一、选题背景
选择此选题的原因是为了进行电影数据的分析。电影作为一种重要的文化娱乐形式,对社会、经济和文化等方面都有着重要的影响。通过对电影数据的分析,可以揭示电影产业的发展趋势、观众喜好、电影市场的竞争情况等,为电影行业的决策制定提供依据。
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称 Rotten Tomatoes电影数据爬虫
2.主题式网络爬虫爬取的内容与数据特征分析
爬取的内容:电影的名称、图片、链接、番茄评分、观众评分、类型、语言、导演、制片人、编剧、院线上映时间、流媒体上映时间、片长、发行商、制作公司、电影链接。
数据特征分析:分析电影的评分分布、不同类型电影的数量和比例、电影上映时间的分布、导演和演员的影响力等。
3.主题式网络爬虫设计方案概述
实现思路:使用Selenium库模拟浏览器操作,访问Rotten Tomatoes网站,按照预设的规则爬取电影数据。通过XPath表达式解析HTML文档,提取所需的电影信息,并进行数据清洗和整理。 技术难点:网站反爬虫机制可能会限制爬虫的访问频率,需要设置适当的访问间隔或使用代理IP进行访问。另外,网页内容的结构变化可能会导致XPath表达式失效,需要及时调整和更新解析代码。此外,数据量较大时,需要考虑存储和处理大规模数据的方法,例如使用数据库进行存储和查询。
三、主题页面的结构特征分析
1.主题页面的结构与特征分析
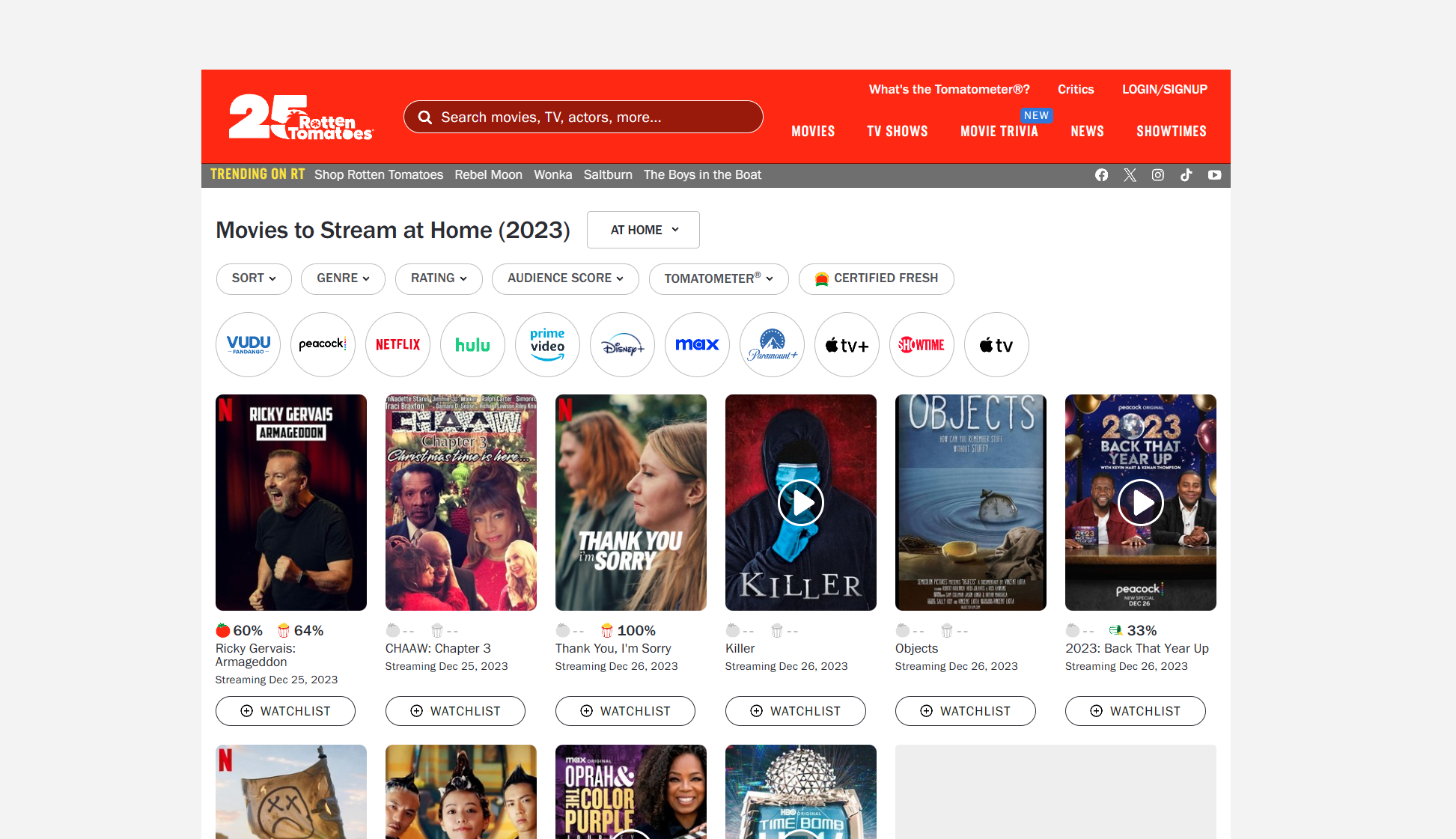

主题页面通常包含多个电影信息的列表或网格布局,每个电影信息都以卡片或类似的方式呈现。 每个电影信息通常包含电影名称、图片、评分、类型、导演、演员等基本信息,并可能包含其他详细信息如上映日期、片长、制作公司等。 电影信息的排列顺序可能是按照某种规则(如热度、评分)进行排序的。 主题页面可能包含分页功能,允许用户浏览不同页的电影信息。
2.Htmls页面解析
首先,使用库加载HTML页面,将其转换为树状结构。 然后,使用XPath表达式或CSS选择器来定位和提取所需数据的节点。 通过节点的标签、属性、文本内容等信息,可以获取电影名称、图片地址、评分、类型、导演、制片人、编剧、上映日期、片长、发行商、制作公司、电影视频链接等数据。
3.节点(标签)查找方法与遍历方法
节点查找方法:可以使用XPath表达式或CSS选择器来查找HTML页面中的节点。 通过标签名、属性值、类名等进行节点查找,例如使用XPath表达式//div[@class='movie-card']或CSS选择器.movie-card来定位电影信息的节点。 节点遍历方法:可以使用循环、递归等方式对节点进行遍历和访问。 可以使用父节点、子节点、兄弟节点等关系进行节点的遍历和访问,以获取所需的数据。
四、网络爬虫程序设计
1.数据爬取与采集与数据清洗和处理
从Rotten Tomatoes网站上爬取电影信息的功能。使用了Selenium库来模拟浏览器操作,获取网页内容,并使用lxml库解析HTML内容,提取所需的电影信息。这里采用边爬取边清洗和整理.将提取的电影信息存储在一个列表中,并使用csv库将列表数据写入到CSV文件中。在写入CSV文件之前,还进行了一些判断和处理,例如检查文件是否存在、文件大小是否为0,避免重复写入数据。另外,还提供了保存数据到数据库的功能(注释部分),可以根据需要进行相应的配置。



2.文本分析 (可选): jieba 分词、wordcloud 的分词可视化
不同电影的评论词云



由于电影众多,以上就不一一截图了
1 # 创建一个空字典来存储每个电影的评论
2 comments = {}
3
4 # 遍历数据集,将评论按电影名称存储在字典中
5 for index, row in com.iterrows():
6 movie_name = row['movie_name']
7 comment = str(row['text']) # 将评论的值转换为字符串
8 if movie_name in comments:
9 comments[movie_name] += comment
10 else:
11 comments[movie_name] = comment
12
13 # 生成每个电影的词云可视化
14 for movie_name, comment in comments.items():
15 # 创建词云对象
16 wordcloud = WordCloud(background_color='white', width=800, height=400).generate(comment)
17
18 # 绘制词云图像
19 plt.figure(figsize=(10, 5))
20 plt.imshow(wordcloud, interpolation='bilinear')
21 plt.title(movie_name + ' 评论词云')
22 plt.axis('off')
23 plt.show()
3.数据分析与可视化(例如:数据形图、直方图、散点图、盒图、分布图)
专业评分TOP10

1 # 读取CSV文件 2 data = pd.read_csv('RottentomatoesMovies.csv') 3 # 根据专业评分排序并选择前10个电影 4 top10_critic_score = data.sort_values('tomatometer_score', ascending=False).head(10) 5 6 # 创建水平条形图 7 plt.barh(top10_critic_score['name'], top10_critic_score['tomatometer_score']) 8 plt.xlabel('分数') 9 plt.ylabel('电影名') 10 plt.title('专业评分TOP10') 11 plt.show()
业务评分TOP10

1 # 根据业务评分排序并选择前10个电影 2 top10_critic_score = data.sort_values('tomatometer_score', ascending=False).head(10) 3 4 # 创建水平条形图 5 plt.barh(top10_critic_score['name'], top10_critic_score['audience_score']) 6 plt.xlabel('分数') 7 plt.ylabel('电影名') 8 plt.title('业务评分TOP10') 9 plt.show()
不同语种电影的数量占比
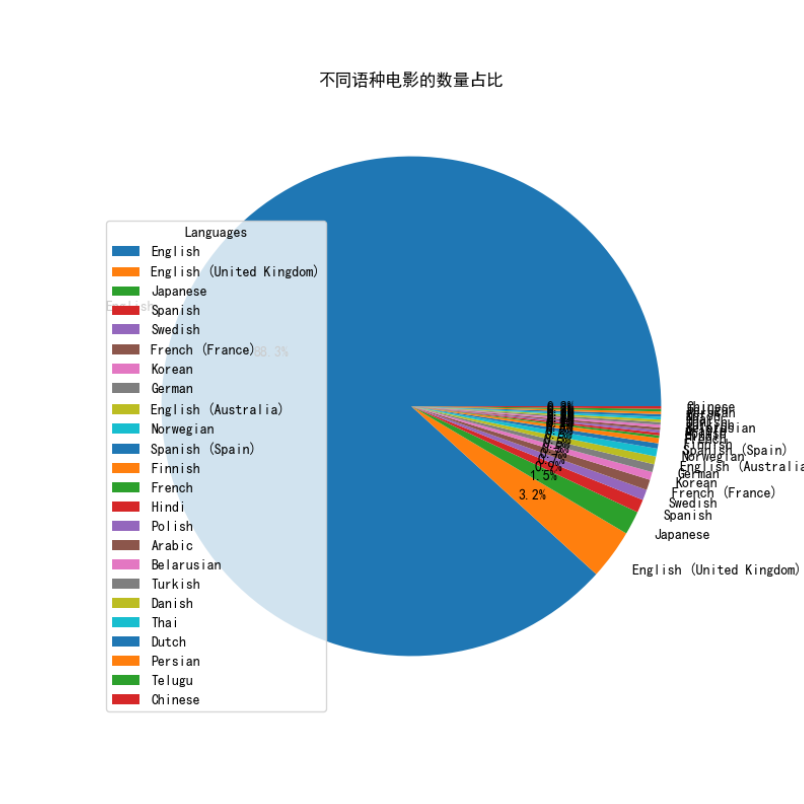
1 # 统计每种语言电影的数量 2 language_counts = data['original_language'].value_counts() 3 4 # 创建饼图 5 plt.pie(language_counts, labels=language_counts.index, autopct='%1.1f%%') 6 7 # 调整饼图的大小 8 fig = plt.gcf() 9 fig.set_size_inches(8, 8) 10 11 # 添加图例 12 plt.legend(title='Languages', loc='best') 13 14 # 添加标题 15 plt.title('不同语种电影的数量占比') 16 17 # 显示饼图 18 plt.show()
电影上线流媒体的时间分布

1 # 将上线流媒体日期转换为日期类型 2 data['release_date_streaming'] = pd.to_datetime(data['release_date_streaming']) 3 4 # 创建直方图 5 plt.hist(data['release_date_streaming'], bins=30) 6 plt.xlabel('时间日期') 7 plt.ylabel('电影数量') 8 plt.title('电影上线流媒体的时间分布') 9 plt.xticks(rotation=45) 10 plt.show()
评分与时长的相关性

1 # 创建散点图 2 plt.scatter(data['runtime'], data['tomatometer_score']) 3 plt.xlabel('片长') 4 plt.ylabel('番茄表评分') 5 plt.title('电影上线影院的时间分布') 6 plt.show()
电影上线影院的时间分布

# 将上线流媒体日期转换为日期类型
data['release_date_streaming'] = pd.to_datetime(data['release_date_streaming'])
# 设置图形样式
sns.set(style='whitegrid')
# 解决中文乱码问题
sns.set_style('whitegrid', {'font.sans-serif': ['simhei', 'Arial']})
# 创建直方图
plt.figure(figsize=(10, 6)) # 调整图形大小
# 绘制直方图
plt.hist(data['release_date_streaming'], bins=30, edgecolor='k', alpha=0.7)
# 设置坐标轴标签和标题
plt.xlabel('时间日期', fontsize=12)
plt.ylabel('电影数量', fontsize=12)
plt.title('电影上线影院的时间分布', fontsize=14)
# 调整坐标轴刻度的旋转角度
plt.xticks(rotation=45)
# 显示图形
plt.tight_layout() # 自动调整布局,防止标签重叠
plt.show()
电影评论新鲜度TOP10
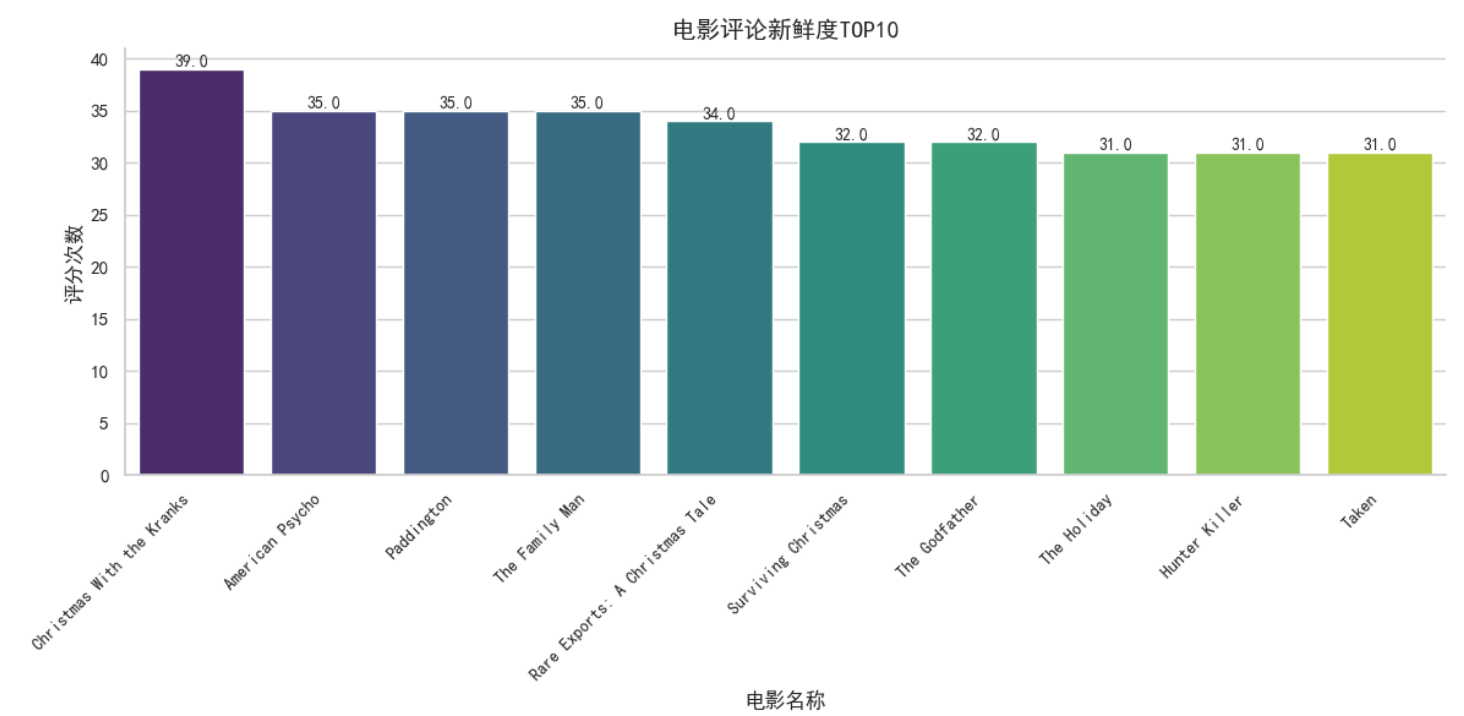
1 # 计算每个电影的评分次数 2 review_counts = com[com['top'] == 1]['movie_name'].value_counts().head(10) 3 4 # 设置绘图样式 5 sns.set_theme(style='whitegrid') 6 #解决中文乱码问题 7 sns.set_style('whitegrid',{'font.sans-serif':['simhei','Arial']}) 8 9 # 绘制柱状图 10 plt.figure(figsize=(12, 6)) 11 ax = sns.barplot(x=review_counts.index, y=review_counts.values, palette='viridis') 12 ax.set_xlabel('电影名称', fontsize=12) 13 ax.set_ylabel('评分次数', fontsize=12) 14 ax.set_title('电影评论新鲜度TOP10', fontsize=14) 15 ax.set_xticklabels(review_counts.index, rotation=45, ha='right', fontsize=10) 16 ax.spines['top'].set_visible(False) 17 ax.spines['right'].set_visible(False) 18 19 # 添加标签 20 for p in ax.patches: 21 ax.annotate(f'{p.get_height()}', (p.get_x() + p.get_width() / 2, p.get_height()), ha='center', va='bottom', fontsize=10) 22 23 plt.tight_layout() 24 plt.show()
最会评论家TOP10

1 # 生成十个随机颜色 2 random_colors = [] 3 for _ in range(10): 4 r = random.randint(0, 255) 5 g = random.randint(0, 255) 6 b = random.randint(0, 255) 7 color = '#%02x%02x%02x' % (r, g, b) 8 random_colors.append(color) 9 10 # 统计每个评论家的评论得分平均值 11 reviewer_scores = com.groupby('reviewer_name')['top'].mean() 12 13 # 选择前10名评论家 14 top10_expert_reviewers = reviewer_scores.sort_values(ascending=False).head(10) 15 16 # 创建水平条形图,应用随机颜色 17 plt.barh(top10_expert_reviewers.index, top10_expert_reviewers, color=random_colors) 18 19 plt.xlabel('平均评论分数') 20 plt.ylabel('名字') 21 plt.title('最会评论家TOP10') 22 23 plt.show()
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程(一元或多元)。

1 # 读取数据 2 data = pd.read_csv('RottentomatoesMovies.csv') 3 4 # 选择两个变量进行分析 5 x = data['tomatometer_score'] 6 y = data['audience_score'] 7 8 # 计算相关系数 9 correlation = np.corrcoef(x, y)[0, 1] 10 print("相关系数:", correlation) 11 12 # 绘制散点图 13 plt.scatter(x, y) 14 plt.xlabel('Tomatometer Score') 15 plt.ylabel('Audience Score') 16 plt.title('Scatter Plot of Tomatometer Score vs Audience Score') 17 plt.show() 18 19 # 建立回归方程 20 regression_model = LinearRegression() 21 x = x.values.reshape(-1, 1) 22 regression_model.fit(x, y) 23 intercept = regression_model.intercept_ 24 slope = regression_model.coef_[0] 25 print("回归方程: y =", slope, "* x +", intercept)
6.数据持久化
在save_csv方法中,将数据以CSV格式写入到文件RottentomatoesMovies.csv中。首先检查文件是否存在且非空,然后使用csv.writer将数据写入文件。7.将以上各部分的代码汇总,附上完整程序代码
Rottentomatoes_Movies类
1 # -*- coding: utf-8 -*- 2 import os 3 from urllib import request 4 from lxml import html, etree 5 import re 6 import csv 7 8 from datetime import datetime 9 from selenium.common import TimeoutException 10 from selenium.webdriver.common.by import By 11 from selenium.webdriver.support.ui import WebDriverWait 12 from selenium.webdriver.support import expected_conditions as EC 13 from FinalProject_BigData.SeleniumConfig import getDriver 14 from FinalProject_BigData.RottenTomatoes_Movies_Comment import RottenTomatoesSpiderMoviesComment 15 import pandas as pd 16 from sqlalchemy import create_engine 17 18 # 定义一个爬虫类 19 class RottenTomatoesSpiderMovies(object): 20 # 初始化 21 # 定义初始页面url 22 def __init__(self): 23 # self.url = 'https://maoyan.com/board/4?offset={}' 24 self.page_url = 'https://www.rottentomatoes.com/browse/movies_at_home/' 25 self.info_url = 'https://www.rottentomatoes.com' 26 self.comment_spider = RottenTomatoesSpiderMoviesComment() 27 self.parser = html.HTMLParser(encoding='utf-8') 28 self.movie_infos = {} 29 self.driver = getDriver() 30 self.flag = True 31 self.movie_containers_old_len = 0 32 self.movie_comment_info = [] 33 self.save_list = [] 34 self.insert_count = 0 35 self.existing_names = set() 36 self.cookie = '' 37 if os.path.exists('RottentomatoesMovies.csv') and os.stat('RottentomatoesMovies.csv').st_size > 0: 38 with open('RottentomatoesMovies.csv', 'r', encoding="utf-8") as f: 39 reader = csv.DictReader(f) 40 for row in reader: 41 self.existing_names.add(row['name']) 42 43 def load_page(self): 44 page_number = 5 45 # 打开网页 46 url = self.page_url + '?page=' + str(page_number) 47 self.driver.get(url) 48 self.cookie = self.driver.execute_script("return document.cookie") 49 print(url) 50 for index in range(16): 51 # 等待“加载更多”按钮可点击 52 try: 53 # 点击“加载更多”按钮 54 if self.flag: 55 load_more_button = WebDriverWait(self.driver, 60).until( 56 EC.element_to_be_clickable((By.XPATH, '//button[@data-qa="dlp-load-more-button"]')) 57 ) 58 load_more_button.click() 59 self.flag = False 60 self.parse_html(self.driver.page_source) 61 # 增加页数 62 page_number += 1 63 # 输出当前页数 64 print(f"当前页: {page_number}==============") 65 except TimeoutException: 66 print("加载按钮未找到,可能已经到达最后一页。") 67 break 68 if len(self.save_list) > 0: 69 self.save_csv() 70 #将CSV里的数据存入数据库 71 #self.save_sql() 72 self.comment_spider.run(self.movie_comment_info, self.driver) 73 74 def save_csv(self): 75 # 检查文件是否存在,并且文件大小是否为 0 76 is_empty = not os.path.exists('RottentomatoesMovies.csv') or os.stat('RottentomatoesMovies.csv').st_size == 0 77 # 生成文件对象 78 with open('RottentomatoesMovies.csv', 'a', newline='', encoding="utf-8") as f: 79 # 生成csv操作对象 80 writer = csv.writer(f) 81 # 整理数据 82 if is_empty: 83 header = ['name', 'img', 'url','tomatometer_score', 'audience_score', 'genres', 'original_language', 84 'directors', 85 'producers', 'writers', 'release_date_theaters', 'release_date_streaming', 'runtime', 86 'distributor', 'productionCo', 'movie_video_url'] 87 writer.writerow(header) 88 for movie_data in self.save_list: 89 movie_name = movie_data[0] 90 if movie_name not in self.existing_names: 91 writer.writerow(movie_data) 92 self.existing_names.add(movie_name) 93 self.save_list.clear() 94 95 96 # 请求函数 97 def get_html(self, url): 98 # headers = {'User-Agent': random.choice(ua_list)} 99 headers = { 100 'Referer': 'https://www.rottentomatoes.com', 101 'Cookie': self.cookie, 102 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"} 103 req = request.Request(url=url, headers=headers) 104 res = request.urlopen(req, timeout=120) 105 html = res.read().decode() 106 return html 107 108 # 解析函数 109 def parse_html(self, html_content): 110 tree = html.fromstring(html_content, parser=self.parser) 111 movie_containers_old = tree.xpath('//div[@class="flex-container "]') 112 movie_containers_cur = movie_containers_old[self.movie_containers_old_len:len(movie_containers_old)] 113 self.movie_containers_old_len = len(movie_containers_old) 114 for container in movie_containers_cur: 115 # 提取电影名称 116 movie_name_old = container.xpath( 117 './/span[@class="p--small" and @data-qa="discovery-media-list-item-title"]/text()') 118 if movie_name_old: 119 movie_name = movie_name_old[0].strip() 120 else: 121 movie_name = None 122 # 提取电影信息 URL 123 movie_info_url_old = container.xpath( 124 './/a[@data-track="scores" and @data-qa="discovery-media-list-item-caption"]/@href') 125 if movie_info_url_old: 126 movie_info_url = movie_info_url_old[0] 127 else: 128 movie_info_url = \ 129 container.xpath('.//a[@class="js-tile-link" and @data-qa="discovery-media-list-item"]/@href')[0] 130 # 提取评分信息 131 tomatometer_score_old = container.xpath('.//score-pairs-deprecated/@criticsscore') 132 if tomatometer_score_old[0]: 133 tomatometer_score = int(tomatometer_score_old[0]) 134 else: 135 tomatometer_score = 0 136 audience_score_old = container.xpath('.//score-pairs-deprecated/@audiencescore') 137 if audience_score_old[0]: 138 audience_score = int(audience_score_old[0]) 139 else: 140 audience_score = 0 141 if movie_name not in self.existing_names: 142 self.parse_movie_info((movie_name, tomatometer_score, audience_score, movie_info_url)) 143 self.flag = True 144 print("结束当前页爬取!") 145 146 # 解析电影详情页 147 def parse_movie_info(self, movie_info): 148 movie_info_url = self.info_url + movie_info[3] 149 print(movie_info_url) 150 self.movie_comment_info.append([movie_info[0], movie_info_url]) 151 tree = html.fromstring(self.get_html(movie_info_url), parser=self.parser) 152 movie_name = movie_info[0] 153 movie_img_old = tree.xpath('//tile-dynamic[@class="thumbnail" and @isvideo=""]/rt-img/@src') 154 # 获取电影照片链接 155 if movie_img_old: 156 movie_img = movie_img_old[0] 157 else: 158 movie_img = None 159 tomatometer_score = movie_info[1] 160 audience_score = movie_info[2] 161 genres = ', '.join(map(str, [item.replace('\n', '').replace(' ', '').strip() for item in tree.xpath( 162 '//li[@data-qa="movie-info-item"]/p[b[@data-qa="movie-info-item-label"]="Genre:"]/span[@data-qa="movie-info-item-value"]/text()')])) 163 original_language = ', '.join(map(str, tree.xpath( 164 '//li[@data-qa="movie-info-item"]/p[b[@data-qa="movie-info-item-label"]="Original Language:"]/span[@data-qa="movie-info-item-value"]/text()'))) 165 directors = ', '.join(map(str, [item.strip() for item in tree.xpath( 166 '//li[@data-qa="movie-info-item"]/p[b[@data-qa="movie-info-item-label"]="Director:"]/span[@data-qa="movie-info-item-value"]/a[@data-qa="movie-info-director"]/text()')])) 167 producers = ', '.join(map(str, tree.xpath( 168 '//li[@data-qa="movie-info-item"]/p[b[@data-qa="movie-info-item-label"]="Producer:"]/span[@data-qa="movie-info-item-value"]/a/text()'))) 169 writers = ', '.join(map(str, tree.xpath( 170 '//li[@data-qa="movie-info-item"]/p[b[@data-qa="movie-info-item-label"]="Writer:"]/span[@data-qa="movie-info-item-value"]/a/text()'))) 171 releaseDateByTheatersOld = tree.xpath( 172 '//li[@data-qa="movie-info-item"]/p[b[@data-qa="movie-info-item-label"]="Release Date (Theaters):"]/span[@data-qa="movie-info-item-value"]/time/text()') 173 if releaseDateByTheatersOld: 174 releaseDateByTheaters = datetime.strptime(releaseDateByTheatersOld[0].replace(' ', ''), '%b%d,%Y') 175 else: 176 releaseDateByTheaters = None 177 releaseDateByStreamingOld = [item.replace('\n', '').replace(' ', '').strip() for item in tree.xpath( 178 '//li[@data-qa="movie-info-item"]/p[b[@data-qa="movie-info-item-label"]="Release Date (Streaming):"]/span[@data-qa="movie-info-item-value"]/time/text()')] 179 if releaseDateByStreamingOld: 180 releaseDateByStreaming = datetime.strptime(releaseDateByStreamingOld[0].replace(' ', ''), '%b%d,%Y') 181 else: 182 releaseDateByStreaming = None 183 runtimeOld = [item.replace('\n', '').replace(' ', '').strip() for item in tree.xpath( 184 '//li[@data-qa="movie-info-item"]/p[b[@data-qa="movie-info-item-label"]="Runtime:"]/span[@data-qa="movie-info-item-value"]/time/text()')] 185 if runtimeOld: 186 match = re.match(r'(?:(\d+)h)?(?:(\d+)m)?', runtimeOld[0]) 187 if match: 188 hours = int(match.group(1) or 0) 189 minutes = int(match.group(2) or 0) 190 # 将小时转换为分钟并加上分钟部分 191 runtime = hours * 60 + minutes 192 else: 193 runtime = 0 194 else: 195 runtime = 0 196 distributor = ', '.join(map(str, [item.replace('"', '').strip() for item in tree.xpath( 197 '//li[@data-qa="movie-info-item"]/p[b[@data-qa="movie-info-item-label"]="Distributor:"]/span[@data-qa="movie-info-item-value"]/text()')])) 198 productionCo = ', '.join( 199 map(str, [re.sub(r'\s+', ' ', item.replace('"', '').replace('\n', '').strip()) for item in tree.xpath( 200 '//li[@data-qa="movie-info-item"]/p[b[@data-qa="movie-info-item-label"]="Production Co:"]/span[@data-qa="movie-info-item-value"]/text()')])) 201 #movie_video_url = self.get_movie_video_url(movie_info_url) 202 movie_video_url = None 203 204 self.save_list.append( 205 [movie_name, movie_img, movie_info_url, tomatometer_score, audience_score, genres, original_language, directors, producers, 206 writers, 207 releaseDateByTheaters, releaseDateByStreaming, runtime, distributor, productionCo, movie_video_url]) 208 if len(self.save_list) > 500: 209 self.save_csv() 210 211 def test(self, html_content): 212 with open('t.txt', 'a', encoding='utf-8') as f: 213 f.write(html_content) 214 raise Exception 215 # 主函数 216 def run(self): 217 self.load_page() 218 219 220 # 以脚本方式启动 221 if __name__ == '__main__': 222 # 捕捉异常错误 223 try: 224 spider = RottenTomatoesSpiderMovies() 225 spider.run() 226 except Exception as e: 227 print("错误:", e)
Rottentomatoes_Movies_Comment类
1 # -*- coding: utf-8 -*- 2 import csv 3 import os 4 import queue 5 import threading 6 import time 7 from lxml import html, etree 8 from datetime import datetime 9 from selenium.common import TimeoutException 10 from selenium.webdriver.common.by import By 11 from selenium.webdriver.support.ui import WebDriverWait 12 from selenium.webdriver.support import expected_conditions as EC 13 import pandas as pd 14 from sqlalchemy import create_engine 15 16 # 定义一个爬虫类 17 class RottenTomatoesSpiderMoviesComment(object): 18 # 初始化 19 # 定义初始页面url 20 def __init__(self): 21 self.load_count = 1 22 self.parser = html.HTMLParser(encoding='utf-8') 23 self.flag = True 24 self.next = True 25 self.movie_rows_old_len = 0 26 self.movie_info = [] 27 self.save_list_lock = threading.Lock() 28 self.save_list = [] 29 self.insert_count = 0 30 self.load_count = 1 31 self.movie_queue = queue.Queue() 32 33 def load_page(self, movie_info, driver): 34 url = movie_info[1] + '/reviews' 35 driver.get(url) 36 37 while True: 38 try: 39 if self.flag: 40 load_more_button = WebDriverWait(driver, 5).until( 41 EC.element_to_be_clickable((By.XPATH, '//rt-button[@data-qa="load-more-btn"]')) 42 ) 43 time.sleep(1) 44 # 将元素滚动到视图中 45 if self.load_count < 6: 46 # 使用JavaScript来解决问题 47 driver.execute_script("arguments[0].scrollIntoView(true);", load_more_button) 48 driver.execute_script("arguments[0].click();", load_more_button) 49 self.load_count += 1 50 else: 51 raise TimeoutException 52 53 except TimeoutException: 54 print("开始爬取当前{"+movie_info[0]+"}的评论") 55 self.flag = False 56 self.parse_html(movie_info[0], driver.page_source) 57 break 58 59 60 def save_csv(self): 61 with self.save_list_lock: 62 is_empty = not os.path.exists('RottentomatoesMoviesComment.csv') or os.stat( 63 'RottentomatoesMoviesComment.csv').st_size == 0 64 with open('RottentomatoesMoviesComment.csv', 'a', newline='', encoding="utf-8") as f: 65 writer = csv.writer(f) 66 if is_empty: 67 header = ['movie_name', 'reviewer_name', 'date', 'top', 'state', 'text'] 68 writer.writerow(header) 69 70 for d in self.save_list: 71 writer.writerow(d) 72 # 清空列表 73 self.save_list.clear() 74 print('CSV存入成功!') 75 76 def save_sql(self): 77 engine = create_engine('mysql+pymysql://root:huangchao123@localhost:3306/huangchao') 78 data = pd.read_csv('./RottentomatoesMoviesComment.csv') 79 data.to_sql('rottentomatoes_movies_comment', engine, index=None, if_exists='append') 80 print('数据库存入成功!') 81 82 83 # 解析函数 84 def parse_html(self, movie_name, html_content): 85 tree = html.fromstring(html_content, parser=self.parser) 86 movie_rows_old = tree.xpath('//div[@class="review-row" and @data-qa="review-item"]') 87 movie_rows_cur = movie_rows_old[self.movie_rows_old_len:len(movie_rows_old)] 88 self.movie_rows_old_len = len(movie_rows_old) 89 for row in movie_rows_cur: 90 reviewer_name_old = row.xpath('.//a[@class="display-name"]/text()') 91 if reviewer_name_old: 92 reviewer_name = reviewer_name_old[0].replace('\n', '').strip() 93 else: 94 reviewer_name = None 95 96 review_date_old = row.xpath('.//span[@data-qa="review-date"]/text()') 97 if review_date_old: 98 review_date = datetime.strptime(review_date_old[0].replace(' ', ''),'%b%d,%Y') 99 else: 100 review_date = None 101 review_text_old = row.xpath('.//p[@class="review-text"]/text()') 102 103 review_isTop_old = row.xpath('.//rt-icon-top-critic[@class="small"]') 104 if review_isTop_old: 105 review_isTop = 1 106 else: 107 review_isTop = 0 108 109 review_state_old = row.xpath('.//score-icon-critic-deprecated/@state') 110 if review_state_old: 111 if review_state_old[0] == 'fresh': 112 review_state = 1 113 else: 114 review_state = 0 115 else: 116 review_state = 0 117 118 if review_text_old: 119 review_text = review_text_old[0] 120 else: 121 review_text = None 122 self.save_list.append([movie_name, reviewer_name, review_date, review_isTop, review_state, review_text]) 123 if len(self.save_list) > 0: 124 self.save_csv() 125 self.flag = True 126 127 def run(self, movie_infos, driver): 128 for m in movie_infos: 129 self.movie_queue.put(m) 130 while not self.movie_queue.empty(): 131 movie_info = self.movie_queue.get() 132 print("爬取当前电影评论:"+movie_info[0]) 133 self.load_count = 1 134 self.load_page(movie_info, driver) 135 # self.save_sql() 136 print("评论爬取结束")
shape类
1 # -*- coding: utf-8 -*- 2 import warnings 3 import seaborn as sns 4 import matplotlib 5 import numpy as np 6 import pandas as pd 7 import matplotlib.pyplot as plt 8 import random 9 from wordcloud import WordCloud 10 from sklearn.linear_model import LinearRegression 11 12 warnings.filterwarnings("ignore") 13 matplotlib.rcParams['font.sans-serif'] = ['SimHei'] 14 matplotlib.rcParams['axes.unicode_minus'] = False 15 # 显示中文标签 16 plt.rcParams['font.sans-serif'] = ['SimHei'] 17 # 设置正常显示符号 18 plt.rcParams['axes.unicode_minus'] = False 19 # 设置列名与数据对齐 20 pd.set_option('display.unicode.ambiguous_as_wide', True) 21 pd.set_option('display.unicode.east_asian_width', True) 22 23 # 读取CSV文件 24 data = pd.read_csv('RottentomatoesMovies.csv') 25 com = pd.read_csv('RottentomatoesMoviesComment.csv') 26 27 # 根据专业评分排序并选择前10个电影 28 top10_critic_score = data.sort_values('tomatometer_score', ascending=False).head(10) 29 30 # 创建水平条形图 31 plt.barh(top10_critic_score['name'], top10_critic_score['tomatometer_score']) 32 plt.xlabel('分数') 33 plt.ylabel('电影名') 34 plt.title('专业评分TOP10') 35 plt.show() 36 37 # 根据业务评分排序并选择前10个电影 38 top10_critic_score = data.sort_values('tomatometer_score', ascending=False).head(10) 39 40 # 创建水平条形图 41 plt.barh(top10_critic_score['name'], top10_critic_score['audience_score']) 42 plt.xlabel('分数') 43 plt.ylabel('电影名') 44 plt.title('业务评分TOP10') 45 plt.show() 46 47 # 统计每种语言电影的数量 48 language_counts = data['original_language'].value_counts() 49 50 # 创建饼图 51 plt.pie(language_counts, labels=language_counts.index, autopct='%1.1f%%') 52 53 # 调整饼图的大小 54 fig = plt.gcf() 55 fig.set_size_inches(8, 8) 56 57 # 添加图例 58 plt.legend(title='Languages', loc='best') 59 60 # 添加标题 61 plt.title('不同语种电影的数量占比') 62 63 # 显示饼图 64 plt.show() 65 66 # 将上线流媒体日期转换为日期类型 67 data['release_date_streaming'] = pd.to_datetime(data['release_date_streaming']) 68 69 # 设置图形样式 70 sns.set(style='whitegrid') 71 # 解决中文乱码问题 72 sns.set_style('whitegrid', {'font.sans-serif': ['simhei', 'Arial']}) 73 # 创建直方图 74 plt.figure(figsize=(10, 6)) # 调整图形大小 75 76 # 绘制直方图 77 plt.hist(data['release_date_streaming'], bins=30, edgecolor='k', alpha=0.7) 78 79 # 设置坐标轴标签和标题 80 plt.xlabel('时间日期', fontsize=12) 81 plt.ylabel('电影数量', fontsize=12) 82 plt.title('电影上线影院的时间分布', fontsize=14) 83 84 # 调整坐标轴刻度的旋转角度 85 plt.xticks(rotation=45) 86 87 # 显示图形 88 plt.tight_layout() # 自动调整布局,防止标签重叠 89 plt.show() 90 91 # 创建散点图 92 plt.scatter(data['runtime'], data['tomatometer_score']) 93 plt.xlabel('片长') 94 plt.ylabel('番茄表评分') 95 plt.title('电影上线影院的时间分布') 96 plt.show() 97 98 # 将上线流媒体日期转换为日期类型 99 data['release_date_streaming'] = pd.to_datetime(data['release_date_streaming']) 100 101 # 创建直方图 102 plt.hist(data['release_date_streaming'], bins=30) 103 plt.xlabel('时间日期') 104 plt.ylabel('电影数量') 105 plt.title('电影上线影院的时间分布') 106 plt.xticks(rotation=45) 107 plt.show() 108 109 # 计算每个电影的评分次数 110 review_counts = com[com['top'] == 1]['movie_name'].value_counts().head(10) 111 112 # 设置绘图样式 113 sns.set_theme(style='whitegrid') 114 # 解决中文乱码问题 115 sns.set_style('whitegrid', {'font.sans-serif': ['simhei', 'Arial']}) 116 117 # 绘制柱状图 118 plt.figure(figsize=(12, 6)) 119 ax = sns.barplot(x=review_counts.index, y=review_counts.values, palette='viridis') 120 ax.set_xlabel('电影名称', fontsize=12) 121 ax.set_ylabel('评分次数', fontsize=12) 122 ax.set_title('电影评论新鲜度TOP10', fontsize=14) 123 ax.set_xticklabels(review_counts.index, rotation=45, ha='right', fontsize=10) 124 ax.spines['top'].set_visible(False) 125 ax.spines['right'].set_visible(False) 126 127 # 添加标签 128 for p in ax.patches: 129 ax.annotate(f'{p.get_height()}', (p.get_x() + p.get_width() / 2, p.get_height()), ha='center', va='bottom', 130 fontsize=10) 131 132 plt.tight_layout() 133 plt.show() 134 135 # 生成十个随机颜色 136 random_colors = [] 137 for _ in range(10): 138 r = random.randint(0, 255) 139 g = random.randint(0, 255) 140 b = random.randint(0, 255) 141 color = '#%02x%02x%02x' % (r, g, b) 142 random_colors.append(color) 143 144 # 统计每个评论家的评论得分平均值 145 reviewer_scores = com.groupby('reviewer_name')['top'].mean() 146 147 # 选择前10名评论家 148 top10_expert_reviewers = reviewer_scores.sort_values(ascending=False).head(10) 149 150 # 创建水平条形图,应用随机颜色 151 plt.barh(top10_expert_reviewers.index, top10_expert_reviewers, color=random_colors) 152 153 plt.xlabel('平均评论分数') 154 plt.ylabel('名字') 155 plt.title('最会评论家TOP10') 156 157 plt.show() 158 159 # 创建一个空字典来存储每个电影的评论 160 comments = {} 161 # 遍历数据集,将评论按电影名称存储在字典中 162 for index, row in com.iterrows(): 163 movie_name = row['movie_name'] 164 comment = str(row['text']) # 将评论的值转换为字符串 165 if movie_name in comments: 166 comments[movie_name] += comment 167 else: 168 comments[movie_name] = comment 169 170 # 生成每个电影的词云可视化 171 for movie_name, comment in comments.items(): 172 # 创建词云对象 173 wordcloud = WordCloud(background_color='white', width=800, height=400).generate(comment) 174 175 # 绘制词云图像 176 plt.figure(figsize=(10, 5)) 177 plt.imshow(wordcloud, interpolation='bilinear') 178 plt.title(movie_name + ' 评论词云') 179 plt.axis('off') 180 plt.show() 181 182 183 184 # 读取数据 185 data = pd.read_csv('RottentomatoesMovies.csv') 186 187 # 选择两个变量进行分析 188 x = data['tomatometer_score'] 189 y = data['audience_score'] 190 191 # 计算相关系数 192 correlation = np.corrcoef(x, y)[0, 1] 193 print("相关系数:", correlation) 194 195 # 绘制散点图 196 plt.scatter(x, y) 197 plt.xlabel('Tomatometer Score') 198 plt.ylabel('Audience Score') 199 plt.title('Scatter Plot of Tomatometer Score vs Audience Score') 200 plt.show() 201 202 # 建立回归方程 203 regression_model = LinearRegression() 204 x = x.values.reshape(-1, 1) 205 regression_model.fit(x, y) 206 intercept = regression_model.intercept_ 207 slope = regression_model.coef_[0] 208 print("回归方程: y =", slope, "* x +", intercept)
五、总结
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
通过爬取Rotten Tomatoes网站的电影数据,获取了电影的名称、评分、类型、导演等信息。可以统计电影的新鲜度指数和观众评分,并进行比较和分析。可以根据电影的类型进行分类,了解各类电影在评分上的表现。可以分析电影的上映时间和时长,探讨与评分之间的关系。可以了解电影的制片公司和发行商,对电影产业进行分析。所获得的数据和分析对于进一步研究电影产业做出决策具有参考价值,达到了预期的目标。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
学习了如何使用Python编程语言进行网络爬虫,从网页中提取所需的数据。掌握了使用Selenium进行动态网页的爬取,并解决了网页加载和数据提取的问题。学习了使用XPath解析HTML页面,提取所需信息。熟悉了CSV文件的读写操作,将爬取到的数据保存为CSV格式。了解了数据分析和可视化的基本方法,通过统计和图表展示对数据进行分析。在爬取数据时,可以考虑增加异常处理机制,防止爬虫中断或出现错误。可以进一步完善数据分析和可视化的方法,提供更多的统计指标和图表展示,使得分析结果更加全面和直观。考虑将爬取到的数据存储到数据库中,以便更灵活地进行数据管理和查询。进一步优化代码结构和性能,提高爬取和分析的效率。在使用第三方库和工具时,要注意版本兼容性和安全性。