分类网络
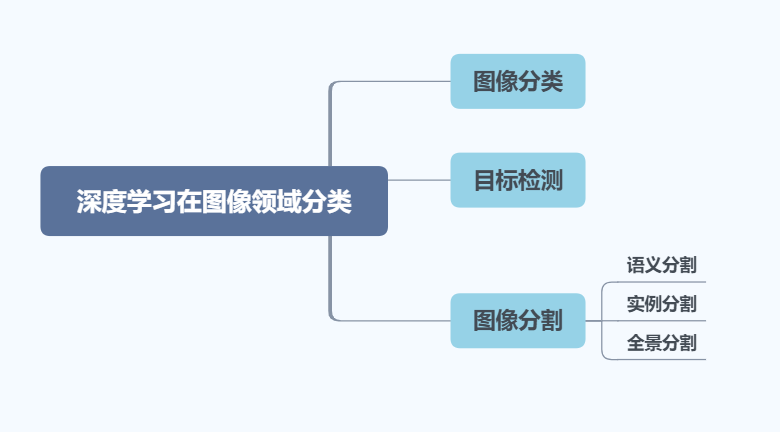
深度学习在图像邻域的应用大致可以分为图像分类、目标检测、图像分割三大类,其中图像分割又可以细分为语义分割、实例分割和全景分割,这一篇梳理下常见的分类数据集和分类网络,后续会重点介绍ResNet,并逐步实现ResNet训练及推理。
一、常用分类数据集
MNIST 内容是0-9的手写数字,60k训练图像、10k测试图像、10个类别、图像大小1×28×28。
CIFAR-10 50k训练图像、10k测试图像、10个类别、图像大小3×32×32。
CIFAR-100 50k训练图像、10k测试图像、100个类别、图像大小3×32×32。
STL-10 和CIFAR-10类似,5k训练图像、8k测试图像、10个类别,还包含100k无标签数据用于无监督学习、图片大小变为3×96×96。
ILSVRC2012 属于ImageNet的一个子集,ILSVRC是一个比赛,其全称为:ImageNet Large-Scale Visual Recognition Challenge,1200k训练图像、50k验证图像、10k测试数据,1k个类别。
以上数据集有很多算法进行了验证,查看http://rodrigob.github.io/are_we_there_yet/build/可以看到各算法在数据集上的排名。
更多数据集内容如汽车、花卉、动物等可参考:
https://zhuanlan.zhihu.com/p/556588185
二、经典分类网络
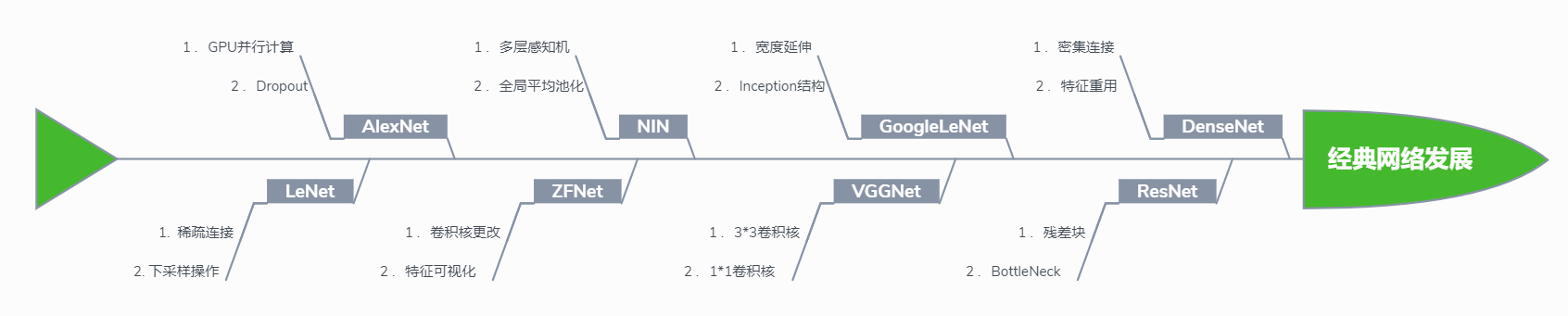
从LeNet到VGGNet网络深度逐渐增加,GoogleNet引入Inception加宽了网络,随着深度的增加,网络出现退化问题,ResNet引入残差块来解决此问题,使得网络可以更深,可以看到这些经典网络的发展逐渐使得网络深度更深,宽度更宽,进而获取特征的能力越来越强。
1.1 LeNet
论文
PDF: https://sci-hub.st/10.1109/5.726791
时间:1998年
介绍
LeNet由深度学习三巨头之一的Yan LeCun(2019图灵奖得主)在上世纪90年代提出,是一种用于识别手写数字和机器印刷字符的卷积神经网络。LeNet有不同版本(LeNet-5, LeNet-4和LeNet-1),通常指LeNet-5。LeNet-5阐述了图像中像素特征之间的相关性能够由参数共享的卷积操作所提取,同时使用卷积、下采样(池化)和非线性映射这样的组合结构,是当前流行的大多数深度图像识别网络的基础。
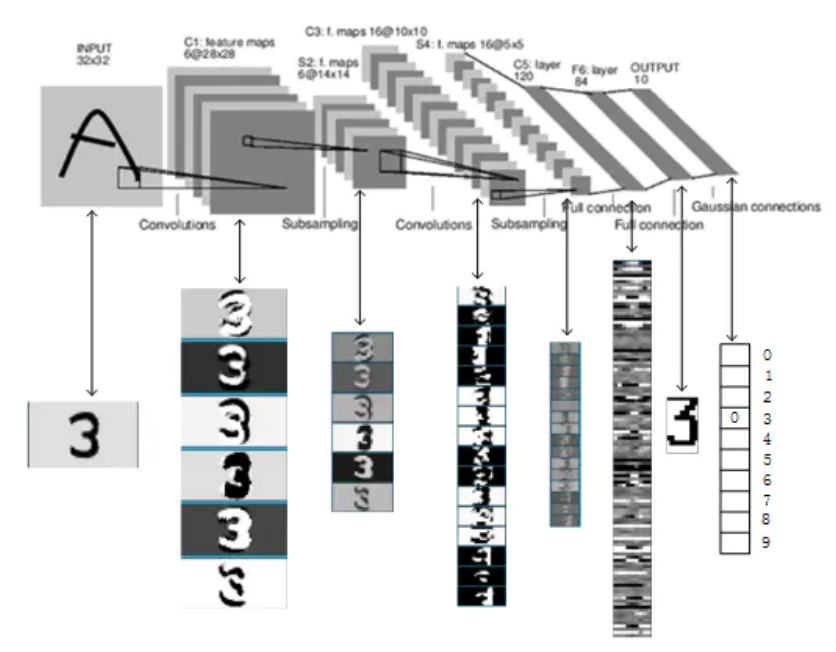
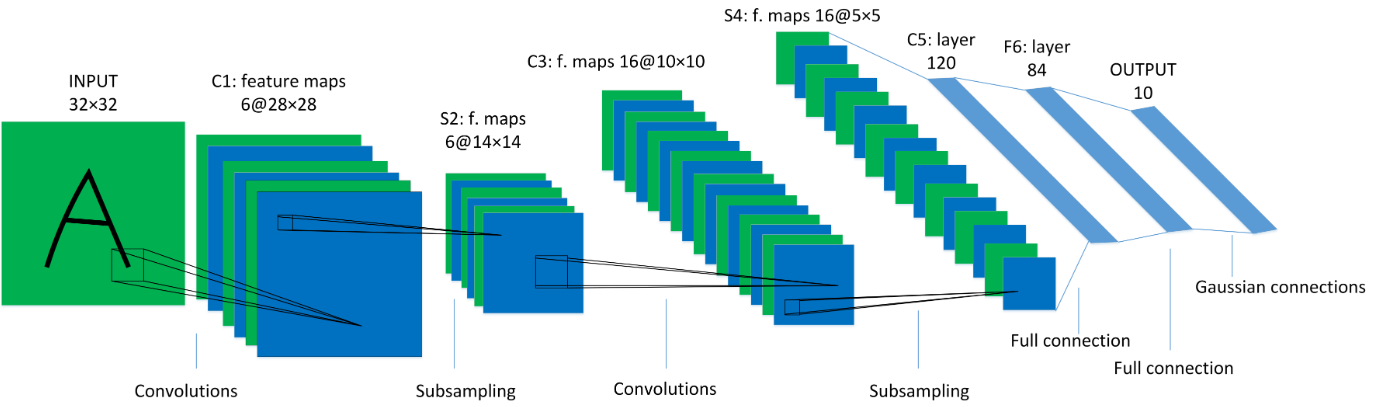
网络结构
网络结构如下图所示,包含卷积操作、下采样和全连接共七层。
LeNet-5网络参数配置如下表所示
其中
-
下采样层核尺寸分别代表采样范围和连接矩阵的尺寸
-
卷积层核尺寸表示核大小,步长即卷积核个数,如\(C_1\)中\(“5\times5\times1/1,6”\)表示核大小为\(5\times5\times1\)、步长为\(1\)且核个数为6的卷积核
| 网络层 | 输入尺寸 | 核尺寸 | 输出尺寸 | 可训练参数量 |
|---|---|---|---|---|
| 卷积层\(C_1\) | \(32\times32\times1\) | \(5\times5\times1/1,6\) | \(28\times28\times6\) | \((5\times5\times1+1)\times6\) |
| 下采样层\(S_2\) | \(28\times28\times6\) | \(2\times2/2\) | \(14\times14\times6\) | \((1+1)\times6\) \(^*\) |
| 卷积层\(C_3\) | \(14\times14\times6\) | \(5\times5\times6/1,16\) | \(10\times10\times16\) | \(1516^*\) |
| 下采样层\(S_4\) | \(10\times10\times16\) | \(2\times2/2\) | \(5\times5\times16\) | \((1+1)\times16\) |
| 卷积层\(C_5\)\(^*\) | \(5\times5\times16\) | \(5\times5\times16/1,120\) | \(1\times1\times120\) | \((5\times5\times16+1)\times120\) |
| 全连接层\(F_6\) | \(1\times1\times120\) | \(120\times84\) | \(1\times1\times84\) | \((120+1)\times84\) |
| 输出层 | \(1\times1\times84\) | \(84\times10\) | \(1\times1\times10\) | \((84+1)\times10\) |
关键点
1、\(^*\)在LeNet中,下采样操作和池化操作类似,但是在得到采样结果后会乘以一个系数和加上一个偏置项,所以下采样的参数个数是\((1+1)\times6\)而不是零。
2、\(^*\) \(C_3\)卷积层可训练参数并未直接连接\(S_2\)中所有的特征图(Feature Map),而是采用下图所示的稀疏连接,生成的16个通道特征图中分别按照相邻3个特征图、相邻4个特征图、非相邻4个特征图和全部6个特征图进行映射,得到的参数个数计算公式为\(6\times(25\times3+1)+6\times(25\times4+1)+3\times(25\times4+1)+1\times(25\times6+1)=1516\)。
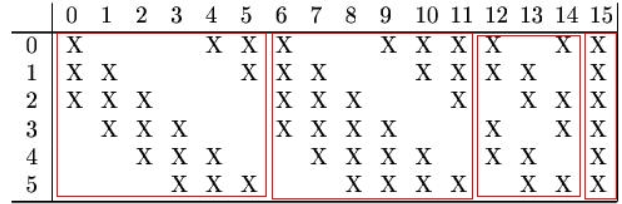
在原论文中解释了使用这种采样方式原因包含两点:
- 限制了连接数不至于过大(当年的计算能力比较弱);
- 强制限定不同特征图的组合可以使映射得到的特征图学习到不同的特征模式
1.2 AlexNet
论文
PDF: https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
时间:2012年
介绍
AlexNet是由\(Alex\) $Krizhevsky $提出的首个应用于图像分类的深层卷积神经网络,该网络在2012年ILSVRC(ImageNet Large Scale Visual Recognition Competition)图像分类竞赛中以15.3%的top-5测试错误率赢得第一名。AlexNet使用GPU代替CPU进行运算,使得在可接受的时间范围内模型结构能够更加复杂,它的出现证明了深层卷积神经网络在复杂模型下的有效性,使CNN在计算机视觉中流行开来,直接或间接地引发了深度学习的热潮。
网络结构
如下图所示AlexNet一共包含8层,前5层由卷积层组成,而剩下的3层为全连接层。网络结构分为上下两层,分别对应两个GPU的操作过程,除了中间某些层(\(C_3\)卷积层和\(F_{6-8}\)全连接层会有GPU间的交互),其他层两个GPU分别计算结 果。最后一层全连接层的输出作为\(softmax\)的输入,得到1000个图像分类标签对应的概率值。
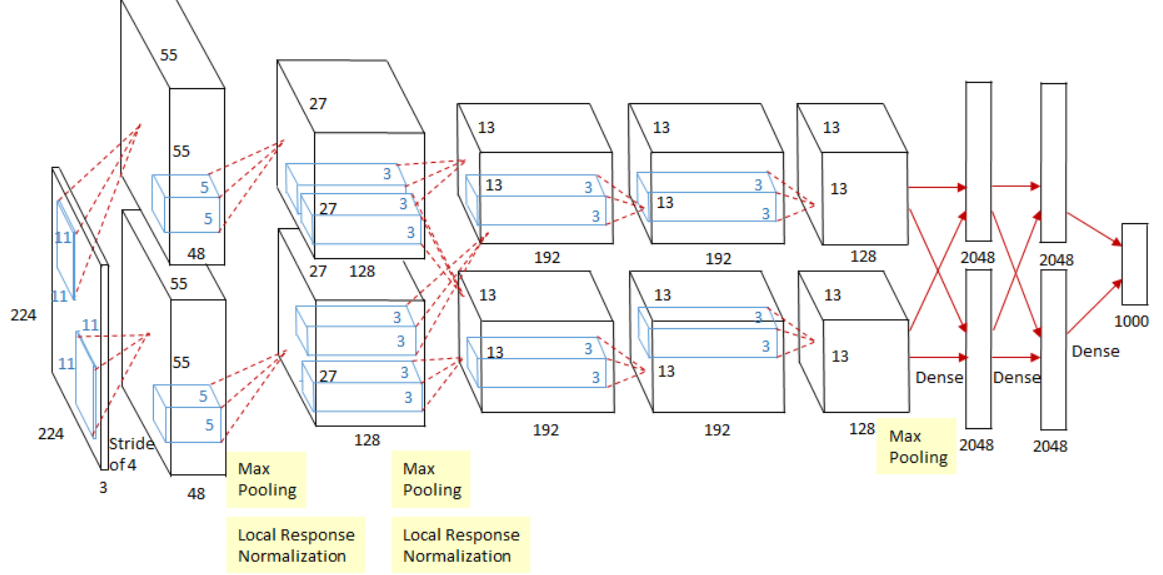
关键点
1、设计了GPU并行计算结构
2、使用随机丢弃技术(dropout)选择性地忽略训练中的单个神经元,避免模型的过拟合
1.3 ZFNet
论文
PDF:https://arxiv.org/pdf/1311.2901.pdf
时间:2013年
介绍
ZFNet是由\(Matthew\) \(D. Zeiler\)和\(Rob\) \(Fergus\)在AlexNet基础上提出的大型卷积网络,在2013年ILSVRC图像分类竞赛中以11.19%的错误率获得冠军。ZFNet实际上是微调(fine-tuning)了的AlexNet,并通过反卷积(Deconvolution)的方式可视化各层的输出特征图,进一步解释了卷积操作在大型网络中效果显著的原因。
网络结构
ZFNet与AlexNet类似,都是由8层网络组成的卷积神经网络,其中包含5层卷积层和3层全连接层。两个网络结构最大的不同在于,ZFNet第一层卷积采用了\(7\times7\times3/2\)的卷积核替代了AlexNet中第一层卷积核\(11\times11\times3/4\)的卷积核。
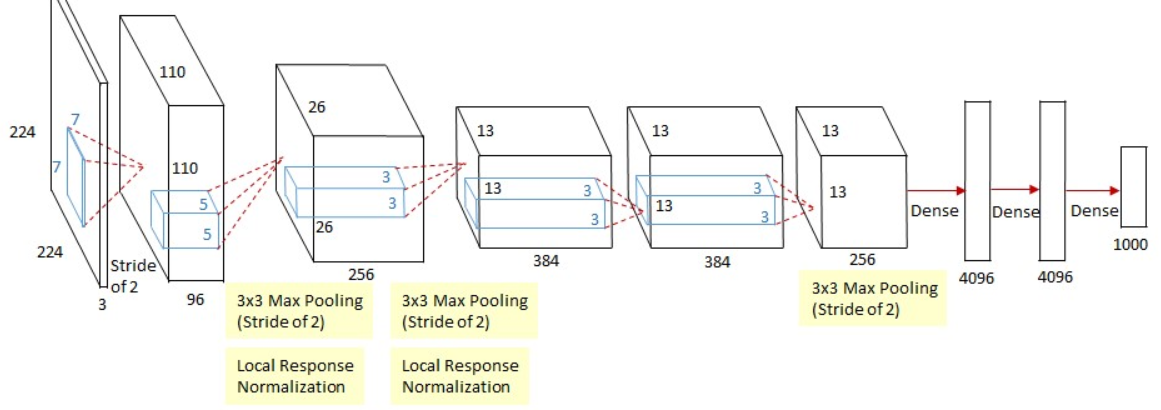
关键点
1、 卷积层\(C_1\)与AlexNet中的\(C_1\)有所不同,采用\(7\times7\times3/2\)的卷积核代替\(11\times11\times3/4\),使第一层卷积输出的结果可以包含更多的中频率特征,对后续网络层中多样化的特征组合提供更多选择,有利于捕捉更细致的特征。
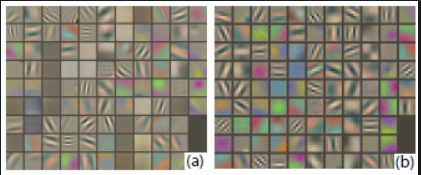
(a)ZFNet第一层输出的特征图(b)AlexNet第一层输出的特征图

(c)AlexNet第二层输出的特征图(d)ZFNet第二层输出的特征图
2、 特征可视化,特征图经过反卷积映射到原图像素空间
1.4 NIN
论文
PDF:https://arxiv.org/pdf/1312.4400.pdf
时间:2014年
介绍
Network In Network (NIN)是由\(Min Lin\)等人提出,在2014年的CIFAR-10和CIFAR-100分类任务中达到当时的最好水平,因其网络结构是由三个多层感知机堆叠而被成为NIN。NIN以一种全新的角度审视了卷积神经网络中的卷积核设计,通过引入子网络结构代替纯卷积中的线性映射部分,这种形式的网络结构激发了更复杂的卷积神经网络的结构设计,其中下一节中介绍的GoogLeNet的Inception结构就是来源于这个思想。
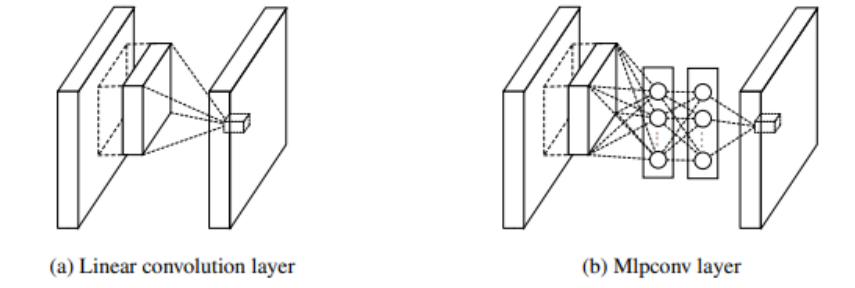
网络结构
NIN由三层的多层感知卷积层(MLPConv Layer)构成,每一层多层感知卷积层内部由若干层的局部全连接层和非线性激活函数组成,代替了传统卷积层中采用的线性卷积核,最大的不同在于多层感知器对局部特征进行了非线性的映射,而传统卷积的方式是线性的。
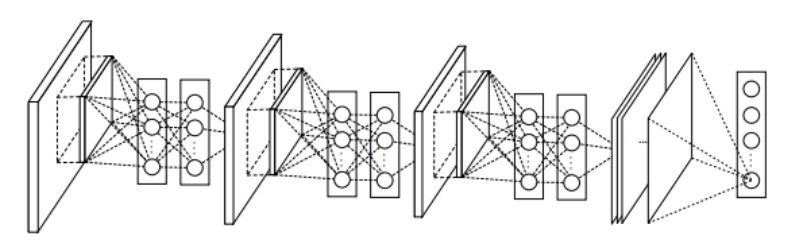
关键点
1、使用多层感知机结构来代替卷积的滤波操作,不但有效减少卷积核数过多而导致的参数量暴涨问题,还能通过引入非线性的映射来提高模型对特征的抽象能力。
2、使用全局平均池化来代替最后一个全连接层,能够有效地减少参数量(没有可训练参数),同时池化用到了整个特征图的信息,对空间信息的转换更加鲁棒,最后得到的输出结果可直接作为对应类别的置信度。
1.5 VGGNet
论文
PDF:https://arxiv.org/pdf/1409.1556.pdf
时间:2014年
介绍
VGGNet是由牛津大学视觉几何小组(Visual Geometry Group, VGG)提出的一种深层卷积网络结构,他们以7.32%的错误率赢得了2014年ILSVRC分类任务的亚军(冠军由GoogLeNet以6.65%的错误率夺得)和25.32%的错误率夺得定位任务(Localization)的第一名(GoogLeNet错误率为26.44%),网络名称VGGNet取自该小组名缩写。VGGNet是首批把图像分类的错误率降低到10%以内模型,同时该网络所采用的\(3\times3\)卷积核的思想是后来许多模型的基础。
网络结构
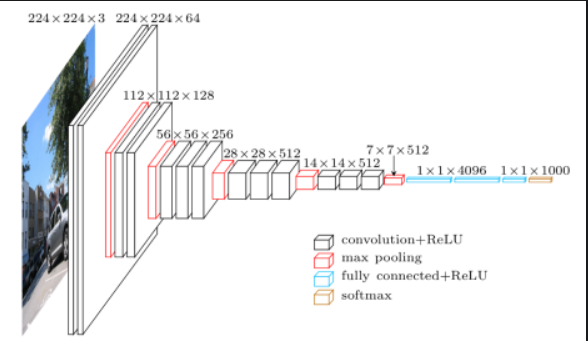
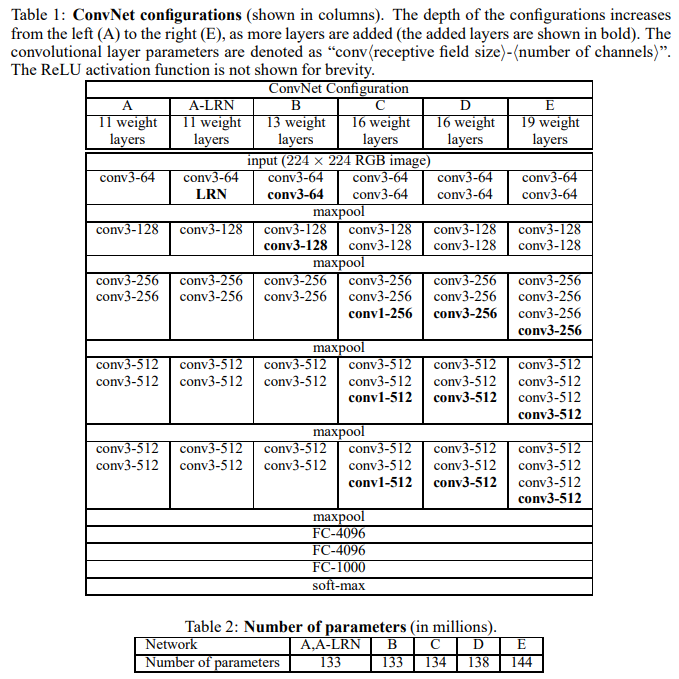
在原论文中的VGGNet包含了6个版本的演进,分别对应VGG11、VGG11-LRN、VGG13、VGG16-1、VGG16-3和VGG19,不同的后缀数值表示不同的网络层数。
关键点
1、 整个网络都使用了同样大小的卷积核尺寸\(3\times3\)和最大池化尺寸\(2\times2\)。
2、 \(1\times1\)卷积的意义主要在于线性变换,而输入通道数和输出通道数不变,没有发生降维。
3、 两个\(3\times3\)的卷积层串联相当于1个\(5\times5\)的卷积层,感受野大小为\(5\times5\)。同样地,3个\(3\times3\)的卷积层串联的效果则相当于1个\(7\times7\)的卷积层。这样的连接方式使得网络参数量更小,而且多层的激活函数令网络对特征的学习能力更强。
1.6 GoogleLeNet
论文
PDF:https://arxiv.org/pdf/1409.4842v1.pdf
时间:2014年
介绍
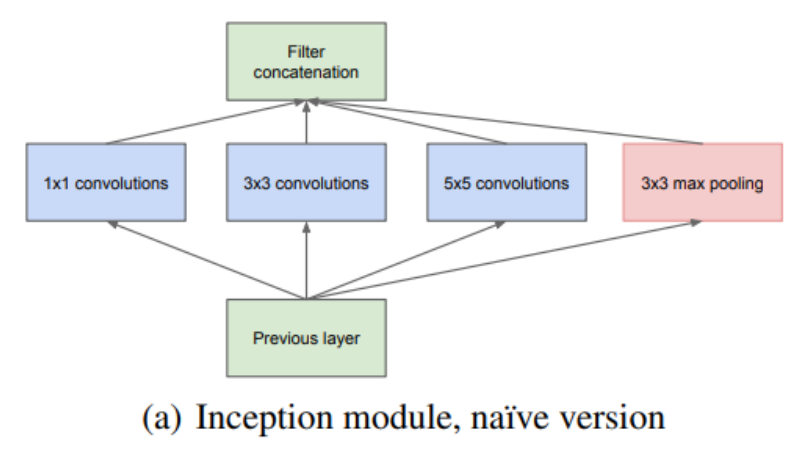
GoogLeNet作为2014年ILSVRC在分类任务上的冠军,以6.65%的错误率力压VGGNet等模型,在分类的准确率上面相比过去两届冠军ZFNet和AlexNet都有很大的提升。从名字GoogLeNet可以知道这是来自谷歌工程师所设计的网络结构,而名字中GoogLeNet更是致敬了LeNet。GoogLeNet中最核心的部分是其内部子网络结构Inception,该结构灵感来源于NIN,至今已经经历了四次版本迭代(Inception\(_{v1-4}\))。
网络结构
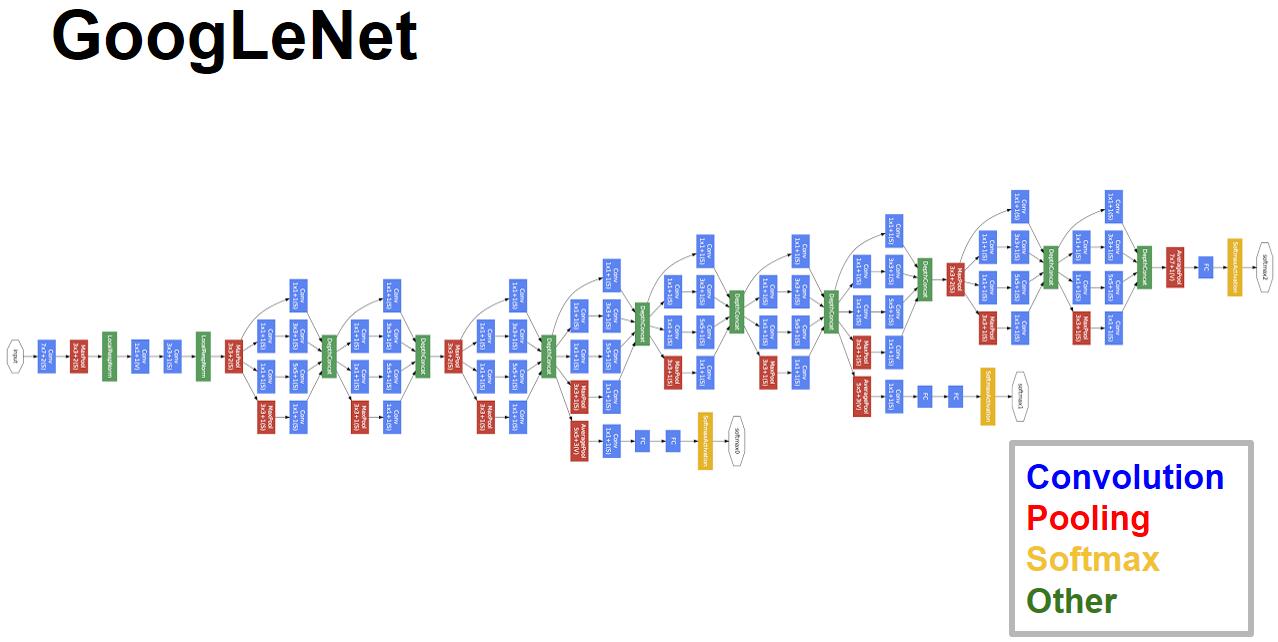
GoogLeNet相比于以前的卷积神经网络结构,除了在深度上进行了延伸,还对网络的宽度进行了扩展,整个网络由许多块状子网络的堆叠而成,这个子网络构成了Inception结构。
关键点
1、GoogLeNet相比于以前的卷积神经网络结构,除了在深度上进行了延伸,还对网络的宽度进行了扩展,整个网络由许多块状子网络的堆叠而成,这个子网络构成了Inception结构。
2、Inception不需要人为决定使用哪个过滤器、是否使用池化,而是由网络自行决定这些参数。你可以给网络添加这些参数的所有可能值,然后把这些输出连接起来,让网络学习自己需要什么样的参数、采用哪些过滤器组合。
1.7 ResNet
论文
PDF:https://arxiv.org/pdf/1512.03385.pdf
时间:2015年
介绍
ResNet是2015年由何凯明大神提出的网络,其在CNN图像领域具有里程碑意义,在2015年ImageNet中斩获图像分类、检测、定位三项的冠军,ResNet的提出很大程度上解决了网络退化问题。

网络结构
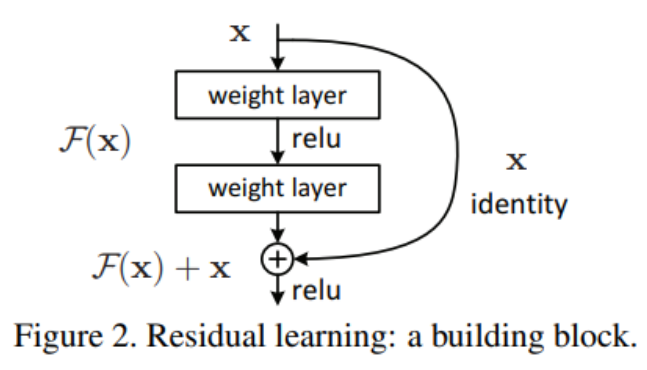
结构上参考VGG-19,在其基础上网络更深,且添加了残差块,以下是ResNet34结构图

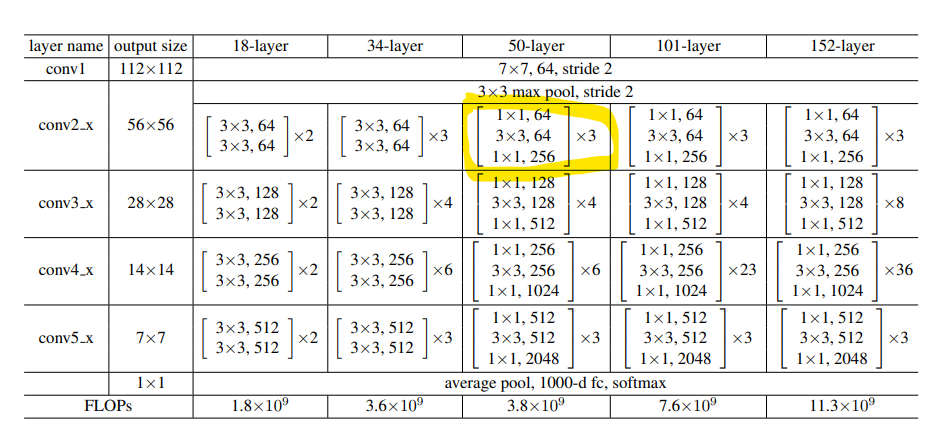
如下图ResNet有不同的版本,后面的数字表示其层数,其中50层及以上的引入了BottleNeck结构,使用 \(1\times 1\)的网络结构很方便改变维度,并且减小了计算量。
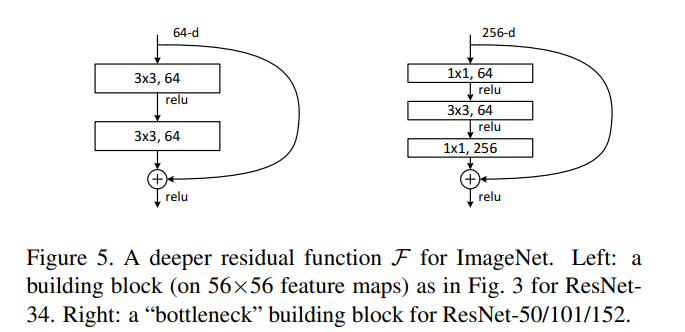
关键点
1、 引入残差块解决网络退化问题
2、 引入了BottleNeck结构,使得网络深度更深的同时,参数量没有爆炸式增长
1.8 DenseNet
论文
PDF:https://arxiv.org/pdf/1608.06993.pdf
时间:2017年
介绍
DenseNet的基本思路与ResNet一致,但相比ResNet,DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入(如下图的DenseBlock)。DenseNet主要还是和ResNet及Inception网络做对比,思想上有借鉴,但却是全新的结构,网络结构并不复杂,却非常有效!作者从feature入手,通过对feature的极致利用达到更好的效果和更少的参数。
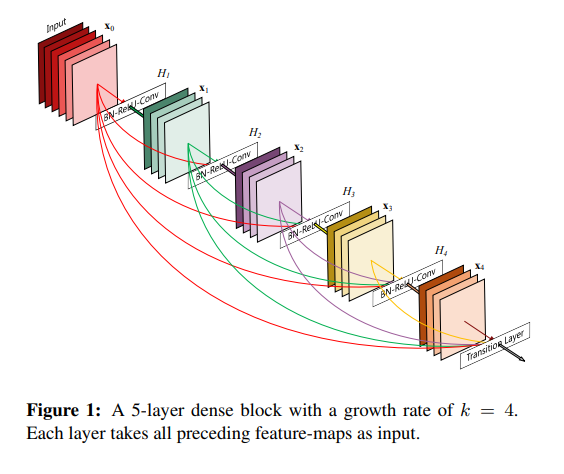
网络结构
网络主要由密集连接的残差块组成

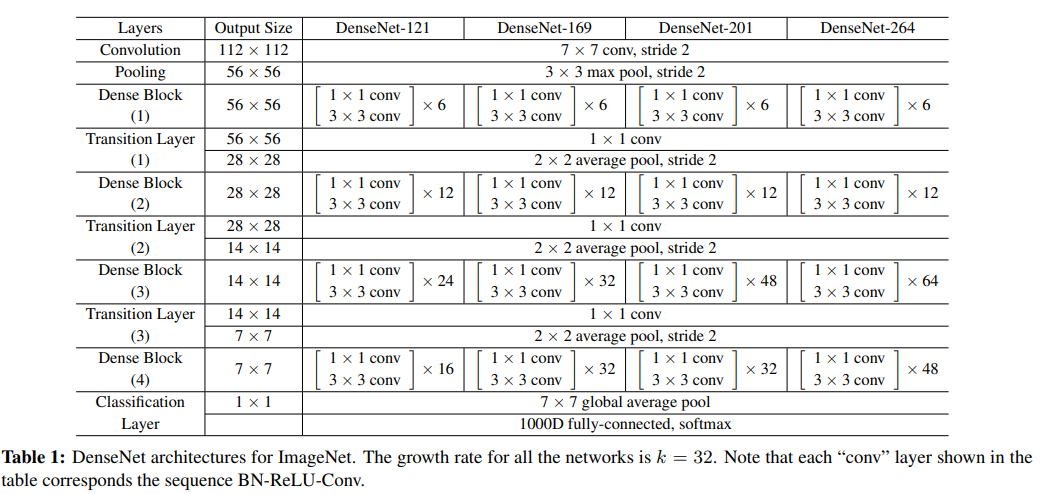
关键点
1、由于密集连接方式,每层可以直达最后的误差信号,DenseNet提升了梯度的反向传播,使得网络更容易训练;
2、由于DenseNet是通过concat特征来实现短路连接,实现了特征重用