众所周知,一般采用分布式设计的企业级应用,数据不可能单一的存储,往往会涉及到关系型数据库(mysql/sql等), redis ,以及mongo,solr 等非关系型, 尤其是涉及到APP应用时,快搜选用solr ,业务频繁访问的用mongo+redis, 后台管理可以用mysql ,分布式没错,但需要注意的是数据强一致性和业务高效快捷响应的取舍,要根据不同的需求场景来考虑不同的解决方案,此文不详谈,主要记录solr 的一些基础概率,使用方法,以及避免的坑.
solr 是有可视化界面的,可以直观的校验后台代码对接的数据是否正常,可视化界面如下,常用的功能已标记
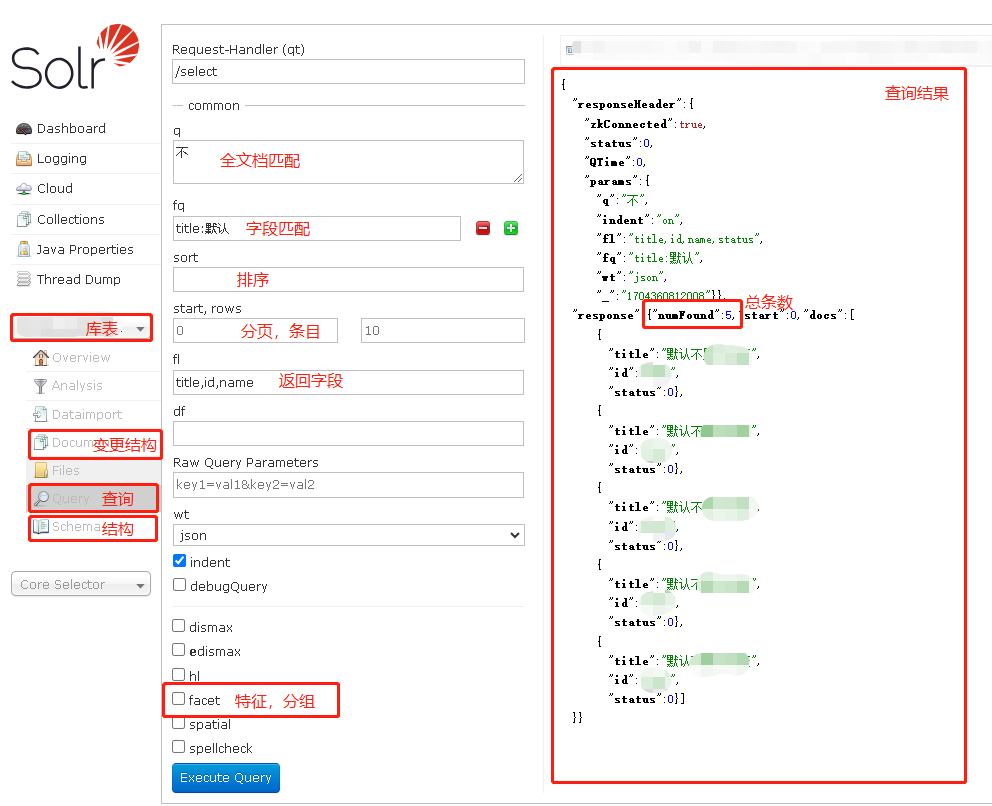
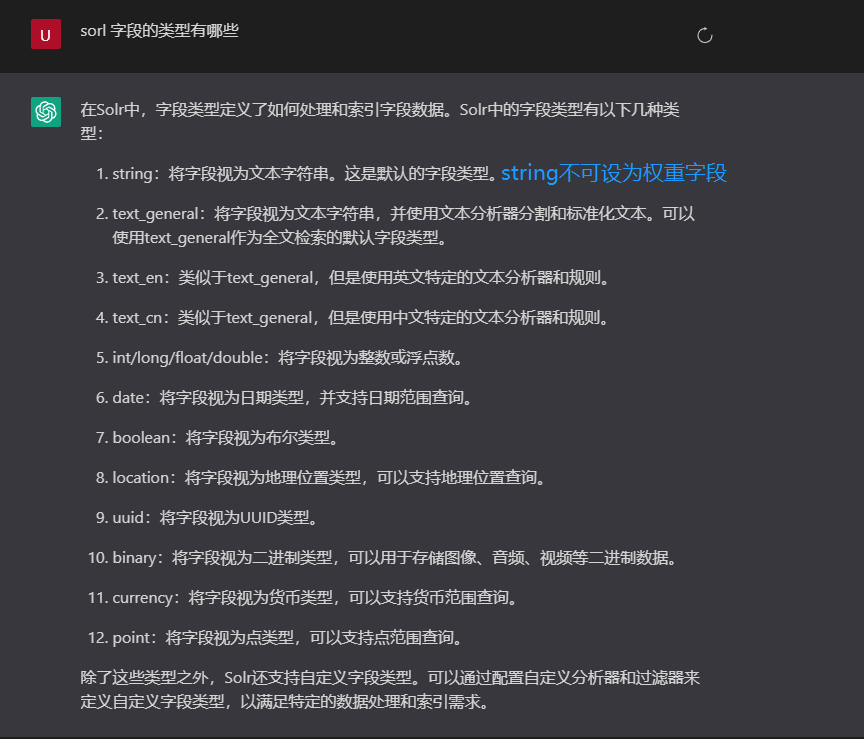
其次就是关于 solr 的一些数据结构,solr主要服务于文档类的业务,数据结构会稍有不同,可直接问话AI, 毕竟这年头AI 针对非数据收集类的回答,多少还是可信的, 对于代码层面的很多解决方案,还有待培训,一知半解或者基础不稳的同学很容易被忽悠住,尽信AI 不如没有AI,
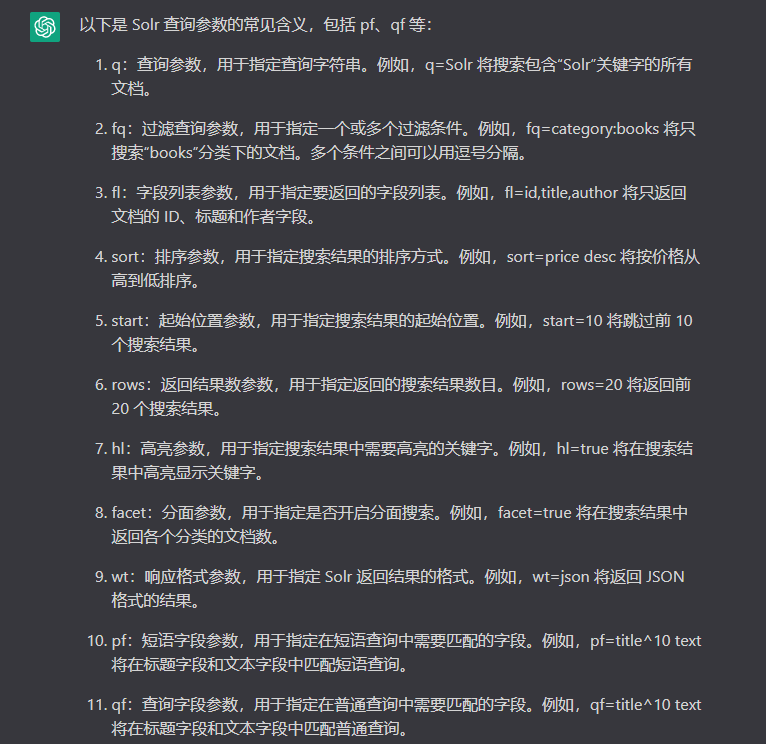
对于其他的一些参数,可以参考 这篇Solr文章
solr 的文档搜索,其实是有所谓的分词一说,针对这些分词(拆分文档内容为词条,然后去搜索匹配词条)会涉及到权重,啥又是权重呢?就是所谓的排名,占比,可以简单的解释为淘宝搜索X商品, 你的店铺是放在第一页被搜索出来还是在第100页才出现,就在这个权重上, 又比如比如我要搜索 姓名A, 标题B,内容C 三个字段中的某个关键词 K, 但是呢,对我来说标题更吸引我一些,内容第二,姓名其次, 那么搜索的结果就可以用到这个权重:
public string Qf { get { return "titlet^10 content^2 name^0.2"; } }
没有这种诉求的话,可以不设置Qf ,Pf 字段, 但是若设置,一定要确认清楚权重的字段类型,不能是string, 要调整为 text_general 才可以, 不然上线各种错误