一、总体使用情况
1、top 命令
top命令可以看到总体的系统运行状态和cpu的使用率 。
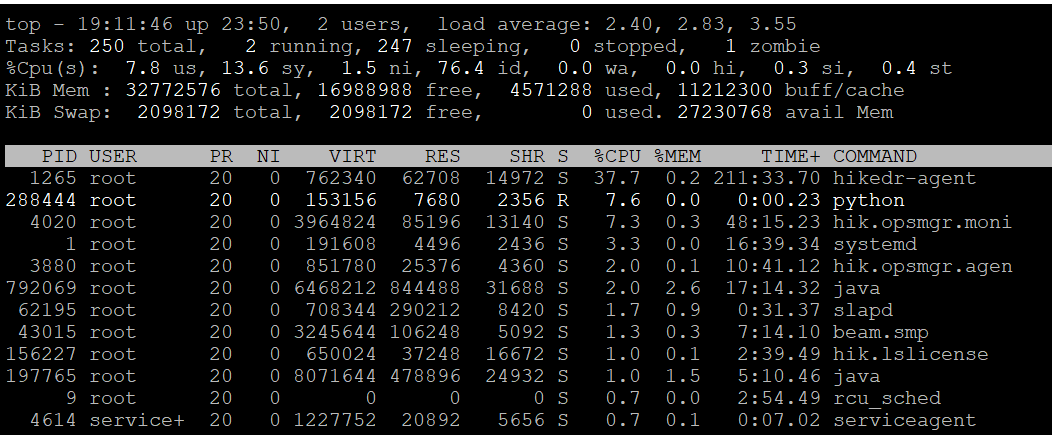
参数解释
(1) top
(2) Tasks
- total:
- running
- sleeping
- stopped
- zombie
(3) Cpu
- us:表示用户空间程序的cpu使用率(没有通过nice调度)
- sy:表示系统空间的cpu使用率,主要是内核程序。
- ni:表示用户空间且通过nice调度过的程序的cpu使用率。
- id:空闲cpu
- wa:cpu运行时在等待io的时间
- hi:cpu处理硬中断的数量
- si:cpu处理软中断的数量
- st:被虚拟机偷走的cpu
(4) KiB Mem
(5) KiB Swap
(6) 列表
2、vmstat 命令
该命令是通过安装 sysstat rpm 包存在的。可以通过 yum install -y sysstat 进行安装。
vmstat n k : 表示每n秒采集,总共采集k次
k 不填写的时候,表示每 n 秒采集一直持续下去直到程序退出

参数解释
(1) 进程procs:
- r:在运行队列中等待的进程数 。表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高
- b:在等待io的进程数 。表示阻塞的进程,这个不多说,进程阻塞。
(2) Linux 内存监控内存memory:
- swpd:现时可用的交换内存(单位KB)。虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
- free:空闲的内存(单位KB)。
- buff: 缓冲去中的内存数(单位:KB)。Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存。
- cache:被用来做为高速缓存的内存数(单位:KB)。cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用3800多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
(3) Linux 内存监控swap交换页面
- si: 从磁盘交换到内存的交换页数量,单位:KB/秒。每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。
- so: 从内存交换到磁盘的交换页数量,单位:KB/秒。每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
(4) Linux 内存监控 io块设备
- bi: 发送到块设备的块数,单位:块/秒。块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte;
- bo: 从块设备接收到的块数,单位:块/秒。块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
(5) Linux 内存监控system系统:
- in: 每秒的中断数,包括时钟中断。每秒CPU的中断次数,包括时间中断。
- cs: 每秒的环境(上下文)转换次数。每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的 数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或 者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核 空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的 时间少了,CPU没有充分利用,是不可取的。
(6) Linux 内存监控cpu中央处理器:
- cs:用户进程使用的时间 。以百分比表示。用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
- sy:系统进程使用的时间。 以百分比表示。系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
- id:中央处理器的空闲时间 。以百分比表示。空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
常见诊断:
1、假如 r 经常大于4 ,且 id 经常小于40,表示中央处理器的负荷很重。
2、假如 bi,bo 长期不等于0,表示物理内存容量太小。
3、si/so 这两个数越大,表明数据需要经常在磁盘和内存之间进行交换,系统性能越差
4、bi/bo 这两个数越大,代表系统的 I/O 越繁忙。
5、如果us+sy 大于 80%说明可能存在CPU不足,如果wa超过30%,说明IO等待比较严重。
3、sar 命令
sar 命令很强大,是分析系统性能的重要工具之一,通过该命令可以全面地获取系统的 CPU、运行队列、磁盘读写(I/O)、分区(交换区)、内存、CPU 中断和网络等性能数据。
命令基本格式:sar [options] [-o filename] interval [count]
此命令格式中,各个参数的含义如下:
- -o filename:其中,filename 为文件名,此选项表示将命令结果以二进制格式存放在文件中;
- interval:表示采样间隔时间,该参数必须手动设置;
- count:表示采样次数,是可选参数,其默认值为 1;
- options:为命令行选项,由于 sar 命令提供的选项很多,这里不再一一介绍,仅列举出常用的一些选项及对应的功能,如表 1 所示。
| sar命令选项 | 功能 |
|---|---|
| -A | 显示系统所有资源设备(CPU、内存、磁盘)的运行状况。 |
| -u | 显示系统所有 CPU 在采样时间内的负载状态。 |
| -P | 显示当前系统中指定 CPU 的使用情况。 |
| -d | 显示系统所有硬盘设备在采样时间内的使用状态。 |
| -r | 显示系统内存在采样时间内的使用情况。 |
| -b | 显示缓冲区在采样时间内的使用情况。 |
| -v | 显示 inode 节点、文件和其他内核表的统计信息。 |
| -n | 显示网络运行状态,此选项后可跟 DEV(显示网络接口信息)、EDEV(显示网络错误的统计数据)、SOCK(显示套接字信息)和 FULL(等同于使用 DEV、EDEV和SOCK)等,有关更多的选项,可通过执行 man sar 命令查看。 |
| -q | 显示运行列表中的进程数、进程大小、系统平均负载等。 |
| -R | 显示进程在采样时的活动情况。 |
| -y | 显示终端设备在采样时间的活动情况。 |
| -w | 显示系统交换活动在采样时间内的状态。 |
二、磁盘IO
1、查看磁盘的读写性能
sar -d 2 3 ----- 每2秒刷新展示磁盘读写情况,总共采集3次
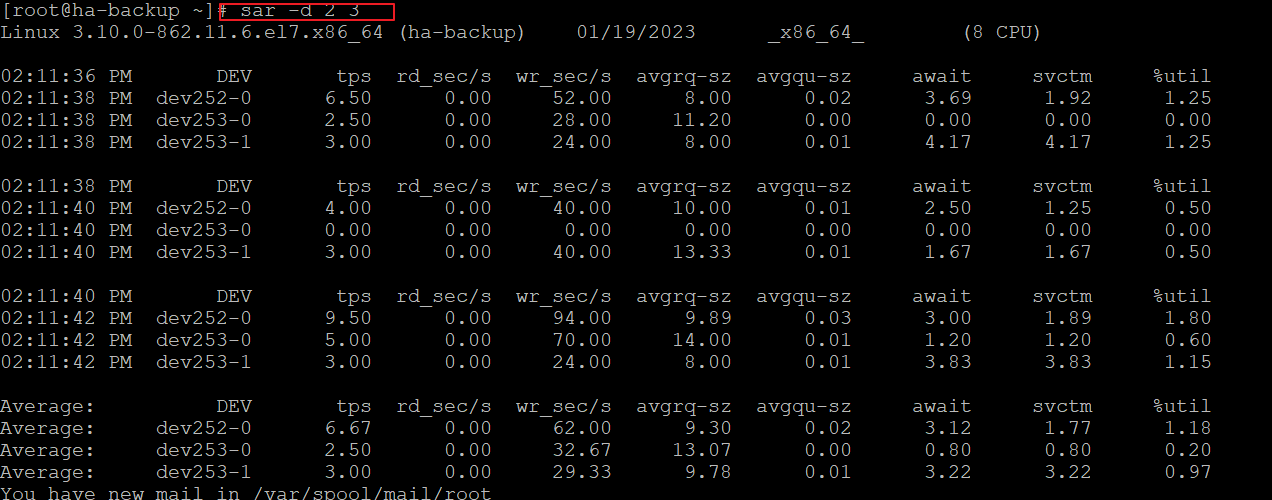
此输出结果中,各个列表头的含义如下:
- tps:每秒从物理磁盘 I/O 的次数。注意,多个逻辑请求会被合并为一个 I/O 磁盘请求,一次传输的大小是不确定的;
- rd_sec/s:每秒读扇区的次数;
- wr_sec/s:每秒写扇区的次数;
- avgrq-sz:平均每次设备 I/O 操作的数据大小(扇区);
- avgqu-sz:磁盘请求队列的平均长度;
- await:从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒(1 秒=1000 毫秒);
- svctm:系统处理每次请求的平均时间,不包括在请求队列中消耗的时间;
- %util:I/O 请求占 CPU 的百分比,比率越大,说明越饱和。
2、iostat(仅能对系统的整体IO进行分析)
语法 iostat (选项) (参数)
选项
- -c:仅显示CPU使用情况;
- -d:仅显示设备利用率;
- -k:显示状态以千字节每秒为单位,而不使用块每秒;
- -m:显示状态以兆字节每秒为单位;
- -p:仅显示块设备和所有被使用的其他分区的状态;
- -t:显示每个报告产生时的时间;
- -V:显示版号并退出;
- -x:显示扩展状态。
参数
- 间隔时间:每次报告的间隔时间(秒);
- 次数:显示报告的次数。

CPU:
- %user:CPU处在用户模式下的时间百分比。
- %nice:CPU处在带NICE值的用户模式下的时间百分比。
- %system:CPU处在系统模式下的时间百分比。
- %iowait:CPU等待输入输出完成时间的百分比。
- %steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
- %idle:CPU空闲时间百分比。
备注:
- 如果%iowait的值过高,表示硬盘存在I/O瓶颈
- 如果%idle值高,表示CPU较空闲
- 如果%idle值高但系统响应慢时,可能是CPU等待分配内存,应加大内存容量。
- 如果%idle值持续低于10,表明CPU处理能力相对较低,系统中最需要解决的资源是CPU。
磁盘:
- tps:该设备每秒的传输次数
- kB_read/s:每秒从设备(drive expressed)读取的数据量;
- kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
- kB_read: 读取的总数据量;
- kB_wrtn:写入的总数量数据量;
- rrqm/s:每秒进行 merge 的读操作数目,即每秒这个设备相关的读取请求有多少被Merge了,也即 delta(rmerge)/s。当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge。
- wrqm/s:每秒进行 merge 的写操作数目,即每秒这个设备相关的写入请求有多少被Merge了,也即 delta(wmerge)/s。
- r/s: 每秒完成的读 I/O 设备次数,即 delta(rio)/s 。
- w/s: 每秒完成的写 I/O 设备次数,即 delta(wio)/s 。
- rkB/s: 每秒读K字节数,是 rsect/s 的一半,因为每扇区大小为512字节.(需要计算)。
- wkB/s: 每秒写K字节数,是 wsect/s 的一半.(需要计算)。
- avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区),即delta(rsect+wsect)/delta(rio+wio)。
- avgqu-sz: 平均I/O队列长度,即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
- await:平均每次设备I/O操作的等待时间 (毫秒),即 delta(ruse+wuse)/delta(rio+wio)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。
- r_await:每个读操作平均所需的时间;不仅包括硬盘设备读操作的时间,还包括了在kernel队列中等待的时间。
- w_await:每个写操作平均所需的时间;不仅包括硬盘设备写操作的时间,还包括了在kernel队列中等待的时间。
- svctm: 平均每次设备I/O操作的服务时间 (毫秒),即 delta(use)/delta(rio+wio)。
- %util:代表磁盘繁忙程度。100% 表示磁盘繁忙, 0%表示磁盘空闲。%util为在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒【本次案例是2秒】,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
3、pidstat
4、iotop
5、磁盘相关命令
1)
三、CPU
1、 查看系统 CPU 的整理负载状况,每 3 秒统计一次,统计 5 次
sar -u 3 5

此输出结果中,各个列表项的含义分别如下:
- %user:用于表示用户模式下消耗的 CPU 时间的比例;
- %nice:通过 nice 改变了进程调度优先级的进程,在用户模式下消耗的 CPU 时间的比例;
- %system:系统模式下消耗的 CPU 时间的比例;
- %iowait:CPU 等待磁盘 I/O 导致空闲状态消耗的时间比例;
- %steal:利用 Xen 等操作系统虚拟化技术,等待其它虚拟 CPU 计算占用的时间比例;
- %idle:CPU 空闲时间比例。
参考资料:
Linux sar命令详解:分析系统性能 (biancheng.net)