受到HuggingGPT、Visual ChatGPT、AutoGPT等项目的启发,本文试图从LLM as Controller的统一视角来看LLM的能力边界。
LLM as Controller
我认为ChatGPT、GPT-4等LLM模型最强的能力其实是语言理解力,咱不需要让一个LLM做任何事情,只需要它能够准确无误的理解人类说的语言,再按照人类的语言去执行对应的任务即可。假如LLM的理解能力可以达到100分,那么只需要准确无误的调取最精确的工具就可以解决任何问题。
我将上述处理任务的流程总结为以下这个过程,LLM在这个流程中实际上充当的是Controller的角色,或者说是大脑。
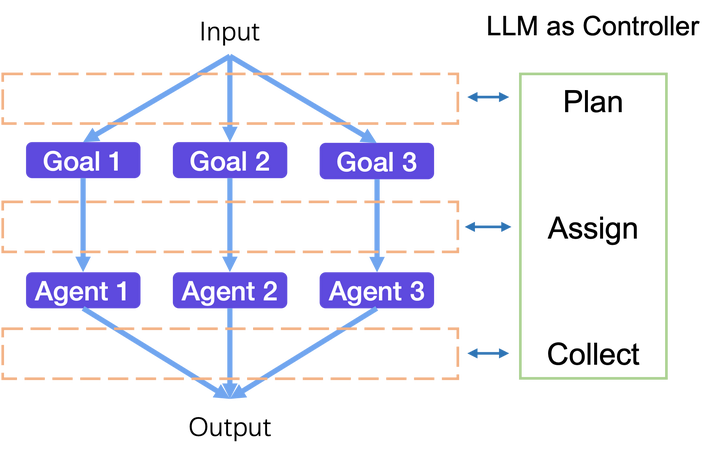
任何复杂任务都可以包含在上述流程之中,给定一个输入(包含需要做的事情以及条件),就能通过LLM控制一系列的agent来达成目标,并且得到输出结果。并且agent的数量和多样性是可以无限拓展的,假设LLM的语言理解能力是100分,那么就可以无限拓展LLM的能力边界。另外从算法的角度来理解,plan其实就是split,collect其实就是merge,整个流程就是分治思想的集中体现。
其中从Input到Output会进行3层处理,第一层会对输入目标进行拆解,并且得到一系列有顺序的目标,第二层会对每个子目标安排最合适的agent来进行处理,第三层会对所有的agent得到的结果进行汇总整合。其中agent可以理解为各种能力,可以是模型,可以是网页,也可以是工具,其中LLM作为这3层的总控制,去理解input的含义,并且给出最优的plan、assign和collect的处理。这个过程像极了一个庞大的组织架构的正常运转。
有了上述统一的概念理解之后,下文对最近最流行的LLM as Controller的项目做一个拆解,不同项目的主要差别在于LLM as Controller的逻辑以及各个专项Agent的能力,主要包含Visual ChatGPT、HuggingGPT、Toolformer、AutoGPT等项目。
Visual ChatGPT

实际上Visual ChatGPT的agent的范围是各种视觉的Foundation Models。
Visual ChatGPT实际上是最简单的一种LLM as Controller的项目,范围仅限于Visual Foundation Models,这种形态的项目,虽然能力边界小,但是LLM的负担是最轻的,每一个步骤以及流程是更加的可控,可能总共就只需要十几二十个流程。未来这种形态的工具或者产品对于各种垂直领域来说可能是更为常见的。
HuggingGPT
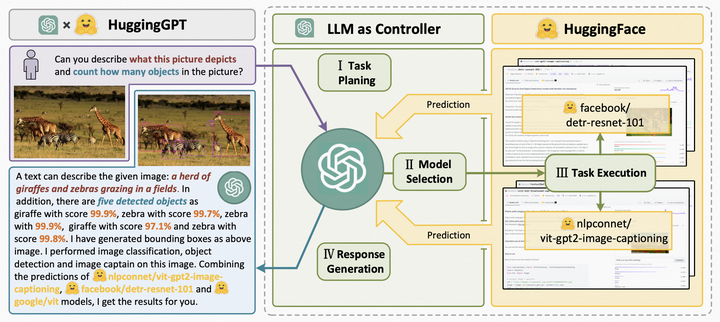
实际上HuggingGPT的agent的范围是huggingface所有模型。
HuggingGPT将LLM as Controller整个过程总结为4步:
• 任务规划:利用ChatGPT分析用户的请求,了解用户的意图,通过提示分解成可能解决的任务。
• 模型选择:为解决计划任务,ChatGPT 根据模型描述选择托管在Hugging Face 上的专家模型。
• 任务执行:调用并执行每个选定的模型,并将结果返回给ChatGPT。
• 生成结果:最后,使用ChatGPT整合所有模型的预测,为用户生成答案。
HuggingGPT的模式可控性也比较高,而且模型都是放在HuggingFace上进行托管的,输入输出的形式上也是一致的,用户使用以及代码维护都更为方便一些。
Toolformer

实际上Toolformer的agent的范围是各种外部工具。
上图中是Toolformer一种典型的用法,Toolformer可以自主决定调用不同的 API(从上到下:问答系统、计算器、机器翻译系统和维基百科搜索引擎)以获取对完成一段文本有用的信息。这个工作实际上也为后续的AutoGPT和BabyAGI等项目提供了灵感。
AutoGPT

AutoGPT其实就是在上述的基础之上,通过LLM反思input->plan->assign->collect->output整个过程,并且重新规划plan,从而产生一直迭代的auto效果。从外部的表现形式上来看,整个系统不断的交替进行plan和reflect,已经出现了自我思考自我迭代的过程。这实际上已经到了autonomous agents的范畴了。
实际上AutoGPT的agent的范围就是各种网页以及各种工具。
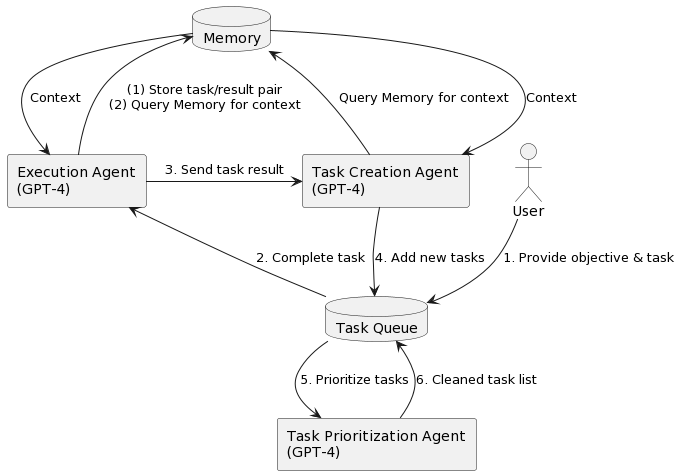
上述流程图来自BabyAGI,下面举一个简单的例子来阐述Autonomous Agent的思想:
假设有一个可以帮助研究的autonomous agent,并且我们想要关于某个主题的最新消息的总结,比如说“关于 Twitter 的新闻”,我们告诉agent你的目标是找出有关 Twitter 的最新消息,然后向我发送摘要”。
- agent查看目标,使用 OpenAI 的 GPT-4 等LLM模型,使其能够理解正在阅读的内容,并提出第一个任务。 “任务:在谷歌上搜索与 Twitter 相关的新闻”。
- 然后agent在谷歌上搜索 Twitter 新闻,找到热门文章,并返回一个链接列表。 第一个任务完成。
- 现在agent回顾它的主要目标(找到关于 Twitter 的最新消息,然后发送摘要)和它刚刚完成的事情(得到一堆关于 Twitter 的新闻链接)并决定它的下一个任务需要是什么 .
- agent提出了两个新任务。 1)写新闻摘要。 2) 阅读通过谷歌找到的新闻链接的内容。
- 现在agent在继续之前停止了一秒钟,它需要确保这些任务的顺序正确。 真的应该先写摘要吗? 不,它决定了最优先阅读通过google找到的新闻链接的内容。
- agent从文章中读取内容,然后再次返回待办事项列表。 它想添加一个新任务来总结内容,但该任务已经在待办事项列表中,所以它没有添加它。
- agent检查待办事项列表,唯一剩下的项目是总结它阅读的内容,所以它这样做了。 它会按照您的要求向您发送摘要。
目前autonomous agent还比较初级,因为agent的范围太大了,无边无际,非常的不可控,但是这个概念非常的强大,随着不断的发展和实验,未来会慢慢的融入我们的日常生活。
接下来再介绍两个比较有意思的项目,可以开拓一下思维。
NexusGPT

上文中提到,整个LLM as Controller系统像极了一个庞大的组织架构的正常运转,事实上,也有脑洞大开的开发者沿着这个思路做了一个NexusGPT项目,简单理解就是每个Agent实际上可以认为是一个人,每个agent擅长不同的事情,那么一个庞大的组织架构可以通过雇佣擅长各种能力的Agent来维持组织的正常运转。
Generative Agents

斯坦福和谷歌的研究者们利用人工智能创造出的生成式智能体。研究人员一共设置了25个角色,并且给每个角色都设定了姓名和职业等基本信息。传统的NPC都是先给他们安排好剧本,安排好话术,该到哪步就说哪句话。而随着ChatGPT的出现,这些游戏角色的对话可以在只输入关键信息的前提下,自我生成。
LLM as Controller—系统稳定性
上文的阐述中都是基于假设LLM语言理解能力为100分的情况,能力边界是可以无限拓展的,但事实上LLM仍然会存在一定的事实性错误。这会影响整个系统的稳定性,并且稳定程度取决于LLM的语言理解能力,以及各个Agent的专项能力。
另外值得注意的是,goal之间、agent之间可以引入相互影响,但是个人认为这样子会使得不同流程的处理变的更加复杂,整个系统的稳定性会下降不少。
LLM as Controller—自然语言编程

以往的编程方式通常是左边这张图的形式,规范好函数的格式化输入和格式化输出,程序主体可以执行特定的功能,而随着LLM的能力不断增强,事实上未来会发生右图编程形态的转变,自然语言输入通过LLM并行控制多个函数的调用,并且通过LLM将多个函数的调用结果进行总结,最终返回自然语言输出,而LLM在其中的执行方式通常是通过Prompt的形态来执行的,Prompt也是自然语言,这个过程可以认为是自然语言编程。
并且其中的格式化输入、格式化输出以及简单的程序主体通常是标准化的,LLM也可以同时去做所有的标准化任务,未来人类可能只需要编写复杂的、非标准化的程序主体。换句话说,LLM可以用自然语言编程的方式去统一所有标准化的内容。右图中的橙色部分可能都会变成自然语言编程的一部分。
LLM as Controller—AI操作系统的雏形
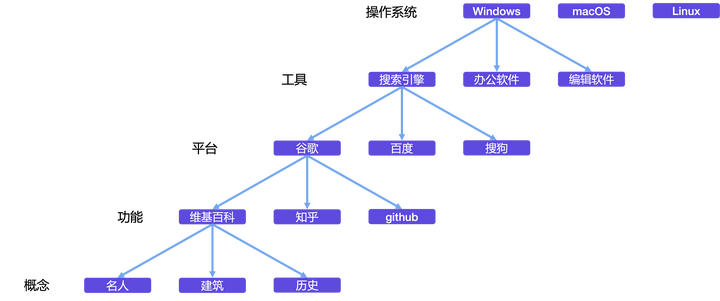
首先我从原来的Windows/macOS/Linux等操作系统的模式说起,比如Windows操作系统上可能有搜索引擎/办公软件/编辑软件等等,然后搜索引擎有谷歌/百度/搜狗等等,谷歌可以搜索到维基百科/知乎/github等等网站,维基百科可以找到名人/建筑/历史等信息。上图的划分方式是为了下文阐述的简化表达。
办公软件比如office全家桶,office全家桶有ppt、word等等,ppt里面又有很多功能点。
编辑软件比如adobe全家桶,adobe全家桶有PS、AE、AI等等,PS里面又有很多功能点。

其中每个分叉都可以认为是一个聚合体单元,其实就是对应最开始描述框架下的Agent,只不过Agent在不同层次的概念粒度以及复杂程度是不同的。比如上图中的维基百科就可以认为是各种概念信息的聚合体。

在搜索引擎出现之前,人们找需要的信息时,需要从对应的网站找对应的信息,这是多个输入对应多个输出的情况;而搜索引擎就是通过更强大的搜索算法对各种网站进行了聚合,即出现了更大概念的Agent,这个时候输入口变成了1个,但是输出仍然需要跳转到各个网站上去获取;而LLM的出现会使得输入输出都变成1个口,并且对输入的精确表达程度要求更低。从这个演化过程来看,LLM会导致完全统一输入输出的Agent的出现,这个时候用户可以无需关心Agent内部的具体构造(即Agent内部完全黑盒化,由LLM自己决策中间过程),只需要输入并获取想要的输出。
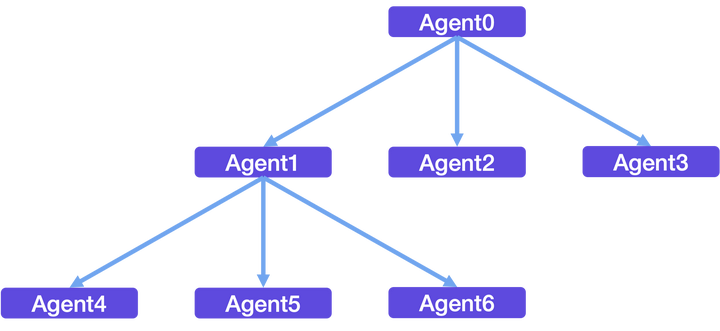
从上述Agent单元的阐述来看,Windows/macOS/Linux等操作系统都可以简化成上图,即不同概念粒度Agent组成的多层Agent树。每个概念粒度的Agent都会逐渐标准化。从Agent的角度来看,HuggingGPT、Visual ChatGPT实际上就是模型管理功能的Agent。
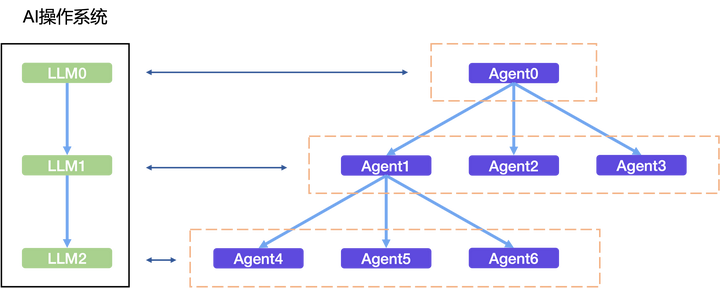
如果在每一层或者每一个Agent单元配备一个LLM作为控制器,并且所有LLM都是信息互通的,并且LLM的语言理解能力是100分,那么可能就会出现真正的AI操作系统。通过AI操作系统中的所有LLM联动控制,可以将一个复杂任务拆分成不同层次的子任务,然后通过所有的Agent联动处理,最后输出想要的结果。
Windows/macOS/Linux等操作系统通过程序编程给出UI界面,然后用户通过鼠标点击和UI界面进行交互完成工作;而AI操作系统可能会变成只需要理解用户的语言就能完成工作。这个转变可能会导致鼠标点击和UI界面进行交互的方式可能会变得越来越冗余。
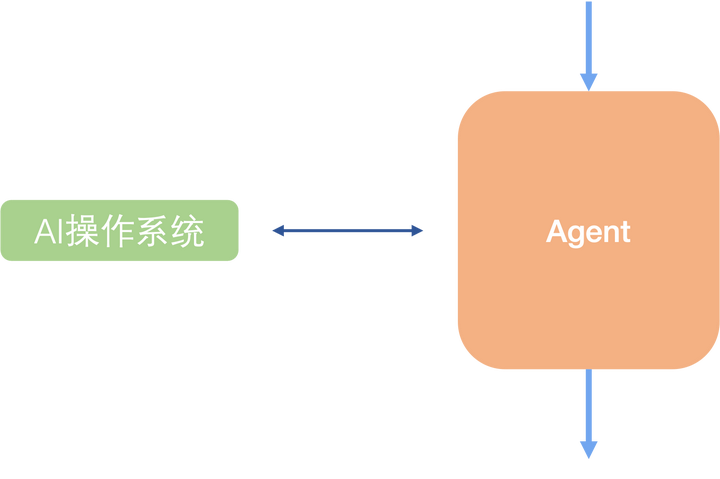
如果AI操作系统只需要理解用户的语言就能完成工作,那么所有不同粒度的Agent就能看成一个黑盒子(因为中间的所有决策环节都由LLM决定了),即一个最大聚合体Agent,而它的内核就是AI操作系统。
从AI操作系统的角度来看,实际上AutoGPT试图自顶向下的构建最大范围的Agent,正是因为范围过于广阔,导致中间过程非常的不可控;而类似HuggingGPT、Visual ChatGPT更倾向于自底向上搭建更可控的Agent,Agent能做的事情都是事先知道的。
相关参考
https://www.mattprd.com/p/the-complete-beginners-guide-to-autonomous-agents
thinkthinking:NexusGPT——目前为止看到的最有创意的Autonomous Agents类项目!附该领域进展概览
本文来源:https://zhuanlan.zhihu.com/p/626736120