完全信息动态博弈是一种研究行为科学者、决策者和经济学家最关心的博弈理论形式之一。它试图研究他们在某种状况下,如何让一组参与者在他们之间分得最大的利益。完全信息动态博弈是一种行为科学模型,可以通过模拟和抽象实际的情况来研究系统中的行为。因此,它是一种重要的研究工具,可以用来模拟和研究不同情境下的博弈局势。完全信息动态博弈涉及有两个或更多参与者,每个人都有自己的可以改变的决策行为。它还涉及到一个模型环境,这些参与者都使用相同的规则来发展他们的决策,而改变决策可以带来某种好处或坏处。所以,完全信息动态博弈是由多个参与者的行为引起的系统分析模型,而这些参与者都会因为相同的模型而产生不同的决策。
一、扩展式博弈(博弈树)
之前我们运用博弈的策略式表述分析了静态博弈,这里我们引入博弈的扩展式表述并用它分析动态博弈。这一解释方法可能会给人一个印象,那就是静态博弈一定要用标准式表述,动态博弈一定要用扩展式表述。但这是一种误解,任何博弈都既可以用标准式表述,又可以用扩展式表述,尽管对某些博弈来讲,用其中一种表述形式分析起来较另外一种要方便一些。一个博弈的策略式表述包含的要素有:(1)博弈的参与人;(2)每一参与人可供选择的策略;及(3)与参与人可能选择的每一策略组合相对应的各个参与人的收益。
博弈的扩展式表述包括:(1)博弈中的参与人;(2a)每一参与人在何时行动;(2b)每次轮到某一参与人行动时,可供他选择的行动;(2c)每次轮到某一参与人行动时,他所了解的信息;及(3)与参与人可能选择的每一行动组合相对应的各个参与人的收益。
参与人的一个策略是关于行动的一个完整计划——它明确了在参与人可能遇到的每一种情况下对可行行动的选择。在参与人\(j\)计算针对参与人\(i\)的最优反应时,\(j\)需要考虑在每一种情况下i将如何行动,而并非仅考虑在\(i\)或\(j\)认为最有可能发生的情况下对方的行动。
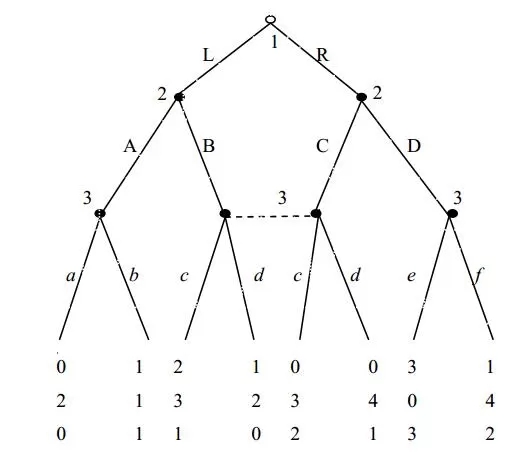
博弈的扩展式通过引入博弈树来描述。博弈树始于参与人\(1\)的一个决策节(decision node),这时\(1\)要从\(L\) 和\(R\) 中作出选择,如果参与人\(1\)选择\(L\) ,其后就到达参与人\(2\)的一个决策节,这时\(2\)要从\(L'\) 和\(R'\)中选择行动。无论\(2\)选择了哪一个,都将到达终点节(terminal node)(即博弈结束)且两参与人分别得到相应终点节下面的收益,参看下图。

1.1 扩展式博弈——信息集
为在博弈的扩展式中表示静态博弈的情况,引入一个新的概念——参与人的信息集(information set)。参与人的一个信息集指满足以下条件的决策结的集合:
(i) 在此信息集中的每一个节都轮到该参与人行动,且
(ii) 当博弈的进行达到信息集中的一个节,应该行动的参与人并不知道达到了(或没有达到)信息集中的哪一个节。
第(ii)部分意味着参与人在一个信息集中的每一个决策节都有着相同的可行行动集合,否则该参与人就可通过他面临的不同的可行行动集来推断到达了(或没有到达)某些结点。
在引入了信息集的概念之后,可以给出区分完美信息和非完美信息的另外一种定义。前面我们曾将完美信息定义为在博弈的每一步行动中,轮到行动的参与者了解前面博弈进行的全部过程。对完美信息的一个等价的定义是每一个信息集都是单节的;相反,非完美信息则意味着至少存在一个非单节的信息集。那么,一个同时行动博弈的扩展式表述就是一个非完美信息博弈。这种用是否单节信息集区分完美信息和非完美信息的方法只限于完全信息的博弈,因为完美但非完全信息博弈的扩展式表述就含有非单节的信息集,这里我们只讨论完全信息的情况。
1.2 扩展式博弈——博弈树
博弈树是指由于动态博弈参与者的行动有先后次序,因此可以依次将参与者的行动展开成一个树状图形。博弈树是扩展型的一种形象化表述。它能给出有限博弈的几乎所有信息,其基本构建材料包括结、枝和信息集。结包括决策结和终点结两类;决策结是参与人采取行动的时点,终点结是博弈行动路径的终点。枝是从一个决策结到它的直接后续结的连线(有时用箭头表述),每一个枝代表参与人的一个行动选择。博弈树上的所有决策结分割成不同的信息集。每一个信息集是决策集集合的一个子集,该子集包括所有满足下列条件的决策结:(1)每一个决策结都是同一参与人的决策结;(2)该参与人知道博弈进入该集合的某个决策结,但不知道自己究竟处于哪一个决策结。
博弈树的特点
(1) 博弈的初始格局是初始结点。
(2) 在博弈树中,”或”结点和”与”结点是逐层交替出现的。自己一方扩展的结点之间是”或”关系,对方扩展的结点之间是”与”关系。双方轮流地扩展结点。
(3) 非叶子结点:代表博弈玩家,表示这个时候哪个博弈玩家做出决策。每个非叶子结点有且仅有一个博弈玩家。叶子结点:代表每个玩家在此时的收益。收益只存在于叶子结点。
(4)边:表示策略
二、完全信息动态博弈
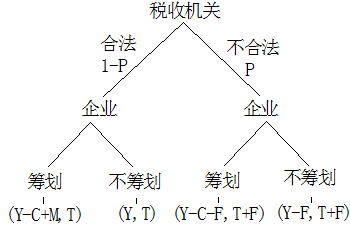
完全信息动态博弈的一个重要特征是完全信息,意味着每个参与者都知道另一个参与者的行动,也知道另一个参与者从这个行动中获得什么样的利益损失。这允许他们考虑到彼此的角色,更好地理解另一个参与者对他们自己利益和损失的影响。有时候,完全信息会被认为是一种缺乏竞争元素的情况,因为当参与者都知道对方的行动时,他们就不太可能达成共同的行为。另一个重要特征是动态性,这意味着参与者可以在游戏过程中改变决策,而这一改变可以影响其他参与者的利润。此外,动态博弈还可以用胜负来衡量收益,因为参与者根据他们的行动可以获得更多的收益。
例1:最后通牒博弈
这个博弈来源于一个真实的故事,但故事本身一点不好玩,我们把其中的博弈游戏抽象出来即可。博弈需要两个人,假设为A和B。A得到了100元,他就获得了分配权。A可以随意分配这100元,可以给B50元,也可以给他10元,当然也可以一分钱都不给。B没有分配权,但他可以接受A的分配方案,也可以拒绝。之所以称之为“最后通牒博弈”,就在于:如果B拒绝了,那么A和B两个人都将失去所有钱。
A可以按100:0分配(即一分不给B),B当然会拒绝,于是两个人都一无所有。A也可以按0:100分配(即全给B),B当然会同意,但A显然不同意。A也可以按50:50分配,B会不会拒绝不知道。很多人做过这样的实验,结果是A的分配方案:中位数在40%50%,平均数在30%40%,A并不会把所有的钱据为己有,或许觉得自己有分配权,因此多拿一点应该,但不能太多,因为那样就“不公平”。请注意:公平,不是理性人应该考虑的问题。B的拒绝底线在20%左右,也就是低于20%的分配方案很大机会被拒绝,因为这TM侮辱人嘛,打发叫花子呢!B本来就是一无所有,能得20元也是一笔不少的收入啊。注意:侮辱,也不是理性人应该考虑的问题。

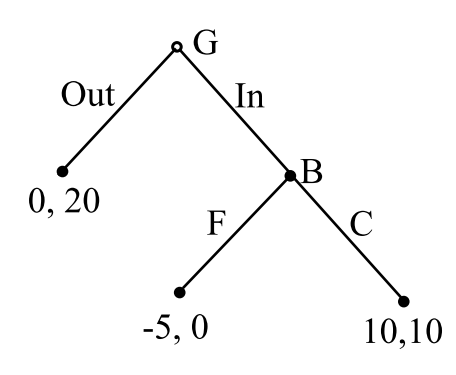
例2:开金矿博弈
甲开采价值4千万元的金矿,缺1千万资金,想说服乙投资,许诺采到金子后对半分成。

在不同的法律环境下有不同的策略可信性,因此就有了不同的相机选择:

结论(1)动态博弃中,博弈方会相机选择,即根据不同阶段的情况灵活做出决策;(2)动态博弃中, 博弃方的策略选择和博弈结果,与策略可信性密切相关;(3)策略的可信性是动态博弈分析的核心问题之一。
例3:谷歌和百度博弈
谷歌想进入中国市场,百度可以选择“对立(F)”和“合作(C)”。
三、子博弈精炼纳什均衡
由于纳什均衡在动态博恋博弈中不能排除不可信的行为选择, 不是真正具有稳定性的均衡概念, 因此需要发展新的均衡概念以满足动态博弈分析的需要。
3.1 子博弈
由一个动态博弈第一阶段以后的某阶段开始的后续博弈阶段构成,有初始信息集和进行博弈所需的全部信息,能够自成一个博弈的原博弈组成部分,称为原动态博弈的一个“子博弈” 。
首先子博弈不能包括原博弈的第一个阶段,这也意味着动态博弈本身不是自己的子博弈。
其次子博弈必须有一个明确的初始信息集,意味着子博弈不能分割任何信息集,有多节点信息集不完美信息博弈可能不存在子博弈(例如好天气坏天气博弈)

在开金矿博弈中,每层虚线框代表了一级子博弈,因此开金矿博弈第三阶段是原博弈的“二级子博弈”
3.2 子博弈精炼纳什均衡
如果一个完全信息动态博弈的一个策略组合,满足在整个动态博弈及它的所有子博弈中都构成纳什均衡,那么该均衡就是一个“子博弈精炼纳什均衡” 。
子博弈完美纳什均衡与纳什均衡的根本不同之处 , 也是这个概念的价值所在, 就在于它能够排除均衡策略中不可信的威胁或承诺, 因此是真正稳定的。子博弈完美纳什均衡能排除不可信行为选择的原因是,虽然包含不可信行为选择的策略组合可以构成整个博率的纳什均衡, 但不可信行为至少在某些子博弈中无法构成纳什均衡, 因此会被排除出去。
在法律保障力度不足的开金矿博弈中:(借,打,分)是整个博弈的纳什均衡(任何一方都不能改变自己的策略而得益,甲选择分了,如果不分而乙选择打,则收益下降,因此仍是纳什均衡),但在第二级子博弈中并不是纳什均衡(因为乙选择打在这个小的子博弈里来说就不是纳什均衡),因此不是“子博弈精炼纳什均衡”。这也就验证了子博弈完美纳什均衡能够排除不可信的威胁,而(不借,不打;不分)才是子博弈完美纳什均衡。
此时第二阶段甲的选择结点,第三阶段乙的选择结点为“不在选择路径上”,两博弈方策略中在这两个节点的选择为“不在均衡路径上的选择”。All in all 子博弈精炼纳什均衡也是纳什均衡, 是比纳什均衡更强的均衡概念, 且是动态博弈分析最核心的概念。动态博弈分析必须先找出它们的子博弈完美纳什均衡, 求动态博弈子博弈完美纳什均衡的基本方法是逆推归纳法。逆推归纳法从动态博弈的最后一级子博弈开始, 逐步找博弈方在各级子博弈中的最优选择。逆推归纳法确定的各博弈方策略不可能包含不可信的行为选择, 找出的均衡策略组合一定是子博弈精炼纳什均衡。
(Selten,1965)如果参与者的策略在每一子博弈中都构成纳什均衡,则称纳什均衡是子博弈精炼的。任何有限的完全信息动态博弈(即任何参与者有限、每一参与者的可行策略集有限的博弈)都存在子博弈精炼纳什均衡,也许包含混合战略。
3.3 逆向递推法
AB两人吃饭挑吃什么,A先选食材,B再选做法。A可以选羊肉和牛肉,如果选羊肉,B就可以选择喝羊肉汤或者羊肉饺子, 如果选牛肉,B就可以选择喝牛肉汤或者牛肉饺子。而且我们还知道,A喜欢吃饺子,B喜欢喝汤。

A选的时候他会怎么想呢?他知道不论选哪种肉,B都会选汤,自己不得不喝汤。假设A喜欢羊肉汤而非牛肉汤,喜欢牛肉饺子而非羊肉饺子。即使如此,A也不会因为喜欢牛肉饺子而选牛肉,因为B会拿牛肉去做汤,所以,A只好选羊肉去喝羊肉汤了。在这个例子里,我们根据B喜欢喝汤的偏好才能猜出A最终的选择,也就是倒着推。这个例子或许并不严谨,纯粹是为了让读者更容易理解为什么采用倒推的思想来求均衡。
例4:斯塔克伯格竞争
古诺模型实际上是假定两个寡头厂商同时作出各自的产量决策的。现在假设厂商1先决定它的产量,然后厂商2知道厂商1的产量后再做出它的产量决策。因此,在确定自己产量时,厂商1必须考虑厂商2将如何作出反应。其他假设与古诺模型相同,这一模型称为斯塔克伯格(Stackelberg)模型。斯塔克尔伯格竞争模型是一个价格领导模型,厂商之间存在着行动次序的区别。产量的决定依据以下次序:领导性厂商决定一个产量,然后跟随者厂商可以观察到这个产量,然后根据领导性厂商的产量来决定他自己的产量。要注意的是,领导性厂商在决定自己的产量的时候,充分了解跟随厂商会如何行动——这意味着领导性厂商可以知道跟随厂商的反应函数。
因此,领导性厂商自然会预期到自己决定的产量对跟随厂商的影响。正是考虑到这种影响的情况下,领导性厂商所决定的产量将是一个以跟随厂商的反应函数为约束的利润最大化产量。在斯塔克尔伯格模型中,领导性厂商的决策不再需要自己的反应函数。
设市场需求函数为:
其中\(p_1\)和\(p_2\)分别是两个企业的产量。假设两企业的成本函数相同,都为 \(C=c_0p\),即:
在知道企业2 对任意给定产量的反应后,企业1的最优产量模型为:
因此斯塔克尔伯格(Stackelberg)模型是先求解如下的优化模型:
得到\(p_2=g(p_1)\)
然后再求解如下的优化模型:
得到 \(p_1\),代入\(p_2=g(p_1)\),得到 \(p_2\),如此得到斯塔克尔伯格均衡时的\((p_1,p_2)\)。
具体地,设市场需求函数为\(D=61.2−10∗(p_1+p_2)\),两企业的成本函数都为\(C=1.2p\),求斯塔克尔伯格均衡时两个企业的产量。(企业1为领导者,企业2为跟随者)
解:首先求解如下的优化模型:
得到\(p_2=\frac{60-10p_1}{20}\),然后求解下列优化模型:
得到结果为 \(p_1=3,p_2=1.5\)。
子博弈精炼纳什均衡之所以比较复杂,主要体现在以下两个方面:
纳什均衡只检查整个博弈中的均衡路径,即均衡路径上的策略在整个博弈中是纳什均衡;而子博弈精炼纳什均衡需要检查均衡路径上的策略在每个子博弈中都是纳什均衡。
除了均衡路径之外,子博弈精炼纳什均衡还需要检查非均衡路径,即非均衡路径中的策略在其涉及的每个子博弈中也是纳什均衡。(这往往是难点,因为即使均衡路径是唯一的,非均衡路径却可能有非常多条)