概述
关于 DSL
- DSL(Domain Specific Language)
- 领域专用语言
- Elasticsearch 提供了基于 JSON 的 DSL 来定义查询
组成
- 叶子查询子句:在特定域中寻找特定的值。
- 复合查询子句:复合查询子句包装其他叶子查询或复合查询,并用于以逻辑方式组合多个查询。
基本语法
POST /索引名称/_search
{
"query": {
"查询类型": {
"查询条件": "查询条件值"
}
}
}
查询类型
- match_all
- match
- term
- range
- ...
DSL 查询
数据准备, 定义索引库:
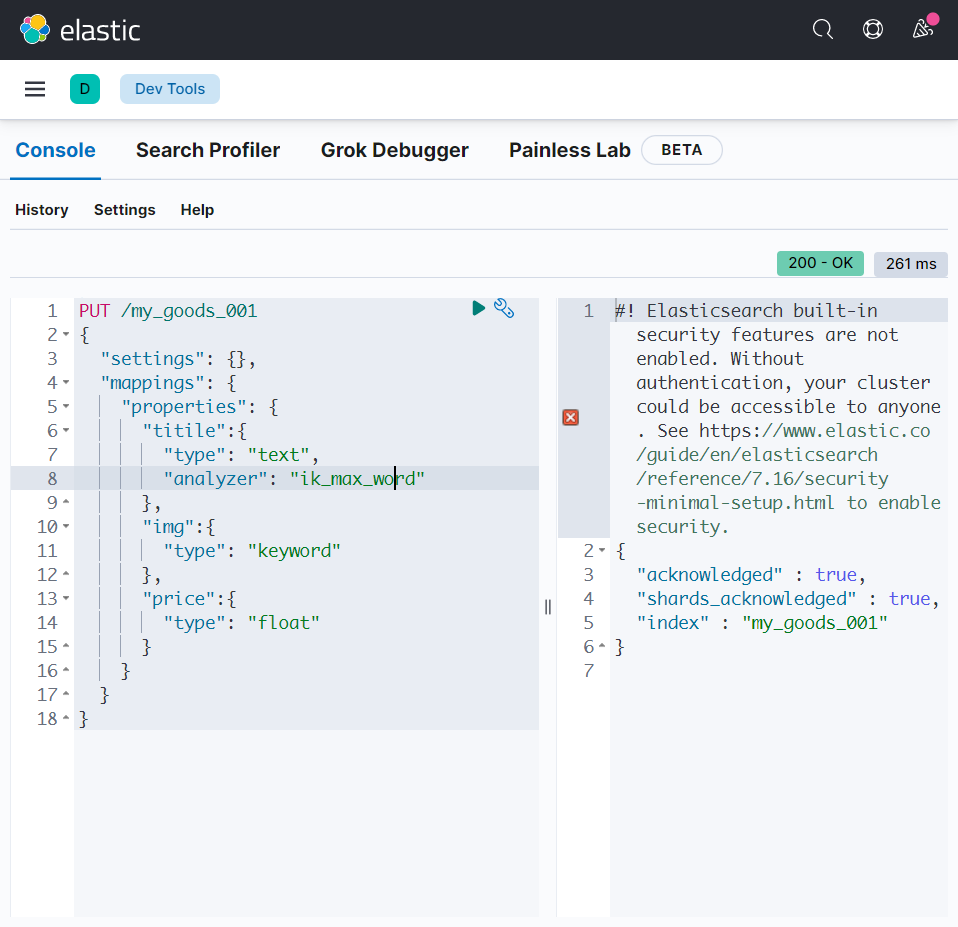
PUT /my_goods_001
{
"settings": {},
"mappings": {
"properties": {
"titile":{
"type": "text",
"analyzer": "ik_max_word"
},
"img":{
"type": "keyword"
},
"price":{
"type": "float"
}
}
}
}
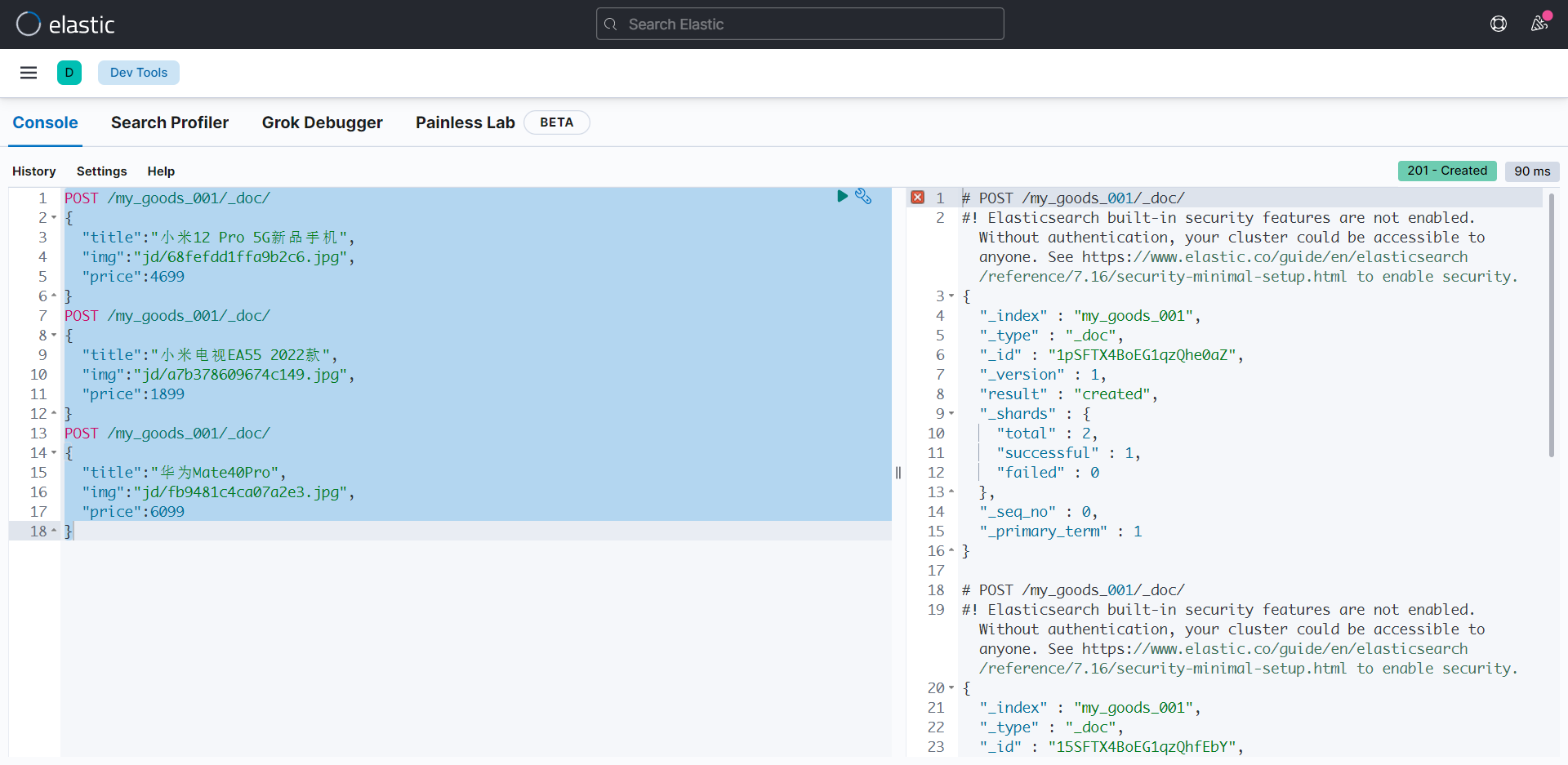
添加数据:
POST /my_goods_001/_doc/
{
"title":"小米12 Pro 5G新品手机",
"img":"jd/68fefdd1ffa9b2c6.jpg",
"price":4699
}
POST /my_goods_001/_doc/
{
"title":"小米电视EA55 2022款",
"img":"jd/a7b378609674c149.jpg",
"price":1899
}
POST /my_goods_001/_doc/
{
"title":"华为Mate40Pro",
"img":"jd/fb9481c4ca07a2e3.jpg",
"price":6099
}
查询所有(match_all query)
无查询条件是查询所有,默认是查询所有的,写法如下:
POST /索引库/_search
{
"query": {
"match_all": {}
}
}
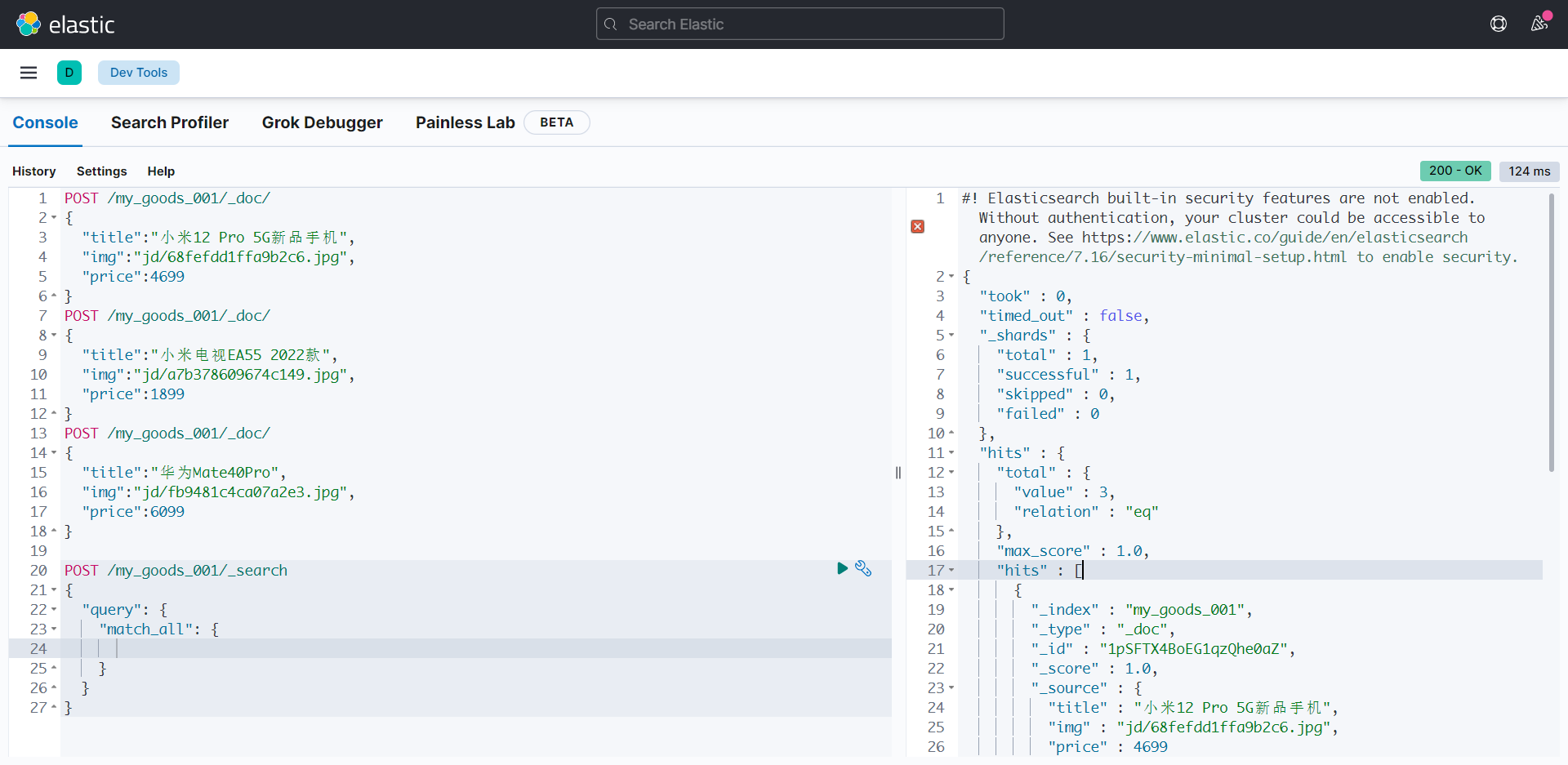
POST /my_goods_001/_search
{
"query": {
"match_all": {
}
}
}
返回结果含义:
- took:查询花费时间,单位是毫秒
- time_out:是否超时
- shards:分片信息
- hits:搜索结果总览对象
- total:搜索到的总条数
- max_score:所有结果中文档得分的最高分
- hits:搜索结果的文档对象数组
- _index:索引库
- _type:文档类型
- _id:文档 id
- _score:文档得分
- _source:文档的源数据
全文搜索
match 匹配搜索
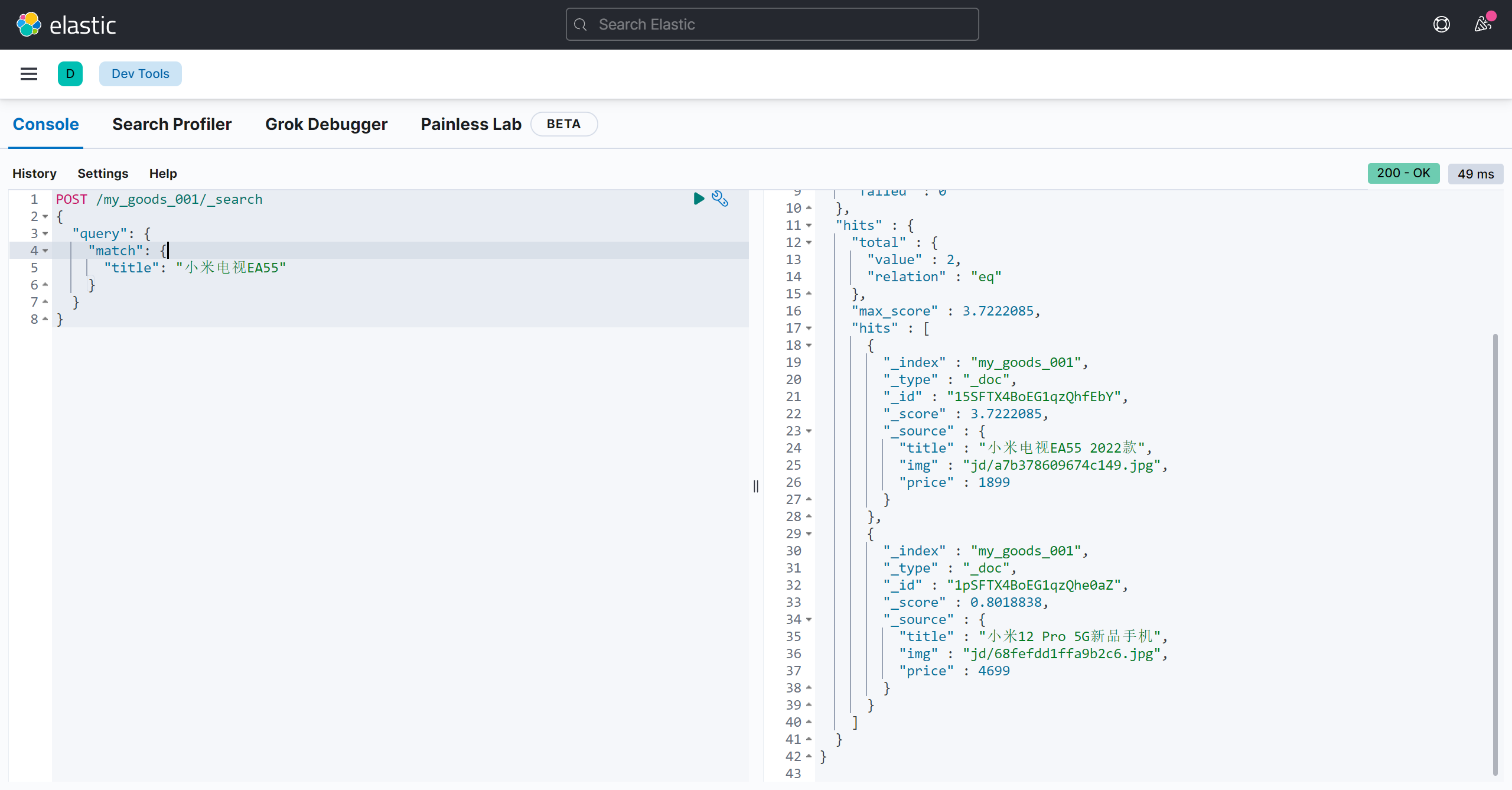
对一个字段进行匹配查询,match 类型查询,match 类型查询,会把查询条件进行分词,or 关系,多个词条之间是 or 的关系:
POST /my_goods_001/_search
{
"query": {
"match": {
"title": "小米电视EA55"
}
}
}
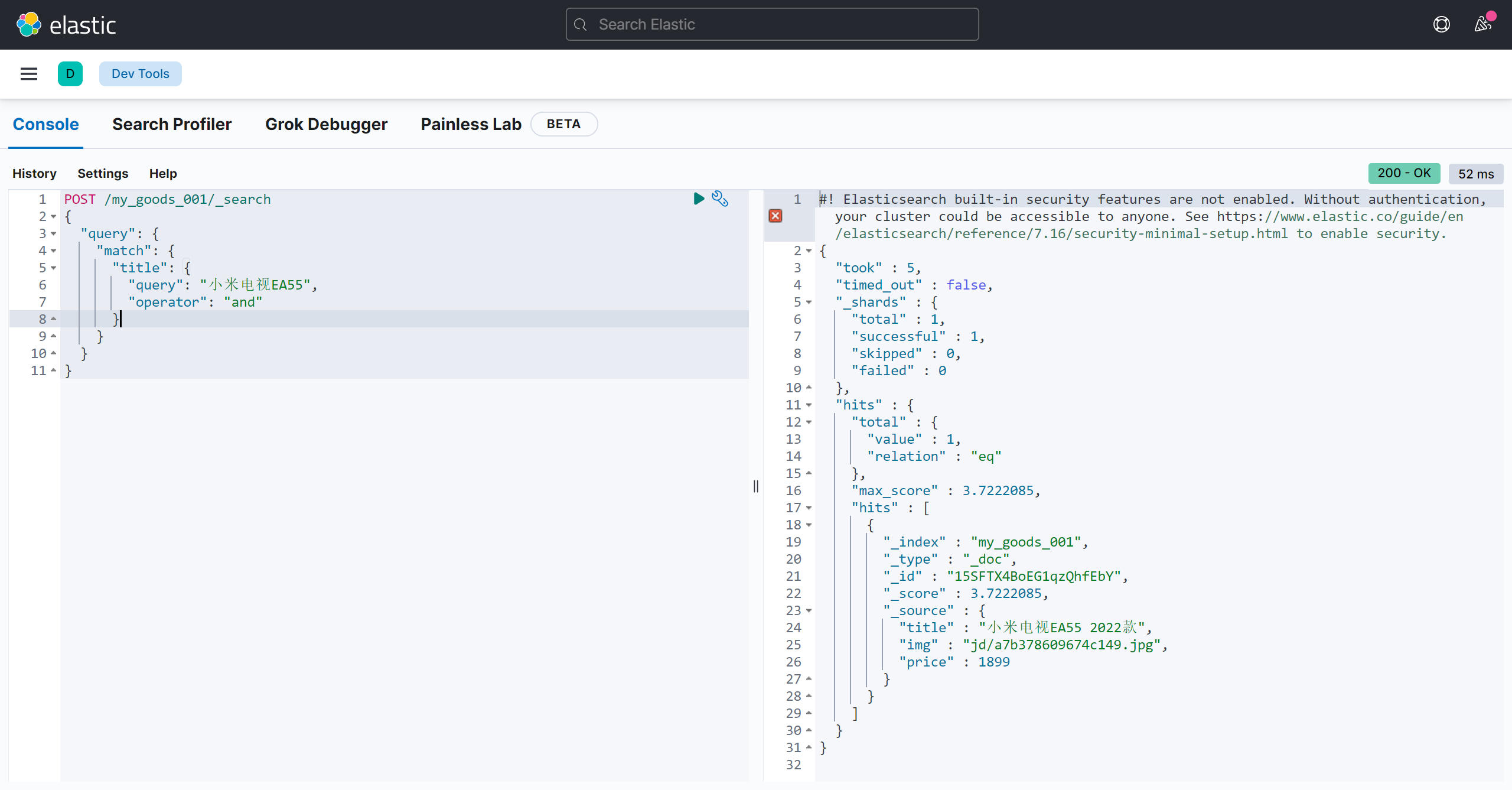
and 关系:
POST /my_goods_001/_search
{
"query": {
"match": {
"title": {
"query": "小米电视EA55",
"operator": "and"
}
}
}
}
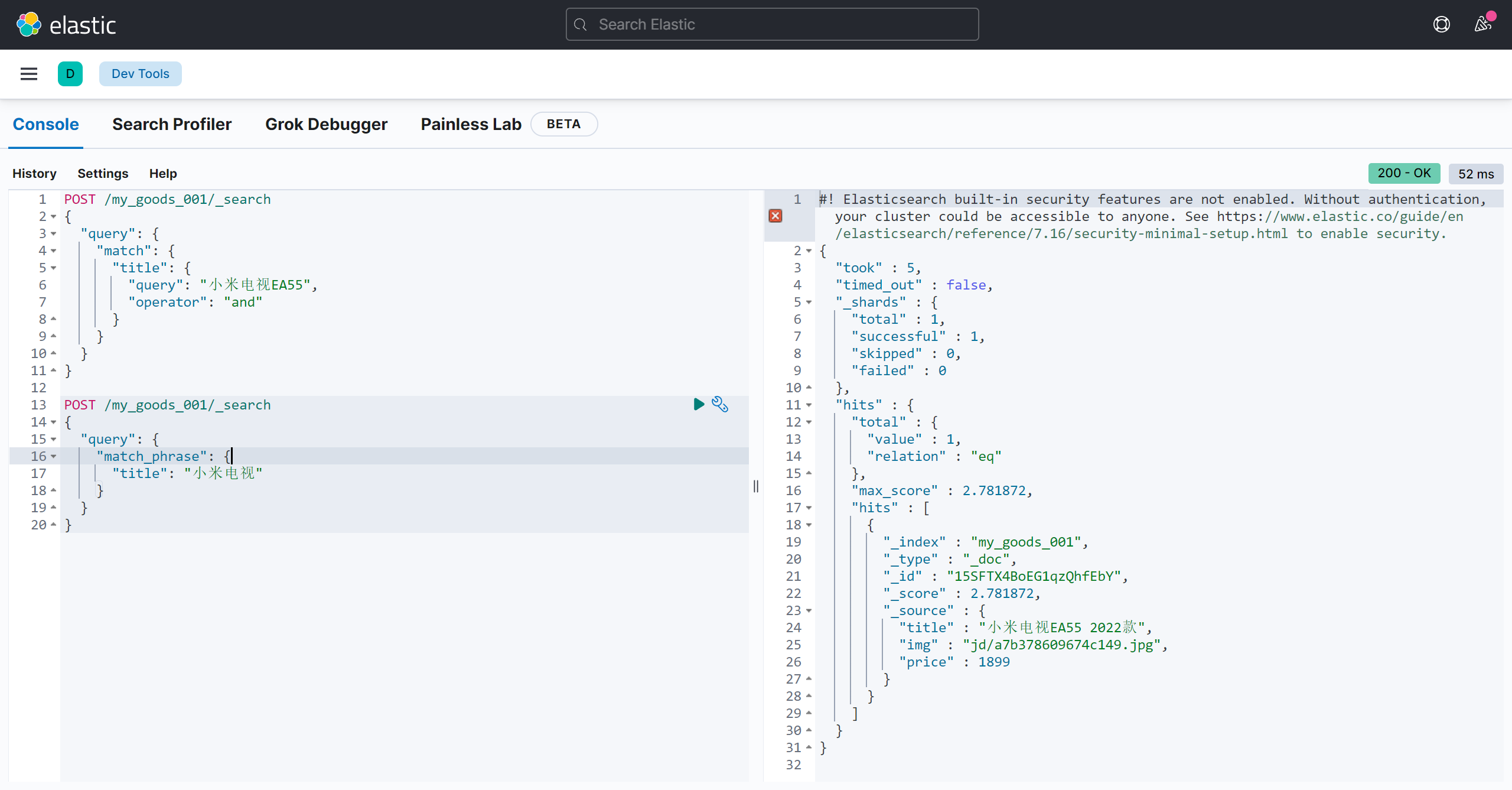
短语搜索
对一个字段进行短语查询, 短语匹配:
POST /my_goods_001/_search
{
"query": {
"match_phrase": {
"title": "小米电视"
}
}
}
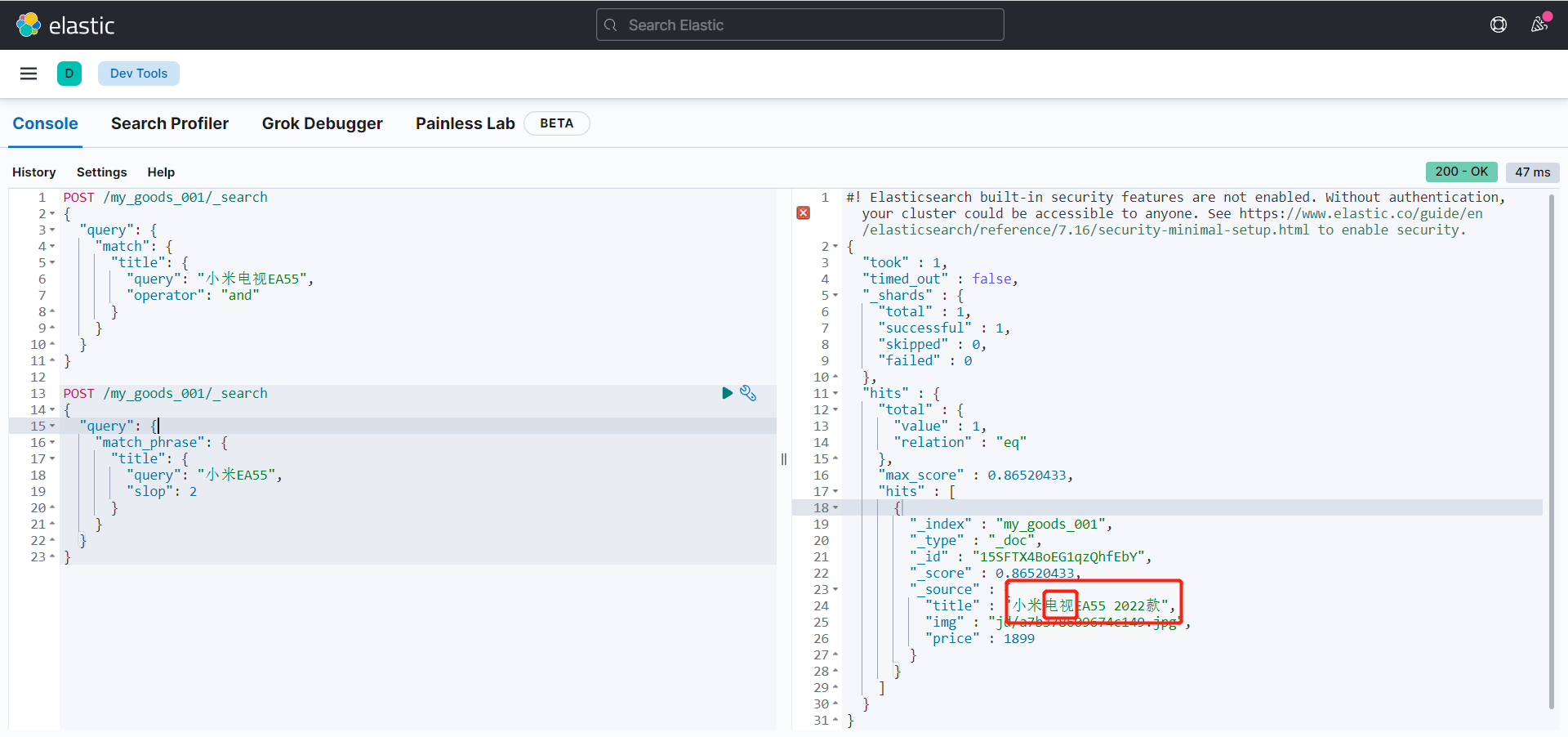
移动因子匹配,关于这个移动因子大概意思就是说假如你现在要搜索一个 小米EA55 如果你的移动因子为 2 那么小米后面两个内容可以是其它的内容然后在拼接EA55来进行查询效果如下:
POST /my_goods_001/_search
{
"query": {
"match_phrase": {
"title": {
"query": "小米EA55",
"slop": 2
}
}
}
}
全文搜索可以理解为 MySQL 当中的模糊搜索。
query_string 查询
无需指定某字段而对文档全文进行匹配查询的一个高级查询。
不指定字段
POST /my_goods_001/_search
{
"query": {
"query_string": {
"query": "手机"
}
}
}
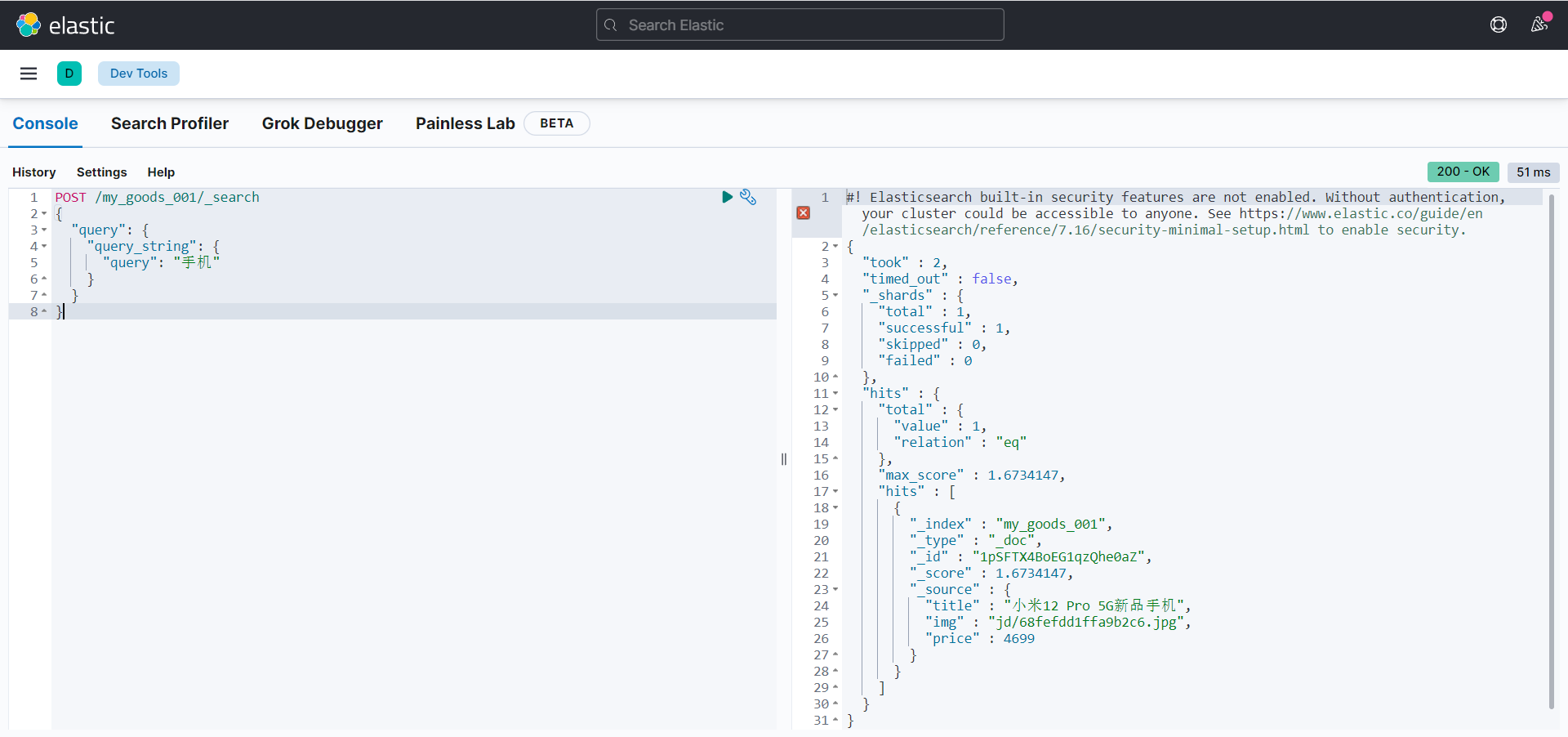
全字段搜索。
指定字段
POST /my_goods_001/_search
{
"query": {
"query_string": {
"query": 1899,
"default_field": "price"
}
}
}
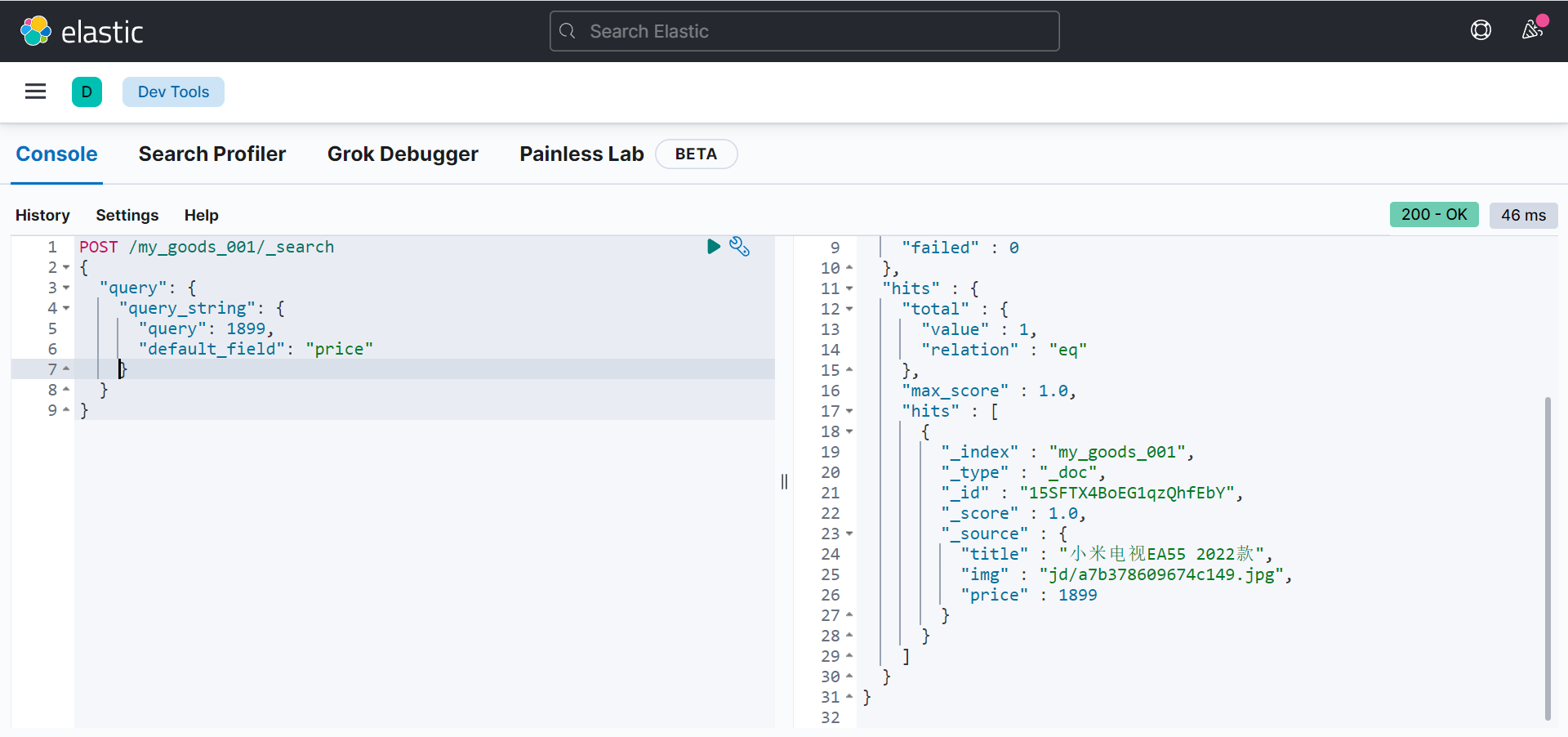
逻辑查询
POST /my_goods_001/_search
{
"query": {
"query_string": {
"query": "小米 AND 手机",
"default_field": "title"
}
}
}

模糊查询
POST /my_goods_001/_search
{
"query": {
"query_string": {
"query": "小米~1",
"default_field": "title"
}
}
}
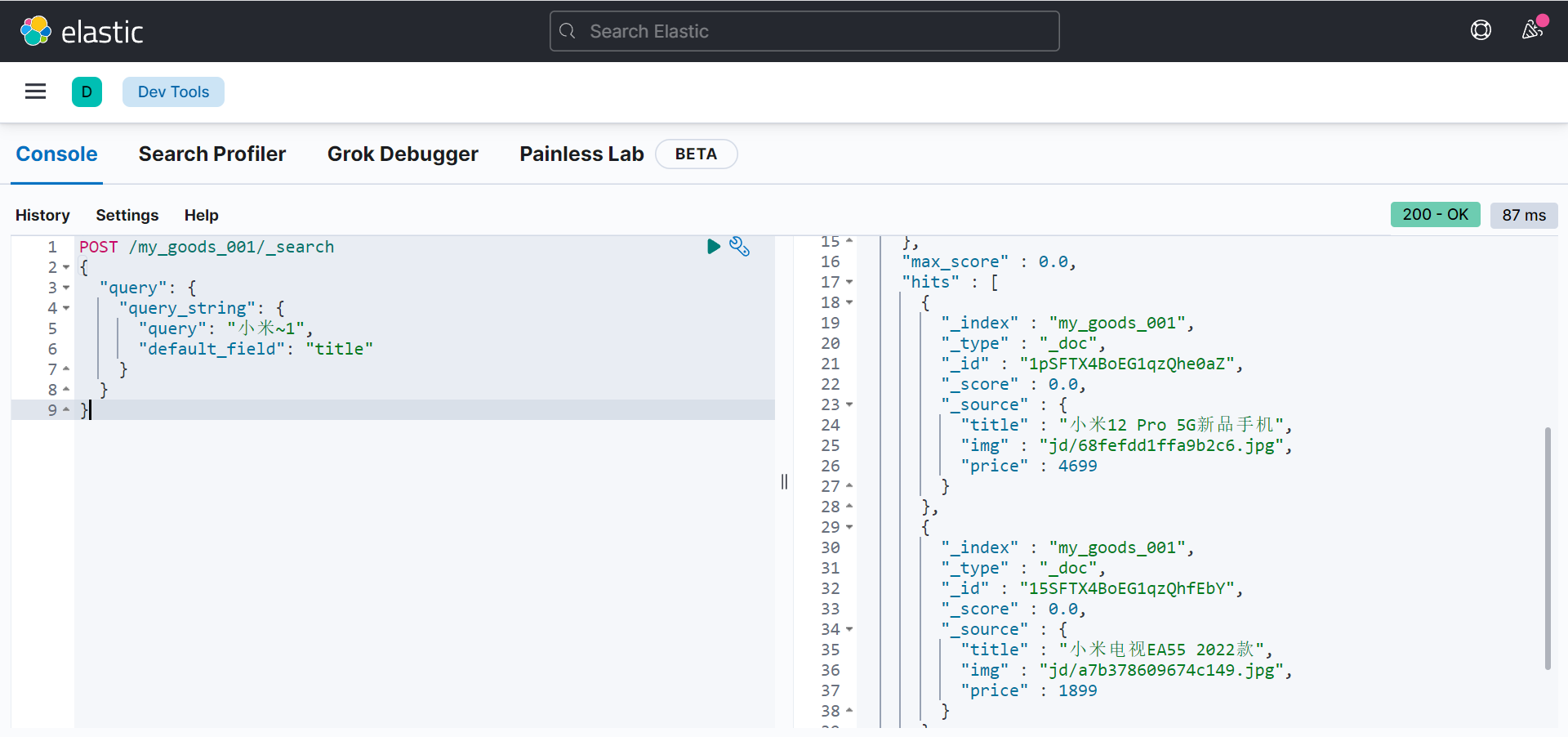
这个模糊搜索主要就是对数据进行修正,如上我编写的为 小米~1 ~1 它内部会自动的进行转换修正,可能会修正为如上所查询出来的电视,或者12啥的。
多字段查询
POST /my_goods_001/_search
{
"query": {
"query_string": {
"query": "1899",
"fields": ["title", "price"]
}
}
}
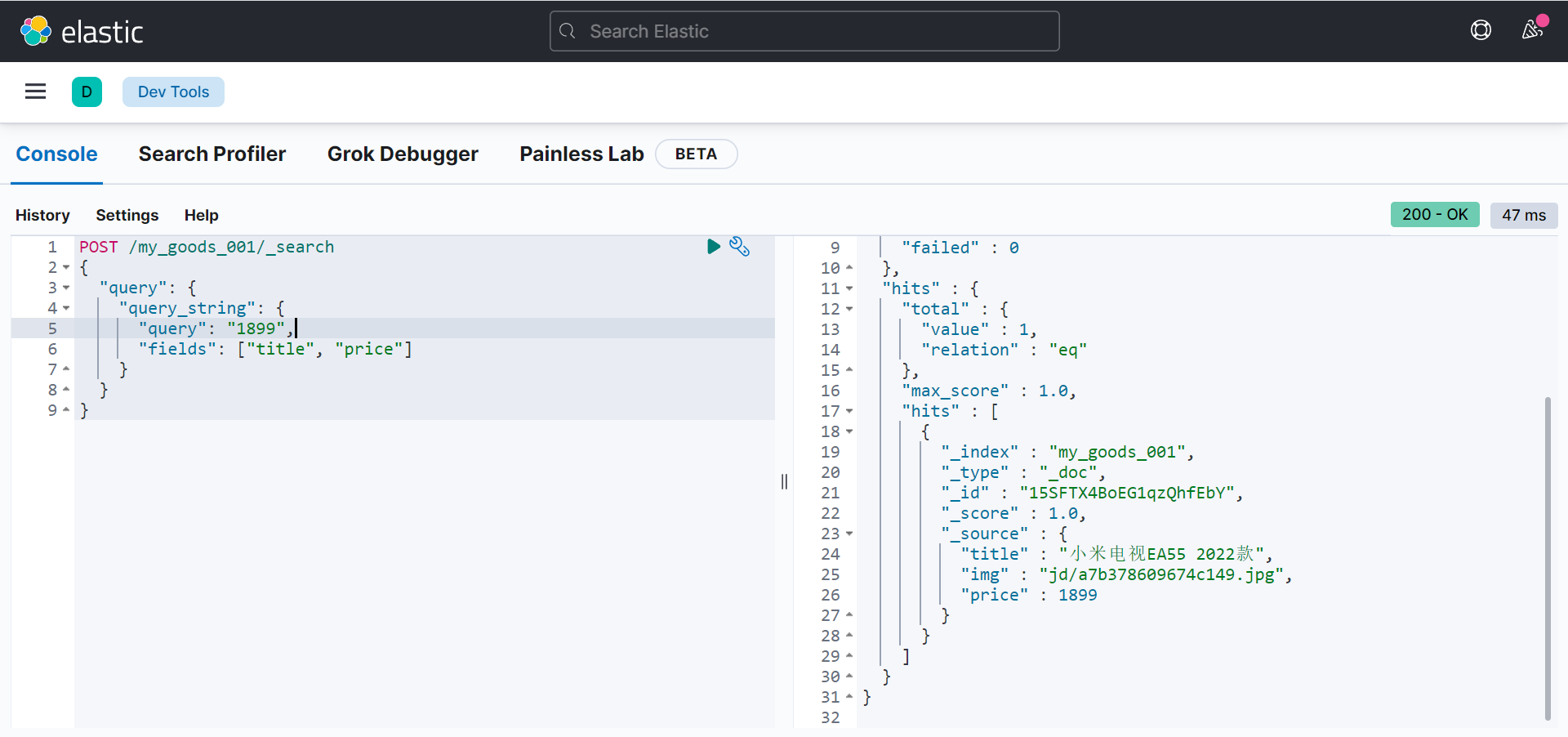
多字段搜索 multi_match
POST /my_goods_001/_search
{
"query": {
"multi_match": {
"query": "1899",
"fields": ["title", "price"]
}
}
}
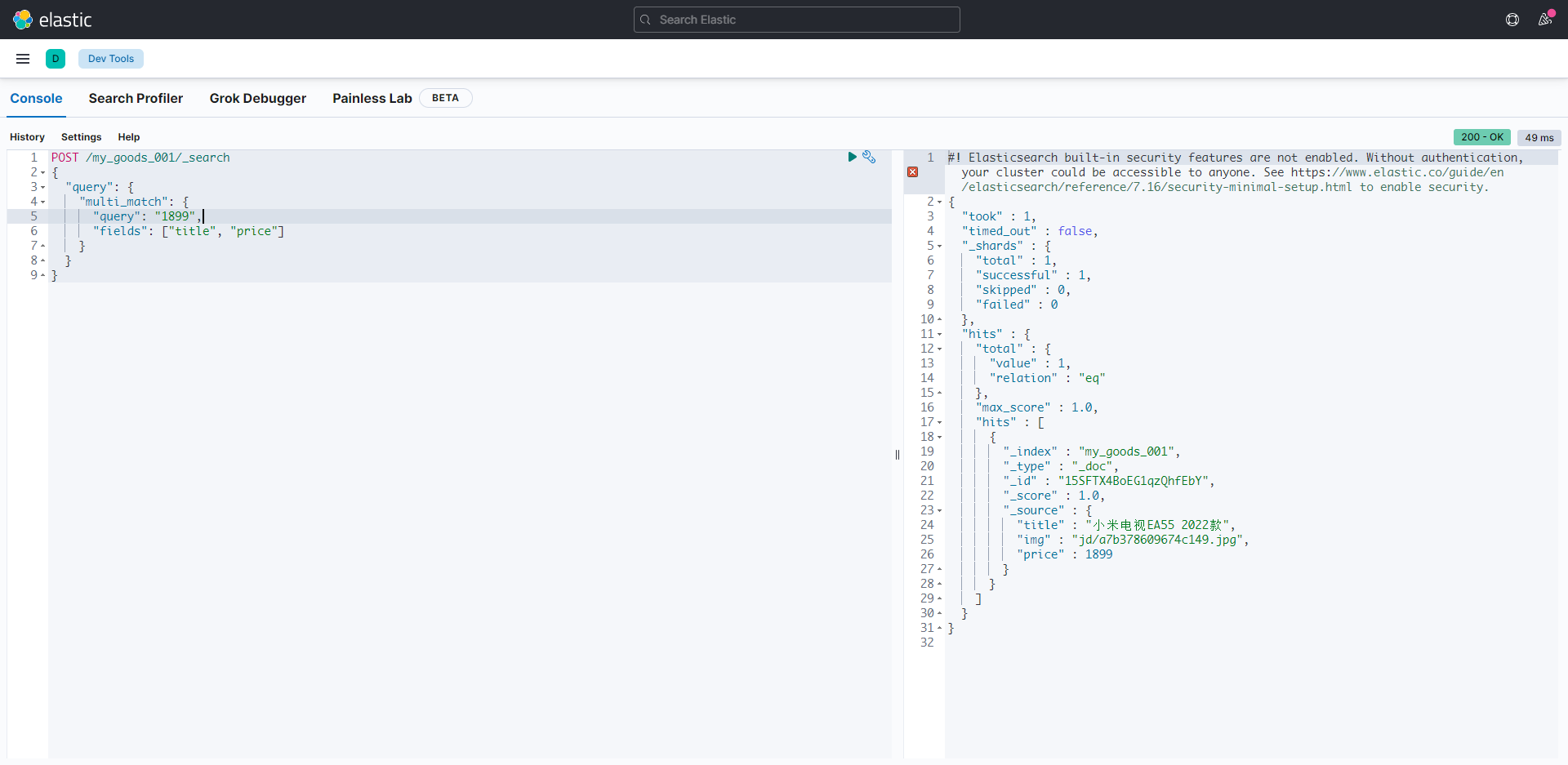
当然搜索的字段可以是进行模糊匹配字段用 * 来表示如下:
POST /my_goods_001/_search
{
"query": {
"multi_match": {
"query": "1899",
"fields": ["title", "pr*"]
}
}
}

词条精确搜索
词条级搜索(term-level queries) 根据结构化数据中的精确值查找文档,term-level queries 不分析搜索词,演示示例数据准备,创建映射:
PUT /my_goods_002
{
"settings": {},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"price": {
"type": "float"
},
"description": {
"type": "text",
"analyzer": "ik_max_word"
},
"create_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
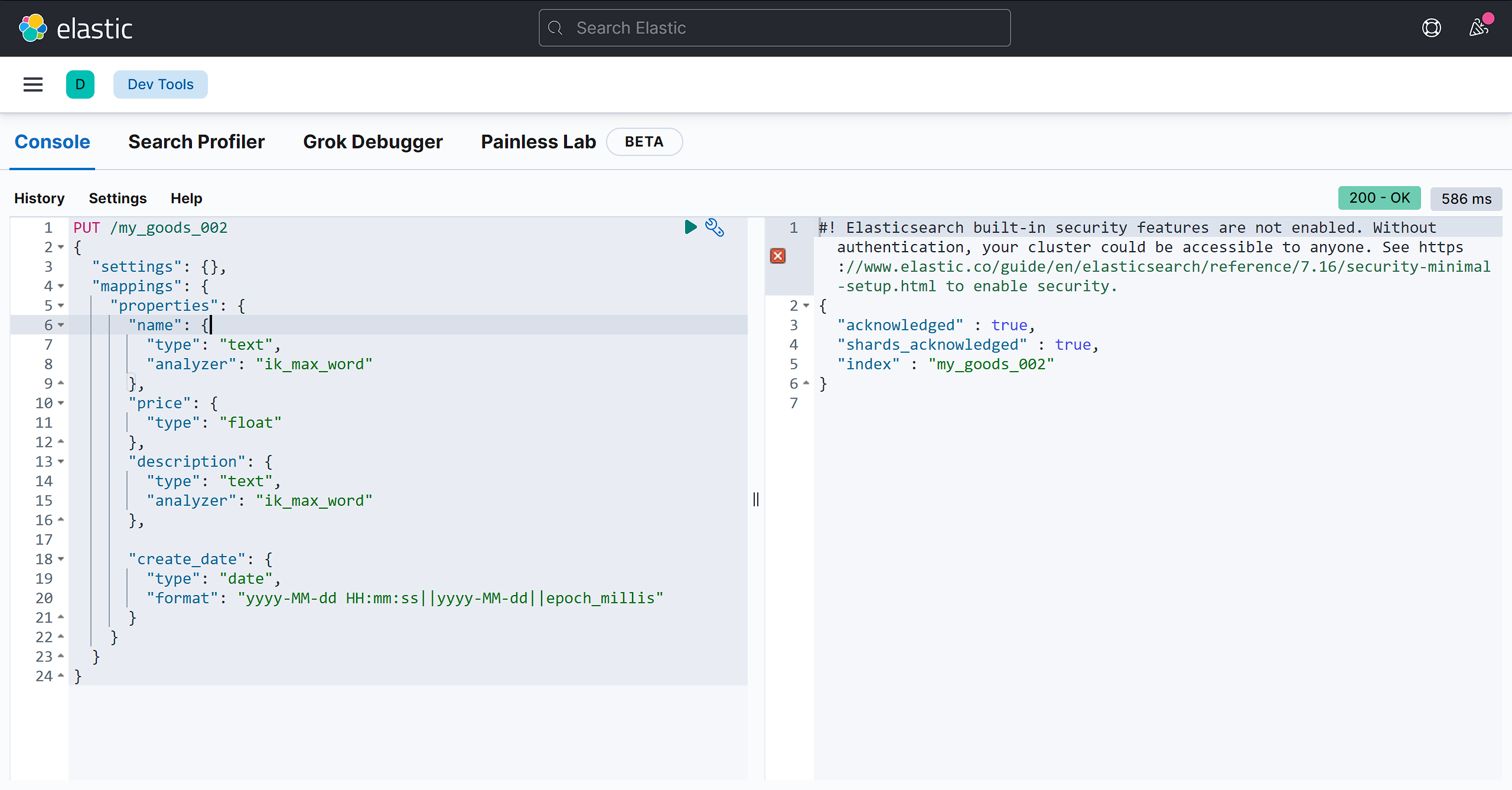
添加数据:
PUT /my_goods_002/_doc/1
{
"name": "Spring实战",
"description": "全球有超过100 000名开发者使用本书来学习Spring 畅销经典Spring技术图书,针对Spring 5全面升级 Spring框架能够让Java开发人员的工作更加轻松。Spring 5的新特性通过微服务、反应式开发进一步提升了生产效率。",
"price":49.50,
"create_date":"2022-01-10 11:12:35"
}
PUT /my_goods_002/_doc/2
{
"name": "MySQL",
"description": "SQL必知必会作者力作,深入浅出MySQL高性能讲解技术内幕,紧贴实战需要,适用于广大软件开发和数据库管理人员学习参考",
"price":24.50,
"create_date":"2021-12-10 18:11:35"
}
PUT /my_goods_002/_doc/3
{
"name": "Elasticsearch",
"description": "Elasticsearch 是一个开源的全文搜索引擎,很多用户对于大规模集群应用时遇到的各种问题难以分析处理,或者知其然而不知其所以然。本书分析 Elasticsearch 中重要模块及其实现原理和机制",
"price":44.50,
"create_date":"2021-12-11 14:18:31"
}
PUT /my_goods_002/_doc/4
{
"name": "Oracle",
"description": "字典式写作手法:不讲具体语法,没有简单知识堆砌,直接以案例形式讲技巧与案例 大量优化实战方法:将主要SQL优化点一一剖析,分享大量SQL优化的实际工作经验 50余改写调优案例:覆盖大多数DBA日常工作场景",
"price":44.90,
"create_date":"2021-11-10 11:12:35"
}
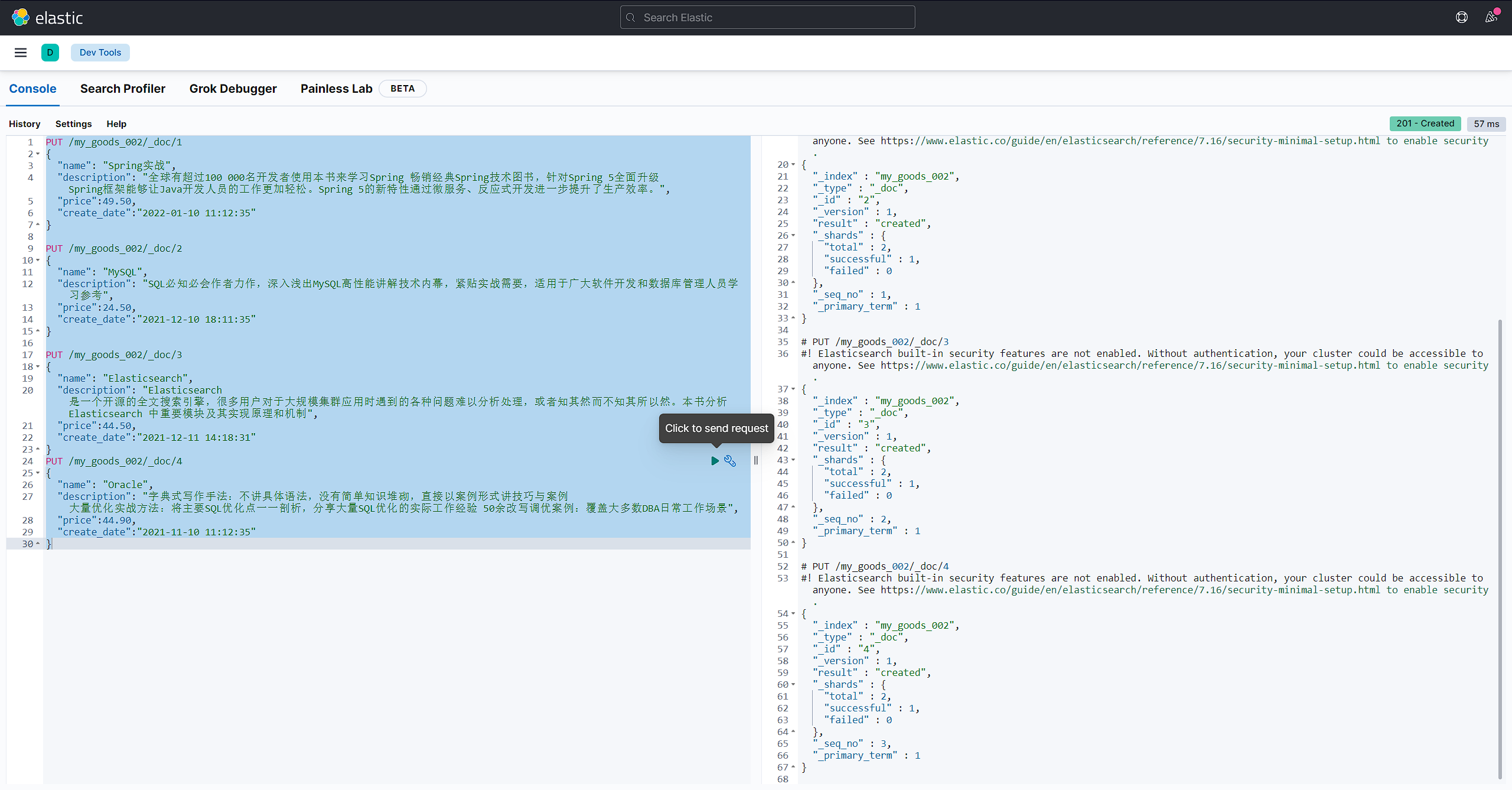
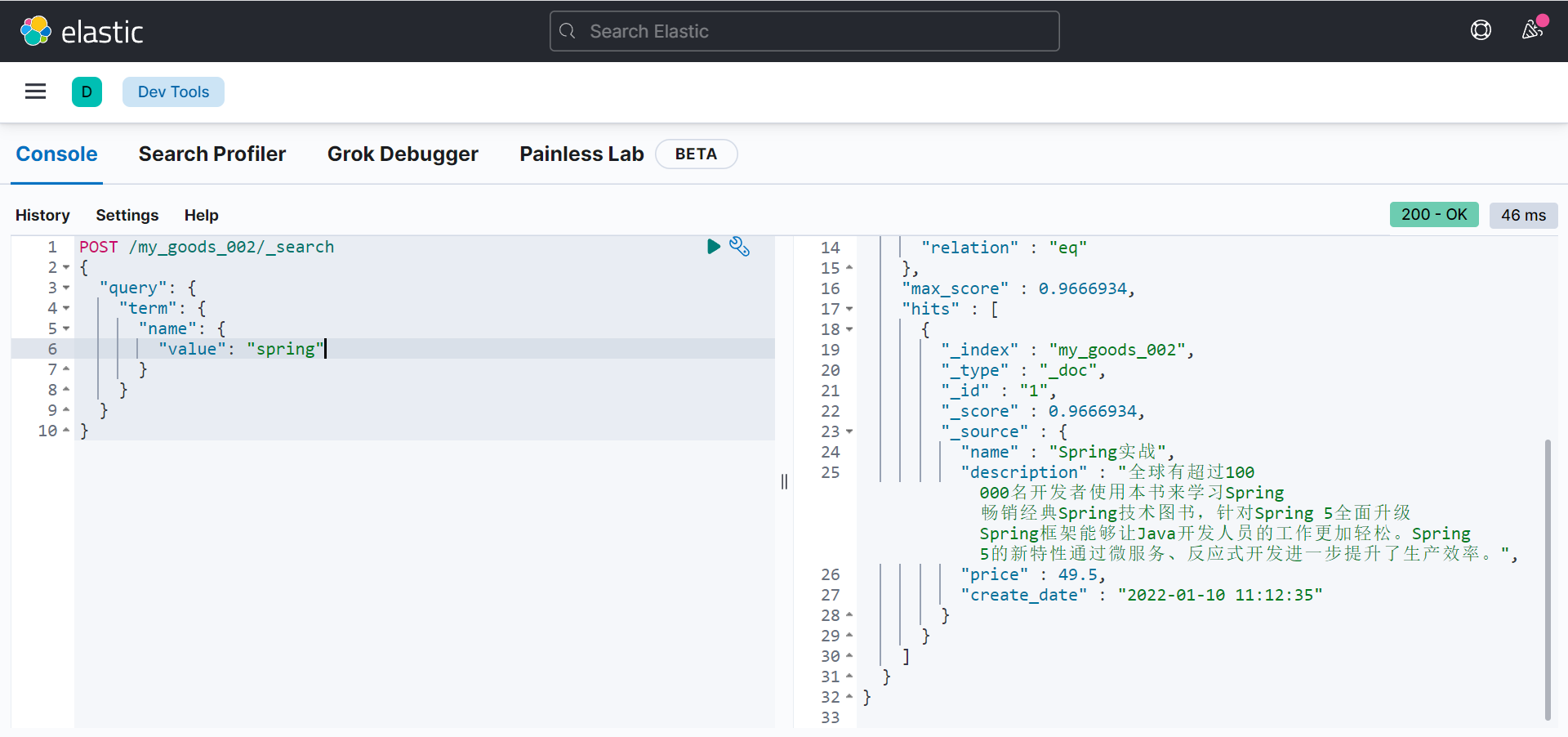
词条搜索
term
查询用于查询指定字段包含某个词项的文档:
POST /my_goods_002/_search
{
"query": {
"term": {
"name": {
"value": "spring"
}
}
}
}
terms
查询用于查询指定字段包含某些词项的文档:
POST /my_goods_002/_search
{
"query": {
"terms": {
"name": [
"spring",
"mysql"
]
}
}
}
range query
查询指定字段范围的值,范围包括:
- gt:大于
- gte:大于等于
- lt:小于
- lte:小于等于
- boost:查询权重
查询指定范围的数据:
POST /my_goods_002/_search
{
"query": {
"range": {
"price": {
"gte": 10,
"lte": 50,
"boost": 1.0
}
}
}
}
查询指定当前日期范围的数据:
POST /my_goods_002/_search
{
"query": {
"range": {
"create_date": {
"gte": "now-30d/d",
"lte": "now/d"
}
}
}
}
查询指定特定日期范围的数据:
POST /my_goods_002/_search
{
"query": {
"range": {
"create_date": {
"gte": "10/12/2021",
"lte": "2022",
"format": "dd/MM/yyyy||yyyy"
}
}
}
}
exists query
查询指定字段值不为空的文档:
POST /my_goods_002/_search
{
"query": {
"exists": {
"field": "name"
}
}
}
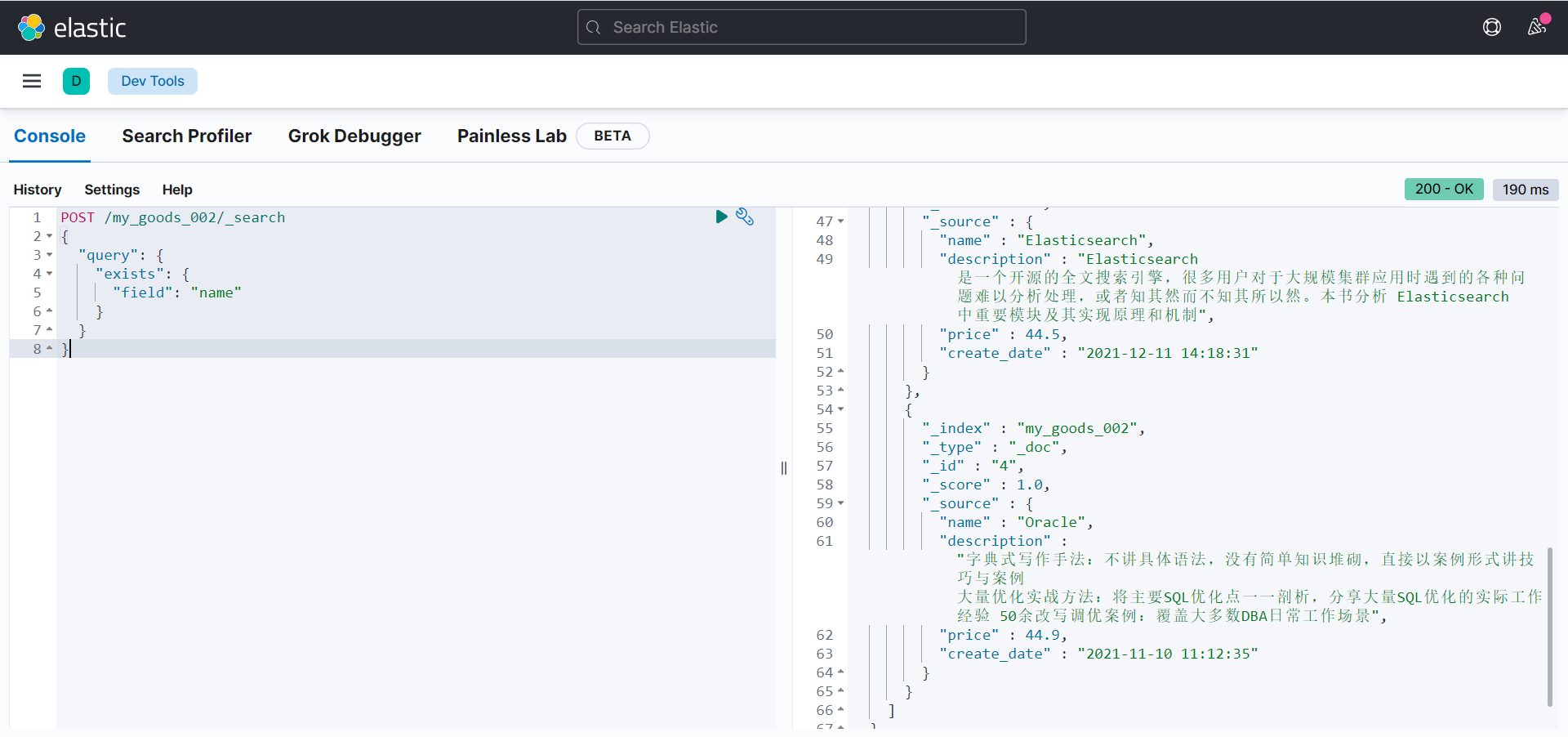
prefix query
词项前缀搜索:
POST /my_goods_002/_search
{
"query": {
"prefix": {
"name": {
"value": "sp"
}
}
}
}
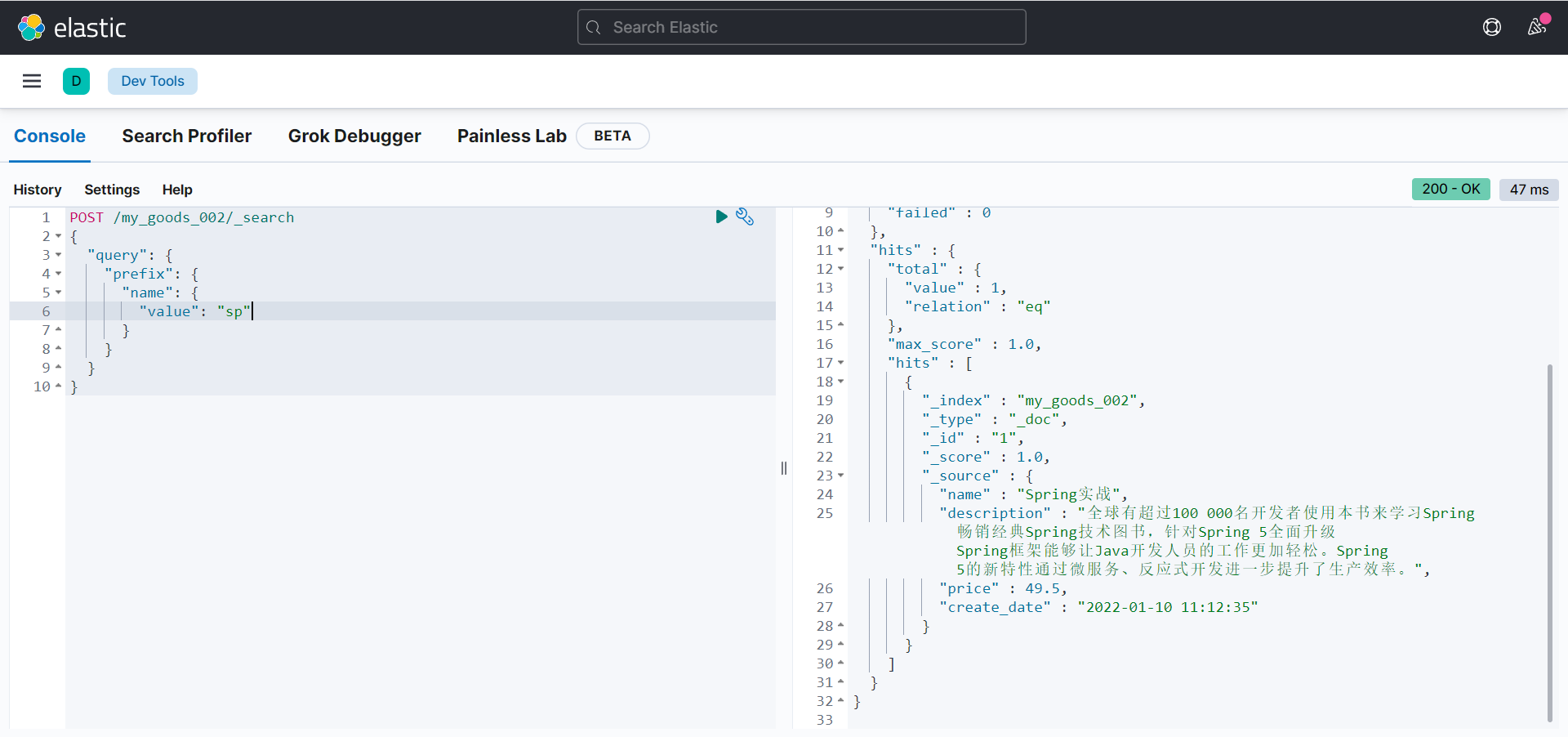
wildcard query
通配符搜索:
POST /my_goods_002/_search
{
"query": {
"wildcard": {
"name": {
"value": "sp*g"
}
}
}
}
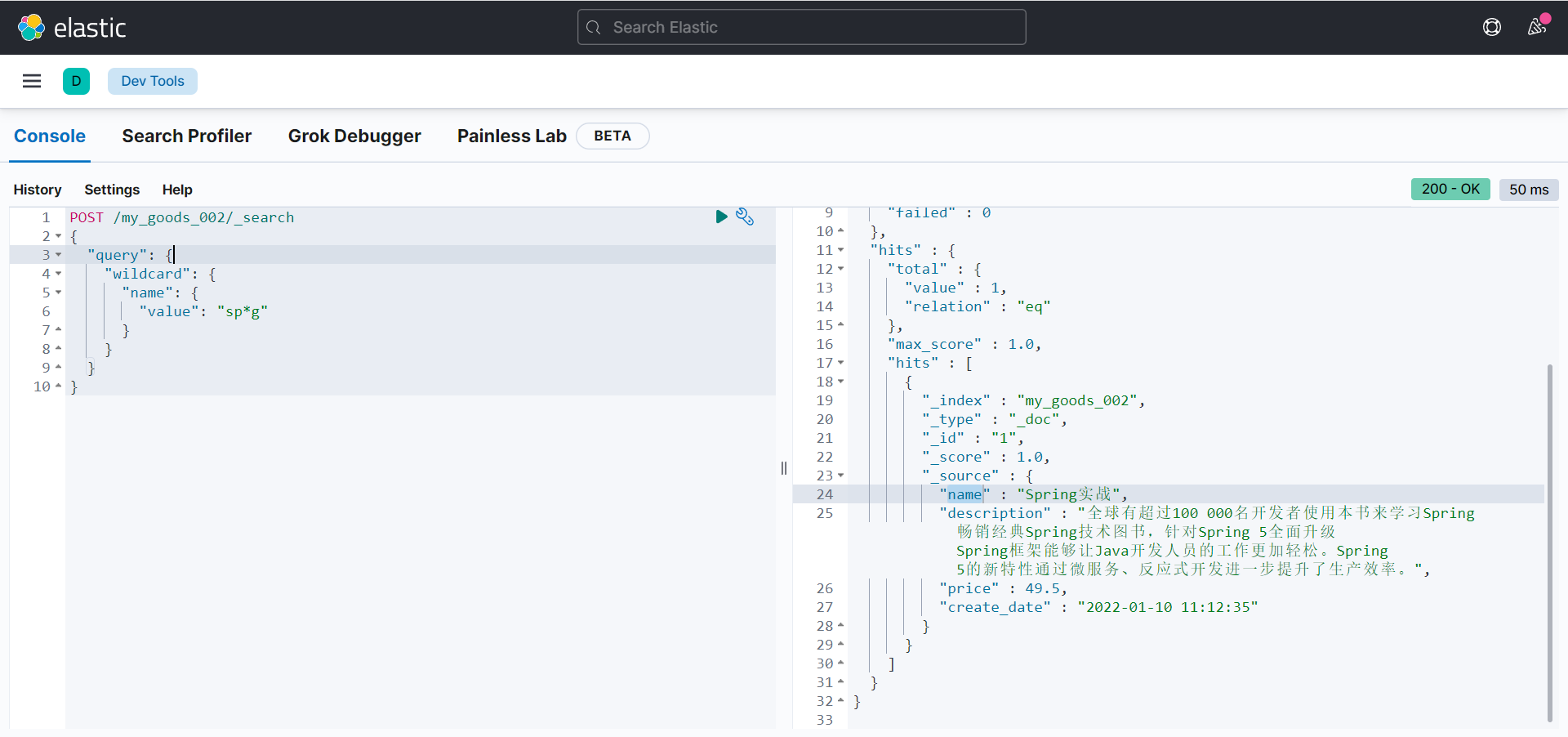
可以在通配符搜索的情况下还可以指定权重比例值:
POST /my_goods_002/_search
{
"query": {
"wildcard": {
"name": {
"value": "sp*",
"boost": 2
}
}
}
}

regexp query
regexp 允许使用正则表达式进行 term 查询,这种方式查询还需谨慎,万一没写好就会造成全查询导致性能下降:
POST /my_goods_002/_search
{
"query": {
"regexp": {
"name": "s.*"
}
}
}
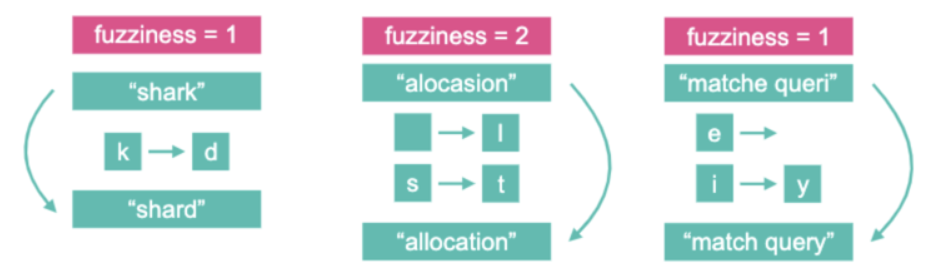
fuzzy query
模糊搜索:
POST /my_goods_002/_search
{
"query": {
"fuzzy": {
"name": {
"value": "sp"
}
}
}
}
没有指定 fuzziness, 查询的内容就是 sp,可以指定 fuzziness 的模糊值:
POST /my_goods_002/_search
{
"query": {
"fuzzy": {
"name": {
"value": "sg",
"fuzziness": 2
}
}
}
}
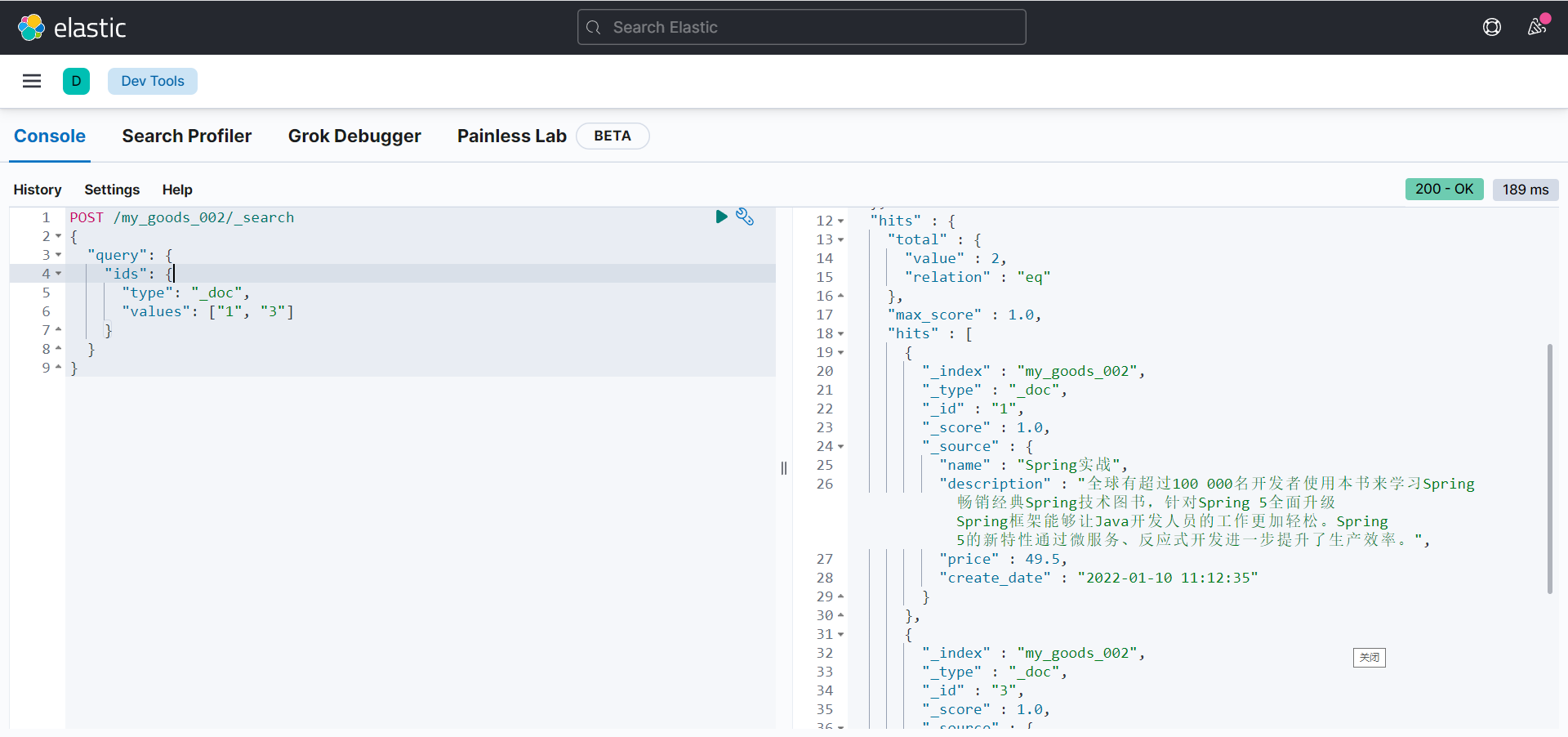
ids
POST /my_goods_002/_search
{
"query": {
"ids": {
"type": "_doc",
"values": ["1", "3"]
}
}
}
复合搜索
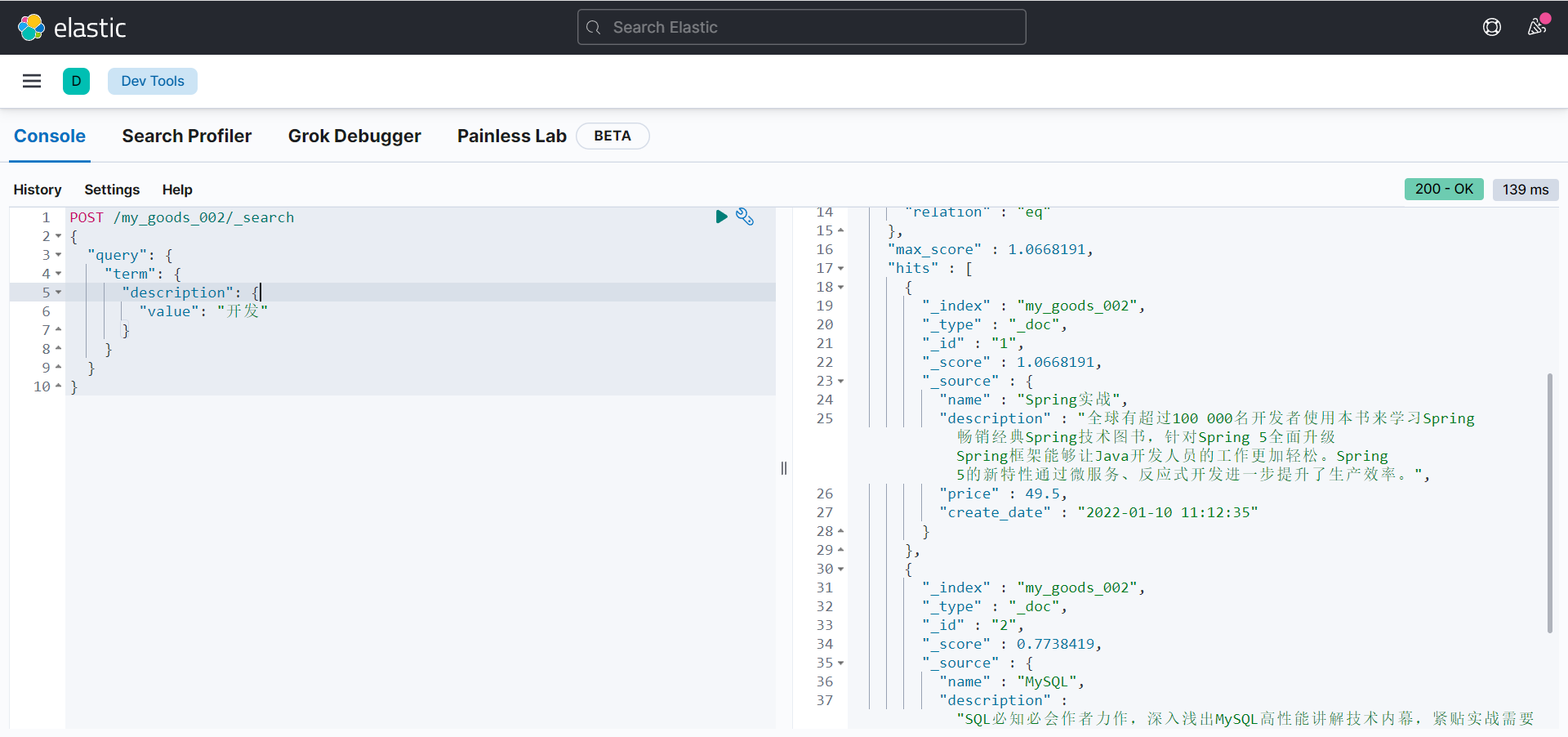
constant_score query
用来包装另一个查询,将查询匹配的文档的评分设为一个常值,词条查询时得到文档的分数不一样:
POST /my_goods_002/_search
{
"query": {
"term": {
"description": {
"value": "开发"
}
}
}
}
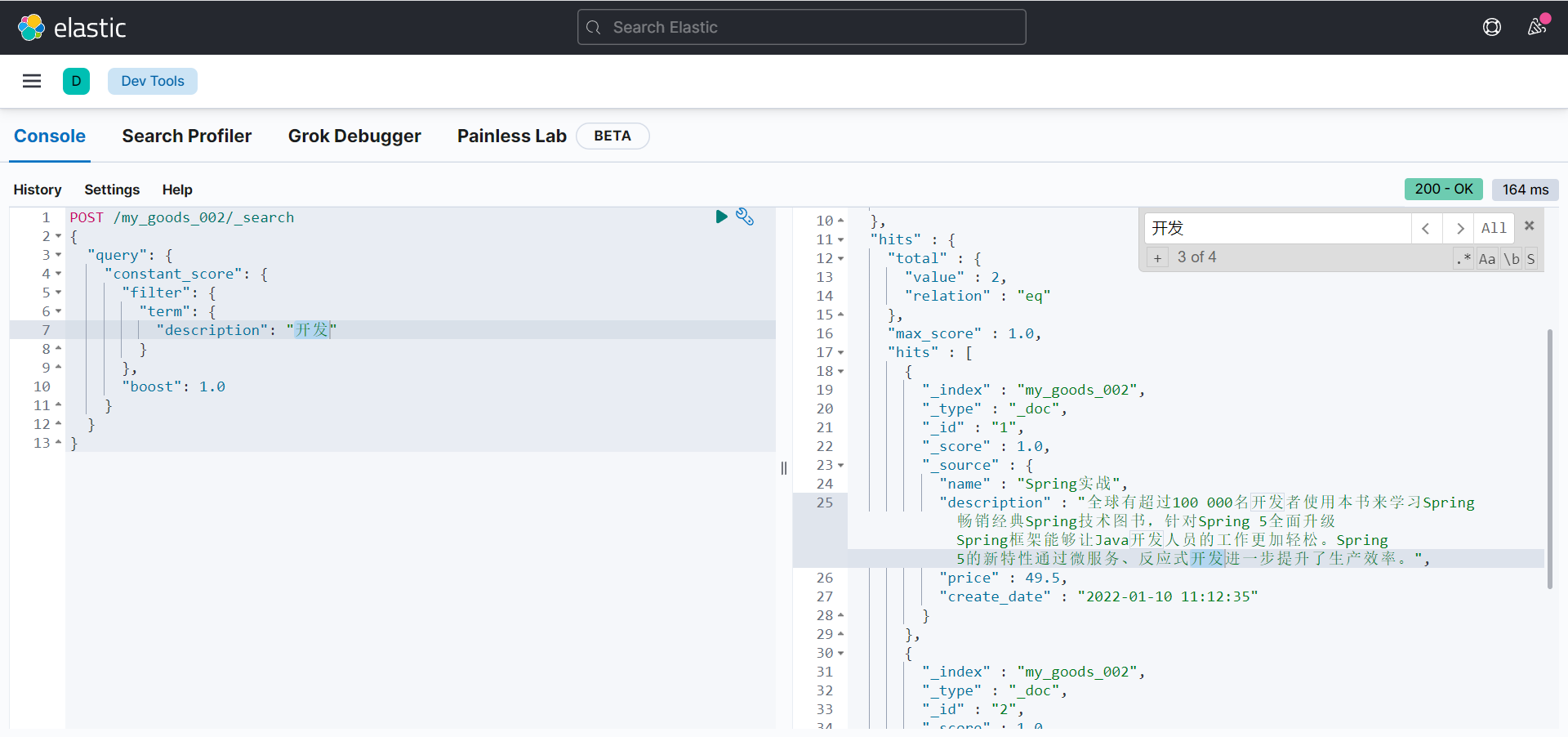
使用 constant_score query 将查询匹配的文档的评分设为一个常值:
POST /my_goods_002/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"description": "开发"
}
},
"boost": 1.0
}
}
}
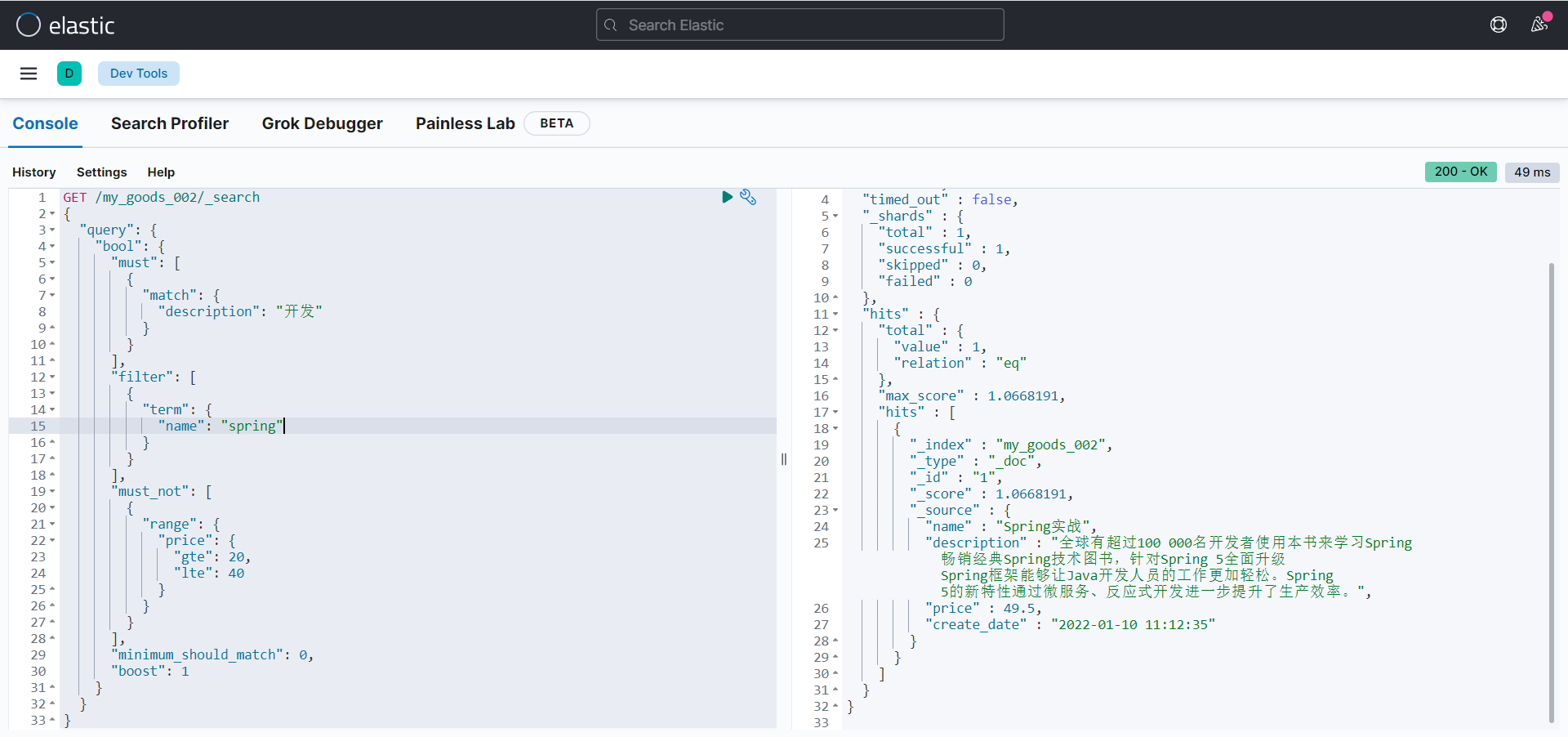
bool query
组合多个关键字查询子句进行 bool 类型过滤,可有关键字:
- must:必须满足
- filter:必须满足, 执行的是
filter上下文, 不影响评分 - should:或者关系
- must_not:必须不满足
- minimum_should_match:最小匹配精度,必须指定
should, 0 可以不出现 should,1 必须出现 should
GET /my_goods_002/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"description": "开发"
}
}
],
"filter": [
{
"term": {
"name": "spring"
}
}
],
"must_not": [
{
"range": {
"price": {
"gte": 20,
"lte": 40
}
}
}
],
"minimum_should_match": 0,
"boost": 1
}
}
}
GET /my_goods_002/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"description": "开发"
}
}
],
"filter": [
{
"term": {
"name": "spring"
}
}
],
"must_not": [
{
"range": {
"price": {
"gte": 20,
"lte": 40
}
}
}
],
"minimum_should_match": 1,
"boost": 1
}
}
}
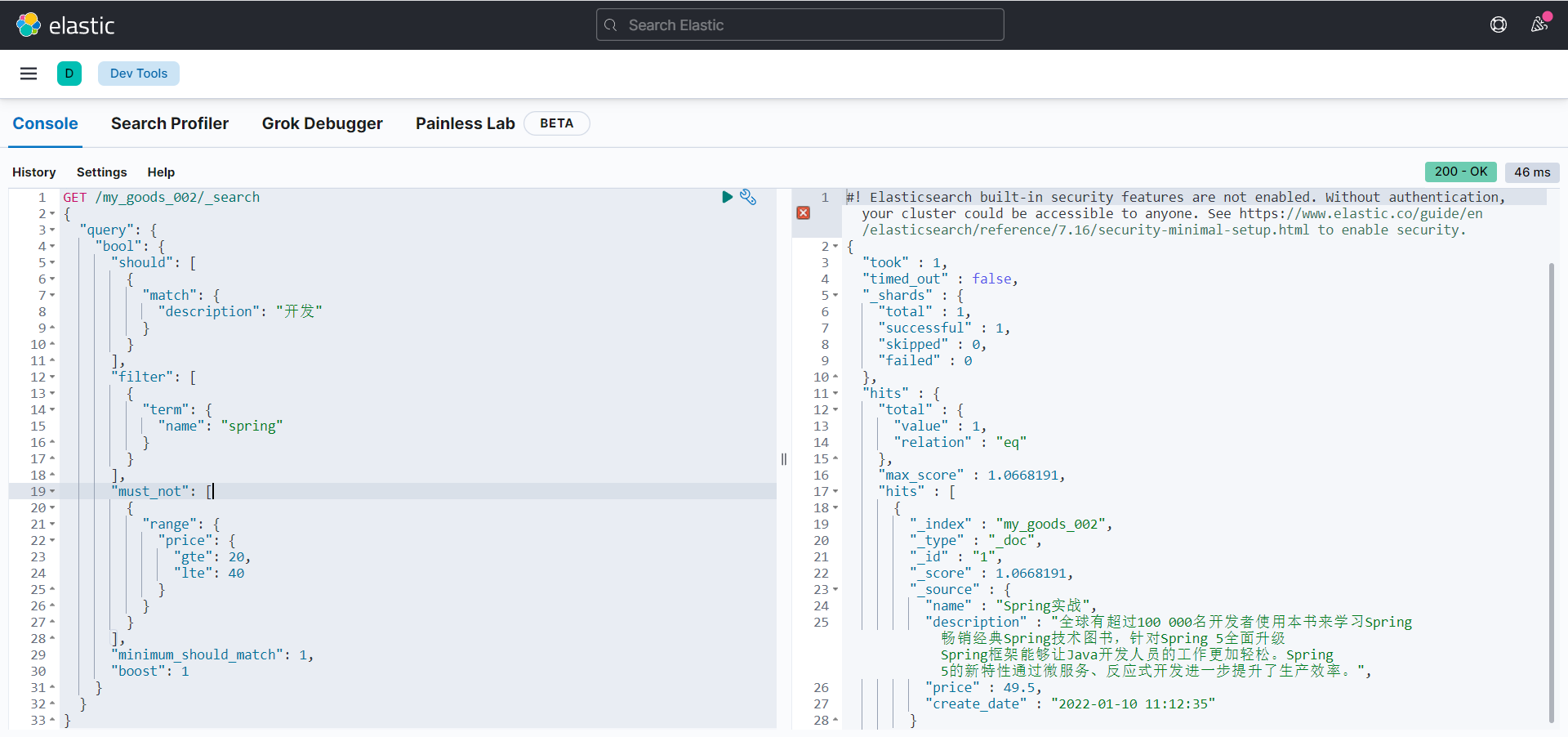
排序
相关性评分排序
默认是按照相关性评分进行排序,最相关的文档排在最前:
GET /my_goods_002/_search
{
"query": {
"match": {
"description": "开发"
}
},
"sort": [
{
"_score": {
"order": "asc"
}
}
]
}
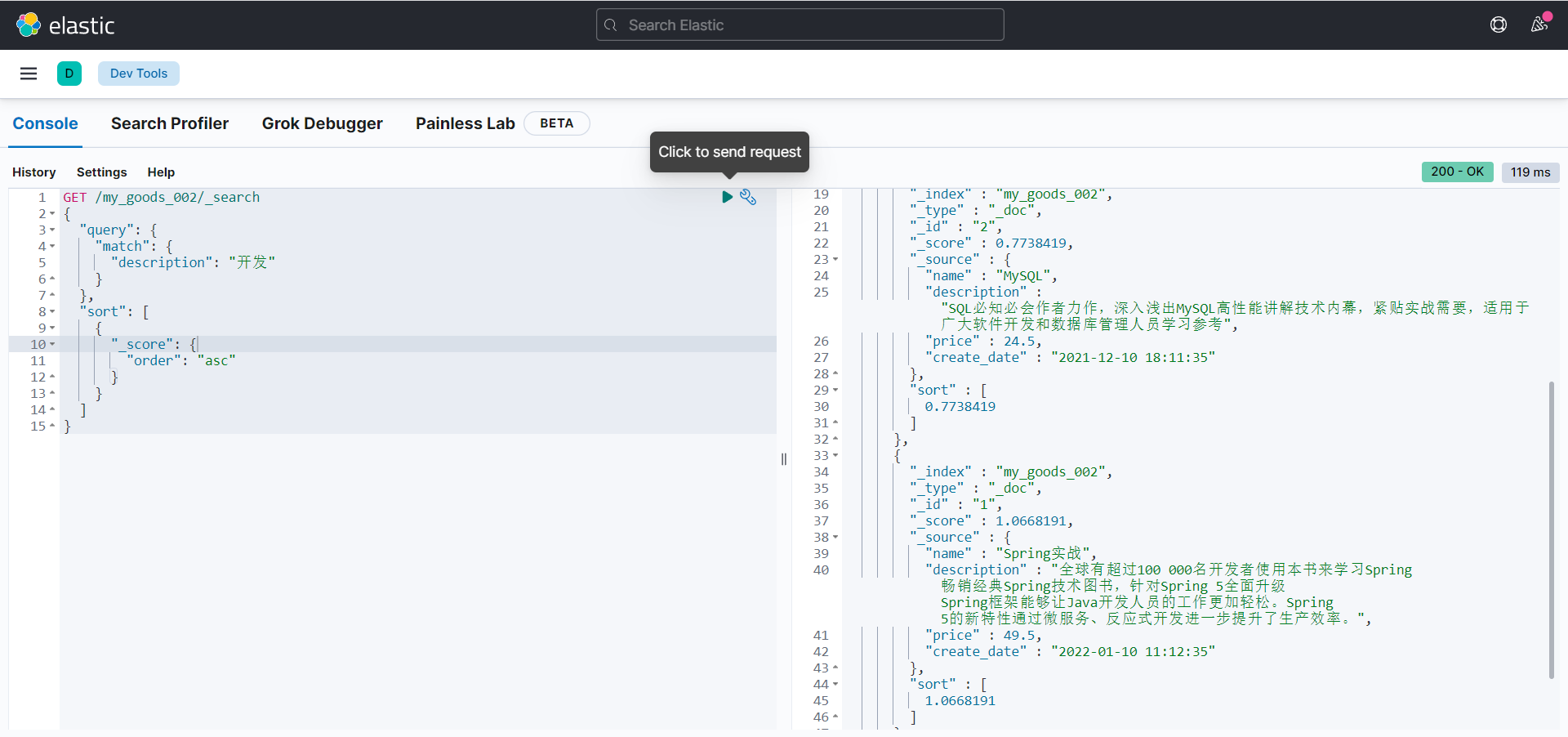
字段值排序
GET /my_goods_002/_search
{
"query": {
"match": {
"description": "开发"
}
},
"sort": [
{
"price": {
"order": "asc"
}
}
]
}
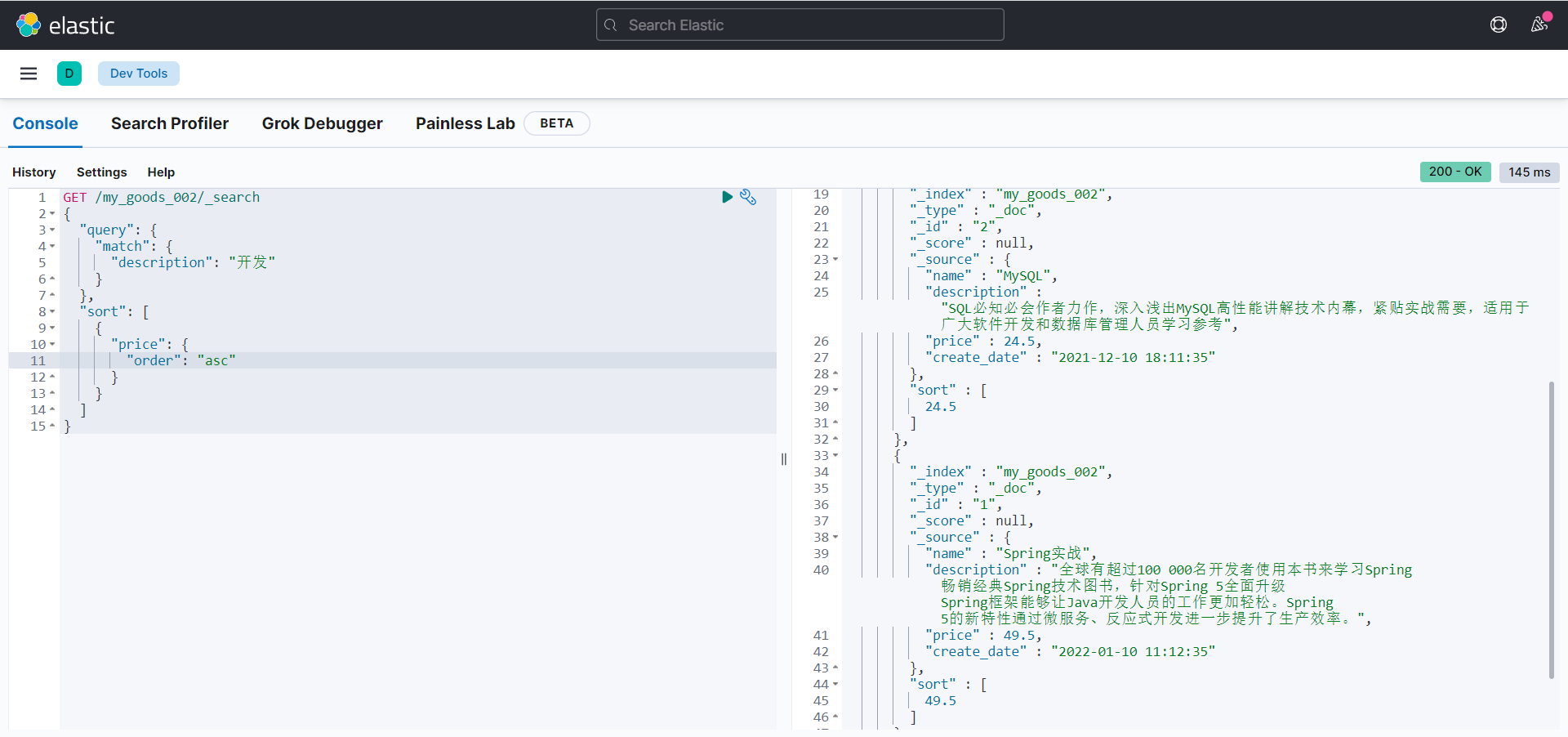
多级排序
GET /my_goods_002/_search
{
"query": {
"match": {
"description": "开发"
}
},
"sort": [
{
"price": {
"order": "asc"
},
"_score": {
"order": "asc"
}
}
]
}
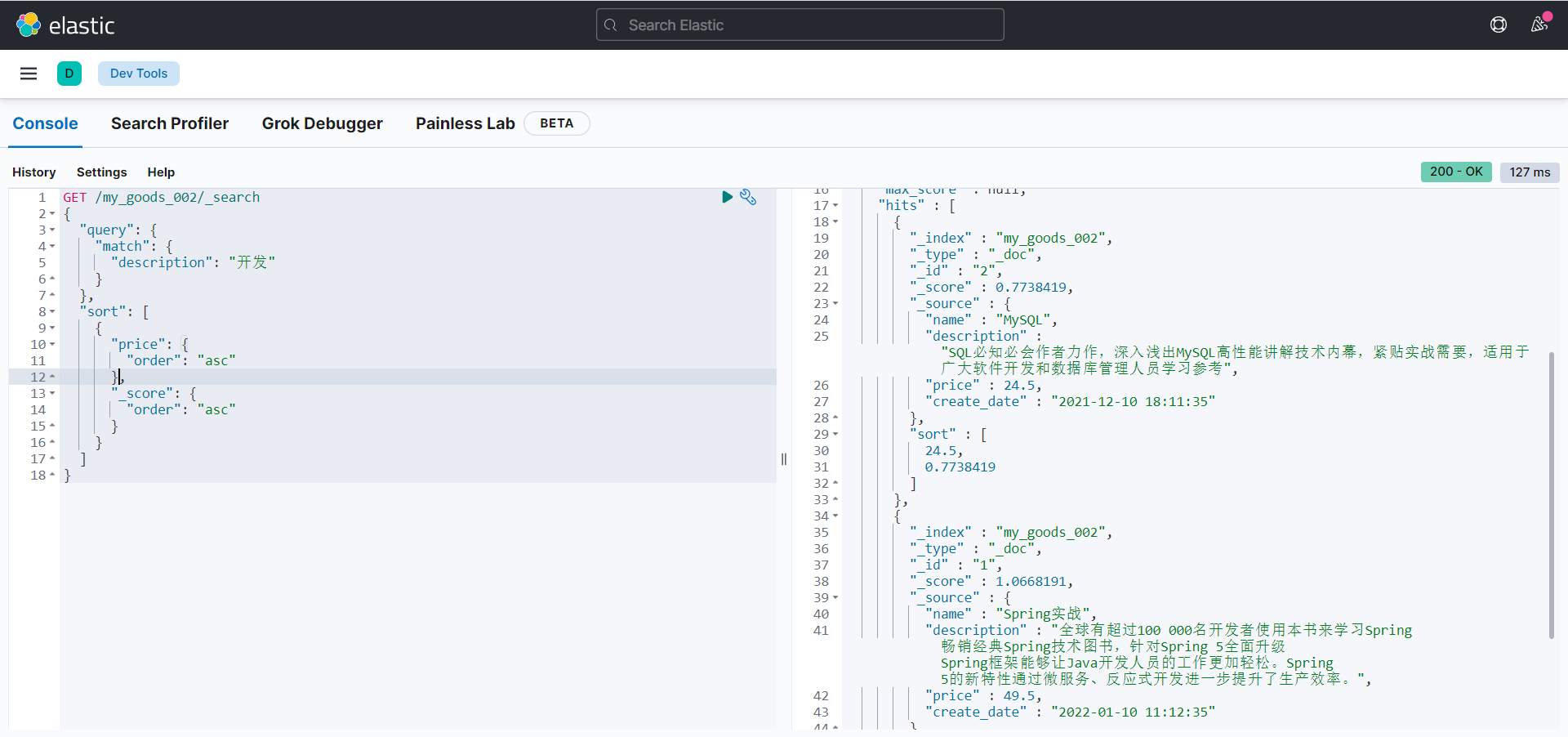
分页
GET /my_goods_002/_search
{
"query": {
"match": {
"description": "开发"
}
},
"sort": [
{
"price": {
"order": "asc"
},
"_score": {
"order": "asc"
}
}
],
"from": 0,
"size": 1
}

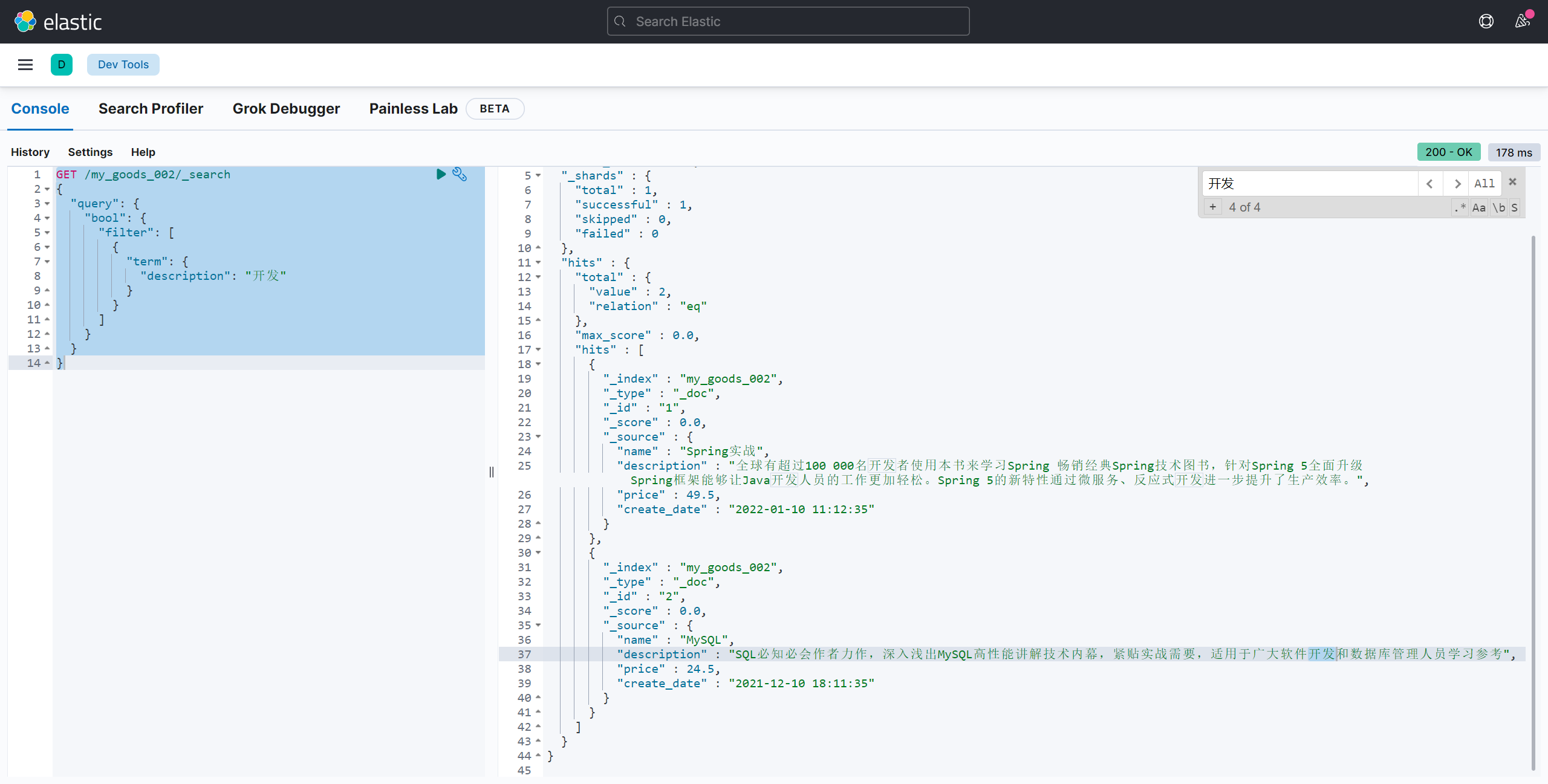
高亮
highlight 属性:
- pre_tags:前置标签
- post_tags:后置标签
- fields:需要高亮的字段
GET /my_goods_002/_search
{
"query": {
"match": {
"description": "开发"
}
},
"sort": [
{
"price": {
"order": "asc"
},
"_score": {
"order": "asc"
}
}
],
"from": 0,
"size": 1,
"highlight": {
"pre_tags": "<font color='red'>",
"post_tags": "</font>",
"fields": [
{
"description": {}
}
]
}
}
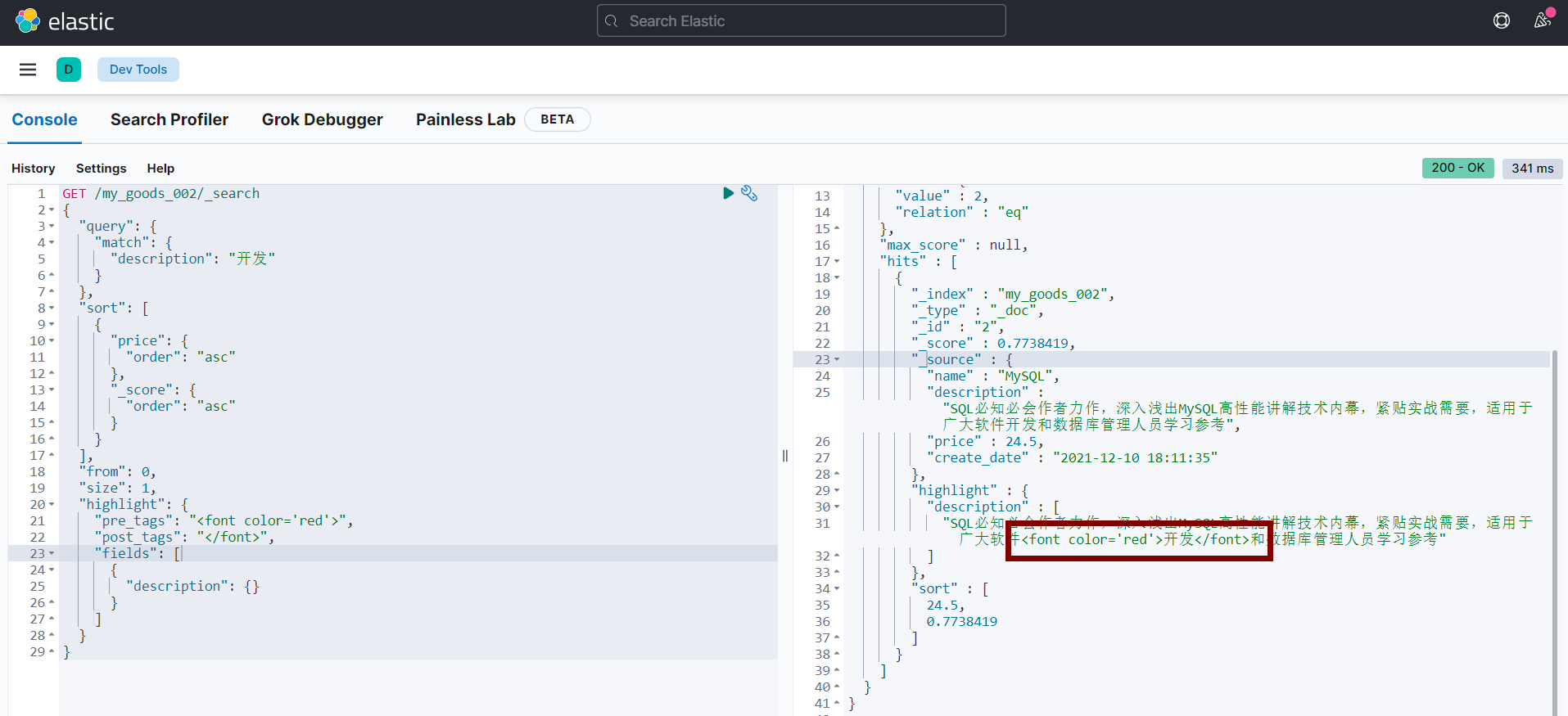
Filter DSL
- ElasticSearch 中的所有的查询都会触发相关度
得分的计算。 - 对于那些我们不需要相关度得分的场景下,Elasticsearch 以过滤器的形式提供了另一种查询功能。
- 执行速度快, 过滤器不会计算相关度的得分,所以它们在计算上更快一些, 也不会对结果进行排序, 过滤器可以被缓存到内存中,这使得在重复的搜索查询上,其要比相应的查询快出许多。
GET /my_goods_002/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"description": "开发"
}
}
]
}
}
}
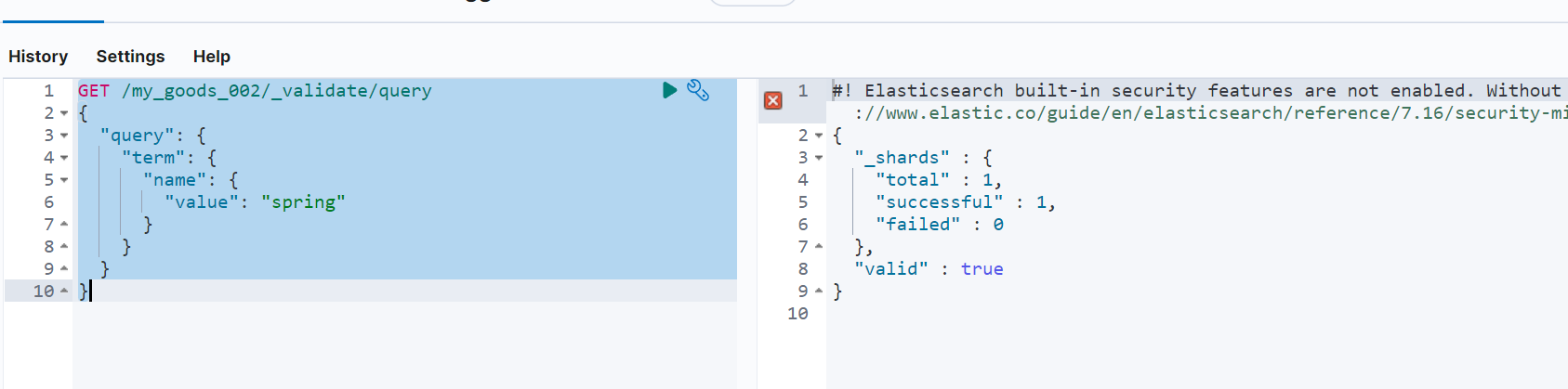
验证语法与分析
- _validate:对请求的查询语法进行验证
正确示例:
GET /my_goods_002/_validate/query
{
"query": {
"term": {
"name": {
"value": "spring"
}
}
}
}
错误示例:
GET /my_goods_002/_validate/query
{
"query": {
"term1": {
"name": {
"value": "spring"
}
}
}
}

- explain,explain 是一个参数,作用可用于对验证的结果进行分析
GET /my_goods_002/_validate/query?explain
{
"query": {
"term1": {
"name": {
"value": "spring"
}
}
}
}

批量操作
批量查询
查询指定 id 的数据信息:
GET /my_goods_002/_mget
{
"docs": [
{
"_id": 1
},
{
"_id": 4
}
]
}
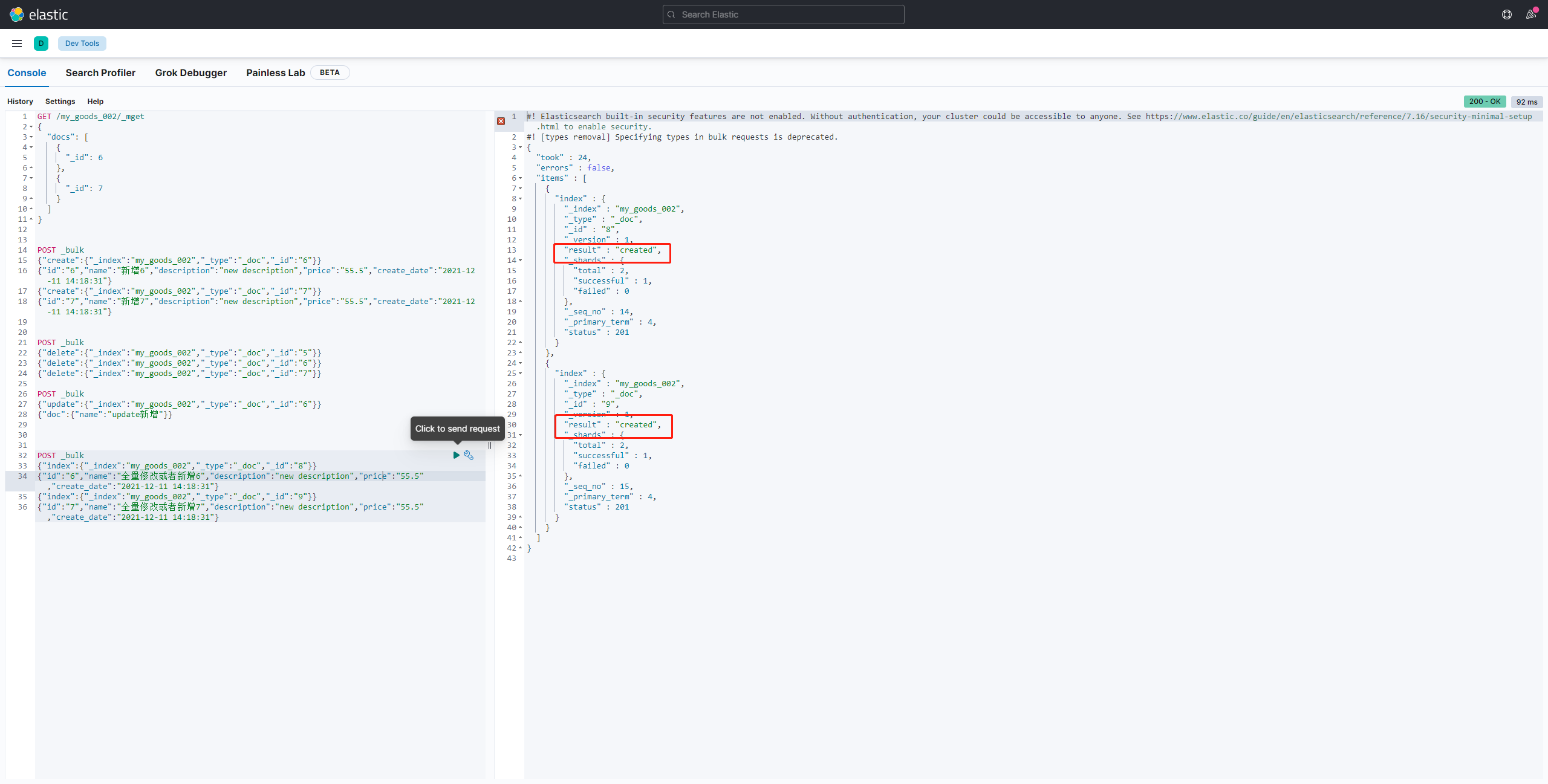
批量创建文档 create
如下代码的含义为,创建两条数据,create 与 id 这两行才代表是一条数据:
POST _bulk
{"create":{"_index":"my_goods_002","_type":"_doc","_id":"6"}}
{"id":"6","name":"新增6","description":"new description","price":"55.5","create_date":"2021-12-11 14:18:31"}
{"create":{"_index":"my_goods_002","_type":"_doc","_id":"7"}}
{"id":"7","name":"新增7","description":"new description","price":"55.5","create_date":"2021-12-11 14:18:31"}
批量删除
可以先创建测试数据,然后在执行如下删除:
POST _bulk
{"delete":{"_index":"my_goods_002","_type":"_doc","_id":"5"}}
{"delete":{"_index":"my_goods_002","_type":"_doc","_id":"6"}}
{"delete":{"_index":"my_goods_002","_type":"_doc","_id":"7"}}
批量修改
修改完毕之后你可以在查询一下你修改的数据是否成功即可:
POST _bulk
{"update":{"_index":"my_goods_002","_type":"_doc","_id":"6"}}
{"doc":{"name":"update新增"}}
普通创建或全量替换 index
如果对应的数据存在就是修改操作,如果不存在相应的数据就是创建操作:
存在的情况:
POST _bulk
{"index":{"_index":"my_goods_002","_type":"_doc","_id":"6"}}
{"id":"6","name":"全量修改或者新增6","description":"new description","price":"55.5","create_date":"2021-12-11 14:18:31"}
{"index":{"_index":"my_goods_002","_type":"_doc","_id":"7"}}
{"id":"7","name":"全量修改或者新增7","description":"new description","price":"55.5","create_date":"2021-12-11 14:18:31"}
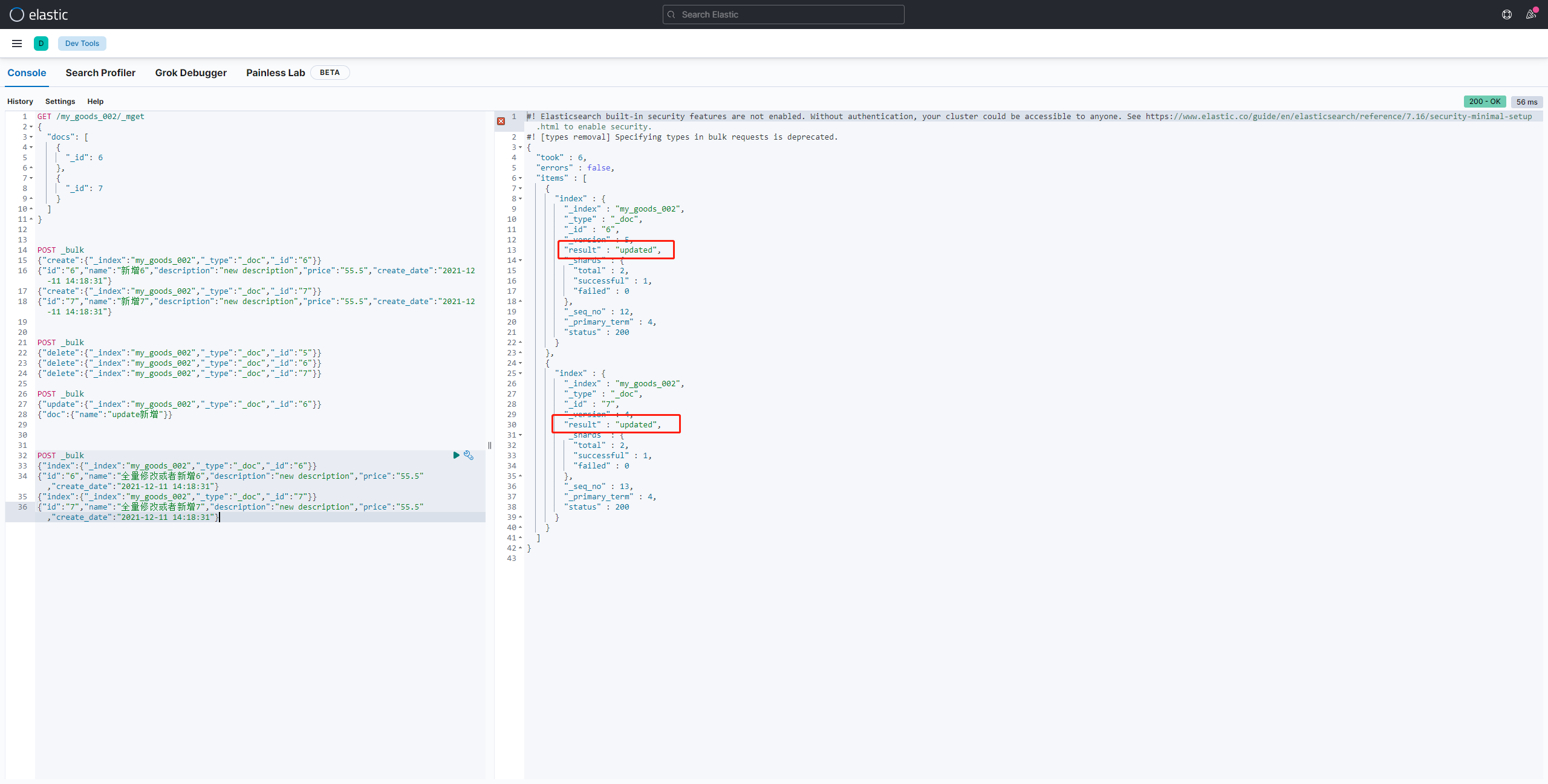
不存在的情况:
聚合分析
完成对一个查询的数据集中数据的聚合计算。
指标聚合 metric
对一个数据集求最大、最小、和、平均值等指标的聚合。
关键字
- max
- min
- sum
- avg
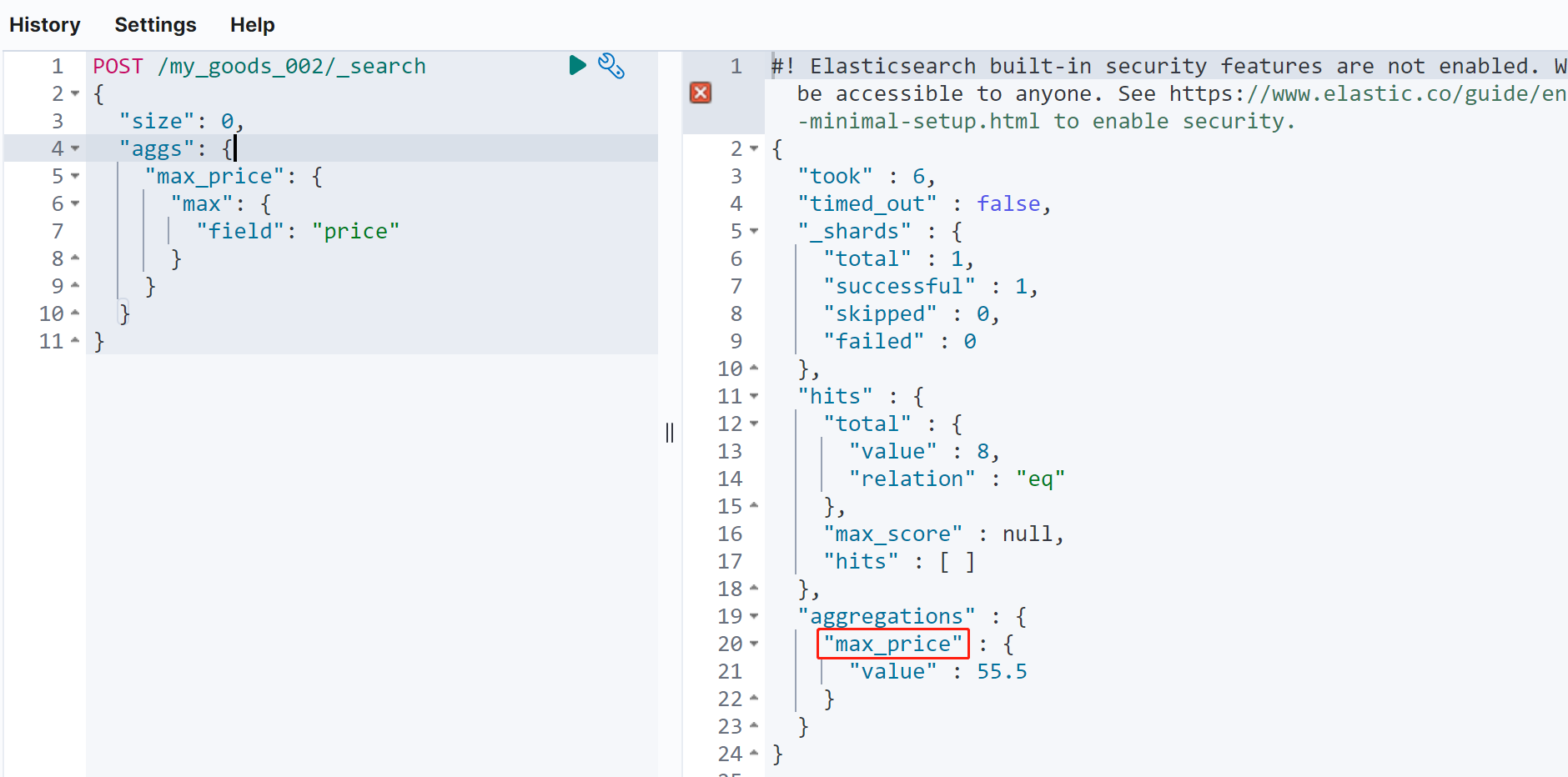
POST /my_goods_002/_search
{
"size": 0,
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
}
}
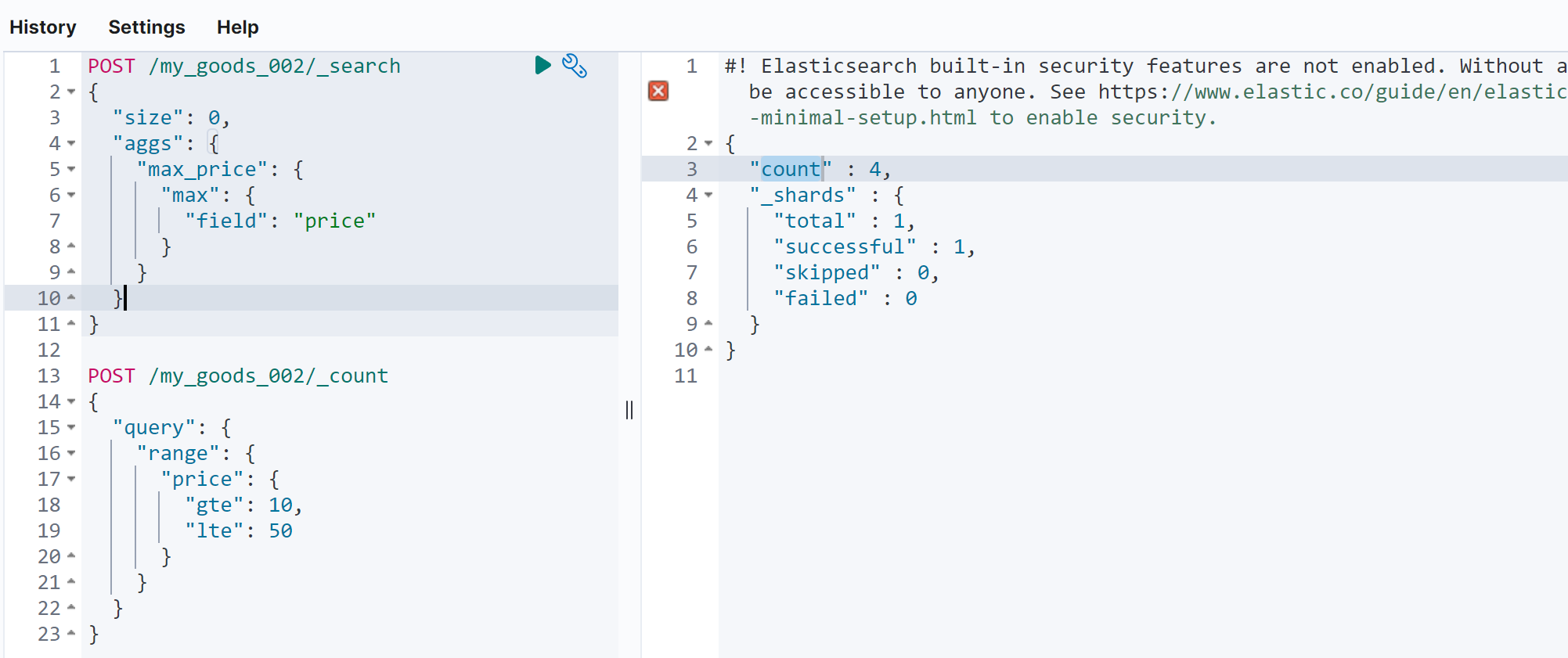
文档统计 count
POST /my_goods_002/_count
{
"query": {
"range": {
"price": {
"gte": 10,
"lte": 50
}
}
}
}
value_count
统计某字段有值的文档数, 就是说一个索引库当中某个文档里面字段不为空的数据的统计:
POST /my_goods_002/_search
{
"size": 10,
"aggs": {
"price_count": {
"value_count": {
"field": "create_date"
}
}
}
}
cardinality
值去重计数,如下代码的含义为,去 _id 进行去重然后进行总结去重之后的总量值:
POST /my_goods_002/_search
{
"aggs": {
"_id_count": {
"cardinality": {
"field": "_id"
}
}
}
}
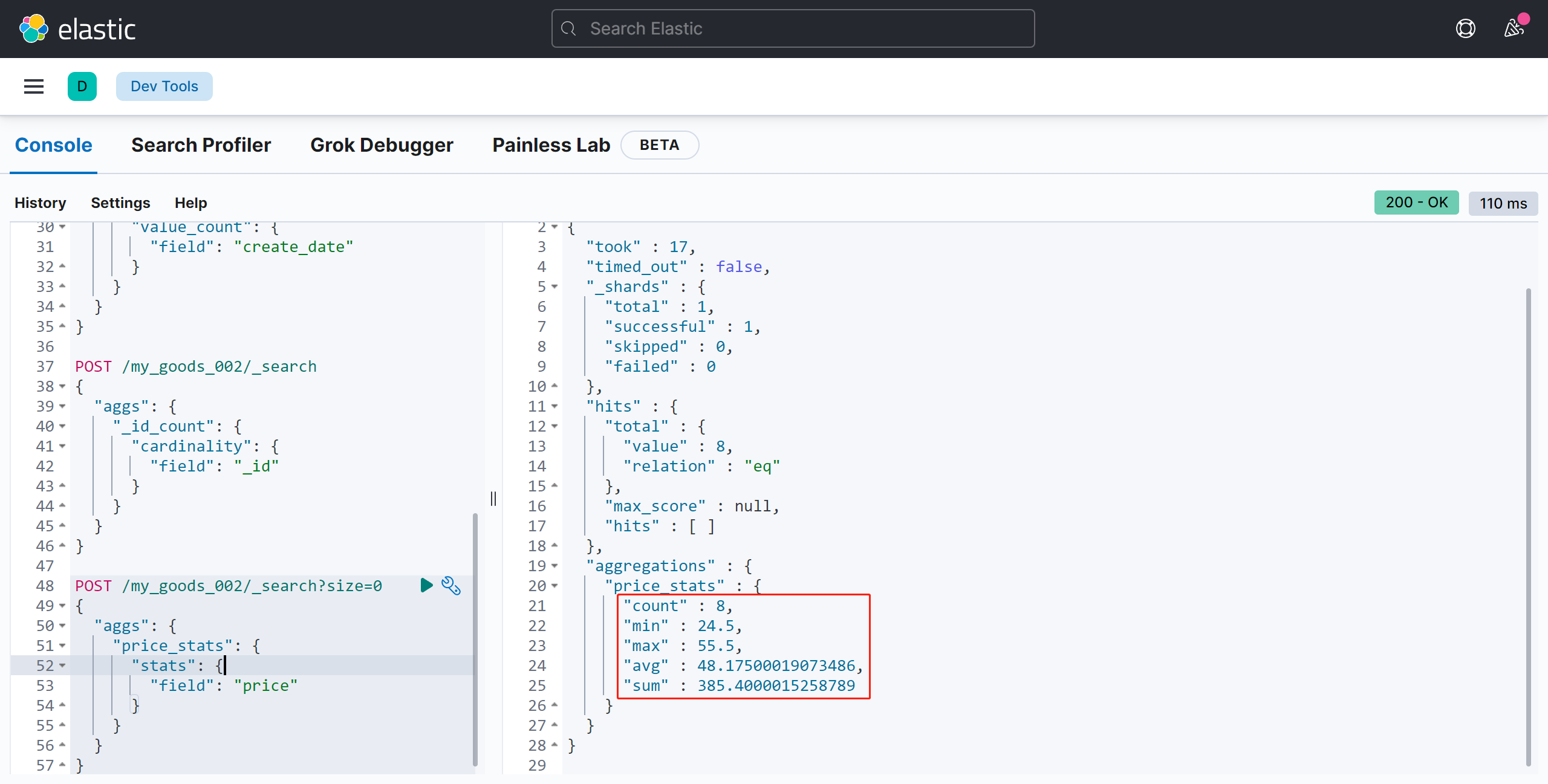
stats
统计 count、max、min、avg、sum、5个值的结果:
POST /my_goods_002/_search?size=0
{
"aggs": {
"price_stats": {
"stats": {
"field": "price"
}
}
}
}
桶聚合 bucketing
也就是再次对查询出的数据进行分组 group by,再在组上进行指标聚合。

如上的这一个示例的含义为,首先是对价格字段进行一次分组操作,不同价格范围的会被分配到不同组当中,然后下面的聚合操作就是对每组当中的内容进行求和操作。
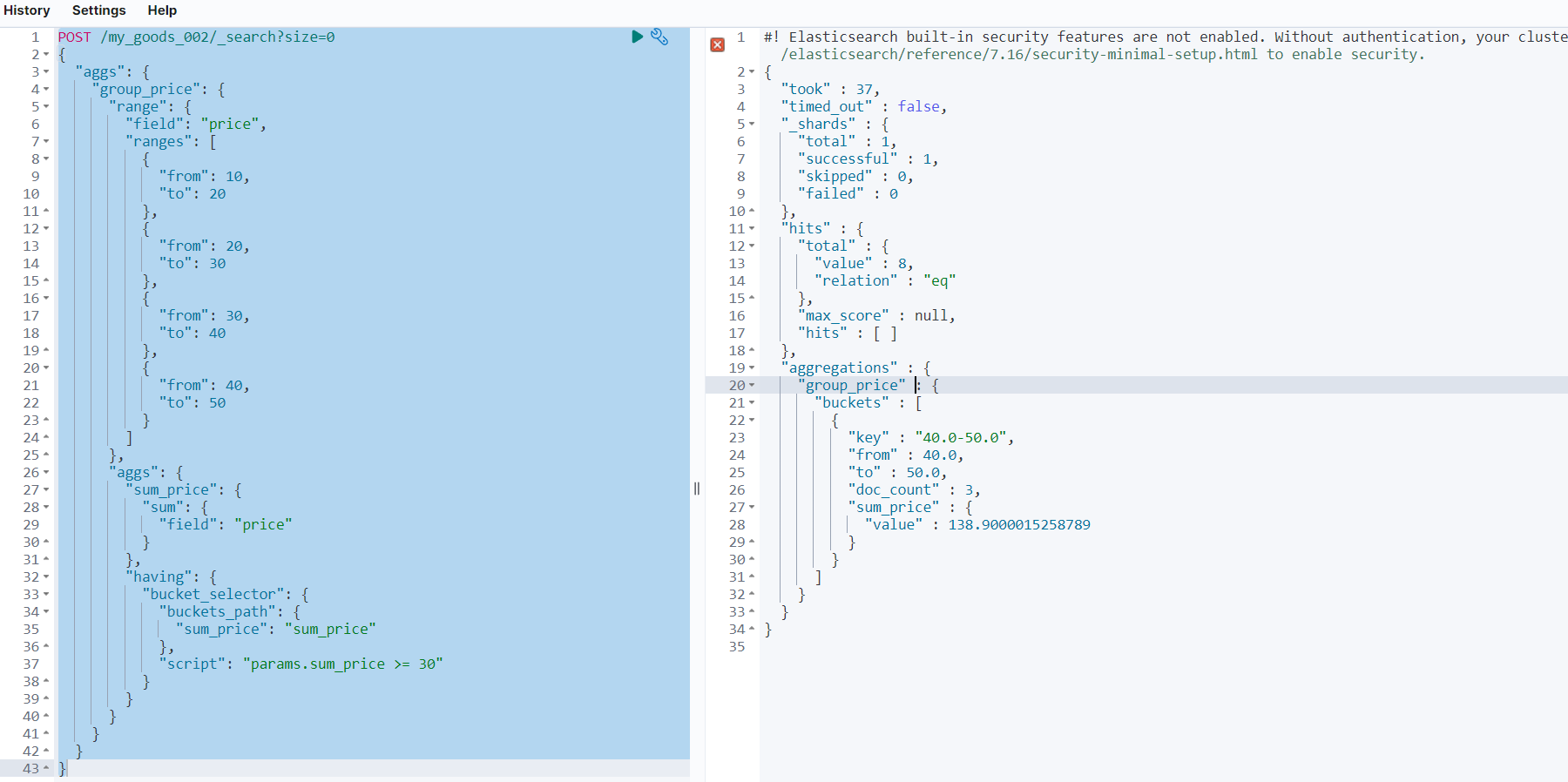
POST /my_goods_002/_search?size=0
{
"aggs": {
"group_price": {
"range": {
"field": "price",
"ranges": [
{
"from": 10,
"to": 20
},
{
"from": 20,
"to": 30
},
{
"from": 30,
"to": 40
},
{
"from": 40,
"to": 50
}
]
},
"aggs": {
"sum_price": {
"sum": {
"field": "price"
}
},
"having": {
"bucket_selector": {
"buckets_path": {
"sum_price": "sum_price"
},
"script": "params.sum_price >= 30"
}
}
}
}
}
}
看了第一个示例在来看这个示例的时候是否发现在聚合当中博主又多添加了一点内容呢,对的,就是 having 那一串,having 是自定义的博主为了让你们更加的容易理解就刻意去定义为 having 的,其实叫啥都可以,然后 bucket_selector 当中的 buckets_path 当中的内容就是 aggs 后面的 sum_price 属性名即可,script 当中编写的内容就是说去获取 buckets_path 当中的内容,博主获取的就是 buckets_path 当中的 sum_price 每组当中的值,然后筛选值大于等于 30 的数据出来: