近期AI模型重要工作综述
自2022年末Chatgpt和Stable Diffusion横空出世以来,AI模型又进入了一个新的阶段,现就2023年出现的一些新颖模型,以及前几年被提出,现在作为某个领域的“基底”的重要工作,做一些总结和分析。
1. GPT-4
OpenAI在Chatgpt(GPT-3.5)之后又于2023年3月14日发布了GPT-4,作为OpenAI最新的大模型,GPT-4在多项测试上展现了对GPT-3.5的全面超越[1]。
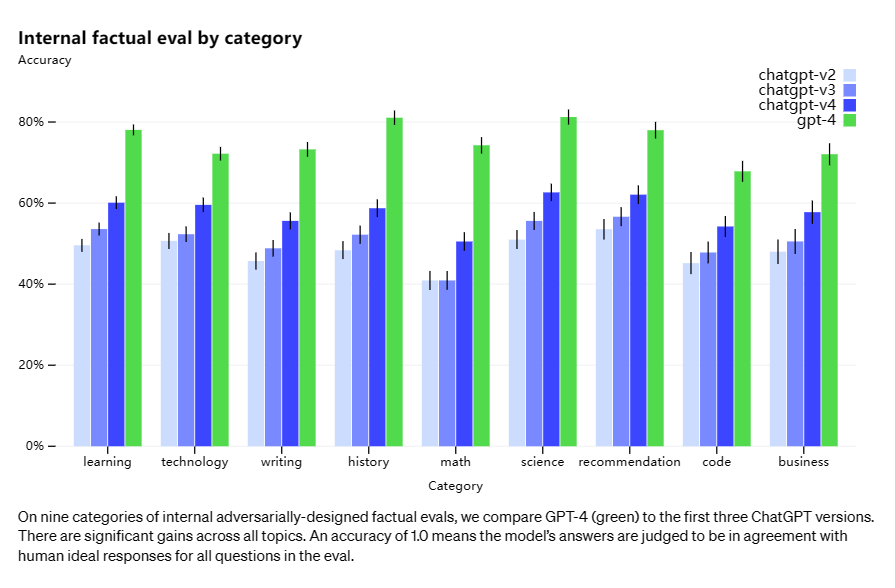
并且相比于只支持文字模态的GPT-3.5,GPT-4是一个可以支持图文输入的多模态模型,可以通过图片+文字prompt的方式来处理图片理解之类的更复杂的问题。最初面向用户发布的GPT-4还不支持图片输入方式,直到9月25日发布的GPT-4V[2]。目前已经有人开始测试GPT-4V在自动驾驶[3]等场景中的应用情况。

此外OpenAI又在GPT-3.5和GPT-4中加入了插件功能[4],使得其可以通过调用外部应用的方式来解决一些大模型本身并不擅长的问题,比如通过调用Wolfram插件来解决一些复杂数学计算问题。
2. Claude2
Anthropic于7月11日发布了Claude2,作为对标OpenAI的GPT-4的大语言模型产品,Claude2在问答上同样有极高的质量,同时其关键特色是支持极长的上下文窗口。Claude2支持200k上下文,使得其可以直接对长文本进行分析,而不需要进行多次拆分输入。
3. LLaMA-1 & LLaMA-2
上述两个大模型别的都好,但是全是商用闭源模型,除了一些测试报告之外毫无任何实现相关的技术细节,使得深入的讨论极为困难。好在Meta今年接连发布了LLaMA-1[5]和LLaMA-2[6]两个开源大模型。
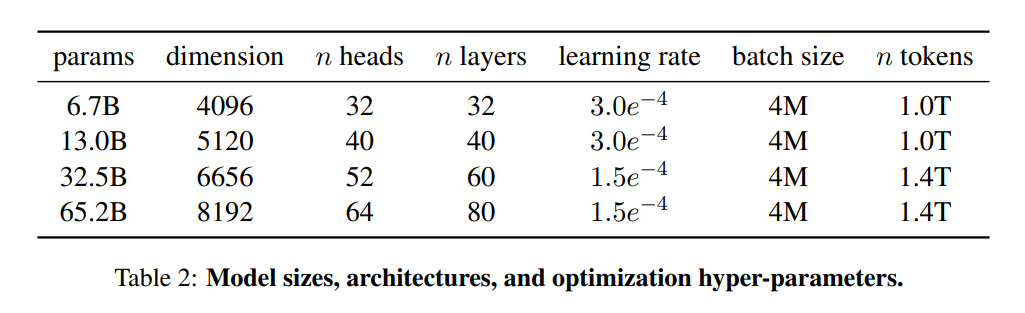
LLaMA-1提供了从6.7B到65.2B共4种参数规模的模型。
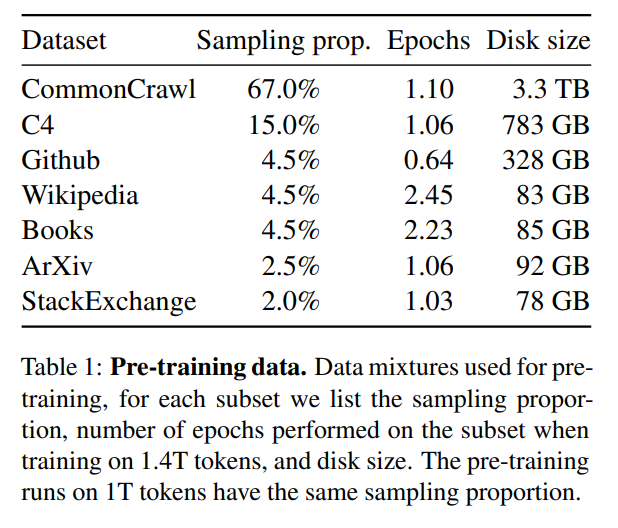
并在如下的公开数据集上进行了训练:
在基于Transformer架构的基础上,LLaMA又参考其他大模型(例如PaLM)做了如下的优化:
- Pre-normalization [GPT3]:为了提高训练稳定性,我们对每个Transformer子层的输入进行归一化,而不是对输出进行归一化。并使用了Zhang and Sennrich(2019) 提出的RMSNorm归一化函数。
- SwiGLU activation function [PaLM]:使用Shazeer(2020)提出的SwiGLU激活函数替换了ReLU激活函数以提升性能。并使用\(\frac{2}{3}4d\)的维度来取代PaLM中的\(4d\)维度。
- Rotary Embeddings [GPTNeo]:去掉了绝对位置嵌入,转而在网络的每一层使用Su et al.(2021)提出的旋转位置嵌入(RoPE)。
从结论上来看:
首先LLaMA-13B可以在小10倍的情况下超越GPT-3,LLaMA-65B可以在尺寸更小的情况下与Chinchilla-70B、PaLM-540B等大模型竞争,其性能具有一定的优越性。其次LLaMA证明了可以在公开数据集上训练出sota大模型,而不需要专有数据集。并且作者们发现通过指令微调的方式还可以进一步提升模型的性能。最后作者在scaling模型的过程中看到了明显的性能提升,并计划在未来放出更大的模型。
作为LLaMA-1的升级版,LLaMA-2在新的公开数据集上进行了训练。并将预训练语料库增大了40%,将模型的上下文长度翻倍,并采用了分组查询注意力 (Ainslie et al., 2023). 目前他们放出了7B,13B,70B三种参数规模的LLaMA-2模型。还有34B的版本只在论文中报告,但没有放出。
此外还有微调后的LLaMA-2,即LLaMA-2-Chat,同样以7B,13B,70B三种规模进行发布。
在安全性评估中,LLaMA-2的表现优于目前的这些开源或闭源的大模型。

LLaMA-2的预训练采用了RLHF方法,这一方法我们在介绍[ChatGPT](对大模型技术与可能的社会影响的思考(一) - sasasatori - 博客园 (cnblogs.com))时就提到过,LLaMA-2这里对它的采用也是再次证明了其有效性。

在训练时LLaMA-2使用了一系列混合的公开可用数据,并使用了两倍于LLaMA-1的Token数量进行训练。LLaMA-2仍然采用了LLaMA-1中的大部分技术,仍然使用标准Transformer架构,使用RMSNorm进行预归一化,使用SwiGLU激活函数,使用旋转位置嵌入等。与LLaMA-1的主要架构差异是增大了上下文长度以及使用了分组查询注意力。
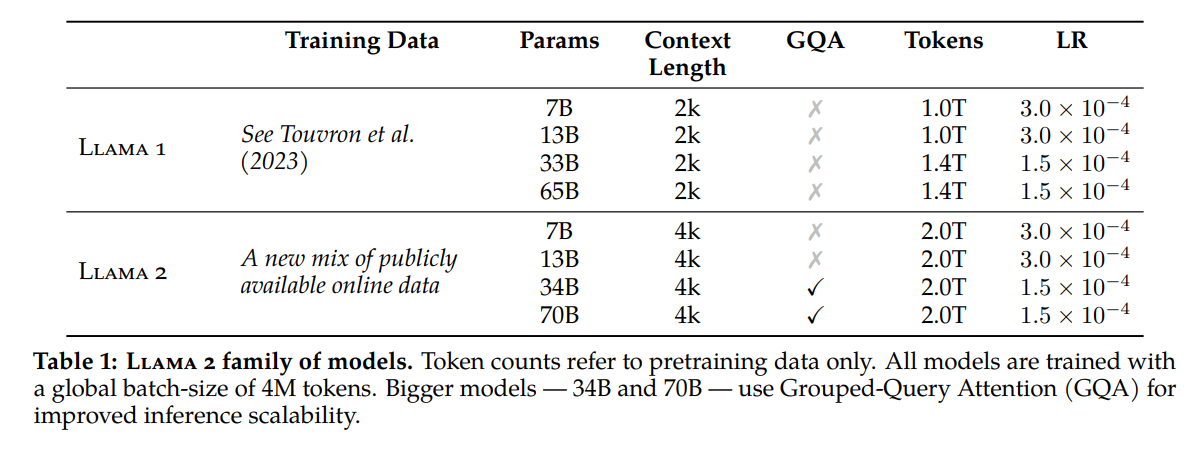
此外LLaMA-2的作者采用了一系列的微调手段来尽可能的提升模型输出的质量和安全性。
从结果上来看,LLaMA-2主要是在LLaMA-1的基础上提出了一些改进,同时由于社会对大模型安全性的担忧问题,作者们在LLaMA-2的论文中着重强调了他们在提高模型的安全性上做出的努力。并计划在未来对于LLaMA-2-Chat做出进一步的改进。
4. RetNet
上面我们介绍完了两个闭源的商用大模型,和基于Transformer的开源大模型LLaMA-1&2,接下来我们看一下由微软研究院和清华于今年联合提出的Retentive Network,简称RetNet结构[7],在论文标题中,作者们说这是大语言模型中Transformer的继承者,可谓野心勃勃,希望RetNet能够取代Transformer在大模型中的地位。
论文一开始,作者提出了一个所谓的“不可能三角”,即低开销的推理、强大的性能和训练的并行性。目前存在的Transformer,Linear Transformer,RNN都各自有缺点。而RetNet的提出解决了这一不可能三角的问题,实现了全能。具体来说,RetNet的贡献于在Transformer和RNN的关键机制之间建立了理论联系(类似的思路在RWKV中见到过),从而使得RetNet能够同时占有两种模型的优势。RetNet支持三种计算范式,分别是并行,循环和分块循环。并行表示使得训练具有并行性。循环表示可实现低开销的O(1)推理,从而提高解码吞吐率,降低延迟,减小GPU存储消耗,同时也不损失性能。分块循环表示有助于实现具有线性复杂度的长序列建模,其中每个块在进行循环总结的同时并行编码。
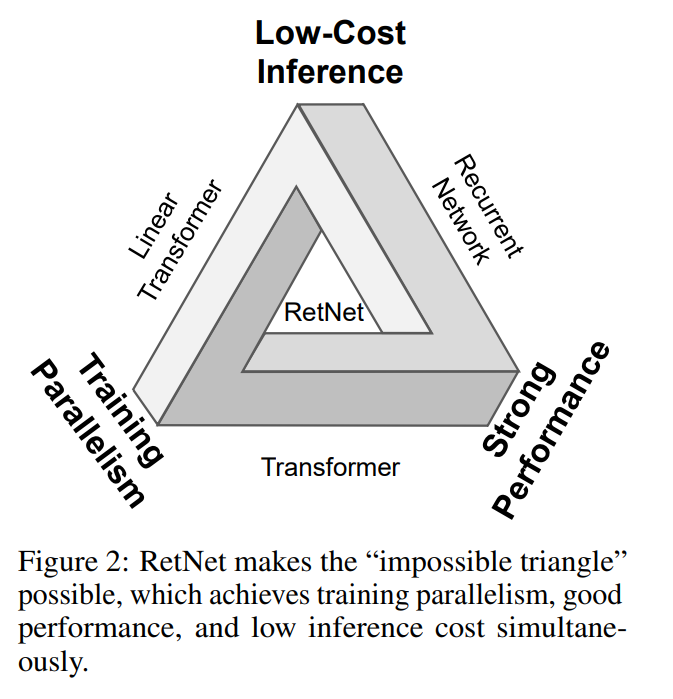
在具体的模型上,并行表示类似于Transformer的注意力机制,因此可以利用其并行性提高训练效率。循环表示类似于RNN,有利于降低推理的开销。
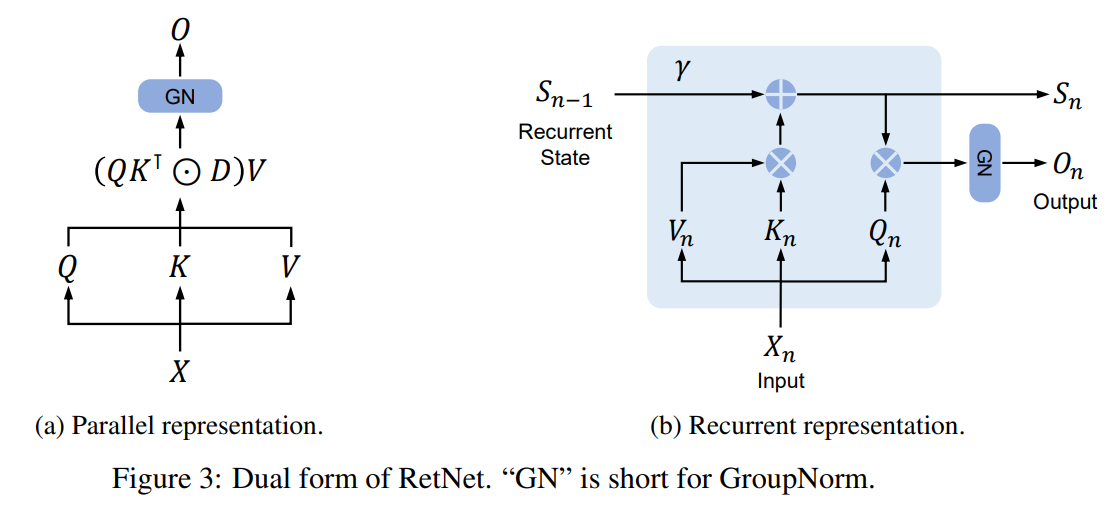
这两种表示的具体数学过程分别如下,并行表示:

循环表示:
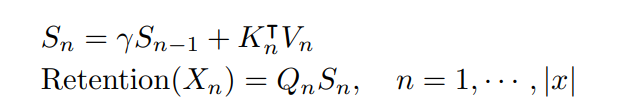
此外还有分块循环表示,其混合使用并行表示和循环表示从而加速训练,尤其是对于长序列。具体来说,通过将输入序列分割成块,在每个块内使用并行表示来进行计算。块之间的信息通过循环表示传递。
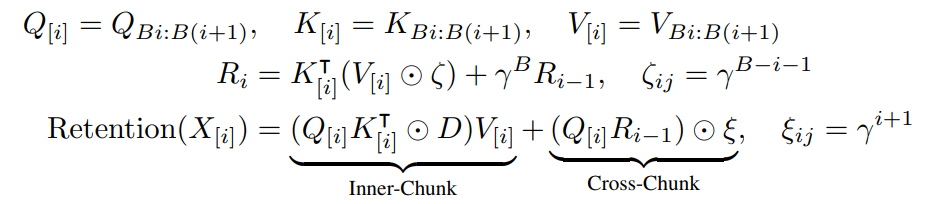
作者通过GroupNorm进行归一化,在整体架构上,RetNet就是MSR(Multi-Scale Retention)和FFN(Feed-Forward Network)的堆叠。LN是LayerNorm,作者使用GeLU激活函数来处理FFN,\(FFN(X)=gelu(XW_1)W_2\)。
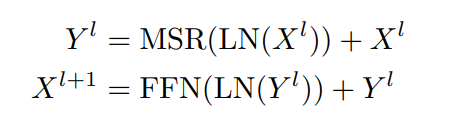
从对比结果上来看,RetNet相比Transformer,RNN以及一些其他的变体在整体上具有更大的优势:
5. SAM
我们上面聊了很多和语言模型有关的东西,接下来我们看看计算机视觉领域今年的新进展,Meta发布的SAM(Segment Anything Model)[8]。
SAM的动力来源在于NLP领域大模型的一系列进展,在大规模数据集上训练过的大规模语言模型能够表现出很强的zero-shot和few-shot性能,作者也希望采用类似的方式去构建一个视觉的“基础模型”。作者提出了新的任务,模型和数据集,预训练后的模型在新的图像和任务上表现出了强劲的zero-shot性能。
作者从任务,模型,数据三个角度进行发问:
- 什么样的任务可以实现zero-shot泛化?
- 相应的模型架构是什么?
- 什么样的数据能够驱动上述的任务和模型?
对此,作者的回答分别为:
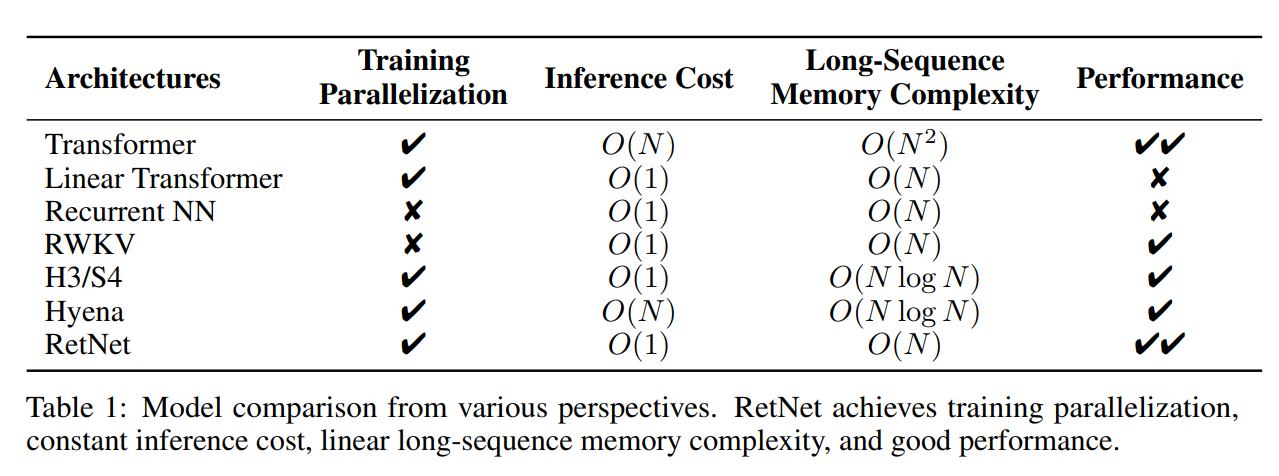
- 任务:在NLP和近期的计算机视觉领域,基础模型都是很激动人心的进展,具体表现为通过使用“提示”技巧在新的数据和任务上执行zero-shot和few-shot学习。受其启发,这个工作提出了“可提示分割任务”,其目标是通过任意给定的分割提示返回一个有效的分割遮罩。一个提示就是指出在图片中要分割什么东西,提示可以包含指示物体的空间或者文本信息。即使提示是模糊的或者指向了多个物体(比如一个衬衫上的点可能指这个衬衫也可能指穿着这个衬衫的人),输出也应当是包含了至少一个这些物体的有效的分割遮罩。作者使用可提示分割任务作为预训练目标,并通过提示工程来解决通用下游任务。
- 模型:可提示分割任务以及在真实世界中使用的目标对模型架构提出了约束。具体来说,模型需要支持灵活的提示,需要能够实时计算出遮罩来满足交互使用,并且需要能够理解模糊的提示。令人惊喜的是,作者们发现使用一个简单的设计就能满足上述三条要求:一个强大的图像编码器来计算图像嵌入,一个提示编码器来计算提示嵌入,然后两个信息源通过一个轻量的遮罩解码器来组合然后预测分割遮罩。作者将这个模型称为分割一切模型(SAM)。通过将SAM分解成一个图像编码器,一个提示编码器和一个快速的遮罩解码器,同一个图像嵌入可以被重用在不同的提示中。给定一个图像嵌入,提示编码器和遮罩解码器可以在浏览器中以大约50ms的速度来预测一个遮罩。作者关注了点,框,特殊形状的几何遮罩提示,以及文本提示。为了使得SAM可以接受模糊的提示,作者将SAM设计为可以从单一的提示中预测出多个遮罩,比如之前提到的衬衫和人的例子。
- 数据:为了取得强大的泛化性,作者发现有必要在庞大且多样的遮罩上训练SAM,并且需要超过任何已有的分割数据集。一个基础模型获得数据的典型方式是从网络上爬取数据,然而遮罩并不是一个网络上能够大量获取的资源,因此作者们改变策略,搭建了一个数据引擎,以协同开发模型和“含模型的数据标注”。数据引擎分成三个阶段:辅助人工,半自动,全自动。在第一个阶段中,SAM帮助标注者进行遮罩标注,类似于传统的交互式分割。在第二个阶段,SAM能够通过提示可能的物体位置自动生成一组物体的遮罩,标注者只需要专注于标注遗漏的物理,以便增加遮罩的多样性。最后的阶段中,作者通过多个点组成的均匀网格来提示SAM,在每张图片上产生大概100个高质量的遮罩。最终的数据集SA-1B包含了一千一百万张图片,十亿个遮罩。其遮罩数量比之前的分割数据集大了400倍。并且经过检验,这些遮罩有着很高的质量和多样性。
SAM的具体架构如下图所示,作者使用了一个重量级的图像编码器(MAE方法预训练的ViT)输出图像嵌入。提示编码器处理两种类型的提示,稀疏类如点、框、文本,稠密类如人工画的遮罩。作者将点和框通过位置编码和其他学习得到的嵌入加在一起,并使用了一个CLIP中的文本编码器来处理文本嵌入,稠密提示则通过卷积后逐元素与图像嵌入累加的方式来进行嵌入。遮罩解码器则使用了一个修改后的Transformer解码器模块和一个动态遮罩预测头,修改后的解码器使用提示自注意力和两个方向的交叉注意力(提示到图像嵌入或者反之)来更新所有的嵌入。在经过这两个模块之后,对图像嵌入做上采样并使用一个MLP把输出token映射成动态线性分类器,从而计算出每个图像位置上的遮罩前景概率。
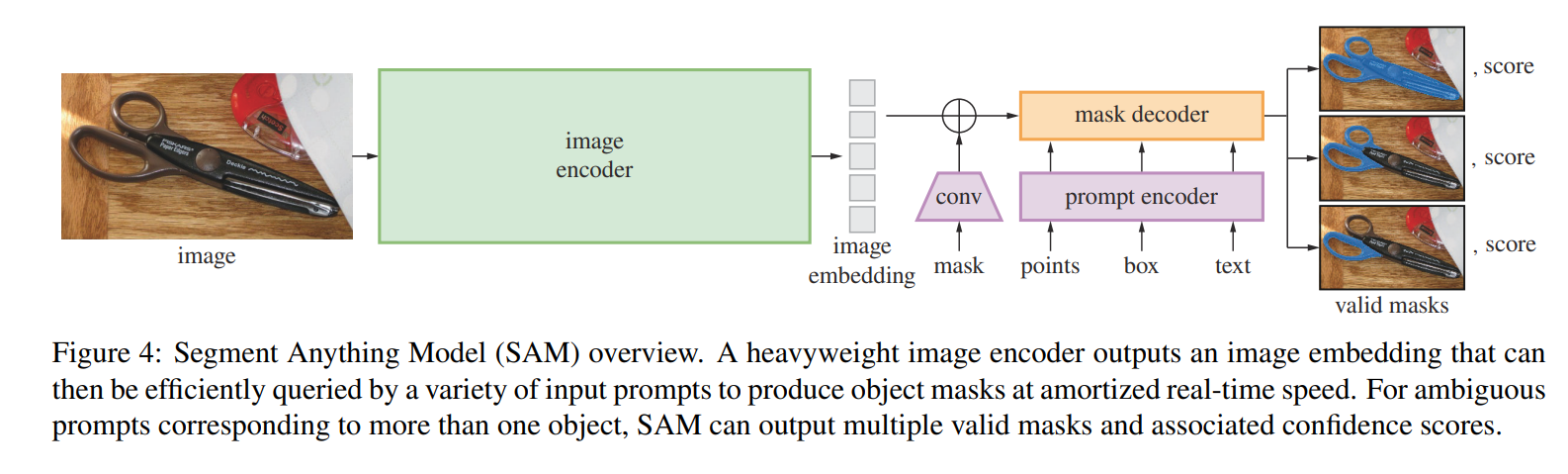
6. Diffusion Model
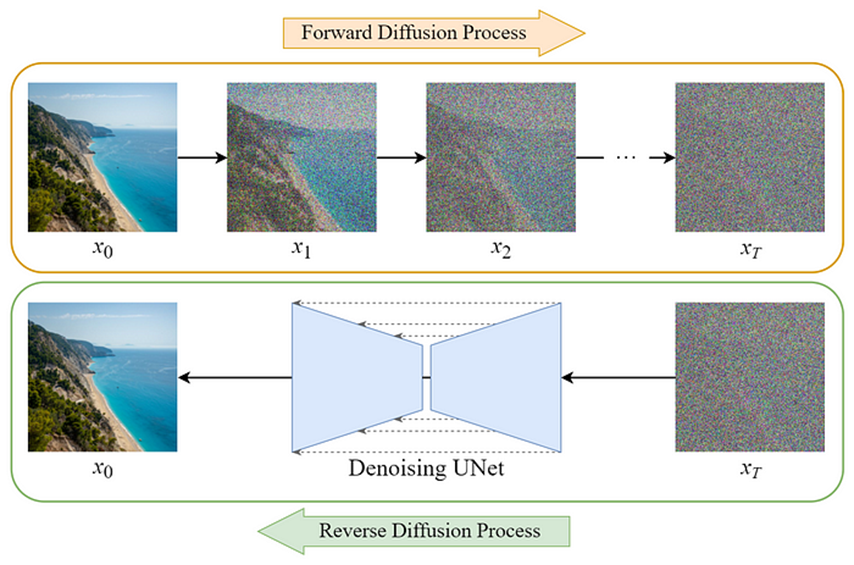
上面主要是讨论了今年的一些新模型,但还有很多工作是以前几年提出的重量级基石为基础进行改进,扩散模型(Diffusion Model)[9]就是其中之一,Diffusion Model在2020年由伯克利大学提出,并成为了大量文本-图像生成工作采用/参考的基础模型。
Diffusion Model全称为扩散概率模型,模型本身是一个参数化的马尔科夫链,使用变分推理,用于在有限时间后生成与数据匹配的样本。链的传播过程学习为逆转一个扩散过程,扩散过程即在采样的相反反向中逐渐向数据中添加噪声,直到信号被破坏为止。当扩散由少量的高斯噪声组成时,就足以将采样链转为条件高斯分布,使得可以通过一个简单的神经网络参数化来实现。
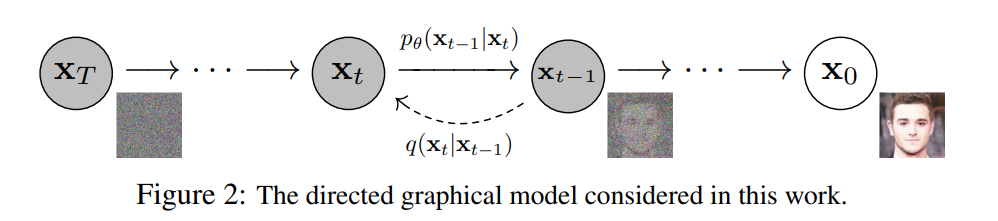
具体来说,Diffusion的前向过程为向一个原始图片\(x_o \sim q(x)\)中进行\(T\)次的高斯噪声添加,得到\(x_1,x_2,...,x_T\),这里需要给定一系列高斯分布方差的超参数\(\beta_t\)。前向过程由于每个时刻\(t\)只与\(t-1\)时刻有关,所以也可以看作马尔可夫过程[10]。
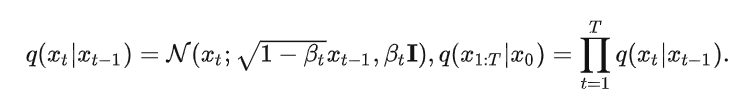
如果说前向过程是加噪的过程,那么逆向过程就是去噪推断过程,如果能够逐步得到逆转后的分布\(q(x_{t-1}|x_t)\),就可以从完全的标准高斯分布\(x_T \sim \mathcal{N}(0,I)\)中还原出原分布\(x_0\),由于这个逆向的分布\(p_\theta\)难以简单推断,可以使用深度学习模型来预测这个分布(比如U-Net)。
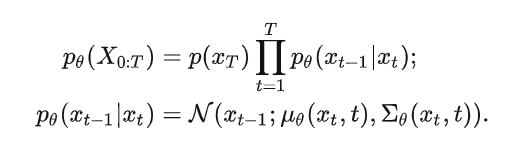
Diffusion Model的大致的结构可以参考下图。Diffusion Model的逆向过程实际上就是一个图像生成的过程,在进行图像生成时,将文本/图像编码器输出的文本/图像嵌入加入逆向过程作为控制条件,就可以从噪声中生成所需要的图像,具体的工作可以参考Stable Diffusion[11],DALL-E2[12],Imagen[13],ControlNet[14]等。如何优化条件控制以获得更可控的输出仍然是Diffusion Model的研究热点。
7. NeRF
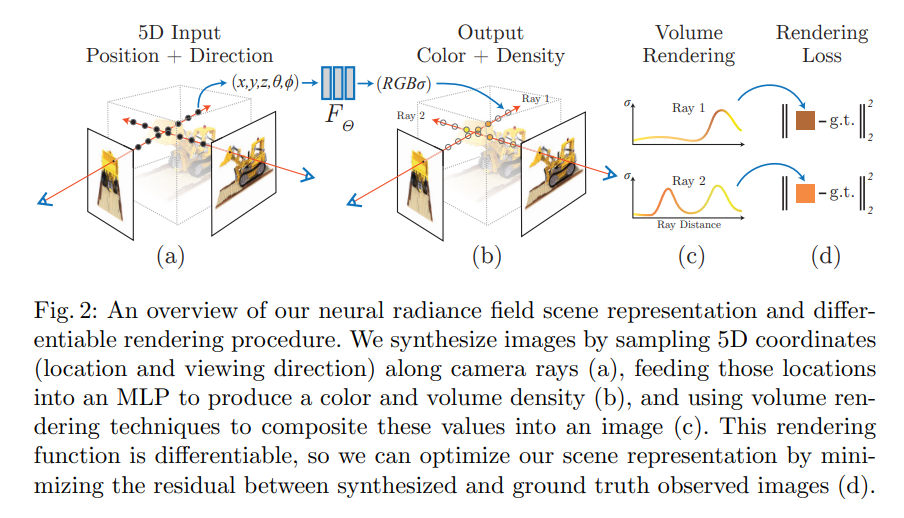
NeRF[15]是UC Berkeley于2020年提出的模型,后续成为了三维重建领域的重要基础模型,引发了很多改进工作,如Mip-NeRF[16],Zip-NeRF[17]等。NeRF即Neural Radiance Fields,神经辐射场。NeRF主要处理的是三维重建任务,其本质是其通过一系列输入的二维图像和相机位置去预测未知新视角下物体的图像。
如下图所示,NeRF通过围绕一个架子鼓随机视角拍摄的100张图像,获得了架子鼓的连续5D(\(X\),\(Y\),\(Z\)的空间位置和\(\theta\),\(\phi\)的视角方向)的神经辐射网表示,并且可以得到之前未拍摄过的视角下的架子鼓的图像。

在具体的方法上,NeRF采用了很简洁的思想,沿着相机轴线采样5D信息(位置与视角方向)来分析图片,将这些位置信息送入一个MLP中来预测颜色与体积密度,再使用体渲染技术来将这些值重组成图片,由于使用的渲染函数可微,可以通过最小化分析的结果和真实观察到的图片之间的差值来优化ReRF的建模表现。
8. CLIP
尽管OpenAI发布的CLIP[18]在之前的博客就提到过,其经过时间检验后其已经成为多模态模型领域的基石之一,后续有很多基于CLIP的改进工作提出,比如BLIP[19],BLIP-2[20]等。
CLIP通过大量的图像文本对训练了图像编码器(对比了ResNet和ViT,ViT的效果更好)和文本编码器(使用了根据Radford et al.(2019)修改后的Transformer),与标准图像模型联合训练图像特征抽取器和线性分类器来分类一些标签不同,CLIP通过联合训练的图像编码器和文本编码器来预测正确的图像文本对。在训练时CLIP采用对比学习方法进行预训练,即利用数据集的构建图像文本对,只有匹配的一对图像文本构成正样本,其他的全部构成负样本。在测试时CLIP通过嵌入目标数据数据集类别的名字或者描述输入学习好的文本编码器,CLIP可以化为一个线性分类器。具体来说,图像编码器将输入图像编码成图像特征向量,而文本编码器将多个类别文本形成的文本编码成多个文本特征向量,然后计算图像特征向量和文本特征向量的余弦相似度,其中的最大值就是分类结果。
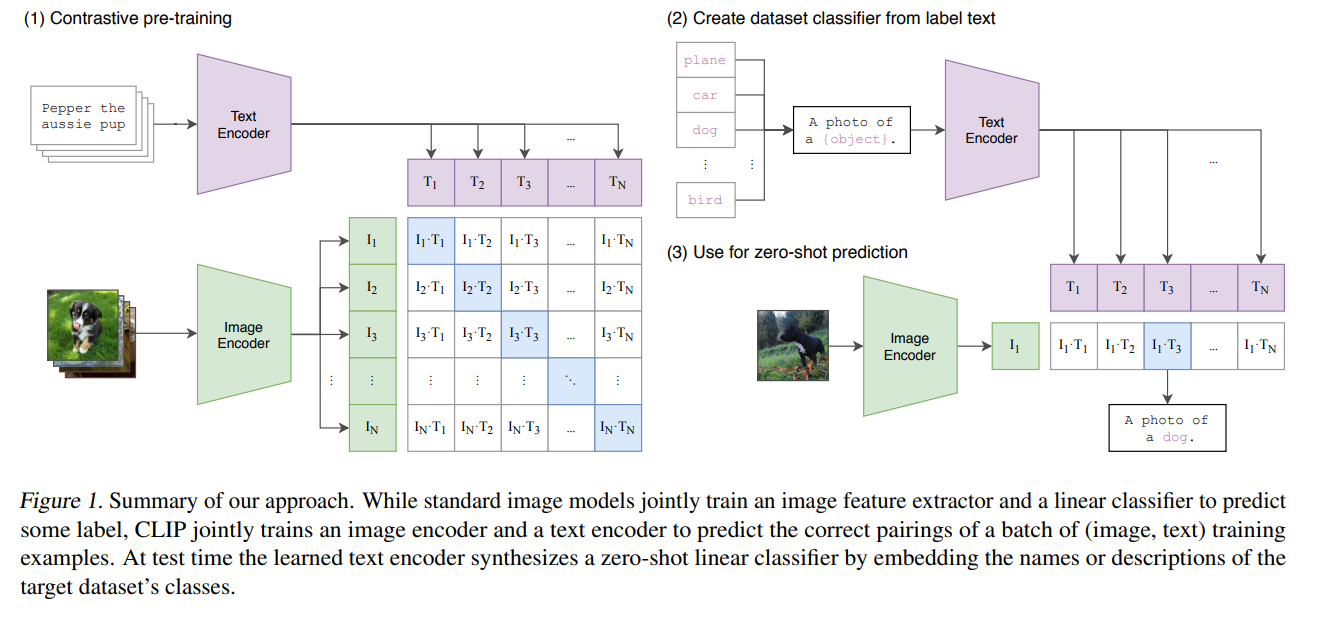
CLIP的重要贡献是以一种全新的方式解决了传统视觉模型受限于有限数据集标签数量的问题,在众多不同的数据集和视觉任务上展现出了非常强大的zero-shot性能,并且CLIP可以用于各种各样的下游任务。
引用
"Sparks of Artificial General Intelligence: Early experiments with GPT-4"https://arxiv.org/abs/2303.12712v1 ↩︎
"The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)" https://arxiv.org/abs/2309.17421 ↩︎
"GPT-4V在自动驾驶中初探" https://zhuanlan.zhihu.com/p/660940512 ↩︎
"ChatGPT plugins (openai.com)" https://openai.com/blog/chatgpt-plugins?ref=essa-vida-ai ↩︎
"LLaMA: Open and Efficient Foundation Language Models" https://arxiv.org/abs/2302.13971 ↩︎
"Llama 2: Open Foundation and Fine-Tuned Chat Models" https://arxiv.org/abs/2307.09288 ↩︎
"Retentive Network: A Successor to Transformer for Large Language Models" https://arxiv.org/abs/2307.08621 ↩︎
"Segment Anything" https://arxiv.org/abs/2304.02643 ↩︎
"Denoising Diffusion Probabilistic Models" https://arxiv.org/abs/2006.11239 ↩︎
"由浅入深了解Diffusion Model" https://zhuanlan.zhihu.com/p/525106459 ↩︎
"High-Resolution Image Synthesis with Latent Diffusion Models" https://arxiv.org/abs/2112.10752 ↩︎
"Hierarchical Text-Conditional Image Generation with CLIP Latents" https://arxiv.org/abs/2204.06125 ↩︎
"Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding" https://arxiv.org/abs/2205.11487 ↩︎
"Adding Conditional Control to Text-to-Image Diffusion Models" https://arxiv.org/abs/2204.06125 ↩︎
"NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis" https://arxiv.org/abs/2003.08934 ↩︎
"Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields" https://arxiv.org/abs/2103.13415 ↩︎
"Zip-NeRF: Anti-Aliased Grid-Based Neural Radiance Fields" https://arxiv.org/abs/2304.06706 ↩︎
"Learning Transferable Visual Models From Natural Language Supervision" https://arxiv.org/abs/2103.00020 ↩︎
"BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation" https://arxiv.org/abs/2201.12086 ↩︎
"BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models" https://arxiv.org/abs/2301.12597 ↩︎