JVM 在进行垃圾收集的时候,有一项非常重要的工作就是确定这一次垃圾收集的对象到底有多少个,即确定 live set 的范围。
卡表和 RSet(Remember Set),是 JVM 为了解决分代收集时,live set 扫描需要穿梭到不同的代的时候的效率问题。
对于新生代垃圾收集器而言,这个问题又有其特殊之处。根据 JVM 的弱分代收集假设(weak generational hypothesis)的存在,每次垃圾收集的时候,新生代的扫描范围可能很大,但新生代的 live set 不应该太大。
card table/Remember Set 的设计目的,就是尽量减少无用的垃圾扫描范围,使用类似操作系统或者数据库的脏页表的形式,来做类似快表的查询。
一、CardTable
卡表是 CMS 的解决方案。
官方解释:A kind of remembered set that records where oops have changed in a generation.
1、CardTable
问题: 新生代回收为什么可以不全表扫描标记?
答案: 只标记在新生代区的根引用+ cardTable上的标记。
作用:采用空间换时间,不需要扫描整个Heap空间,降低MonitorGC耗时。
我们都知道JVM为了更有效率地清除垃圾,把堆对象分为年轻代和老年代,这就可能存在年轻代和老年代的对象存在互相引用的现象。
解决跨代引用带来的问题,采用CardTable很好的规避了遍历整个老年代的问题。
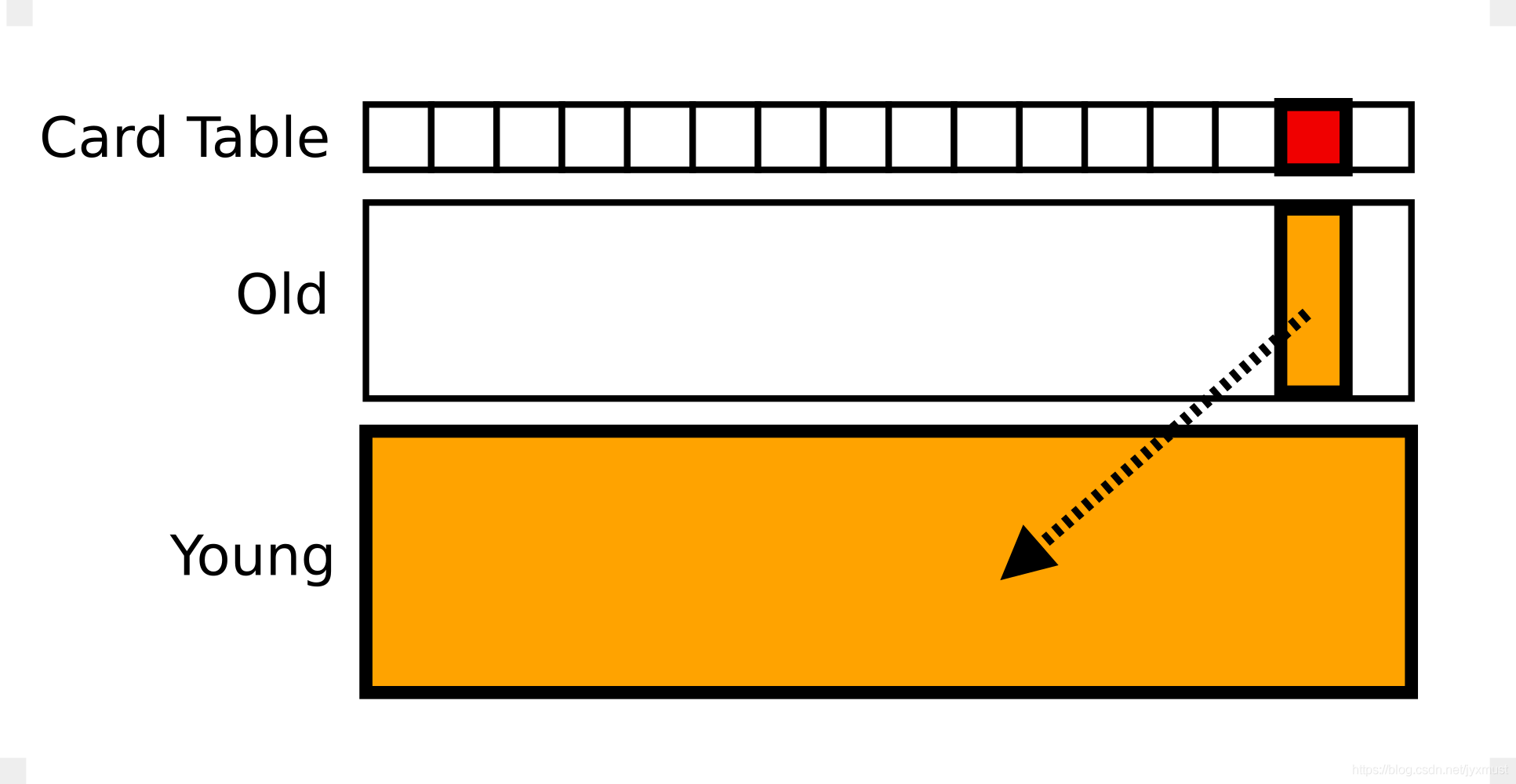
卡表通常在 JVM 中实现为单字节数组。当我们把 JVM 划分成不同区域的时候,每一个区域(通常是4k字节)就得到了一个标志位。每一位为 1 的时候,表明这个区域为 dirty,持有新生代对象,否则,这个区域不持有新生代对象。这样,新生代垃圾收集器在收集live set 的时候,可以通过以下两个操作:
- 从栈/方法区出发,进入新生代扫描。
- 从栈/方法区出发,进入老年代扫描,且只扫描 dirty 的区域,略过其他区域。
2、Write barrier
在实现卡表的时候,对于所有老年代更新新生代的操作插入了一种写屏障(write barrier),写屏障保证所有更新引用操作能把卡表的脏位设置到最新状态。不仅原生代码拥有这种写屏障,JIT 生成的代码也有这种写屏障。
并发标记时,如果某个对象的引用发生了变化,标记该对象所在的 Card 为 Dirty Card(通过 write-barrier)。在重新标记时,只需要重新扫描 Dirty Cards 即可,同时清除 Dirty 标记。
二、Remember Set
Remember Set 是从 G1 开始特有的一种数据结构,是卡表的设计思路 + G1 垃圾收集器使用场景的衍生产物。
1、记录外部对Region中对象的引用
伴随 Hotspot G1 垃圾收集器的诞生,传统的老年代和新生代都从物理上的连续空间,变成了一个个物理上不连续的空间 region。
G1 垃圾收集器将堆内存空间分成等分的 Regions,物理上不一定连续,逻辑上构成连续的堆地址空间。各个 Mutator 线程(即用户应用的线程)拥有各自的 Thread-Local Allocation Buffer (TLAB),用于降低各个线程分配内存的冲突。

为什么要把堆空间分成 Region 呢?其主要目的是让各个 Region 相对独立,可以分别进行 GC,而不是一次性地把所有垃圾收集掉。
我们需要一个机制来让各个 Region 能独立地进行垃圾收集,这也就是 Remember Set 存在的意义。每个 Region 会有一个对应的 Remember Set,它记录了哪些内存区域中存在对当前 Region 中对象的引用。(all locations that might contain pointers to (live) objects within the region)
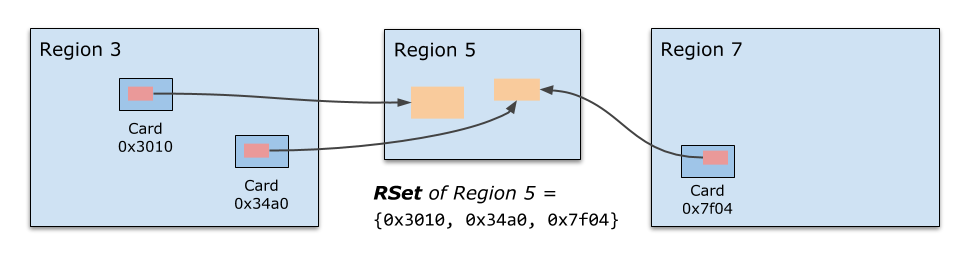
注意 Remember Set 不是直接记录对象地址,而是记录了那些对象所在的 Card 编号。所谓 Card 就是表示一小块(512 bytes)的内存空间,这里面很可能存在不止一个对象。
当我们需要确定当前 Region 有哪些对象存在外部引用时(这些对象是可达的,不能被回收),只要扫描一下这块 Card 中的所有对象即可,这比扫描所有 live objects 要容易的多。
实现上,Remember Set 的实现就是一个 Card 的 Hash Set,并且为每个 GC 线程都有一个本地的 Hash Set,最后的 Remember Set 实际上是这些 Hash Set 的并集。当 Card 数量特别多的时候会退化到 Region 粒度,这时候就要扫描更多的区域来寻找引用,参考下面的优化部分。
2、Remember Set 的维护
维护上面所说的 Remember Set 势必需要记录对象的引用,通常的做法是在 set 一个引用的时候插入一段代码,这称为 Write Barrier。
为了尽可能降低对 Mutator 线程的影响,Write Barrier 的代码应当尽可能简化。
G1 的 Write Barrier 实际上只是一个“通知”:将当前 set 引用的事件放到 Remember Set Log 队列中,交给后台专门的 GC 线程处理。
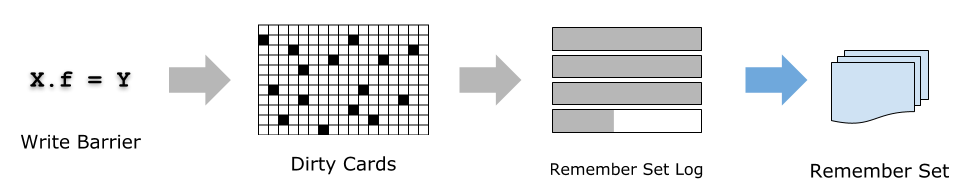
Write Barrier 具体实现如下。当发生 X.f = Y 时,假设 rX 为 X 对象的地址,rY 为 Y 对象的地址,则 Write 的同时还会执行以下逻辑:
t = (rX XOR rY) >> LogOfRegionSize // 对 X, Y 地址右移得到 Region 编号,并将二者做个 XOR
if (rY == NULL ? 0 : t) // 忽略两种情况: X.f 被赋值为 NULL,或 X 和 Y 位于同一个 Region 内
rs_enqueue(rX) // 如果 Card(X) 还不是 dirty 的,将 X 的地址放进 Log,并把该 card 置为 dirty
这里 Dirty Bit 的作用是去除重复的 Cards,考虑到一个 Cards 内经常发生密集的引用赋值(比如对象初始化),去重一下能大幅减少冗余。
最后,后台的 GC 线程则负责从 Remember Set Log 不断取出这些引用赋值发生的 Cards,扫描上面所有的对象,然后更新相应 Region 的 Remember Set。在并发标记发生之前,G1 会确保 Remember Set Log 中的记录都处理完,从而保证并发标记算法一定能拿到最新的、正确的 Remember Set。
极端情况下,如果后台的 GC 进程追不上 Mutator 进程写入的速度,这时候 Mutator 线程会退化到自己处理更新,形成反压机制。
3、RSet 优化
当 Region 被引用较多的情况,RSet 占用空间会上升,因此对 RSet 的记录划分了三种存储粒度:
- 稀疏表(Sparse):直接通过哈希表来存储,key 是 region index,value 是 card 数组(记录 card index)
- 细粒度(Fine):当一个 region 的 card 数量超过阈值时,退化为一个 bitmap,每一位对应一个 card(index)
- 粗粒度(Coarse):当被引用的 region 数量超过阈值时,退化为只记录 regin 引用情况,由 bitmap 存储,每一位对应一个 region(index)
struct g1_rset {
hash_map<region_id, card_list> sparse;
hash_map<region_id, bitmap<MAX_CARD>> fine_grained;
bitmap<MAX_REGION> coarse;
};
三、CardTable对比RSet
卡表解决 young gc 减少老年代扫描的问题,而 RSet 则解决了(G1 对)所有 Region 的扫描问题。
卡表通过对外引用(Dirty Card)提示我们应该扫描什么区域,这样我们可以避开不用扫描的区域;RSet通过对内引用提示我们应该扫描什么区域,这样我们可以避开不用扫描的区域。
不管是卡表还是 RSet,都通过写表 + 查表的方式减少了对堆的扫描,进而减少 GC 的时间。
使用缓存表来提高查询效率,是化顺序查找为部分随机查找的一种常用的设计思路。
例如,在传统的计算机体系结构中,当我们把内存分成页以后,会有一个页表,页表又会有一个快表,作为一个中间缓存项,来帮助我们查找我们需要使用的页表项(table entry)。