flex/bison usage in pgsql
In regular bison usage, we call yyparse() to get an AST. So, I searched for yyparse in PostgreSQL source code, which eventually led me to the base_yyparse() function. What is that?
In gram.y:
%name-prefix="base_yy"
%parse-param {core_yyscan_t yyscanner}
%lex-param {core_yyscan_t yyscanner}
This tells me that PostgreSQL has changed the conventional name yyparse to base_yyparse, which has one parameter core_yyscan_t yyscanner. What is core_yyscan_t?
In regular flex code, there is a scanner object of type yyscan_t. But in PostgreSQL, specifically in scan.l:
%option prefix="core_yy"
It renames yyscan_t to core_yyscan_t which maps to the opaque void * type.
Okay, that's fine. The next step is to know from where base_yyparse() is called.
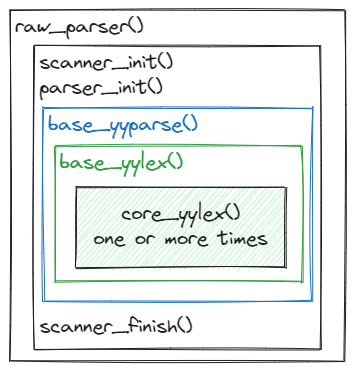
It is called from raw_parser() function in parser.c file.
parser.c::raw_parser()
|___ scan.l::scanner_init()
|___ gram.y::parser_init()
|___ base_yyparse()
|___ scan.l::scanner_finish()
From the article [[overview of flex and bison]], we know yyparse() calls yylex() internally.
In PostgreSQL, we use base_yylex() instead. This version of yylex() has three arguments:
extern int base_yylex(YYSTYPE *lvalp, YYLTYPE *llocp, core_yyscan_t yyscanner);
Where do they come from?
core_yyscan_t yyscanner is generated by the option line:
%lex-param {core_yyscan_t yyscanner}
YYSTYPE* lvalp is generated by the option line:
%pure-parser
YYLTYPE* llocp is generated by the option line:
%locations
Refer to the info bison section 4.3.6 Calling Conventions for Pure Parsers for more details.
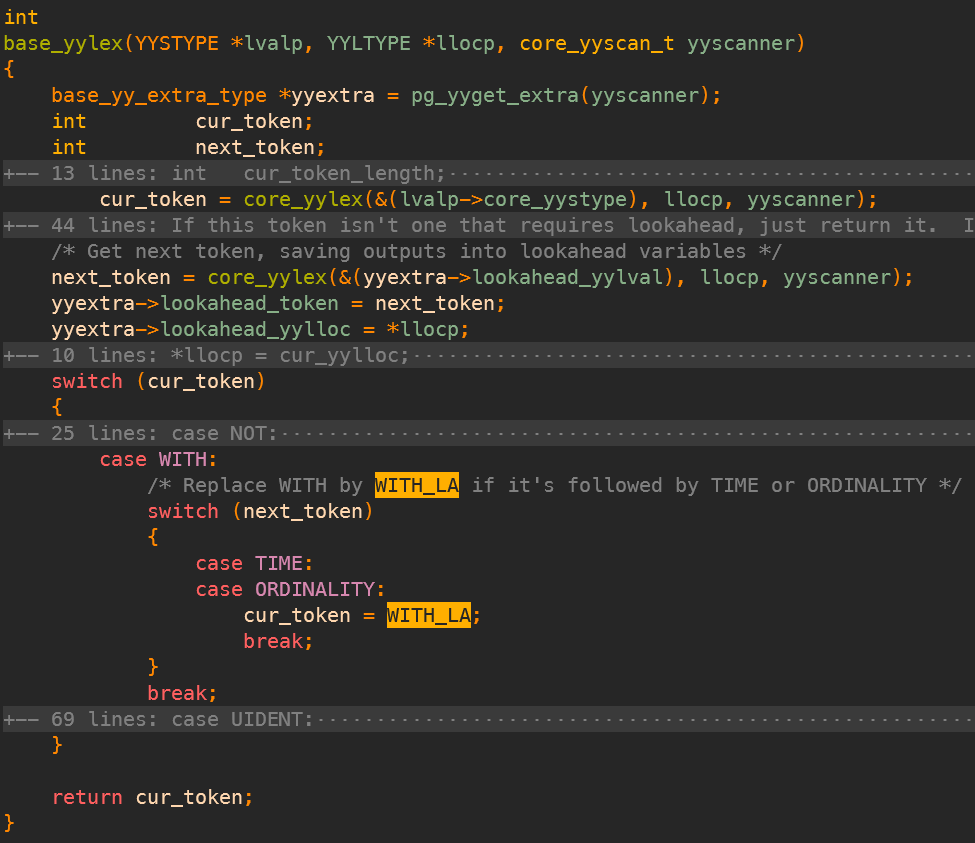
Inside the base_yylex() function, the lvalp and llocp values must be set to tell the bison generated parser the semantic value and token location. PostgreSQL dispatches that work to the unerlying core_yylex() method.Through this mechanism, base_yylex() is called a 'filter' in the PostgreSQL source code.
In normal cases, base_yylex() only calls core_yylex() once. In some particular cases, one lookahead token is not enough to make a shift/reduce decision. For those cases, we need to call core_yylex() more times to retrieve more consecutive tokens.
In PostgreSQL, the WITH_LA token is the special case relevant to this article. According to PostgreSQL source code, WITH_LA token is a multiword token.
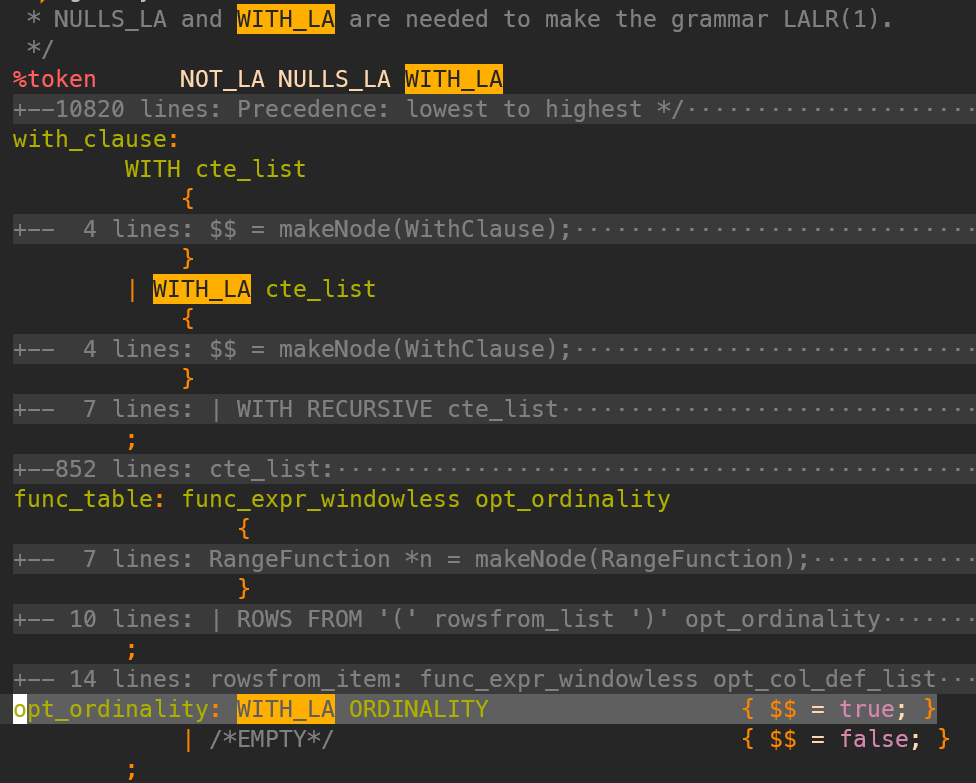
When does the lexical analyzer return the WITH_LA token?
Here is how to use with ordinality:

As PostgreSQL allows with ordinality being used in CTE, the parser needs to differentiate the two cases. Therefore, the WITH_LA token was introduced to enable the parser to look ahead when it encounters the with keyword.
Now, it is time to talk about with and ordinality keywords in PostgreSQL lexical scanner.
All keywords are kept in src/include/parser/kwlist.h.

By the way, use vim sort command to sort these keywords.
The kwlist.h is then included in scan.l file.
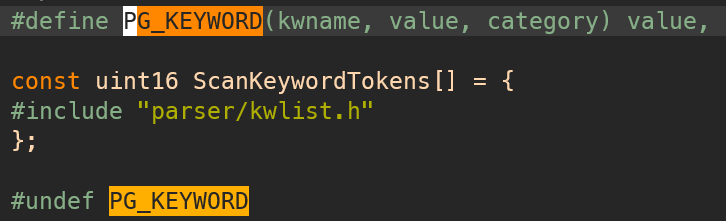
When the scanner reads an identifer, it uses some utility functions to find and return the keyword.
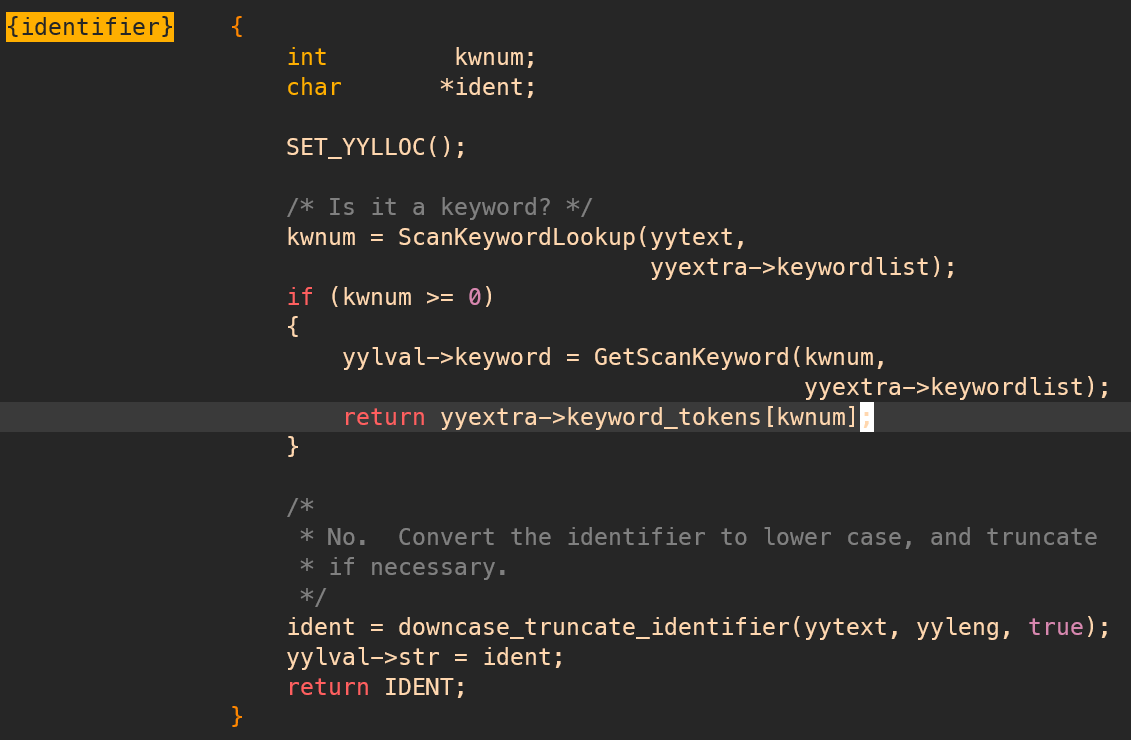
Let's use a picture to end this article.