我们将使用两个循环神经网络的编码器和解码器, 并将其应用于序列到序列(sequence to sequence,seq2seq)类的学习任务。
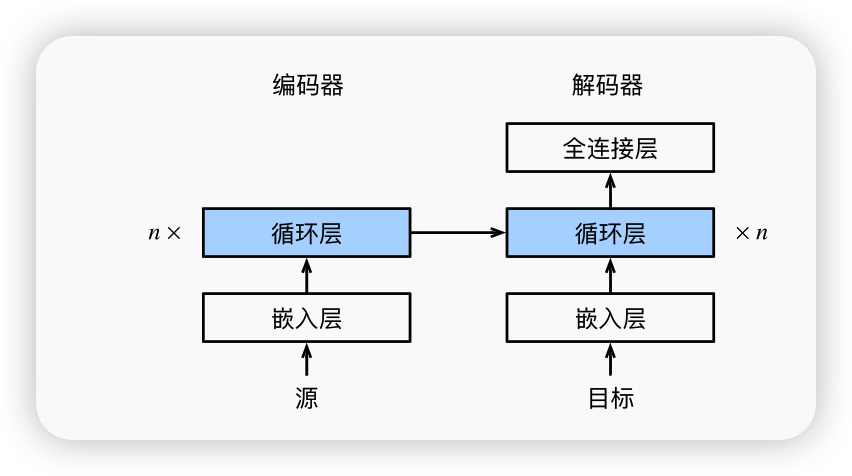
编码器

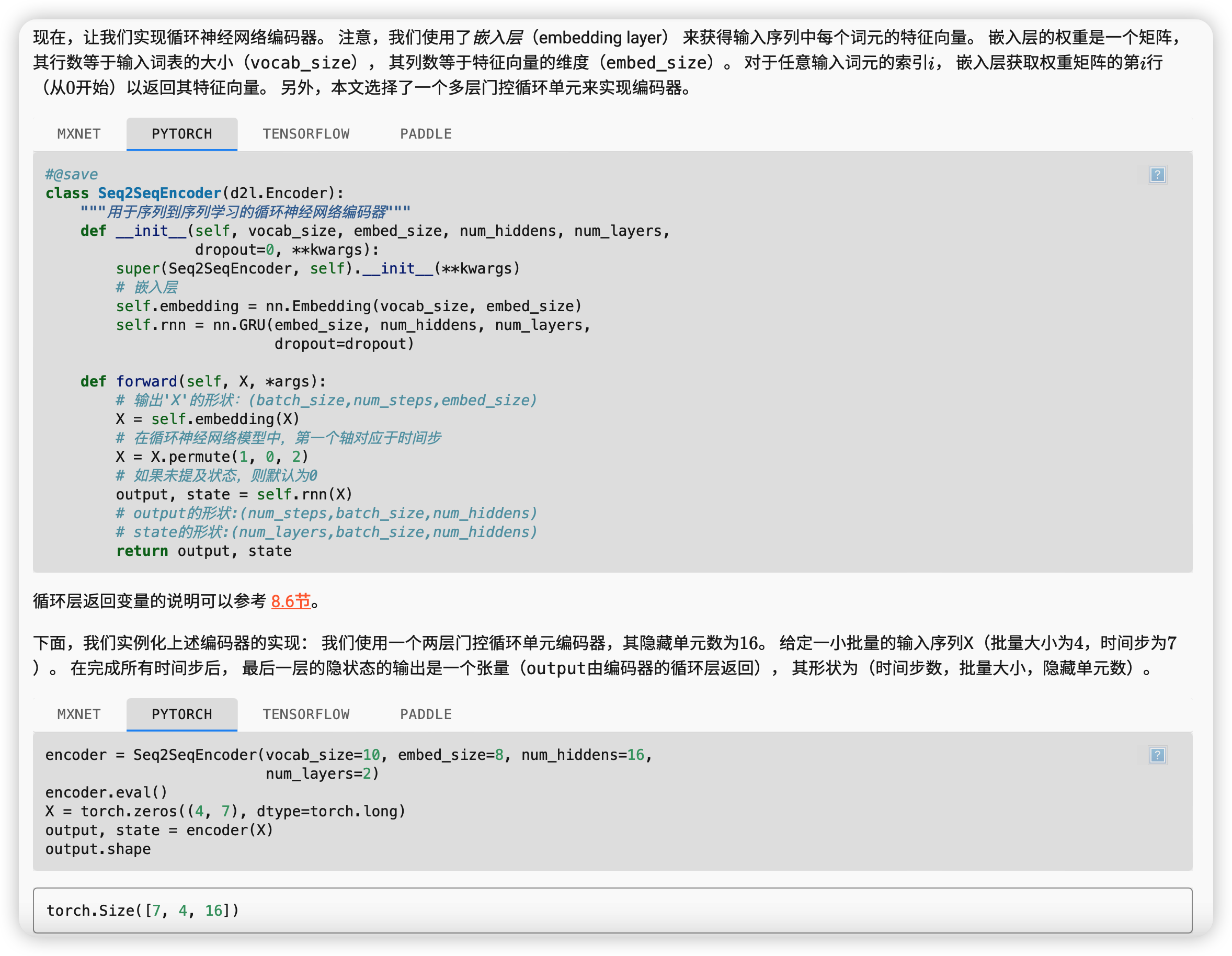
由于这里使用的是门控循环单元, 所以在最后一个时间步的多层隐状态的形状是 (隐藏层的数量,批量大小,隐藏单元的数量)。 如果使用长短期记忆网络,state中还将包含记忆单元信息。
state.shape
torch.Size([2, 4, 16])
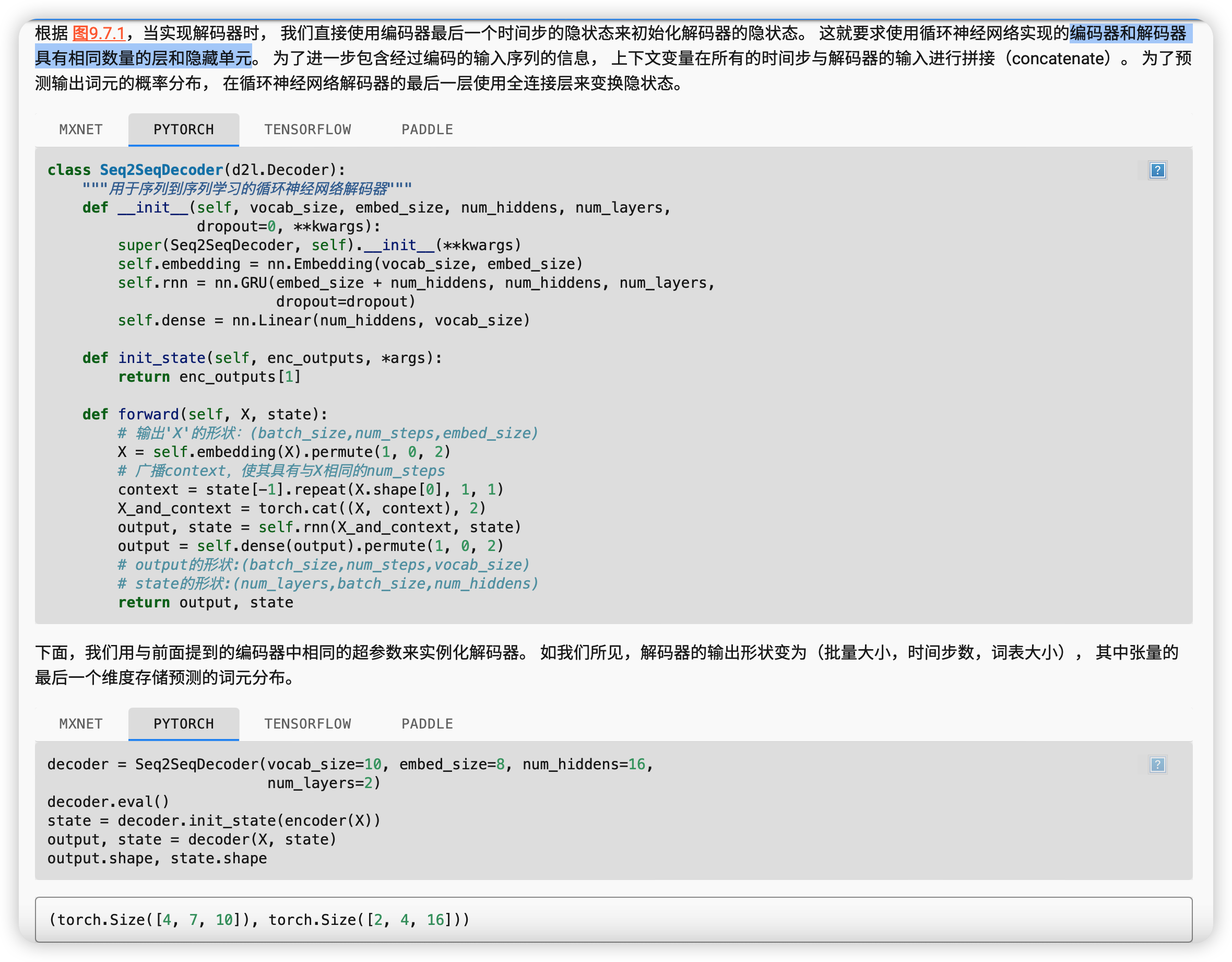
解码器

损失函数
在每个时间步,解码器预测了输出词元的概率分布。 类似于语言模型,可以使用softmax来获得分布, 并通过计算交叉熵损失函数来进行优化。 回想一下 9.5节中, 特定的填充词元被添加到序列的末尾, 因此不同长度的序列可以以相同形状的小批量加载。 但是,我们应该将填充词元的预测排除在损失函数的计算之外。
为此,我们可以使用下面的sequence_mask函数 通过零值化屏蔽不相关的项, 以便后面任何不相关预测的计算都是与零的乘积,结果都等于零。 例如,如果两个序列的有效长度(不包括填充词元)分别为1和2,则第一个序列的第一项和第二个序列的前两项之后的剩余项将被清除为零。
#@save
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
sequence_mask(X, torch.tensor([1, 2]))
tensor([[1, 0, 0],
[4, 5, 0]])
我们还可以使用此函数屏蔽最后几个轴上的所有项。如果愿意,也可以使用指定的非零值来替换这些项。
X = torch.ones(2, 3, 4) sequence_mask(X, torch.tensor([1, 2]), value=-1)
tensor([[[ 1., 1., 1., 1.], [-1., -1., -1., -1.], [-1., -1., -1., -1.]], [[ 1., 1., 1., 1.], [ 1., 1., 1., 1.], [-1., -1., -1., -1.]]])
现在,我们可以通过扩展softmax交叉熵损失函数来遮蔽不相关的预测。 最初,所有预测词元的掩码都设置为1。 一旦给定了有效长度,与填充词元对应的掩码将被设置为0。 最后,将所有词元的损失乘以掩码,以过滤掉损失中填充词元产生的不相关预测。
#@save
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction='none'
unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(
pred.permute(0, 2, 1), label)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss
我们可以创建三个相同的序列来进行代码健全性检查, 然后分别指定这些序列的有效长度为4、2和0。 结果就是,第一个序列的损失应为第二个序列的两倍,而第三个序列的损失应为零。
loss = MaskedSoftmaxCELoss()
loss(torch.ones(3, 4, 10), torch.ones((3, 4), dtype=torch.long),
torch.tensor([4, 2, 0]))
tensor([2.3026, 1.1513, 0.0000])
训练
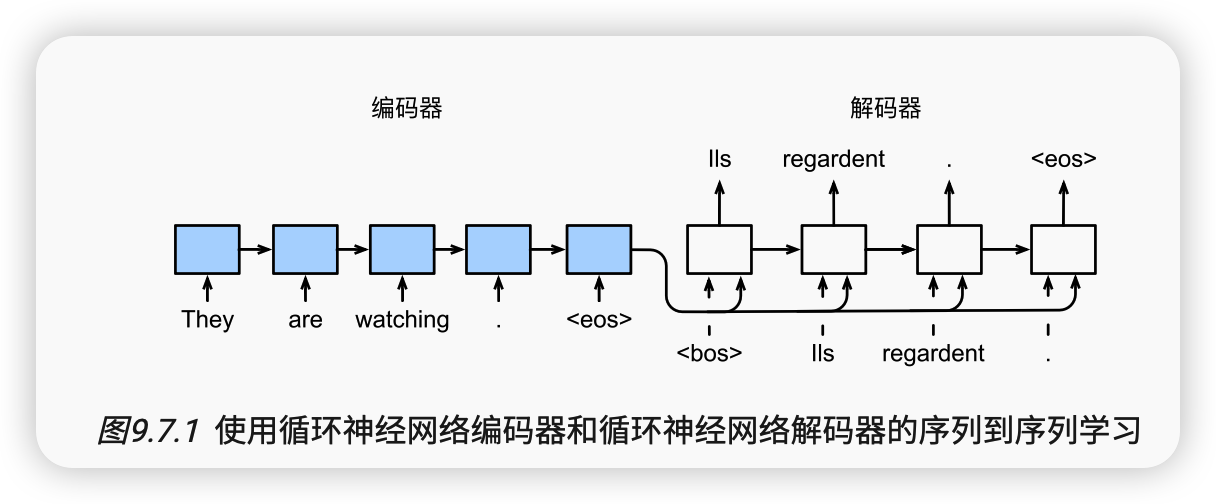
在下面的循环训练过程中,如 图9.7.1所示, 特定的序列开始词元(“<bos>”)和 原始的输出序列(不包括序列结束词元“<eos>”) 拼接在一起作为解码器的输入。 这被称为强制教学(teacher forcing), 因为原始的输出序列(词元的标签)被送入解码器。 或者,将来自上一个时间步的预测得到的词元作为解码器的当前输入。
预测
为了采用一个接着一个词元的方式预测输出序列, 每个解码器当前时间步的输入都将来自于前一时间步的预测词元。 与训练类似,序列开始词元(“<bos>”) 在初始时间步被输入到解码器中。 该预测过程如 图9.7.3所示, 当输出序列的预测遇到序列结束词元(“<eos>”)时,预测就结束了。

预测序列的评估
BLEU是一种常用的评估方法,它通过测量预测序列和标签序列之间的元语法的匹配度来评估预测。
总结
-
根据“编码器-解码器”架构的设计, 我们可以使用两个循环神经网络来设计一个序列到序列学习的模型。
-
在实现编码器和解码器时,我们可以使用多层循环神经网络。
-
我们可以使用遮蔽来过滤不相关的计算,例如在计算损失时。
-
在“编码器-解码器”训练中,强制教学方法将原始输出序列(而非预测结果)输入解码器。
-
BLEU是一种常用的评估方法,它通过测量预测序列和标签序列之间的元语法的匹配度来评估预测。