当一个计算任务过于复杂不能被一台服务器独立完成的时候,我们就需要分布式计算。分布式计算技术将一个大型任务切分为多个更小的任务,用多台计算机通过网络组装起来后,将每个小任务交给一些服务器来独立完成,最终完成这个复杂的计算任务。本篇我们介绍两个经典的计算框架MapReduce和Spark。

— MapReduce批处理引擎 —
MapReduce是第一个比较成功的计算引擎,主要用于数据批处理。由于企业的大数据业务多是围绕结构化数据等价值密度更高的数据展开,所有的大数据公司开始在大数据平台上打造SQL引擎或分布数据库。2012年开始到随后两年中出现20多个基于Hadoop的SQL引擎,以解决结构化数据问题。MapReduce框架是Hadoop技术的核心,它的出现是计算模式历史上的一个重大事件,在此之前行业内大多是通过MPP(Massive Parallel Programming)的方式来增强系统的计算能力,一般都是通过复杂而昂贵的硬件来加速计算,如高性能计算机和数据库一体机等。而MapReduce则是通过分布式计算,只需要廉价的硬件就可以实现可扩展的、高并行的计算能力。一个MapReduce程序会包含一个Map过程和一个Reduce过程。在Map过程中,输入为(Key, Value)数据对,主要做过滤、转换、排序等数据操作,并将所有Key值相同的Value值组合起来;而在Reduce过程中,解析Map阶段生成的(Key, list(value))数据,并对数据做聚合、关联等操作,生成最后的数据结果。每个worker只处理一个file split,而Map和Reduce过程之间通过硬盘进行数据交换,如果出现任何错误,worker会从上个阶段的磁盘数据开始重新执行相关的任务,保证系统的容错性和鲁棒性。

图片来源于《MapReduce: simplified data processing on large clusters》
MapReduce在设计上并不是为了高性能,而是为了更好的弹性和可扩展性。在同等规模的硬件以及同等量级的数据上,与一些基于关系数据库的MPP数据库相比,MapReduce的分析性能一般会慢一个数量级,不过MapReduce可以支持的集群规模和数据量级要高几个数量级。在2014年Jeff Dean提出MapReduce的论文里提及的相关集群已经是1800台服务器的规模,而现在放眼国内,单个集群超过几千个服务器、处理数据量达到PB级别的集群有超过数百个。
除了可以支持PB级别的弹性化数据计算外,MapReduce还有几个很好的架构特性,这些特性也都被后来的一些计算框架(如Spark等)有效地继承。第一个特性是简化的编程接口设计,与之前的MPP领域流行的MPI等编程接口不同,MapReduce不需要开发者自己处理并行度、数据分布策略等复杂问题,而是需要关注于实现Map和Reduce对应的业务逻辑,从而大大简化开发过程。另外MapReduce的计算基于key-value的数据对,value域可以包含各种类型的数据,如结构化数据或图片、文件类非结构化数据,因此MapReduce计算框架能够很好地支持非结构化数据的处理。
此外,在容错性方面,由于MapReduce的分布式架构设计,在设计之初即设定了硬件故障的常态性,因此其计算模型设计了大量的容错逻辑,如任务心跳、重试、故障检测、重分布、任务黑/灰名单、磁盘故障处理等机制,覆盖了从JobTracker、TaskTracker到Job、Task和Record级别的从大到小各个层级的故障处理,从而保证了计算框架的良好容错能力。
而随着企业数据分析类需求的逐渐深入,MapReduce计算框架的架构问题从2010年后也逐渐暴露出来。首先就是其性能问题,无论是框架启动开销(一般要数分钟),还是任务本身的计算性能都不足,尤其是在处理中小数据量级的数据任务上与数据库相差太大,不能用于交互式数据分析场景。有意思的是,从2010年开始,学术界有大量的论文研究如何优化MapReduce性能,也有多个开源框架诞生出来,但都未能实现性能在量级上的提升,因此也逐渐淡出了历史。第二个重要问题是不能处理实时类数据,因此不能满足一些快速发展的互联网场景需求,如实时推荐、实时调度、准实时分析等。后续Spark框架的出现就优先解决了这几个问题,框架启动开销降到2秒以内,基于内存和DAG的计算模式有效的减少了数据shuffle落磁盘的IO和子过程数量,实现了性能的数量级上的提升。随着更好的计算框架出现,MapReduce逐渐退出了主流应用场景,不过其作为分布式计算的第一代技术架构,其在计算技术演进的过程中发挥了重要的历史价值。
— Spark计算框架 —
随着大量的企业开始通过Hadoop来构建企业应用,MapReduce的性能慢的问题逐渐成为瓶颈,只能用于离线的数据处理,而不能用于对性能要求高的计算场景,如在线交互式分析、实时分析等。在此背景下,Spark计算模型诞生了。虽然本质上Spark仍然是一个MapReduce的计算模式,但是有几个核心的创新使得Spark的性能比MapReduce快一个数量级以上。第一是数据尽量通过内存进行交互,相比较基于磁盘的交换,能够避免IO带来的性能问题;第二采用Lazy evaluation的计算模型和基于DAG(Directed Acyclic Graph, 有向无环图)的执行模式,可以生成更好的执行计划。此外,通过有效的check pointing机制可以实现良好的容错,避免内存失效带来的计算问题。

Spark 实现了一种分布式的内存抽象,称为弹性分布式数据集(RDD,Resilient Distributed Datasets)。它支持基于工作集的应用,同时具有数据流模型的特点 自动容错、位置感知调度和可伸缩性。RDD 允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和 groupBy) 而创建,然而这些限制使得实现容错的开销很低。与分布式共享内存系统需要付出高昂代价的检查点和回滚机制不同,RDD通过Lineage来重建丢失的分区一个RDD中包含了如何从其他 RDD衍生所必需的相关信息,从而不需要检查点操作就可以重构丢失的数据分区。

除了Spark Core API以外,Spark还包含几个主要的组件来提供大数据分析和数据挖掘的能力,主要包括Spark SQL、Spark Streaming、Spark MLLib。
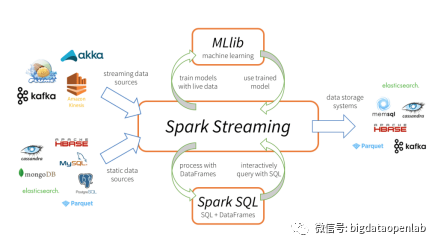
- Spark SQL
- Spark Streaming
Spark Streaming 基于 Spark Core 实现了可扩展、高吞吐和容错的实时数据流处理。Spark Streaming 是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark,也就是把Spark Streaming的输入数据按照micro batch size(如500毫秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成 Spark中RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的转换操作变为针对Spark中对RDD的转换操作,将RDD经过操作变成中间结果保存在内存中。

由于Spark Streaming采用了微批的处理方式,系统本身的吞吐量比较高,但是从应用的视角来看,数据从发生到计算结构的延时在500毫秒甚至以上,如果一个复杂逻辑涉及到多个流上的复杂运算,这个延时将会进一步放大,因此对一些延时敏感度比较高的应用,Spark Streaming的延时过高问题是非常严重的架构问题。Spark社区也在积极的解决相关的问题,从Spark 2.x版本开始推出了Structured Streaming,最本质的区别是不再将数据按照batch来处理,而是每个接收到的数据都会触发计算操作并追加到Data Stream中,紧接着新追加的记录就会被相应的流应用处理并更新到结果表中,如下图所示。
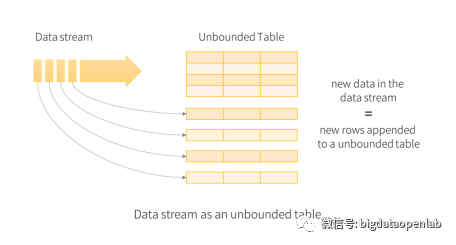
由于Structured Streaming有效地降低了实时计算的延时,此外又是直接基于Dataframe和Dataset API进行了封装,从而方便与Spark SQL以及MLlib对接,因此很快便取代了Spark Streaming成为Spark主要的实时计算方案。此后,社区很快增加了对数据乱序问题的处理、通过checkpoint机制保证At least once语义等关键的流计算功能要求,逐步贴近了生产需求。
- Spark MLLib