Spark有多种运行模式,可以运行在一台机器上,称为本地(单机)模式——local模式;可以使用Spark自带的资源调度系统,称为Spark Standalone模式;也可以以YARN或Mesos作为底层资源调度系统以分布式的方式在集群中运行,称为Spark On YARN模式。本文就介绍前两种运行模式。
一:本地模式(local模式)
本地模式通过多线程模拟分布式计算,通常用于对应用程序的简单测试。本地模式在提交应用程序后,将会在本地生成一个名为SparkSubmit的进程,该进程既负责程序的提交,又负责任务的分配、执行和监控等。
二:Spark Standalone模式
Spark Standalone模式为经典的Master/Slave架构,资源调度是Spark自己实现的。在Standalone模式中,根据应用程序提交的方式不同,Driver(主控进程)在集群中的位置也有所不同。应用程序的提交方式主要有两种:client和cluster,默认是client。可以在向Spark集群提交应用程序时使用--deploy-mode参数指定提交方式。
(1)client提交方式

集群的主节点称为Master节点,从节点称为Worker节点。Driver为主控进程,负责执行应用程序的main方法,创建SparkContext对象(负责与Spark集群进行交互)。
(2)cluster提交方式
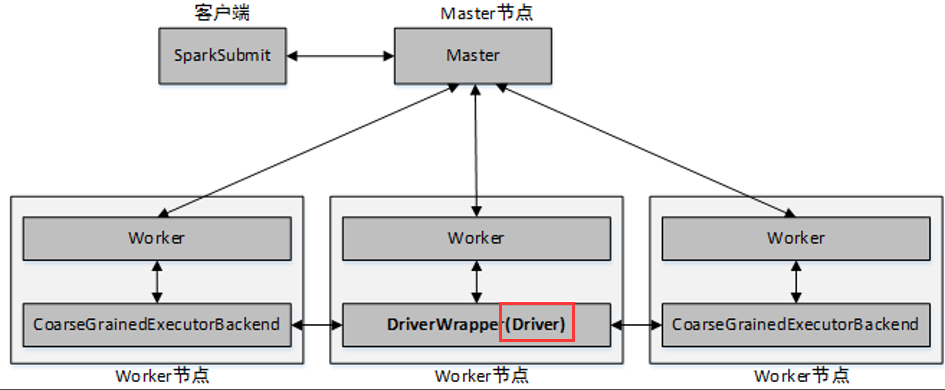
当应用程序运行时,Master会在集群中选择一个Worker进程启动一个名为DriverWrapper的子进程,该子进程即为Driver进程。
三:Spark Standalone模式的配置与提交
(1)先配置Workder节点名称:
$SPARK_HOME/conf/slaves (注:slaves文件是slaves.template的拷贝)
# A Spark Worker will be started on each of the machines listed below.
hadoop000
假设有5台机器,就应该进行如下配置(以下每个名称代表某台机器的主机名)
hadoop000
hadoop001
hadoop002
hadoop003
hadoop004
(2)再启动spark集群:
$SPARK_HOME/sbin/start-all.sh
ps:如果启动失败,可尝试在spark-env.sh中添加JAVA_HOME。spark-env.sh是spark-env.sh.template拷贝而来。
检测:jps命令,如果出现Master和Worker进程,则说明standalone模式安装成功。
(3)启动pyspark进程通过查看Web UI(默认端口为8080,例如http://192.168.158.20:8080/)中的Running Applications可以查看启动的pyspark进程
pyspark进程启动方式:
$SPARK_HOME/bin/pyspark --master spark://hadoop000:7077
(4)Spark Standalone模式提交:
./spark-submit --master spark://hadoop000:7077 --name spark-standalone /home/hadoop/scripts/spark0402.py hdfs://hadoop000:8020/hello.txt hdfs://hadoop000:8020/wc/output