前言 在CVPR 2023上,南洋理工大学-商汤科技联合实验室S-Lab的研究者提出的基于Encoder的快速3D GAN Inversion方法,针对现有3D GAN inversion方法无法兼顾重建速度、重建质量和编辑质量的问题,提出一种自监督3D GAN inversion训练框架。同时,通过构建全局-局部的多尺度结构以及2D-3D混合对齐模型实现了高保真、可编辑的3D重建。该方法适配包括StyleSDF、EG3D等SoTA 3D GAN模型,并在多个基准测试中取得了优异成绩。
本文转载自我爱计算机视觉
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
研究背景
近一两年来,通过使用GAN inversion将真实图片投影到GAN潜在空间,基于2D StyleGAN Inversion的方法在图像语义编辑任务上取得了显著进展。近期出现了一系列 [6,7] 基于StyleGAN结构的3D生成模型研究,然而,相应的通用3D GAN inversion框架仍然缺失,这极大地限制了基于3D GAN模型的重建和编辑相关应用。
由于3D重建的歧义性以及缺少2D-3D的配对数据,我们无法直接将2D GAN inversion的框架应用到3D GAN inversion。同时,由于单一隐变量的表达能力受限,通过现有inversion方法难以重建高质量的3D几何和纹理信息。此外,如何进一步支持高质量的3D编辑依然是一个待解决的问题。
为了解决上述问题,我们提出一个有效的自监督方法约束学习空间,并设计了一个全局-局部的多尺度模型来准确重建几何和纹理细节。该方法在2D、3D的基准数据集测试上都取得了更优的表现。
输入图片:

重建结果:


Editing 结果(+Smiling):


Stylization 结果:


方法
我们认为,一个有效的3D GAN inversion框架应该具备以下特点:
1. 给出单张视角图片作为输入,该方法能够重建合理的3D几何2. 保留高清的纹理信息3. 支持基于3D的语义编辑
基于以上标准,我们提出了E3DGE框架,并将该问题分解为三个子问题分别解决。第一步,我们借鉴Sim2Real[1]的思路,将预训练的3D GAN视为一个拥有海量2D-3D数据对的集合。由于每一个高斯随机噪声z都能够采样得到 3D几何以及对应的某一视角下的2D图片,我们能够在训练过程中在线生成每一个batch的训练数据。同时,因为有了2D图片对应的3D几何ground truth,我们在2D监督信号的基础上,同时加入了3D重建的约束。这使得我们可以学习得到3D-aware的latent space,避免了单纯使用2D 监督信号导致的几何坍塌问题。

第二步,相关研究[2]显示,传统GAN inversion所采用的单一低维隐变量空间缺乏建模高频细节例如纹理的能力,降低视觉效果。3D inversion问题相比2D inversion所需建模的空间更大,对模型表征能力的要求更高,因此高清纹理建模问题变得更加严重。受到近期3D小样本重建方法[3]的启发,在共享的全局隐变量基础上, 我们提出引入局部隐变量提升模型的表达能力,弥补第一阶段重建中丢失的局部细节。其中,局部隐变量的值取决于具体的3D坐标在2D残差图上投影位置的特征。如下图所示,我们计算在第一阶段重建中丢失的局部细节残差图并将残差图送入2D Hourglass [4]模型以提取缺失信息的特征,并联合所在位置结构编码作为补充特征一起与全局特征进行融合。融合过后的特征拥有准确生成重建任意视角的表达能力。
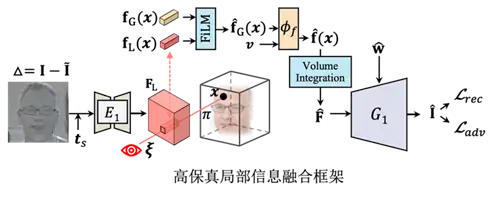
通过以上设计,我们的方法能够实现高保真度的2D-3D重建和视角生成,但依然无法支持任意视角的编辑。
我们分析认为,输入视角的重建效果和任意新视角的编辑效果是相互权衡的:首先,在测试阶段,当输入图片被编辑或者测试视角与输入视角不符时,我们上一个阶段得到的残差图会导致错误的输出;同时,如果我们监督模型重建自身,模型更倾向于学习到回归式的特征,而非生成式的特征。为了解决上述第一个问题,我们提出使用2D-3D混合对齐的方式来推导对齐的特征。具体而言,由于任意新视角编辑结果与残差图结果不匹配,我们使用一个2D对齐模块使得最终的融合特征能够输出高质量的新视角编辑效果。
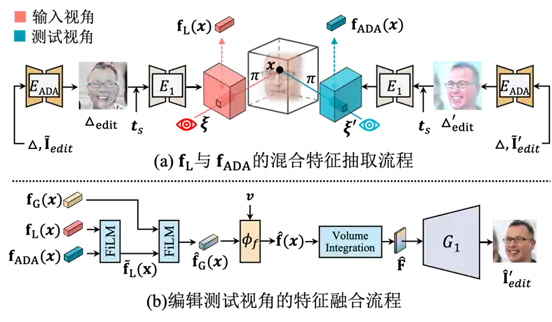
为了解决第二个问题,促使模型学习生成式特征,在GAN数据生成阶段,对于同一个高斯噪声z,我们随机采样两个视角并渲染得到两张目标图片。我们交换重建目标视角并训练模型来重建新视角。该训练策略在促使模型学习生成式特征的基础上,也能够让训练和测试的行为一致,更有助于保证在场景编辑上的高质量视角生成。
训练
由于使用了预训练的3D GAN生成的2D-3D数据对,我们同时使用了2D和3 重建的损失函数:
在3D损失函数中,我们发现同时约束物体表面点集和空间均匀采样点集 会带来更好的 3D 约束效果。
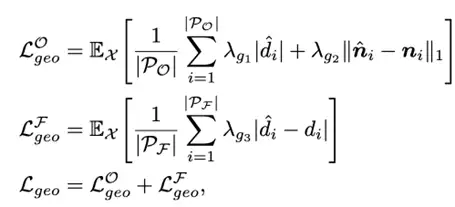
实验
由于其良好的几何性质和高保真的图片生成能力,在本篇工作中我们选择了StyleSDF[7]作为GAN inversion预训练基础模型。
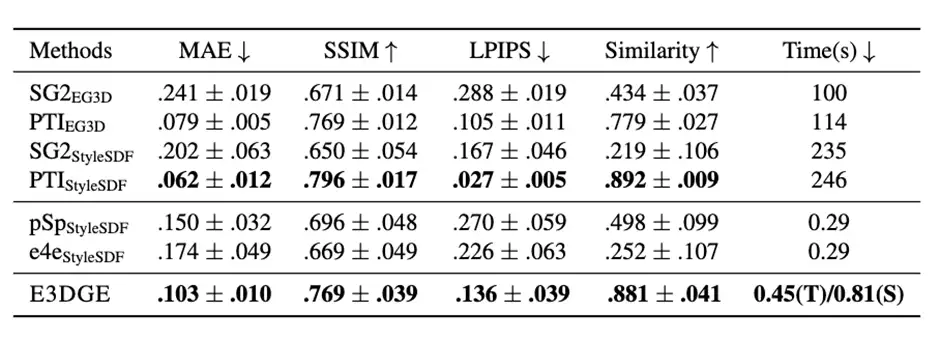
我们在FFHQ数据集上进行训练,并同时在2D和3D基准测试上对我们的方法进行了测试。在2D重建效果上,在CelebA-HQ数据集上进行输入视角重建的测试,并相比baseline获得了更优的表现:

在数值结果上,我们的方法在多种指标下都取得了最优的表现,而且推理速度大幅优于optimization-based方法:
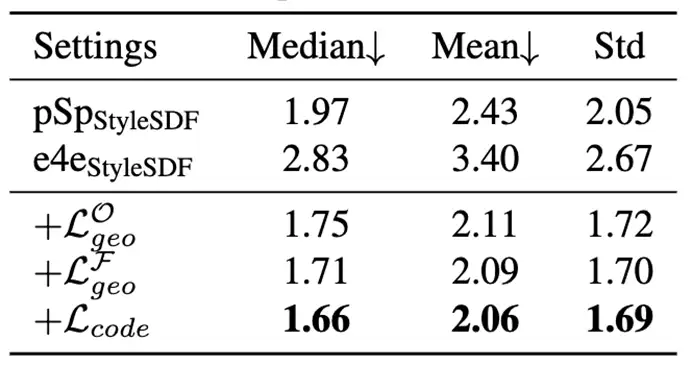
在3D 重建效果上,我们采用人脸3D重建数据集NoW[5]进行测试,验证了我们方法中3D监督的有效性。Median、Mean指重建的3D face与ground truth mesh表面的偏移距离统计量。
同时,我们的方法也能够在风格化3D GAN上表现出很好的效果:

作者介绍
兰宇时,南洋理工大学S-Lab PhD student,本科毕业于北京邮电大学,目前主要研究兴趣为基于神经渲染的3D生成模型、3D重建与编辑。
传送门
论文链接
https://arxiv.org/abs/2212.07409
论文代码
https://github.com/NIRVANALAN/E3DGE
项目主页
https://nirvanalan.github.io/projects/E3DGE/index.html
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
中科院自动化所发布FastSAM | 精度相当,速度提升50倍!!!
大核卷积网络是比 Transformer 更好的教师吗?ConvNets 对 ConvNets 蒸馏奇效
MaskFormer:将语义分割和实例分割作为同一任务进行训练
CVPR 2023 VAND Workshop Challenge零样本异常检测冠军方案
沈春华团队最新 | SegViTv2对SegViT进行全面升级,让基于ViT的分割模型更轻更强
刷新20项代码任务SOTA,Salesforce提出新型基础LLM系列编码器-解码器Code T5+
CVPR最佳论文颁给自动驾驶大模型!中国团队第一单位,近10年三大视觉顶会首例
最新轻量化Backbone | FalconNet汇聚所有轻量化模块的优点,成就最强最轻Backbone
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary