郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Published as a conference paper at ICLR 2023(同大组工作)
ABSTRACT
我们考虑了两种生物学合理的结构,脉冲神经网络(SNN)和自注意机制。前者为深度学习提供了一种节能且事件驱动的范式,而后者则能够捕获特征依赖性,使Transformer能够获得良好的性能。凭直觉,探索他们之间的结合是有希望的。在本文中,我们考虑利用SNN的自注意能力和生物学特性,提出了一种新的脉冲自注意力(Spiking Self Attention, SSA)以及一个强大的框架,称为Spiking Transformer(Spikformer)。Spikformer中的SSA机制通过使用不带softmax的脉冲形式Query、Key和Value来对稀疏视觉特征进行建模。由于SSA的计算是稀疏的并且避免了乘法运算,因此SSA是高效的并且具有低的计算能耗。研究表明,在神经形态和静态数据集上,具有SSA的Spikformer在图像分类方面可以优于最先进的类SNN框架。Spikformer(66.3M参数)的大小与SEW-ResNet-152(60.2M,69.26%)相当,使用4个时间步骤,可以在ImageNet上实现74.81%的top1精度,这是直接训练的SNN模型中最先进的。Spikformer提供代码。
1 INTRODUCTION
作为第三代神经网络(Maass,1997),脉冲神经网络(SNN)以其低功耗、事件驱动特性和生物合理性而极具前景(Roy et al.,2019)。随着人工神经网络(ANN)的发展,SNN能够通过借鉴ANN的先进架构来提高性能,如类ResNet SNN(Hu et al.,2021a;Fang et al.,2021;Zheng et al.,2021;Hu et al,2021b)、脉冲循环神经网络(Lotfi Rezaabad & Vishwanath,2020)和脉冲图神经网络(Zhu et al.,2022)。Transformer最初是为自然语言处理而设计的(Vaswani et al.,2017),在计算机视觉的各种任务中蓬勃发展,包括图像分类(Dosovitskiy et al.,2020;Yuan et al.,2021a)、目标检测(Carion et al.,2020;Zhu et al.,2020;Liu et al.,2021),语义分割(Wang et al.,2021;Yuan et al.,2021b)和底层图像处理(Chen et al.,2020)。自注意是Transformer的关键部分,选择性地关注感兴趣的信息,也是人类生物系统的一个重要特征(Whittington et al.,2022;Cauchette & King,2022)。直观地说,考虑到这两种机制的生物学特性,探索在SNN中应用自注意进行更高级的深度学习是很有趣的。
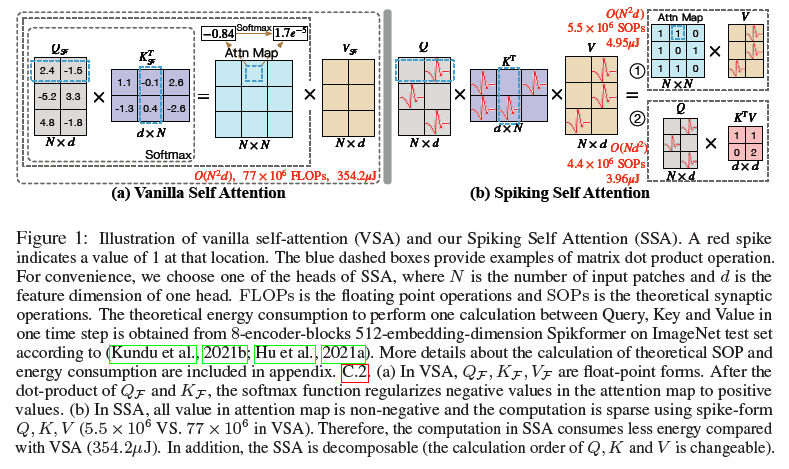
然而,将自注意机制移植到SNN中并非易事。在朴素自注意(VSA)(Vaswani et al.,2017)中,有三个组成部分:查询(Query)、键(Key)和值(Value)。如图1(a)所示,VSA的标准推理首先是通过计算浮点数形式Query和Key的点积来获得矩阵;然后采用包含指数计算和除法运算的softmax对矩阵进行归一化,以给出用于加权值的注意力图。VSA中的上述步骤不符合SNN的计算特性,即避免乘法。此外,VSA繁重的计算开销几乎禁止将其直接应用于SNN。因此,为了在SNN上开发Transformer,我们需要设计一种新的有效且计算高效的自注意变体,它可以避免乘法运算。
因此,我们提出了Spiking Self Attention(SSA),如图1(b)所示。SSA首次将自注意机制引入到SNN中,该机制使用脉冲序列对相互依赖性进行建模。在SSA中,Query、Key和Value是脉冲形式,只包含0和1。自注意在SNN中应用的障碍主要是由softmax引起的。1)如图1所示,根据脉冲形式Query和Key计算的注意力图具有自然的非负性,忽略了不相关的特征。因此,我们不需要softmax来保持注意力矩阵的非负性,这是它在VSA中最重要的作用(Qin et al.,2022)。2)SSA的输入和值是脉冲形式,其仅由0和1组成,并且与ANN中VSA的浮点输入和值相比,包含较少的细粒度特征。因此,浮点查询和键以及softmax函数对于建模这样的脉冲序列是多余的。表1说明了我们的SSA在处理脉冲序列的效果方面与VSA具有竞争力。基于以上见解,我们放弃了SSA中注意力图的softmax归一化。一些以前的Transformer变体也放弃softmax或用线性函数代替它。例如,在Performer(Choromanski et al.,2020)中,采用正随机特征来近似softmax;CosFormer(Qin et al.,2022)用ReLU和余弦函数代替softmax。
在SSA的这种设计中,脉冲形式的Query、Key和Value的计算避免了乘法运算,并且可以通过逻辑AND运算和加法来完成。此外,它的计算非常有效。由于稀疏的脉冲形式Query,Key和Value(如附录D.1所示)和简单的计算,SSA中的操作次数较少,这使得SSA的能耗非常低。此外,我们的SSA在softmax被弃用后是可分解的,这进一步降低了当序列长度大于一个头的特征维度时的计算复杂度,如图1(b)①②所示。
基于所提出的SSA,它很好地适应了SNN的计算特性,我们开发了Spikformer。Spikformer的概述如图2所示。它提高了在静态数据集和神经形态数据集上训练的性能。据我们所知,这是第一次探索SNN中的自注意机制和直接训练的Transformer。总之,我们的工作有三个方面的贡献:
- 针对SNN的性质,我们设计了一种新的脉冲形式的自注意,称为脉冲自注意(SSA)。使用稀疏脉冲形式的Query、Key和Value而不使用softmax,SSA的计算避免了乘法运算,并且是有效的。
- 我们在提出的SSA的基础上开发了Spikformer。据我们所知,这是第一次在SNN中实现自注意和Transformer。
- 大量实验表明,所提出的结构在静态和神经形态数据集上都优于最先进的SNN。值得注意的是,我们首次使用直接训练的SNN模型,在ImageNet上以4个时间步骤实现了74%以上的准确率。
2 RELATED WORK
Vision Transformers.
Spiking Neural Networks.
3 METHOD
3.1 OVERALL ARCHITECTURE
3.2 SPIKING PATCH SPLITTING
3.3 SPIKING SELF ATTENTION MECHANISM
4 EXPERIMENTS
4.1 STATIC DATASETS CLASSIFICATION
4.2 NEUROMORPHIC DATASETS CLASSIFICATION
4.3 ABLATION STUDY
5 CONCLUSION
- Transformer Spikformer Network Spiking Neuraltransformer spikformer network spiking neural-network deep-neural-network-driven deep-neural-network-driven autonomous cdeepfuzz programming network basics neural recurrent network neural 4.3 l-layer network课程neural 神经网络 神经network neural 1b-watching-notes neural-network watching network network neural