摘要
目前已有的连续语义分割方法通常基于卷积神经网络,需要添加额外的卷积层来分辨新类别,且在蒸馏特征时没有对属于旧类别/新类别的区域加以区分。为此,作者提出了基于Transformer的网络incrementer,在学习新类别时只需要往decoder中加入对应的token。同时,作者还提出了对于旧类别区域的蒸馏以及类别解混策略。最终模型在VOC和ADE两个数据集上都达到了SOTA。
方法
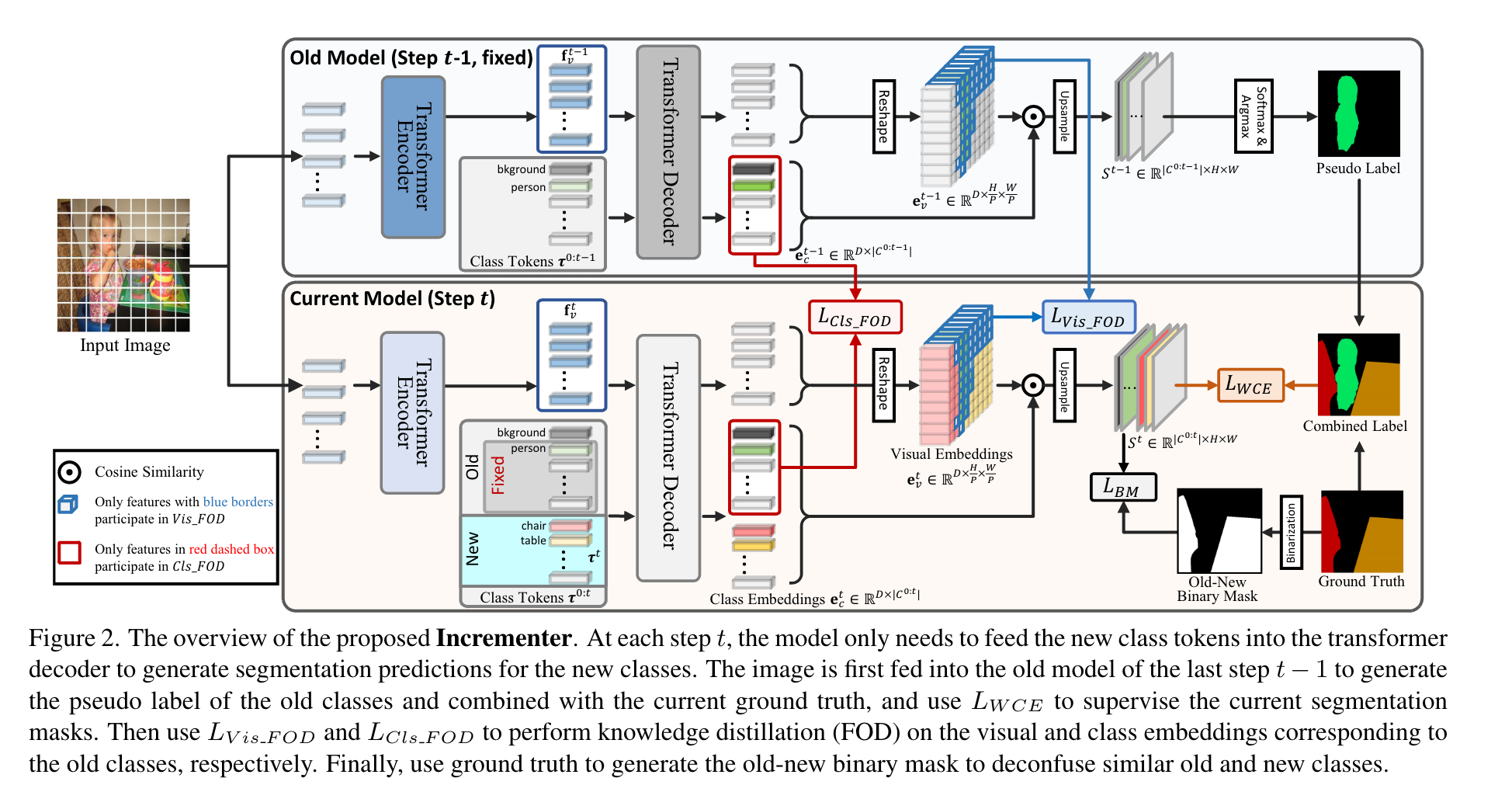
Incrementer Structure
模型整体框架就是一个Vision Transformer的结构,分为编码器和解码器两部分。特别的,为了在不添加额外网络结构的前提下实现增量过程中对于新类别的学习,作者收到Segmenter的启发,为每个类别(包括背景)分配了一个可学习的class token,之后将这些class token与encoder的输出进行拼接,送入decoder以得到对应的visual embeddings以及class embeddings。最后,每个类别的mask通过计算class embedding与visual embedding的相似度得到。在增量学习的过程中,为了防止相似度分数的计算受到新类别的影响,作者对于mask的生成使用了余弦相似度,首先对embedding进行l2归一化,之后通过下式得到mask:\(S'=\gamma \overline{e}_c\overline{e}_v^T,S'\in \mathbb{R}^{(M+1)\times N}\)。将其插值回原图大小就得到了最终的分割结果。基于上述框架,可以很方便地通过添加新类的class token实现类增量学习,在每个增量步骤t将旧类的class token冻结,与新类的class token还有visual feature一起送入decoder得到分割图。为了缓解背景偏移,作者使用了PLOP的伪标签策略,最终的损失计算如下:
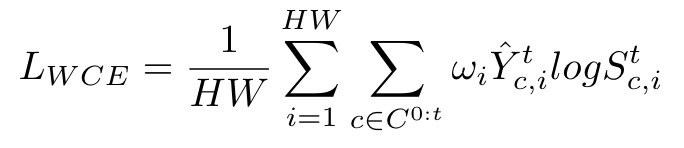
其中\(\omega_i\)的作用是减轻模型对于新类的过拟合。
Knowledge Distillation Focusing on Old Class
现有的知识蒸馏方法不对特征图中属于不同类别的区域加以区分,旧模型会将新类别对应的区域认作背景,直接蒸馏会限制新模型的可塑性。为此,作者提出了FOD,只对visual feature中不属于新类别的区域进行蒸馏,即根据gt选取不包含新类别像素的visual tokens进行蒸馏。因为在生成mask时使用了cosine similarity,这里同样使用cosine similarity以保持相似度测量的一致性,避免使用l2-distance等硬知识蒸馏损失而牺牲可塑性。蒸馏损失计算如下:
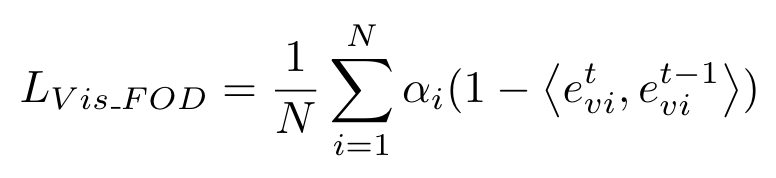
其中:
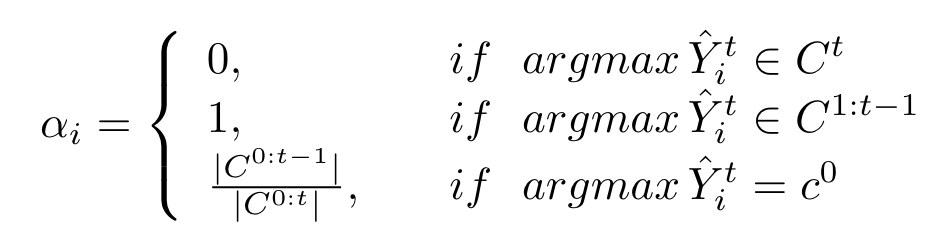
对于伪标签中标记为背景的像素(不确定是旧类or新类)乘以系数\(\frac{C^{0:t-1}}{C^{0:t}}\)进行调节。如此只是在局部进行蒸馏,作者还对新旧模型decoder输出的旧类别class tokens进行蒸馏,从而约束模型对于全局特征的预测一致,公式如下(\(\beta_i\)的含义与上面的\(\alpha_i\)类似):
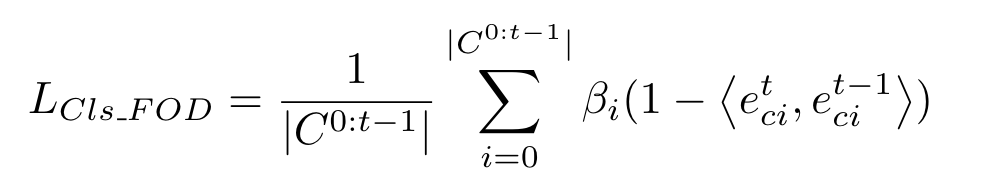
最终总的蒸馏损失就是\(L_{FOD}=L_{Vis_FOD}+L_{Cls_FOD}\)。
Class Deconfusion Strategy
在每次学习一个类且学习的步骤有多个时,模型对于新类的过拟合现象较为严重,同时,如果新类与某些旧类较为相似,模型则很容易将其混淆。为此,作者提出了CDS,首先通过权重\(\omega_i=\lambda \sqrt{\frac{C^t}{C^{0:t}}}\)降低对于新类的损失;其次,为了减轻模型对于新类与旧类的混淆问题,作者通过模型生成一个mask \(B^t\)以区分新类和旧类:
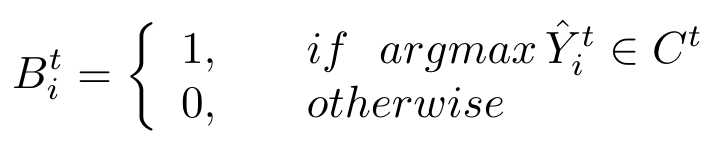
同时使用预测结果\(S^t\in \mathbb{R}^{|C^{0:t}|\times H\times W}\)沿通道维度相加,生成\(S_O^t\)以及\(S_N^t\):
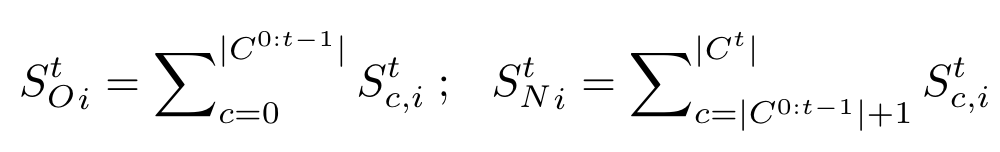
最后通过\(B^t\)监督\(S_O\)和\(S_N\)的生成,损失为dice loss:
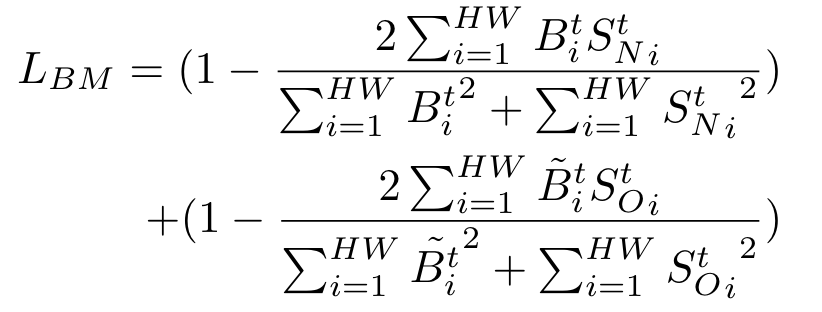
其中\(\tilde{B}_i^t\)是对\(B_i^t\)取反得到的。
总的损失为\(L=L_{WCE}+L_{FOD}+L_{BM}\)。
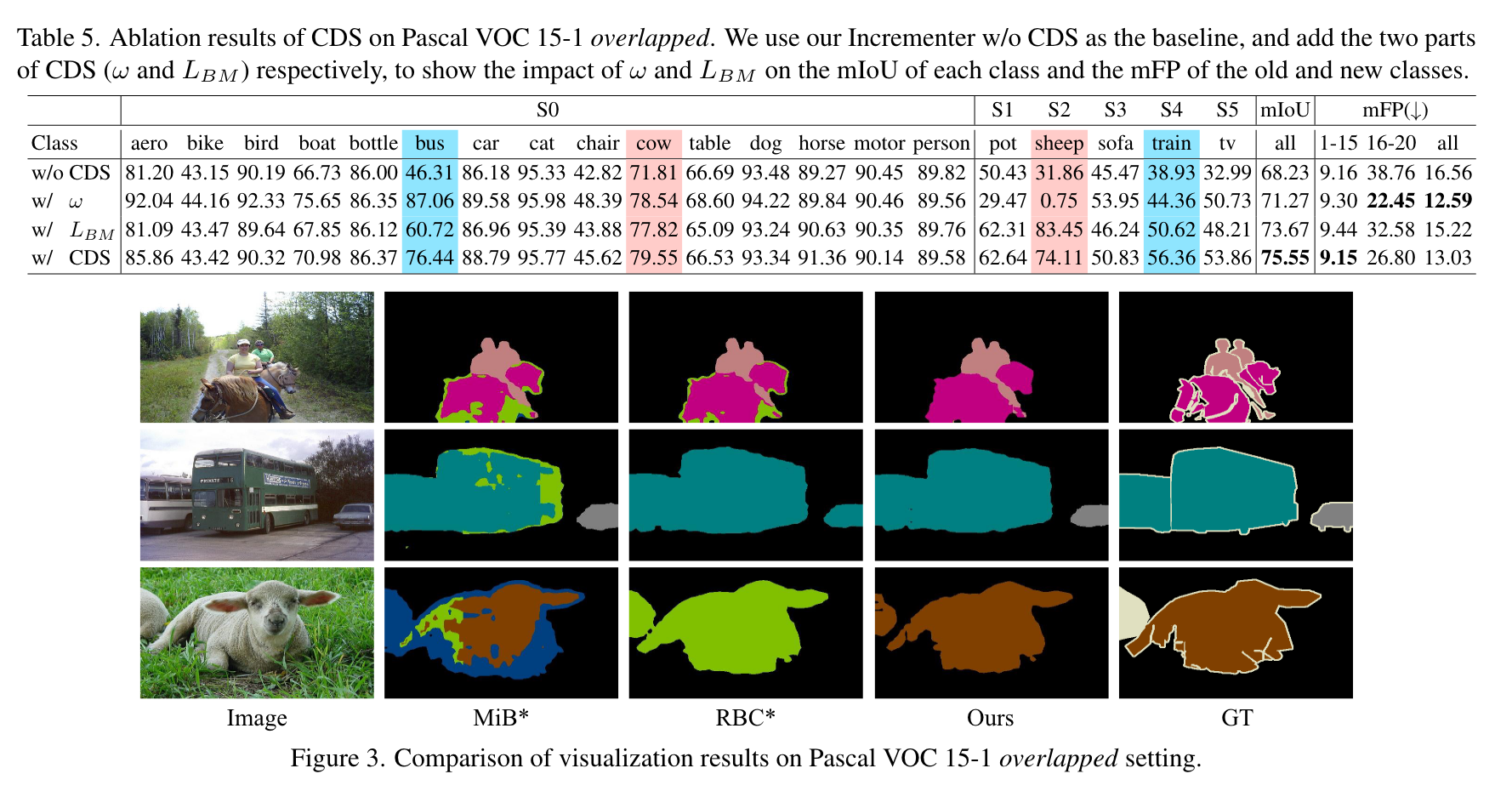
实验
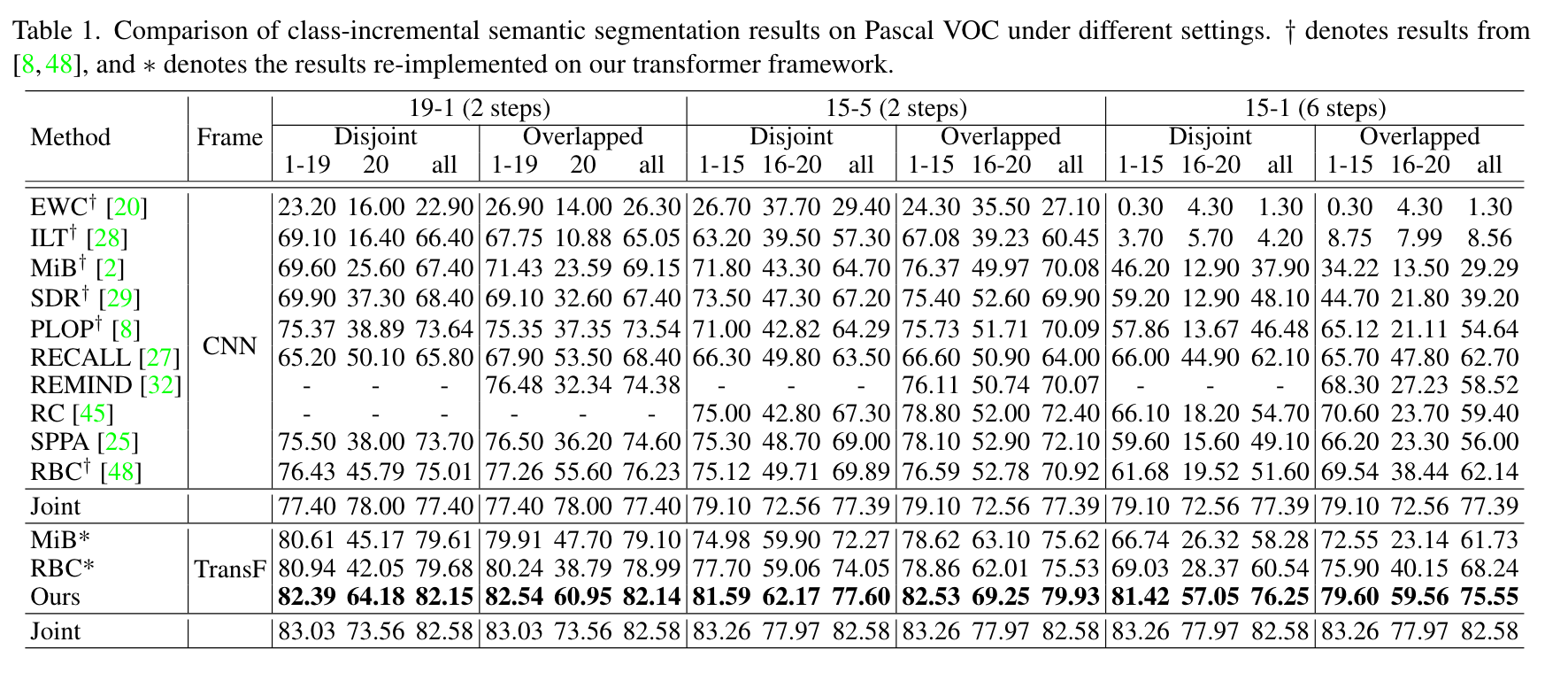
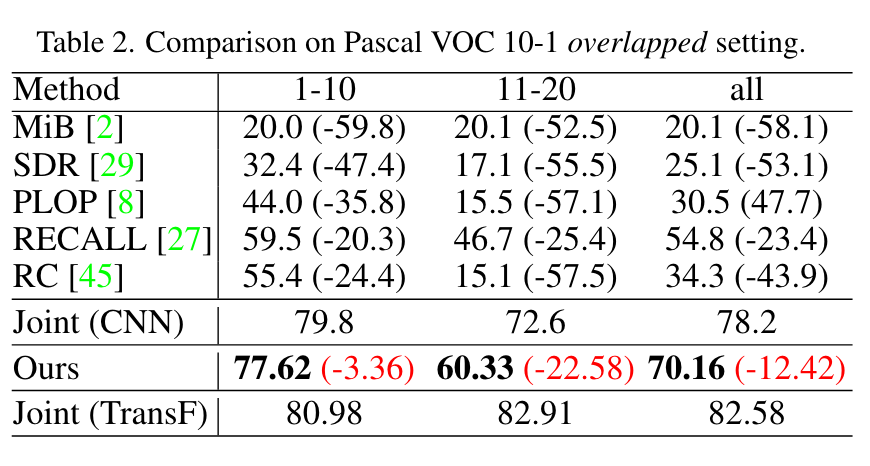
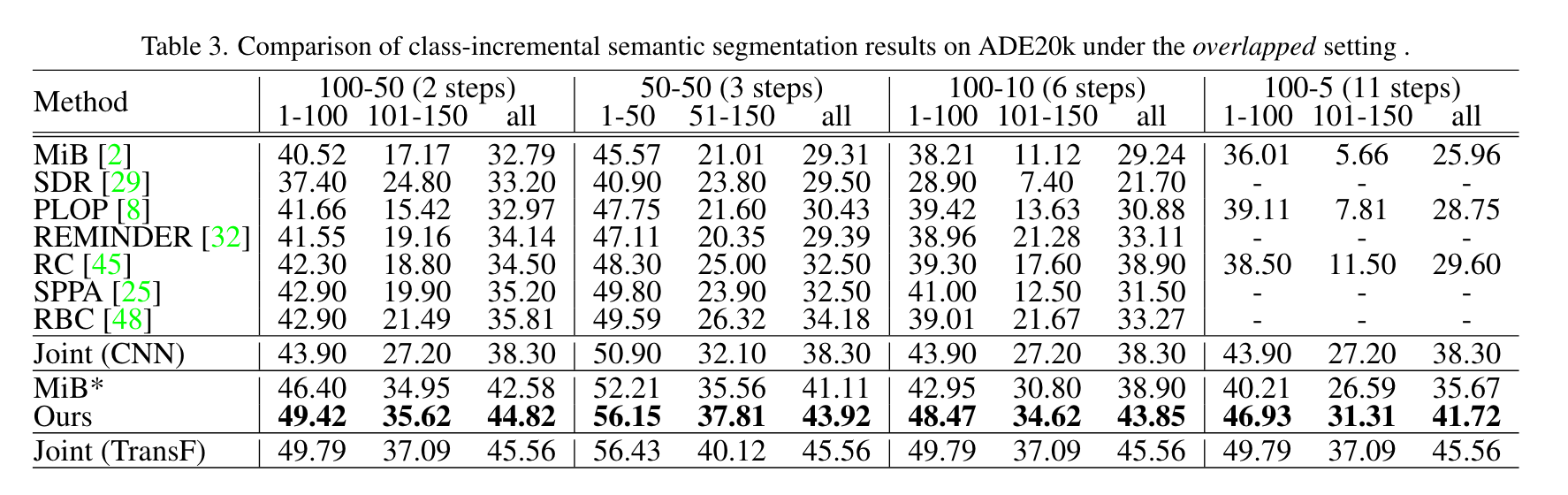
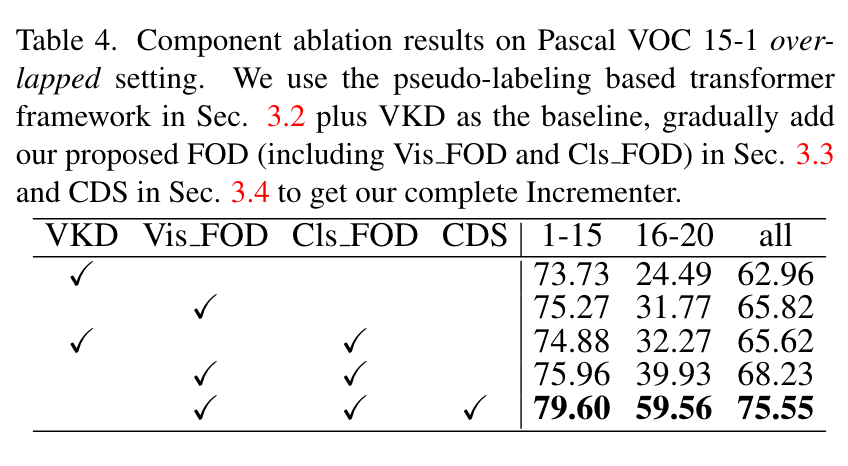
直接把10-1刷到70多了,ade的四个setting都刷到了40+,非常恐怖。
- Class Class-Incremental Distillation Segmentation Incrementerclass class-incremental distillation segmentation class-incremental class-incremental incremental distiling learning class-incremental compression incremental boosting class-incremental incremental classifiers generative distillation detection embedding one-class incrementer distillation understanding distillation knowledge empirical ranking distillation performance recommender