目录
简介
创新点
- Integrated Convolution and Self-Attention (ICSA) unit
提出集成卷积和自注意力单元,形成内容自适应变换 - Multistage Context Model (MCM)
多阶段的上下文模型,按照预安排的空间通道排序,进行精确的并行概率估计。
得到了比常用方法快60倍的解码速度。
内容
本文关注于图像压缩的变换和熵编码阶段
Entropy Coding Using Multistage Context Model
模型结构
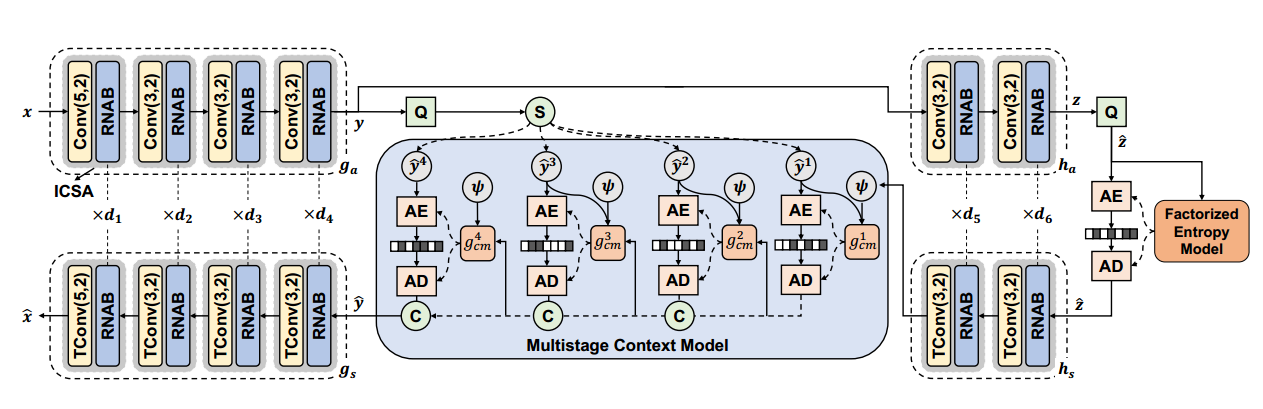
感觉是结合了<不均匀通道上下文模型>和< Swin Transformer>两篇文章
残差邻域注意力块Residual Neighborhood Attention Block RNAB
这里的RNAB设计的和Swin里的设计差不多,残差的 normlization层+注意力层+normalization层+MLP
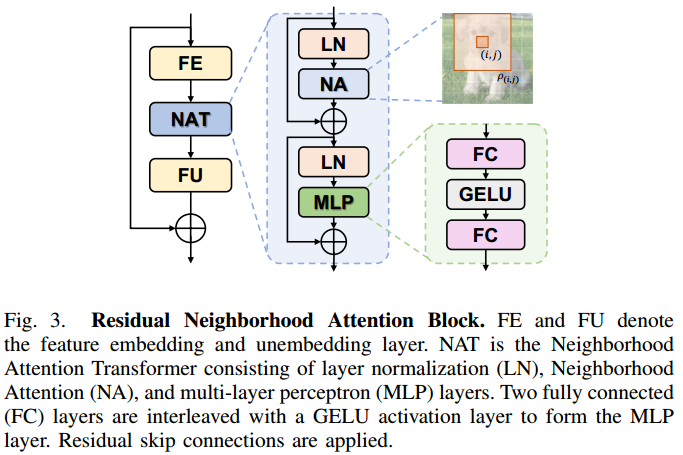
激活函数 高斯误差线性单元激活函数GELU
RNAB中用到了激活函数GELU,谷歌的BERT和OpenAI的GPT-2中都用到了该函数
\(G E L U(x)=x \times P(X<=x)=x \times \phi(x), x \sim N(0,1)\)在代码计算时,用\(G E L U(x)=0.5 x\left(1+\tanh \left(\sqrt{2 / \pi}\left(x+0.044715 x^3\right)\right)\right)\)去近似。
并行解码
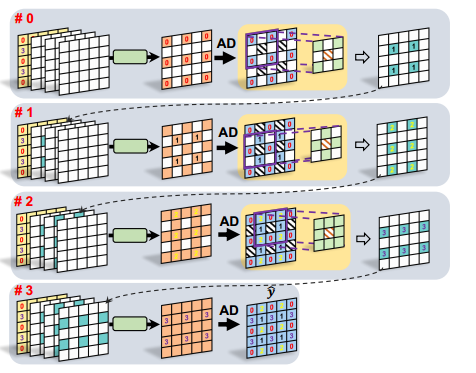
该解码过程也特别想棋盘上下文模型的并行解码。
- High-Efficiency Neighborhood Aggregation Information Efficiencyhigh-efficiency neighborhood aggregation information high-efficiency efficiency neighborhood interpolation neighborhood experience continuous neighborhood atcoder contest around neighborhood around atagc 062d efficiency guaranteed matching subgraph neighborhood source-free exploiting adaptation continuous efficiency transition improving