jieba分词
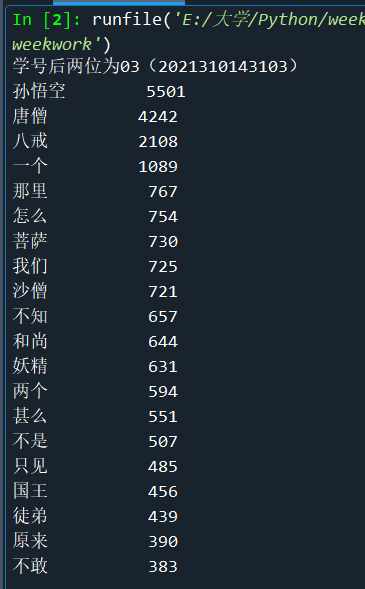
尾号为1,2,3的同学做,西游记相关的分词,出现次数最高的20个。
代码如下:
print("学号后两位为03(2021310143103)") import jieba txt = open("E:\\大学\\Python\\西游记.txt","r",encoding='gb18030').read() words = jieba.lcut(txt) counts = {} for word in words: if len(word) == 1: #排除单个字符的分词结果 continue elif word == "行者" or word == "大圣" or word =="老孙": rword = "孙悟空" elif word == "师父" or word == "三藏" or word == "长老": rword = "唐僧" elif word == "呆子": rword = "八戒" else: rword = word counts[rword] = counts.get(rword,0) + 1 items = list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) for i in range(20): word,count = items[i] print("{0:<10}{1:>5}".format(word,count))
运行结果如下: