对比
通过⼀段代码运⾏来体会ndarray与Python原⽣list运算效率对⽐。
import random import numpy as np import time # 创建包含随机数的列表 a = [] for i in range(1000000): # 我减小了迭代次数以避免内存问题 a.append(random.randint(1, 100)) # 生成1到100之间的随机数 # 使用Python内置的sum函数计算列表的总和 start_time = time.time() sum1 = sum(a) end_time = time.time() execution_time = end_time - start_time print(f"Python list求和执行时间: {execution_time} 秒") # 将列表转换为NumPy数组 b = np.array(a) # 使用NumPy的sum函数计算数组的总和 start_time = time.time() sum2 = np.sum(b) # 使用np.sum而不是内置的sum end_time = time.time() execution_time = end_time - start_time print(f"NumPy数组求和执行时间: {execution_time} 秒")
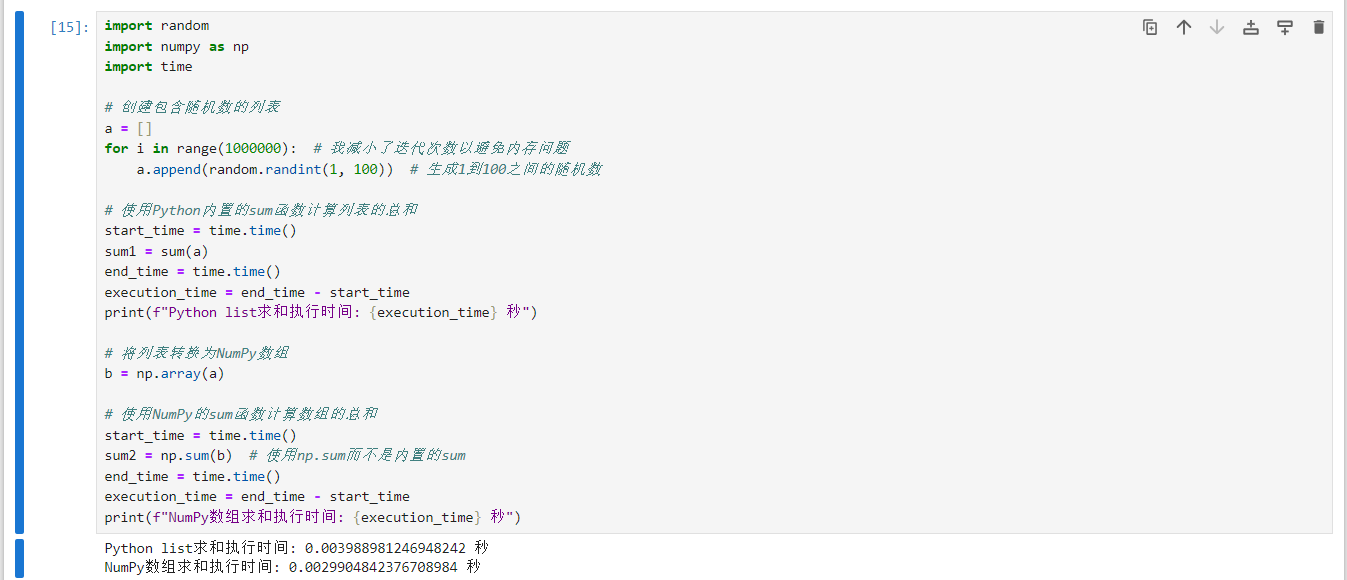
从示例上看numpy比原生list要快,其内存模型对比:
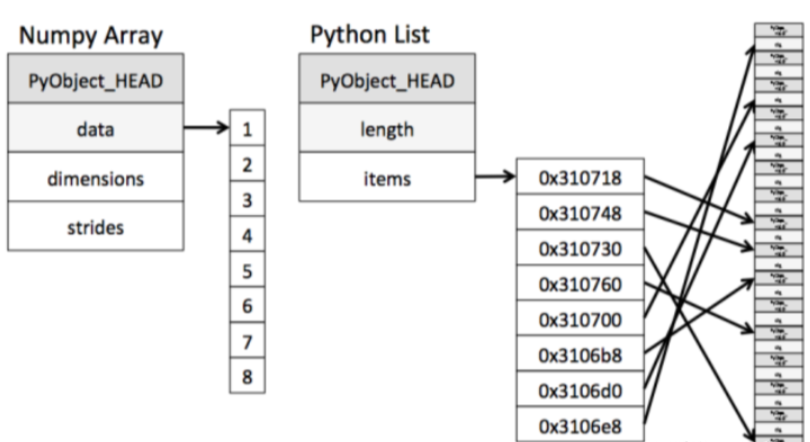
从图中我们可以看出ndarray在存储数据的时候,数据与数据的地址都是连续的,这样就给使得批量操作数组元素时速度更快。
这是因为ndarray中的所有元素的类型都是相同的,而Python列表中的元素类型是任意的,所以ndarray在存储元素时内存可以连续,而python原生list就只能通过寻址方式找到下一个元素,这虽然也导致了在通用性能方面Numpy的ndarray不及Python原生list,但在科学计算中,Numpy的ndarray就可以省掉很多循环语句,代码使用方面比Python原生list简单的多。
ndarray的优势【掌握】
内存块风格
list -- 分离式存储,存储内容多样化
ndarray -- 一体式存储,存储类型必须一样
ndarray支持并行化运算(向量化运算)
ndarray底层是用C语言写的,效率更高,释放了GIL
总结
1. 高效的数组计算:NumPy的ndarray被设计用于高效的数值计算。它们可以比Python的内建数据结构快很多倍,尤其是在进行大规模数据操作时。
import numpy as np # 创建两个大型数组 a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) b = np.array([10, 9, 8, 7, 6, 5, 4, 3, 2, 1]) # 数组加法 c = a + b print(c)

2. 内存效率:ndarray在存储和处理数据时非常节省内存。数组中的元素使用相同的数据类型(具有固定大小),这意味着它们在内存中紧密排列,这种存储方式比Python的列表等数据结构更为高效。
3. 矢量化操作:NumPy允许你对ndarray执行矢量化操作,而不是使用循环。例如,你可以一次性对整个数组进行加法或乘法等操作,这样可以显著提高代码的性能和可读性。

4. 广播能力:NumPy的广播规则允许执行不同形状数组之间的算术运算,这在纯Python操作中是无法做到的。

5. 集成C/C++/Fortran代码的能力:NumPy可以很容易地与C、C++或Fortran等语言编写的代码集成。这意味着如果算法不能通过NumPy本身高效实现,可以用这些语言编写,然后在Python中调用。
6. 丰富的函数库:NumPy提供了大量的数学函数用于快速操作ndarray,包括数学运算、逻辑运算、形状操作、排序、选择、I/O操作、离散傅里叶变换、基本线性代数、基本统计运算等。

7. 灵活的索引和切片:ndarray支持多种索引方式,包括基本的索引、切片、高级索引等,这使得数据操作更加灵活和强大。

8. 多维数组处理能力:NumPy能够处理任意维度的数组,而不仅仅是1D或2D数组,这使其在科学计算中特别有用。

9. 与其他Python科学计算库的集成:NumPy是SciPy、Pandas、Matplotlib、scikit-learn等流行科学计算库的基础,这些库依赖于NumPy的数组以及其它功能。
综上所述,ndarray的这些优势使其在科学计算、数据分析、机器学习等领域中发挥着重要作用。