之前用 dbutils 来实现数据库连接池, 这里将其封装为一个自定义类并在 flask 中实际应用一下, 在实际场景中肯定是多页面接口, 这也就涉及到 python 的 import 问题, 就个人感觉它没有像 js 那样方便, 但也能用吧.
目录结构
- app.py
- config
- __ init __.py
- db.py
- goods
- __ init __.py
- views.py
简单说明如下:
app.py 用来作为主程序入口, 实例化 app , 注册蓝图, 和简单配置.
config 是个文件夹, 因其带有 __ init __ .py 文件则变成了一个 package, 可以轻松 import 了.
goods 是一个业务板块, 业务逻辑视图都放在 view.py, 而 __ init __ 的作用则是向外 export 暴露 views 视图里面的东西能更好被 find 而已.
具体实现
app.py
from flask import Flask
import goods
app = Flask(__name__)
# 注册蓝图
app.register_blueprint(goods.blueprint)
# app.register_blueprint(products.blueprint)
@app.route('/')
def index():
return 'hello, youge!'
if __name__ == "__main__":
app.config['debug'] = True
app.config['JSON_AS_ASCII'] = False
# run 一定要在最后, 配置才会生效
app.run(host='127.0.0.1', debug=True)
这里能 import goods, 说明 goods 是一个 package, 然后会从它的 __ init __ .py 中去慢慢寻找成员
蓝图管理 goods.blueprint 这里的 blueprint 是一个自定义名字的蓝图对象实例, 表示这块业务的二级路由规划等.
goods.__ init __.py
from goods.views import *
它的作用是向外 export 其同级目录下的 views.py 视图函数中的各成员, 同时也声明 goods 是个 pakage, 然后也做代理结构拆分, 让人一看就懂.
goods.views.py
from flask import Blueprint, jsonify
from config.db import db
# 用这个 bluprint 管理这下面一连串的业务逻辑路径
blueprint = Blueprint('goods', __name__, url_prefix='/goods')
@blueprint.route("/test/")
def test():
return jsonify([1, 2, 3])
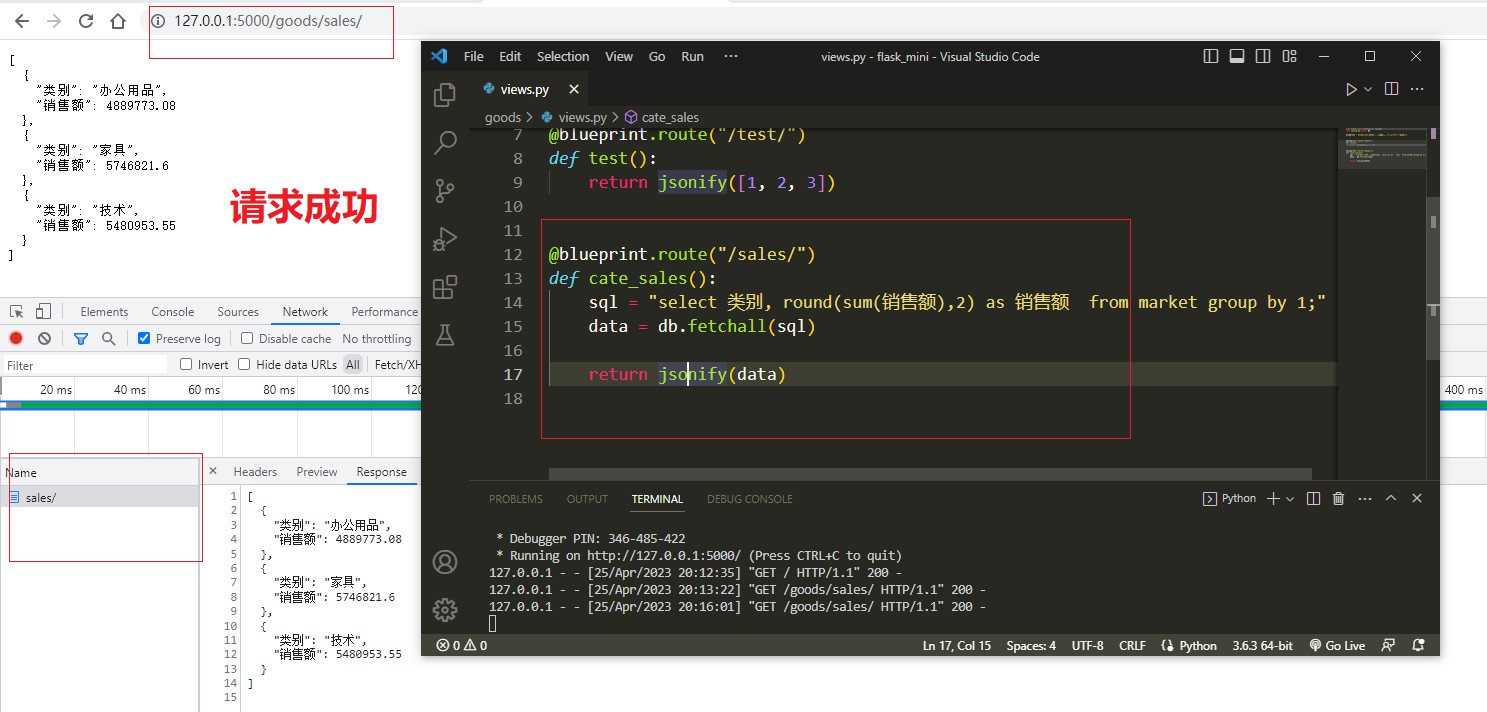
@blueprint.route("/sales/")
def cate_sales():
sql = "select 类别, round(sum(销售额),2) as 销售额 from market group by 1;"
data = db.fetchall(sql)
return jsonify(data)
这里的 blueprint 是一个蓝图实例, 用来管理下面一连串的路由 url 前缀都是 '/goods/xxx' 的方式.
获取数据这里用了原生 sql 并进行了封装, 然后返回一个 json 数据, 因此核心是来看这个 db 对象实例是如何实现的.
config.__ init __.py
# 啥都不写也行
from config.db import *
作用同上, 声明 config 是一个 package, 然后顺带将 下面的 db.py 中的成员都 export 出去, 能被外面的文件进行 import
config.db.py
import pymysql
from pymysql import cursors
from dbutils.pooled_db import PooledDB
# 通过类来创建单例模式封装 DB
class DB(object):
def __init__(self):
self.pool = PooledDB(
creator=pymysql,
# 创建最大连接
maxconnections=6,
mincached=2,
maxcached=3,
maxshared=4,
blocking=True,
maxusage=None,
setsession=[],
ping=0,
# 这一坨会传给上面的 pymysql
host='127.0.0.1',
port=3306,
user='root',
passwd='123456',
database='cj',
charset='utf8',
# 让查询结果是一个 dict
cursorclass=cursors.DictCursor
)
def open(self):
conn = self.pool.connection()
cursor = conn.cursor()
return conn, cursor
def close(slef, cursor, conn):
cursor.close()
conn.close()
def fetchall(self, sql, *args):
conn, cursor = self.open()
cursor.execute(sql, args)
data = cursor.fetchall()
self.close(conn, cursor)
return data
def fetchone(self, sql, *args):
conn, cursor = self.open()
cursor.execute(sql, args)
data = cursor.fetchone()
self.close(conn, cursor)
return data
# 类实例化 DB 对象, 即也是单例创建一个连接池啦
db = DB()
重点在最后这一行, db = DB( ) 即通过类实例化的方式完成了一个单例. 即对于连接池一共只创建了一个, 但在各个地方都能用上.
演示结果
首页:
业务:
还是蛮好理解和使用的, 后面就用它来写接口吧.