1、数据需求:
采集当前配置任务及子任务的详细信息,页面请求返回数据是json格式。
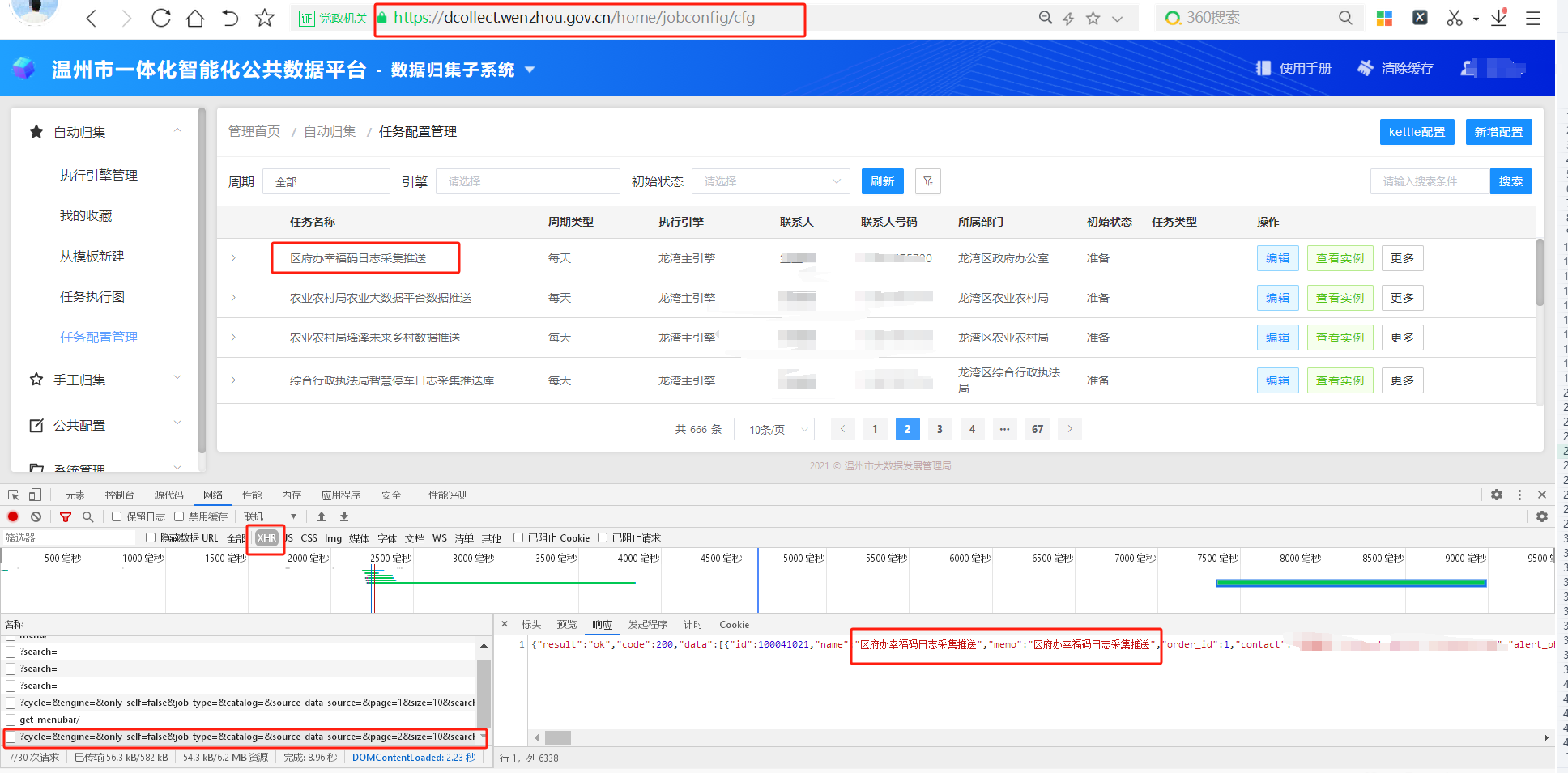
# -*- coding: utf-8 -*- # 爬取公共数据平台数据归集任务 import math import re import pandas as pd import requests #初始化参数 all_data =[] all_data2=[] def directory_list(cookie,Authorization): global items , items2 url = 'https://dcollect.wenzhou.gov.cn/dg_job/v1/cfg/?cycle=&engine=&only_self=false&job_type=&catalog=&source_data_source=&page=4&size=10&search=' #请求头 headers = { "Accept": "application/json, text/plain, */*", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9", "Authorization": Authorization, "Connection": "keep-alive", "Cookie": cookie, "Referer": "https://dcollect.wenzhou.gov.cn/home/jobconfig/cfg", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36" } response = requests.get(url, headers=headers).text #获取总页数 count=re.findall(r'"count":(.*?),"next"',response,re.S)[0] pages=math.ceil(int(count)/10) for page in range(1,pages+1): url=f'https://dcollect.wenzhou.gov.cn/dg_job/v1/cfg/?cycle=&engine=&only_self=false&job_type=&catalog=&source_data_source=&page={page}&size=10&search=' # response=requests.get(url, headers=headers).text response = requests.get(url, headers=headers).json() # print(response) items = response['data'] for data in items: # 获取id id = data['id'] # 获取任务名称 name = data['name'] # 获取联系人 contact = data['contact'] # 获取联系电话 contact_phone = data['contact_phone'] # 获取子任务数量 sub_cfg_count = data['sub_cfg_count'] # 获取周期类型 cycle_name = data['cycle_name'] # 获取创建时间 create_time = data['create_time'] # 获取更新时间 update_time = data['update_time'] all_data.append( { 'id': id, '任务名称':name, '联系人':contact, '联系电话':contact_phone, '子任务数量':sub_cfg_count, '周期类型':cycle_name, '创建时间':create_time, '更新时间':update_time } ) url2 = f'https://dcollect.wenzhou.gov.cn/dg_job/v1/sub_cfg/?cfg={id}&size={sub_cfg_count}&page=1&job_type=' response2=requests.get(url2, headers=headers).json() items2= response2['data'] for data in items2: name2 = data['name'] all_data2.append({ '子任务': name2 }) # 将数据保存为Excel文件 df = pd.DataFrame(all_data) df2 = pd.DataFrame(all_data2) df.to_excel('公共数据平台归集任务数据采集.xlsx', index=False) df2.to_excel('公共数据平台归集任务数据采集-子任务.xlsx', index=False) #授权、cookie 都具有时效性每次执行获取最新 Authorization='******' cookie='******' directory_list(cookie,Authorization)