自定义命名风格、方法实现细节、业务逻辑的封装等;
2)从接口易用性、友好性的角度:作为软件提供商,需要保证 API 简单易用,且符合语言的最佳实践;
调研了当前比较流行的同类工具后,发现它们在自定义代码生成上的支持不够,用户很难对生成的代码进行控制,无法满足上面提及的需求。结合自身需求研发了 NeCodeGen,通过代码模板给予使用者对生成的代码完全的控制,使之成为一个通用的、灵活的工具。
当前开源世界中存在很多非常优秀的自动化生成语言绑定工具,比如强大的 SWIG、dart ffigen 等,NeCodeGen 的主要目标是满足灵活的自定义需求,能够作为现有工具集的一个补充。常常将它和其他代码生成工具结合使用来提升研发效率,如图4.32所示是云信的一个应用场景:

图4.32 云信的一个应用场景
由于 dart ffigen 只支持 C 接口,因此首先使用 NeCodeGen 开发生成 C API 和对应的 C 实现的应用程序,然后使用 dart ffigen 由 C API 来生成的 dart binding,由于 dart ffigen 生成的 dart binding 大量使用 dart ffi 中的类型,它无法满足易用性、友好性需求(上图中将称为低级dart binding)。还需要基于它进一步进行封装,再次使用 NeCodeGen 生成更加友好易用的高级dart binding,在实现上依赖低级dart binding。
4.11.7 NeCodeGen 简介
NeCodeGen 是一个代码生成框架,它以 Python package 的方式发布,可以基于它来开发自己的应用,它的目的是简化具有相同需求的用户的开发成本,提供解决这类问题的最佳工程实践,具备如下特性:
1)使用灵活: 内置模板引擎 yyy,让使用 yyy 模板语言来灵活的描述代码模板;
2)支持从 C++ 同时生成多种目标语言程序,便于同时管理多种目标语言程序,这一点和 SWIG 类似;
3)提供最佳工程实践;
4)充分利用 Python 的语法糖;
在实现上 NeCodeGen 使用 Python3 作为开发语言,使用 Libclang 作为 compiler front end,使用 yyy 作为模板引擎,它借鉴了:
1)在 Python 中非常流行的 web 框架 Flask;
2)clang 的 LibASTMatchers 和 LibTooling;
3)SWIG;
下文将对 NeCodeGen 的各个部分进行更加详细的介绍。
4.11.8 clang 的简介
clang 是 LLVM project 的 C 系语言编译器前端,它支持的语言包括: C、C++、Objective C/C++ 等。clang 采用的是Library Based Architecture(基于 library 的架构),这意味着它的各个功能模块会以独立的库的方式实现,可以直接使用这些功能,并且 clang 的 AST 能够完整的反映源码的信息。clang 的这些特性有助于开发一些工具,典型的例子就是 clang-format。在调研后选择使用 clang 来作为 NeCodeGen 的 前端。
4.11.9工欲善其事,必先利其器: 学习 clang AST
先做一些准备工作: 学习 clang AST,这是使用它来实现源到源转译工具的前提,如果已经掌握了 clang AST,可以跳过本段。clang AST 比较庞杂,从根本上来说这是源于 C++ 语言的复杂性,本节使用 Libclang 的 Python binding 带领读者以实践探索的方式学习 clang AST。
首先需要安装 Libclang 的 Python绑定,命令如下:
pip install libclang
为便于演示,不将 C++ code 保存到文件中,而是通过字符串的方式传入到 Libclang 中进行编译,完整程序如下:
import clang.cindex
code = """#include
<string>/// test function
int fooFunc()
{
return 1;
}
/// test class
class FooClass{
int m1 = 0;
std::string m2 =
"hello";
int fooMethod(){
return 1;
}
};
int main()
{
fooFunc();
FooStruct foo1;
FooClass foo2;
}
""" # C++源代码
index = clang.cindex.Index.create() # 创建编译器对象
translation_unit = index.parse(path='test.cpp',
unsaved_files=[('test.cpp', code)], args=['-std=c++11'])
#
index.parse 函数编译 C++ code,参数 args 表示编译参数。
编译单元
index.parse 函数的返回值类型为
clang.cindex.TranslationUnit(转换单元),可以使用 Python 的 type 函数进行验证:
type(translation_unit) Out[6]: clang.cindex.TranslationUnit
查看include
for i in
translation_unit.get_includes(): print(i.include.name)
通过调用 get_includes() 可以查看编译单元所包含的所有的头文件。如果读者实际进行执行的话,会发现它实际包含的头文件不止 <string>,这是因为头文件 <string> 会包含其他头文件,而这些头文件还会包好其他的头文件,compiler 需要逐个包含。
get_children
clang.cindex.TranslationUnit 的 cursor 属性表示它的 AST,来验证一下它的类型:
type(translation_unit.cursor) Out[9]: clang.cindex.Cursor
从输出可以看出,它的类型是 clang.cindex.Cursor;它的成员方法 get_children() 可以返回它的直接子节点:
for child in
translation_unit.cursor.get_children():
print(f'{child.location}, {child.kind}, {child.spelling}')
输出摘要如下:
......<SourceLocation file 'D:\\Program Files (x86)\\Microsoft Visual
Studio\\2019\\Community\\VC\\Tools\\MSVC\\14.29.30133\\include\\string',
line 24, column 1>,
CursorKind.NAMESPACE, std<SourceLocation file 'test.cpp',
line 4, column 5>,
CursorKind.FUNCTION_DECL, fooFunc<SourceLocation file 'test.cpp', line 8,
column 7>, CursorKind.CLASS_DECL,
FooClass
"......"表示省略了部分输出内容;仔细观察最后四行,它们是文件 test.cpp 中的内容,能够和源代码正确地匹配,这也验证了前面提及的:"clang AST 能够完整的反映源码的信息"。
DECL 是“declaration”的缩写,表示“声明”。
walk_preorder
clang.cindex.Cursor 的 walk_preorder 方法对 AST 进行先序遍历:
children =
list(translation_unit.cursor.get_children()) foo_class_node = children[-2] # 选取 class
FooClass 的节点树for child in
foo_class_node.walk_preorder(): # 先序遍历 print(f'{child.location}, {child.kind}, {child.spelling}')
上述对 class FooClass 对应的 AST 进行先序遍历,输出如下:
<SourceLocation file 'test.cpp', line 8,
column 7>, CursorKind.CLASS_DECL,
FooClass<SourceLocation file 'test.cpp',
line 9, column 9>,
CursorKind.FIELD_DECL, m1<SourceLocation file 'test.cpp',
line 9, column 14>,
CursorKind.INTEGER_LITERAL, <SourceLocation file 'test.cpp',
line 10, column 17>,
CursorKind.FIELD_DECL, m2<SourceLocation file 'test.cpp',
line 10, column 5>,
CursorKind.NAMESPACE_REF, std<SourceLocation file 'test.cpp',
line 10, column 10>,
CursorKind.TYPE_REF, std::string<SourceLocation
file 'test.cpp', line 11, column 9>,
CursorKind.CXX_METHOD, fooMethod<SourceLocation file 'test.cpp', line 11, column 20>, CursorKind.COMPOUND_STMT,
<SourceLocation file 'test.cpp', line 12, column 9>,
CursorKind.RETURN_STMT, <SourceLocation file 'test.cpp',
line 12, column 16>,
CursorKind.INTEGER_LITERAL,
请自行将上述输出和源代码进行对比。
AST node:
clang.cindex.Cursor
对于 clang.cindex.Cursor,下面是它非常重要的成员:
1)kind,类型是 clang.cindex.CursorKind;
2)type,类型是 clang.cindex.Type,通过它可以获得类型信息;
3)spelling,它表示节点的名称。
4.11.10 模板引擎简介
由于后面的例子中会使用 yyy,故先对它进行简单介绍。不需要有学习新事物的惶恐,因为 yyy 非常简单易学,模板并不是什么新概念,熟悉模板元编程的读者对于模板应该不会陌生,并且 yyy 的模板语言和 Python 基本相同,因此并不会引入太多新的概念,一些 yyy 中的概念其实完全可以使用熟知的概念来进行类比。
下面是一个简单的 yyy 模板和渲染模板的程序:
from typing import List
from jinja2 import Environment,
BaseLoader
jinja_env =
Environment(loader=BaseLoader)
view_template =
jinja_env.from_string(
'I am {{m.name}}, I am familiar with {%-
for itor in m.languages %} {{itor}}, {%- endfor %}') # jinja模板
class ProgrammerModel:
"""
model
"""
def __init__(self):
self.name = '' # 姓名
self.languages: List[str] = [] # 掌握的语言
def controller():
xiao_ming = ProgrammerModel()
xiao_ming.name = 'Xiao Ming'
xiao_ming.languages.append('Python')
xiao_ming.languages.append('Cpp')
xiao_ming.languages.append('C')
print(view_template.render(m=xiao_ming))
if __name__ == '__main__':
controller()
上面程序定义了一个简单的软件自介绍的模板 view_template,然后对其进行渲染,从而得到完整的内容,运行程序,它的输出如下:
yyy template variable 其实就是 "模板参数"
仔细对比 view_template 和最终的输出,可以发现其中使用 {{ }} 括号的部分会被替换,它就是 yyy template variable,即“模板参数”,它的语法为: {{template variable}}。
1)MVC 设计模式
在上面的程序中,其实使用了 MVC 设计模式如表4.3所示:

表4.3 MVC设计模式
在后面的程序中,还会继续使用这种设计模式,NeCodeGen 非常推荐使用这种设计模式来构建应用,在后面有专门的内容对 MVC 设计模式进行介绍。
2)yyy render 其实很像是“替换”
view_template.render(m=xiao_ming) 即是对模板进行渲染,这个过程可以简单的理解为替换,即使用变量 xiao_ming 对模板参数 m 进行替换,如果使用函数参数来进行类比的话,变量 xiao_ming 是实参。
4.11.11 抽象和代码模板
当程序中出现重复代码的时候,最先想到的是泛型编程、元编程、注解等编程技巧,它们能够帮助简化代码,但不同的编程语言的抽象能力不同,并且对于一些编程任务上述编程技巧也无济于事。这些都导致了不可避免地去重复写相同模式的代码,这种问题在实现 language binding 中尤其突出。
对于这类问题,NeCodeGen
给出的解法是:
1)对于重复的代码,需要抽象出它们的通用模式(代码模板),然后使用 template language 来描述代码模板,在 NeCodeGen 中,使用的 template language 是 yyy;
2)NeCodeGen
会编译源程序文件并生成 AST,需要从 AST 中提取必要的数据,然后执行转换,然后将转换后的数据作为代码模板中模板参数的实参,完成了代码模板的渲染,从而得到了目标代码。
下面就结合简单的例子来对对上述解法进行更加具体的说明,在这个例子中,需要将 C++ 中的 struct 在
TypeScript 中进行等价的定义,为清晰起见,下面以表格的形式展示了一个具体的例子:
// C++
struct NIN_AuthInfo {
std::string
appKey;
std::string
accid;
int token;
};
// TypeScrip
export interface NIM_AuthInfo {
appKey: string,
accid: string,
token: intger
}
现在需要考虑如何让程序自动化地帮完成这个任务。显然通过 clang,可以得到 struct NIM_AuthInfo 的 AST,还需要考虑如下问题:
1)C++ 类型和 TypeScript 类型的对应关系?
std::string ->
string,int
-> integer
2)C++ 中 struct 在 TypeScript 中如何进行命名?
为简单起见,让 TypeScript 中的名称和 C++ 的保持一致。
3)TypeScript 中使用什么语法来描述类似于 C++struct?
使用的 TypeScript interface 来进行描述,可以使用 yyy 写出通用的代码模板来进行描述。
下面给出具体的实现。按照前面的 MVC 内容提出的思想,可以首先建立 struct 的数据建模:
class
StructModel:
def __init__(self):
self.src_name = '' # 源语言中的名称
self.des_name = '' # 目标语言的名称
self.fields: List[StructFieldModel] =
[] # 结构体的字段
class
StructFieldModel:
def __init__(self):
self.src_name = '' # 源语言中的名称
self.des_name = '' # 目标语言的名称
self.to_type_name = '' # 目标语言的类型名称
然后写出 TypeScript 的代码模板,这个代码模板是基于 StructModel 来写的:
export interface {{m.des_name}}
{
{% for itor in m.fields %}
{{itor.des_name}} :
{{itor.to_type_name}} ,
{% endfor %}
}
接下来的工作就是从 C++ struct AST 中提取关键数据并进行必要的转换:
def controller(struct_node:
clang.cindex.Cursor, model: StructModel) -> str:
model.src_name = model.des_name =
struct_node.spelling # 提取struct的name
for field_node in
struct_node.get_children():
field_model = StructFieldModel()
field_model.src_name = field_model.des_name
= field_node.spelling # 提取字段的name
field_model.to_type_name =
map_type(field_node.type.spelling) # 执行类型映射
model.fields.append(field_model)
return view_template.render(m=model) # 渲染模板,得到TypeScript代码
4.11.12从源语言到目标语言的转译
将由源语言编写的程序转译为目标语言的程序时,主要涉及如下三个方面的转换:
1)类型转换 type
mapping
从源语言中的类型到目标语言中的类型的转换。在 NeCodeGen 中对 C++ 语言的内置类型和 C++ 标准库类型,进行了枚举并给出了预定义,对于这部分类型的转换,使用 hash
map 建立映射关系;对于用户自定义类型,NeCodeGen 无法给出预定义,则需要自行定义。
2)命名转换 name
mapping
不同语言的命名规范不同,因此需要考虑命名转换。如果源程序遵循统一的命名规范,那么使用正则表达式能够方便地进行命名的转换,这样能够保证生成的程序的严格的遵循用户设置的命名规范,这也体现了自动化代码生成工具的优势:程序对命名规范的遵守比更加严格。
3)语法转换 syntax
mapping
在NeCodeGen
中,语法转换主要是通过代码模板完成的,需要按照目标语言的语法来编写代码模板,然后通过渲染即可得到符合目标语言语法的程序。
4.11.13 NeCodeGen 的设计模式
已经对云信 NeCodeGen 有了一些基本认识,本节主要介绍云信 NeCodeGen 推荐的一些设计模式,在云信 NeCodeGen 的实现中,提供了支持这些设计模式的基础功能。这些设计模式是经过工程实践后总结得出的,能够帮助开发出更易维护的应用,由于 C++ 语言的复杂性,其 AST 的处理也会比较复杂,合适的设计模式就尤为重要,这对于大型项目而言,具有重要意义。
Matcher
在编写源到源转译工具时,常用的模式是匹配感兴趣的节点,然后对匹配的节点执行对应的处理,比如名称转换、类型转换。Matcher pattern 就是为这种典型的需求而创建的:框架遍历 AST,并执行用户注册的 match funcion(匹配函数),一旦匹配成功,则执行 match
funcion 对应的 callback。这种模式是
clang 社区为开发 clang 工具而总结出来的,并提供了支持库 LibASTMatchers。
NeCodeGen 借鉴了这种模式,并结合 Python 语言的特性、自身的需求进行了本地化实现,它运用了 Python 的 decorator 语法糖,通用的写法如下:
@frontend_action.connect(match_func)def
callback(): pass
上述写法的含义是: 告诉frontend_action连接(connect) match
funcionmatch_func 和 callback callback;frontend_action 在遍历 AST 时,会将节点作为入参,依次执行所有向它注册的 match func,如果 match func 返回 True,则表示匹配成功,框架就会执行 callback 函数来对匹配成功的节点进行处理,否则pass。
通过实践来看,这种模式能够应用的结构更加清晰、代码复用程度更高。
目前
clang 官方并没有提供 LibASTMatchers 的
Python绑定,为便于用户使用,NeCodeGen 提供对常用节点进行匹配的 match funcion。
MVC
MVC 模式读者应该不会陌生,它是前端开发中经常使用的一种模式,在本节前面的“yyy模板引擎简介”内容中已经对其进行了简单介绍,云信 NeCodeGen 中 MVC 可以归纳为如表4.4所示:

表4.4 云信 NeCodeGen 中 MVC
实际使用中,推荐使用自顶向下的思路:定义 model,确定 model 的成员,基于 model 来编写代码模板,然后再编写提取、转换函数来获取数据来对 model 进行初始化,最后使用 model 来渲染模板。
从实践来看,MVC 能够使代码结构清晰,维护性更强;对于需要从一种源语言生成多种目标语言程序的项目,MVC
能够保证 Model 在目标语言中保持一致,这在一定程度上能够提示代码复用。
Matcher pattern 是
NeCodeGen 框架使用的模式,MVC pattern 则是推荐应用开发者使用的模式;Matcher pattern 的 callback 对应了 MVC pattern 的 controller,即在 callback 中实现 controller 的功能。
4.11.14 NeCodeGen如何运行
已经对 NeCodeGen 的运行流程有了大致的认识,如图4.33所示表示以流程图的形式对 NeCodeGen 的运行流程进行总结:
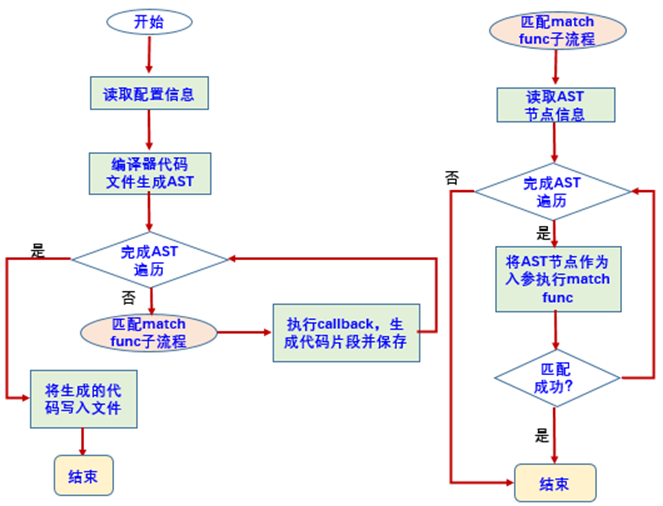
图4.33 NeCodeGen 的运行流程
4.11.15 应用价值
代码生成工具的主要目的是提升生产力,对于大型项目而言,它的作用更加明显。在工程实践中,会综合运用多种代码生成工具,充分发挥工具的威力,并将工具加入
CICD,这样的做法极大地提升了研发效率;对生产力的提高还体现在重构和维护上,在修改源语言程序后,运行工具即可得到更新后的目标语言程序,这能够避免由于源语言程序和目标语言程序的不一致而导致的错误;重构工作也将变得简单,对目标语言程序的重构将简化为修改代码模板,重新运行工具后,即可完成所有的重构。代码生成工具优势还体现在对代码规范的遵守上,通过将命名规范、代码规范等编码在工具中,能够保证生成的程序对代码规范百分之百的遵守。
如表4.5所示,NeCodeGen 除了可以应用于语言绑定的生成上,还可以应用于其他领域,比如实现类似于
QT 的 Meta-Object System,它也可以作为一个 stub代码生成器。
术语

表4.5 NeCodeGen的各种应用