归并排序和快排都是时间复杂度为n*logn的排序算法,都较好的的利用了分治思想,因此放在一起描述。
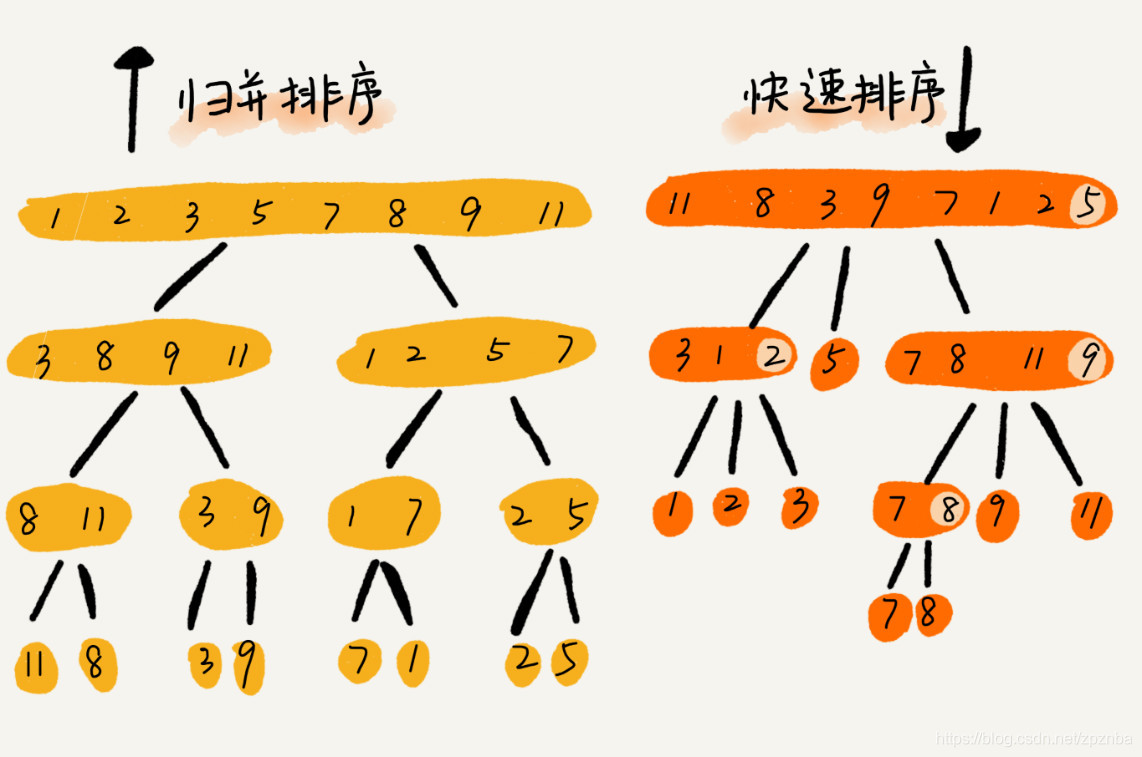
上图是我比较喜欢的一副展示归并和快排的示意图,我们可以通过递归来实现上述两个排序算法。
先来说归并排序:
归并排序的本质就是将要排序的数组一层一层的拆分为直到长度为1的单元素数组然后进行逐层归并。
通过递归的方法来实现这个思路我们就需要拿到一个递归方程,终止条件我们可以随后再考虑,那么递归方程就是:
MergeSort(array, left, right) = Merge(MergeSort(array, left, (left+right)/2), MergeSort(array, (left+right)/2+1, right))
即给定一个array后要将其从m到n的位置进行排序,那么我们只需要将其 "left到(left+right)/2"以及"(left+right)/2+1到right" 两个子数组分别排序,然后通过一个Merge函数组合起来即可。
我们约定left<=right,那么(left+right)/2 - 1可能大于left可能导致递归栈溢出,因此需要使用(left+right)/2作为拆分点。
然后递归的终止条件就是"left==right",此时递归函数MergeSort()只处理单个元素,无需比较直接返回。
Merge函数的实现要用到归并的技巧,这里看代码和注释即可:
func MergeSort(array []int, left int, right int) []int {
if left == right {
return []int{array[left]}
}
return Merge(MergeSort(array, left, (left+right)/2), MergeSort(array, (left+right)/2+1, right))
}
func Merge(array1 []int, array2 []int) []int {
m, n := len(array1), len(array2)
i1, i2 := 0, 0
result := make([]int, 0, m+n)
for i1 < m && i2 < n {
if array1[i1] < array2[i2] {
result = append(result, array1[i1])
i1++
} else {
result = append(result, array2[i2])
i2++
}
}
if i1 == m {
result = append(result, array2[i2:]...)
return result
}
if i2 == n {
result = append(result, array1[i1:]...)
return result
}
return nil
}
// Merge两个已排序好的数组的基本思想是:
// 分别为两个数组定义两个下标索引,初始皆为0,然后开启while循环并使用下标取值
// 我们把两个数组暂且称作左数组和右数组:
// 1.当发现从左边取得的元素更小时,我们把从左数组取得的值放入结果数组中,并把左数组下标右移一位
// 2.否则,我们把从右数组取得的值放入结果数组中,并把右数组下标右移一位
// 3.当任一数组下标触达数组长度时,我们把另一个数组剩下的部分直接追加到结果中即可
// 这样就实现了以O(m+n)时间复杂度对两个有序数组的合并
// 在树的每一层我们总的时间复杂度都是n(n表示原数组的长度),而树的高为logn,因此总的时间复杂度为n*logn
再来看快速排序:
快排的思想和归并排序有些相似,但是实现逻辑是对逻辑树自上而下的处理,而归并排序是自下而上的处理。
快排的原理可以解释为:
1.我们先取出一个参照值(一般是数组的最后一个值,也可以是第一个、中间值or其他固定下标的值),将其称作支点(pivot)
2.然后遍历数组统计,设置一个自增计数 k 来记录比pivot小的元素个数
3.在上述遍历的过程中每当发现比pivot小的元素 v 时,就swap(array[k], v),最后再swap(array[k], pivot),这样整个数组就被分为3部分:
array[k]及其左右两个子数组,其中左数组都是<array[k]的,右数组都是>=array[k]的。
4.然后我们递归的对左右两个子数组采用同样的方式进行拆分,最终当拆分出的子数组大小为1时即可终止
所以递归方程可以近似为:
QuickSort(array) = Partition(array) && QuickSort(array[:k]) && QuickSort(array[k+1:])
快排是通过操作原数组实现排序的,空间复杂度为O(logn),即每一层只需要常数个额外变量记录支点即可,因此其代码实现可以写为:
func QuickSort(array []int) []int {
n := len(array)
if n == 1 {
return array
}
// partition array
pivot := array[n-1]
k := 0
for i, v := range array[:n-1] {
if v < pivot {
array[i], array[k] = array[k], v
k++
}
}
// swap array[k] and pivot
array[n-1], array[k] = array[k], pivot
// sort left && right part
if k > 0 {
QuickSort(array[:k])
}
if k < n-1 {
QuickSort(array[k+1:])
}
return array
}
其时间复杂度就比较容易看出来啦,由于快排的分区不像归并那样平均(即非完全二叉树),所以其最差时间复杂度为O(n²),平均时间复杂度为O(n*logn)了。
在实现快排的过程中,我曾经想仅使用计数来定位pivot的位置然后仅swap(pivot, array[k]),然而事实证明这会导致分区后左(右)子数组可能包含比支点大(小)的值,这样对子数组进行递归就没有了意义,因为每次递归只能确保支点在当前操作的数组内位置正确,而不能确保其在原数组中位置正确。
上述代码的6-18行可以独立为一个func Partition(array) int的分区函数,使快排代码看起来简洁,这个分区函数就是快排最核心的部分,用于对数组进行原址重排(亦即分区)。
如何使用迭代而非递归完成快排和归并排序?
很简单,快排和归并的递归本质上都是二叉树的那种深度遍历模式,如果要使用迭代的方式进行那么就直接参考二叉树的层次遍历即可,产生的分区使用一个额外的数组queue记录,每次只处理queue[0]位置的分区,处理完毕后移除此分区,循环直到queue为空。
快排的实际效率?
《算法导论》一书中是这样评价快排的:虽然快排的最差时间复杂度为O(n²),但快排通常是实际排序应用中最好的选择,因为它的平均性能非常好,且为原址排序。
实际上快排和归并排序以及堆排序的实际性能和原数组的规模以及有序程度息息相关,固定规模数组的排序效率应当通过实际压测来判定。
Go语言sort包使用一种名为内省排序(introsort)的算法来进行排序,这是一种快排和堆排序的混合算法,一般场景使用快排而在快排时间复杂度接近O(n²)时切换为堆排序。
快排的随机化版本?
在本文上述实现的快速排序算法中,我们总是选取数组的最后一个元素作为支点,这在输入数组的所有排列都是等概率的场景下性能会比较符合平均期望,但实际工程中很少是这样的,因此我们可以通过引入随机性来使排序性能更接近平均期望,这可以避免最差场景下快排的时间复杂度接近O(n²)。
我们只需要在选取支点时引入一下随机性即可,然后把选中的支点放在末尾,这样其他代码就不变了:
func QuickSort(array []int) []int {
n := len(array)
if n == 1 {
return array
}
// partition array
// 引入随机性
rand.Seed(time.Now().UnixNano())
randomIndex := rand.Intn(n)
pivot := array[randomIndex]
// 将选中的支点后置
array[randomIndex], array[n-1] = array[n-1], pivot
// 其余代码不变
k := 0
for i, v := range array[:n-1] {
if v < pivot {
array[i], array[k] = array[k], v
k++
}
}
// swap array[k] and pivot
array[n-1], array[k] = array[k], pivot
// sort left && right part
if k > 0 {
QuickSort(array[:k])
}
if k < n-1 {
QuickSort(array[k+1:])
}
return array
}