HTTP协议
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议。(无状态指的是第一次请求与第二次请求之间并没有相关的关联,应用层协议指的是该协议工作在TCP协议之上)
HTTP协议采用URL作为定位网络资源的标识,URL格式如下:
http://host[:port][path]
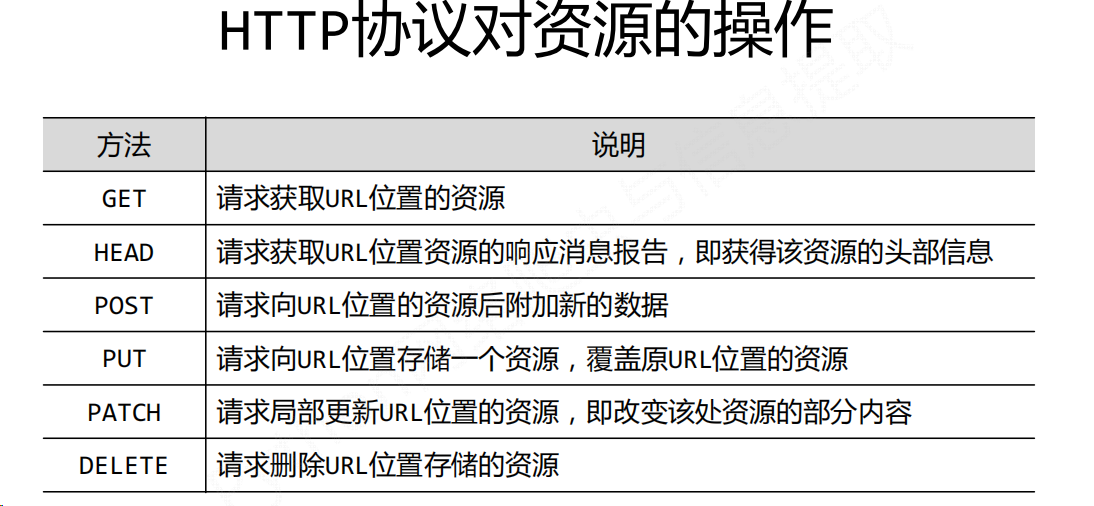
PATCH的主要优点是节省网络带宽
- 爬取网页的通用代码框架
-
1 import requests 2 def getHTMLText(url): 3 try: 4 r = requests.get(url,timeout=30) 5 r.raise_for_status() 6 r.encoding = r.apparent_encoding 7 return r.text 8 except: 9 return "产生异常" 10 11 if __name__ == "__main__": 12 url = "https://www.baidu.com" 13 print(getHTMLText(url))
r.status_code和r.raise_for_status()是Python requests库中用于处理HTTP请求的两个方法。r.status_code是一个属性,它返回HTTP响应的状态码。状态码是一个三位数,表示请求是否成功以及具体的响应状态。常见的状态码包括:- 200:请求成功
- 404:页面不存在
- 500:服务器端错误
通过检查
r.status_code的值,你可以判断请求是否成功,并根据需要采取相应的处理措施。r.raise_for_status()是一个方法,它会根据HTTP响应的状态码抛出异常。如果HTTP请求返回的状态码表示一个错误(如4xx或5xx),r.raise_for_status()将引发一个HTTPError异常。这使得你可以捕捉到请求错误,并进行相应的错误处理。区别在于,r.status_code只是返回状态码的值,而r.raise_for_status()会在状态码表示错误时抛出异常。因此,r.raise_for_status()可以更方便地处理HTTP请求的错误情况。 - HTTP协议与Requests库
HTTP协议方法与Requests库方法、功能是一 一对应的。 -
