1、故障概要
同事在执行Exadata巡检时,发现客户Exadata环境中的celadm01存储节点存在卡顿的现象。相同的命令,在其他的存储节点很快就返回输出结果,而celadm01这台存储节点需要很长时间才返回输出结果。
2、故障分析
(1). 检查主机负载情况。发现celadm01这台存储节点的负载(load average)高达几万,远远高于其他几台存储节点。
(2). 同事在该存储节点执行了top命令,未发现有异常进程独占CPU的情况,但发现该存储节点的进程数高达3万多,真正running的进程只有几个,剩余的进程基本上都处于sleeping状态,具体如下所示。
|
top - 06:56:56 up 594 days, 10:46, 1 user, load average: 27093.61, 27092.08, 27086.28 Threads: 31029 total, 3 running, 30797 sleeping, 0 stopped, 0 zombie %Cpu(s): 5.0 us, 4.2 sy, 0.0 ni, 90.1 id, 0.0 wa, 0.6 hi, 0.0 si, 0.0 st KiB Mem : 13148553+total, 43384912 free, 64332044 used, 23768580 buff/cache KiB Swap: 2097084 total, 2097084 free, 0 used. 61548536 avail Mem |
正常情况下,存储节点的进程数应该在1000个左右,当前这台存储节点上的进程数已经远远超过正常范围。
(3). 分析ps命令输出,发现如下类似的进程占绝大多数,具体如下所示。
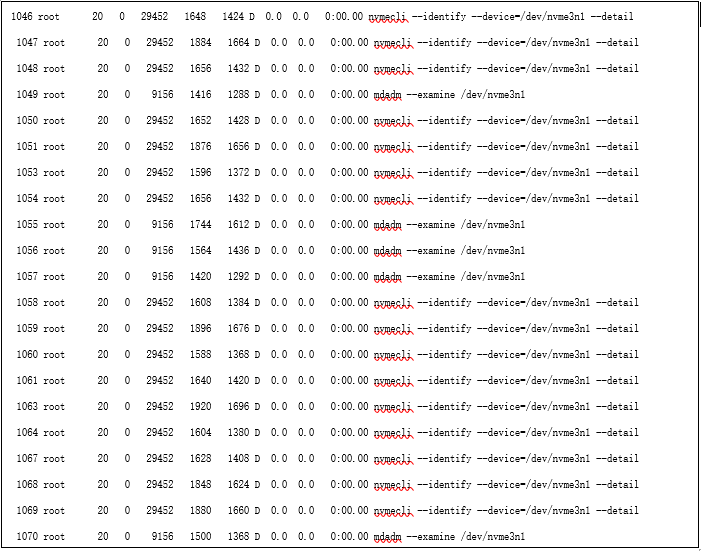
可以看出,当前主机上存在大量的进程正在执行nvmecli --identify --device=/dev/nvme3n1 --detail命令,从这个命令可以推测系统想获取/dev/nvme3n1这块闪存的信息,但这块闪存很可能出现了硬件故障,导致无法获取相关的信息,所以nvmecli命令一直卡着。最终,导致主机上的进程越来越多。
(4). 从目前的情况来看,celadm01存储节点已经异常,建议重启该节点的存储服务,但同事在关闭存储服务时,该存储节点的主机自动重启了。
|
2023-10-27T17:27:48+08:00 critical "CELLSRV shutdown failure. Cell was power cycled." |
主机自动重启后,该存储节点恢复正常。
(5). 查看存储软件的日志。
|
2_1 2023-09-22T14:08:30+08:00 critical "Flash disk entered confinement offline status. .... 2_2 2023-09-22T14:08:34+08:00 critical "Flash disk entered poor performance status. .... 2_3 2023-09-23T02:28:16+08:00 critical "Flash disk failed. Status : FAILED ... 3_1 2023-09-22T14:17:49+08:00 warning " Processes may be in an uninterruptible sleep (D) state...... 3_2 2023-09-23T02:21:50+08:00 info " The following processes may be in an uninterruptible sleep (D) state: Command kworker/u80:0 Tree PID PPID Command 18859 3_3 2023-09-23T02:22:50+08:00 info " The following processes may be in an uninterruptible sleep (D) state: Command /usr/lib/systemd/systemd-udevd Tree PID PPID 3_4 2023-09-23T02:23:50+08:00 info " The following processes may be in an uninterruptible sleep (D) state: Command nvmecli --identify --device=/dev/nvme3n1 --detail 3_5 2023-09-23T02:24:50+08:00 info " The following processes may be in an uninterruptible sleep (D) state: Command nvmecli --identify --device=/dev/nvme3n1 --detail 3_6 2023-09-23T02:25:50+08:00 info " The following processes may be in an uninterruptible sleep (D) state: Command nvmecli --identify --device=/dev/nvme3n1 --detail |
从存储软件的日志可以看出:
2023-09-22T14:08分,有一块闪存出现故障,进入poor performance状态,9分钟后,有一个进程进入D状态,这个进程很可能就是检测闪存信息的nvmecli命令。
2023-09-23T02:21开始,又出现多个进程进入D状态,这些进程中有多个进程是执行nvmecli命令检测闪存信息。最终,在2023-09-23T02:28分,闪存进入FAILED状态。
3、建议
个人认为这应该是存储软件的一个BUG,既然存储软件识别出这块闪存已经出现故障,就不应该再生出这么多检测闪存状态的进程。但搜索MOS资料库,未找到已知的BUG,建议升级存储软件。