线索二叉树与以往的二叉树略有不同,普通二叉树在访问到叶子结点的时候会返回,往往递归的效率并不高,有时还可能有栈溢出的风险,但是线索二叉树在访问到叶子结点的时候因为没有左右孩子,所以他左边存放他前驱的指针。右边存放后继的指针,是指从一个非线性结构变成了一个可以线性访问的的结构,特别是在中许下直接找到他的前驱和后继,
哈夫曼树和哈夫曼编码,以一个由纯字符的文档为例子。这篇文档中每个英文字母出现的次数一定不一样,高频字符出现的次数多,低频字符出现的次数少,于是我们称每个字符出现的频率为为这个字符的权值。将每个字符的权值作为树的根节点构成一片森林,每次取其中两个权值最小的树将他们的和作为根节点重新生成一个有三个结点的树,并将它再次放入森林,再次进行这样的操作,直到只有一棵树为止,那么这颗树的叶子节点的分别对应每个字母,且权值大的越靠近根节点,之后从根节点开始像叶子节点向根节点追踪,若规定从此节点的左结点经过此节点,则此数加一位零,若是右节点则加一位一,当所有叶子节点都经过此操作时,每位字母都会有对应的编码,且权值越高的子字母编码位数越少,以此可以压缩数据的量。
紧接着昨天的优先级队列的实现,优先级队列与普通的栈和队列都有着适配器的作用,但是他的入队列与出队列又有所不同。因为要保持按优先级出队列,就得对插入的数据进行操作,当他不断插入的过程也是不断建堆的过程,比如若队列为大数优先级那么他其中的结构也就是一个大堆,每当尾插数据的时候,就会对这个数据在堆里进行向上调整,将这个数据放到他应有的位置,若要出数据,如果直接将大数输出,那这个堆就会损坏,若要重新建堆时间复杂度就会是o(n),这将大大减小处理数据的效率,于是我们可以将最后一个数与堆顶的数据互换,然后输出队尾的数据,这样只需要再做一次时间复杂度为0(logn)的向下调整就可以又重新生成一个堆,于是就实现了优先级输出,具体代码:

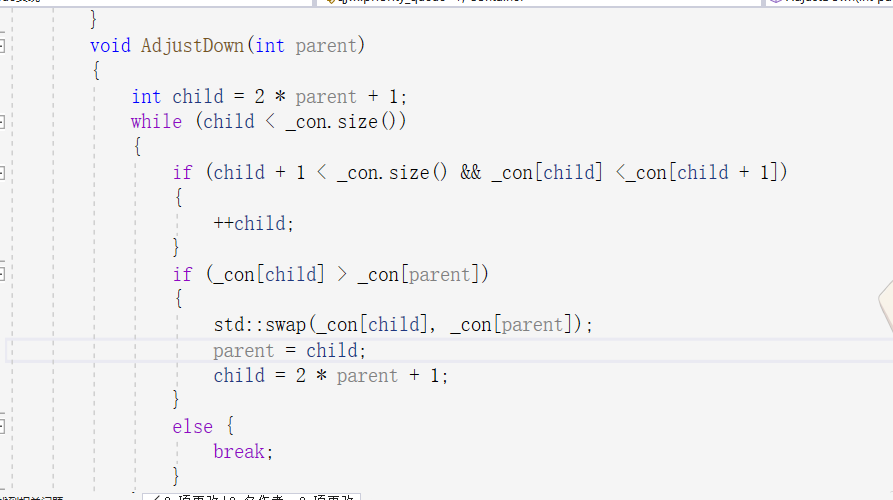
其中再写代码时有一个需要注意的地方,就是当判断左右孩子时,需要判断右孩子是否会越界,不然就崩溃了。