面向对象编程
【一】编程的两大编程思想
【1】面向过程编程
- 面向过程编程:首先分析出解决问题所需要的步骤(即“第一步做什么,第二步做什么,第三步做什么”),然后用函数实现各个步骤,再依次调用。
【1.1】面向过程特点
- 优点 : 复杂的问题简单化,进而流程化
- 缺点 : 扩展性差,牵一发而动全身
- 应用场景 : 一般用在对扩展性要求比较差的情况
【1.2】面向过程案例
把大象放进冰箱需要几步
- 第一步,打开冰箱门
- 第二步,把大象放进冰箱
- 第三步,关上冰箱门
使用面向过程实现注册
- 第一步,用户输入用户名和密码
- 第二步,验证参数
- 第三步,把数据写入文件
# 1. 让用户输入用户名和密码
def get_userinfo():
username = input('username:>>>').strip()
password = input('password:>>>').strip()
email = input('email:>>>').strip()
return {
'username': username,
'password': password,
'email': email,
}
# 2. 验证参数
def check_info(userinfo):
flag = True
if len(userinfo['username']) == 0:
print('用户名不能为空')
flag = False
if len(userinfo['password']) == 0:
print('密码不能为空')
flag = False
if len(userinfo['email']) == 0:
print('邮箱不能为空')
flag = False
return {
'flag': flag,
'userinfo': userinfo
}
# 3. 直接把数据写入文件中
def save_info(param):
# 用来保存数据到文件中
"""
param={
'flag':flag,
'userinfo':userinfo
}
:param param:
:return:
"""
if param['flag']:
with open('userinfo.txt', 'w', encoding='utf-8') as f:
import json
json.dump(param['userinfo'], f)
def main():
userinfo = get_userinfo()
param = check_info(userinfo)
save_info(param)
if __name__ == '__main__':
main()
- 当我需要添加其他功能或者信息,需要查看每一步需要调用到信息的地方,牵一发而动全身
【2】面向对象编程
- 面向对象编程,会将程序看作是一组对象的集合(对象包括类对象和实例对象)
- 用这种思维设计代码时,考虑的不是程序具体的执行过程(即先做什么后做什么),而是考虑先创建某个类,在类中设定好属性和方法,即是什么,和能做什么。
【2.1】对象
- 在生活中:
- 对象就是“特征”与“技能”的集合体
- 在程序中:
- 对象就是盛放“数据属性”和“功能属性”的容器
- 以真假美猴王举例:
- 孙悟空是一个对象,具有
- “特征”:满面毛,雷公嘴,面容赢瘦,尖嘴缩腮,真身长三丈五尺,约10.5米
- “技能”:斗战胜佛
- 假孙悟空
- “特征”:满面毛,雷公嘴,面容赢瘦,尖嘴缩腮,真身长三丈,约9米,害怕唐僧手中的降妖宝杖
- “技能”:斗战胜佛
- 如果假孙悟空与真孙悟空有一样的特征和技能,那么这个时候假孙悟空,也可以是真孙悟空
- 孙悟空是一个对象,具有
【2.2】面向对象特点
- 优点:扩展性强
- 缺点:简单的问题复杂化
【2.3】对象的推导
版本 1 :数据乱,代码冗余,且不利于大量数据
# 版本1
stu_name = 'user001'
stu_age = 18
stu_gender = 'male'
stu_courses = []
stu1_name = 'user002'
stu1_gender = 'female'
stu1_age = 20
stu1_courses = []
def choose_course(stu_name, stu_courses, course):
stu_courses.append(course)
print("%s选课成功:%s" % (stu_name, stu_courses))
choose_course(stu_name, stu_courses, 'python')
choose_course(stu_name, stu_courses, 'linux')
choose_course(stu1_name, stu1_courses, 'python')
choose_course(stu1_name, stu1_courses, 'linux')
版本2:有了对象的信息,但对象不仅仅只有“特征” 还应该有能力
# 版本2
stu1_dict = {
'name': 'user001',
'age': 18,
'gender': 'male',
'courses': [],
}
stu2_dict = {
'name': 'user002',
'age': 20,
'gender': 'male',
'courses': []
}
def choose_course(stu_dict, course):
stu_dict['courses'].append(course)
print("%s选课成功:%s" % (stu_dict['name'], stu_dict['courses']))
choose_course(stu1_dict, 'python')
choose_course(stu2_dict, 'python')
版本 3:对象既要有数据属性,又有功能属性
# 版本3
def choose_course(stu_dict, course):
stu_dict['courses'].append(course)
print("%s选课成功:%s" % (stu_dict['name'], stu_dict['courses']))
stu1_dict = {
'name': 'user001',
'age': 18,
'gender': 'male',
'courses': [],
'choose_course': choose_course
}
stu2_dict = {
'name': 'user002',
'age': 20,
'gender': 'male',
'courses': [],
'choose_course': choose_course
}
stu3_dict = {
'name': 'user003',
'age': 25,
'gender': 'female',
'courses': [],
'choose_course': choose_course
}
stu_dict['choose_course'](stu_dict, 'python')
stu_dict['choose_course'](stu_dict, 'linux')
stu1_dict['choose_course'](stu1_dict, 'linux')
stu2_dict['choose_course'](stu2_dict, 'linux') # 谁来选课,就把谁自己当成第一个参数传递过去
【2.4】类(class)
-
类(class) :一系列相似的特征和相似的技能的结合体
-
在现实中(先有对象,再有类)
- 我们常用类来划分一个个特定的群体,如人类,鸟类,鱼类,植物类……
- 事物也被井井有条地划分成了各个种类,如电子类、家具类、服饰类、食品类……
- 这便是生活中我们所说的类,是物以类聚的类,是分门别类的类,是多个类似事物组成的群体的统称。
-
在编程世界中(先有类,再有对象)
- 一定是先有类,然后调用类,产生对象!
- 如数字 1,2,3 属于 整数类 int
- 如"字符串" 属于 字符串类 str
-
-
在Python的术语里,我们把类的个例就叫做实例 (instance),可理解为“实际的例子”。
【e.g.】狗、秋田犬、忠犬八公、list、[1,2]分别是 类,类,实例,类,实例
- 类是某个特定的群体,实例是群体中某个具体的个体。
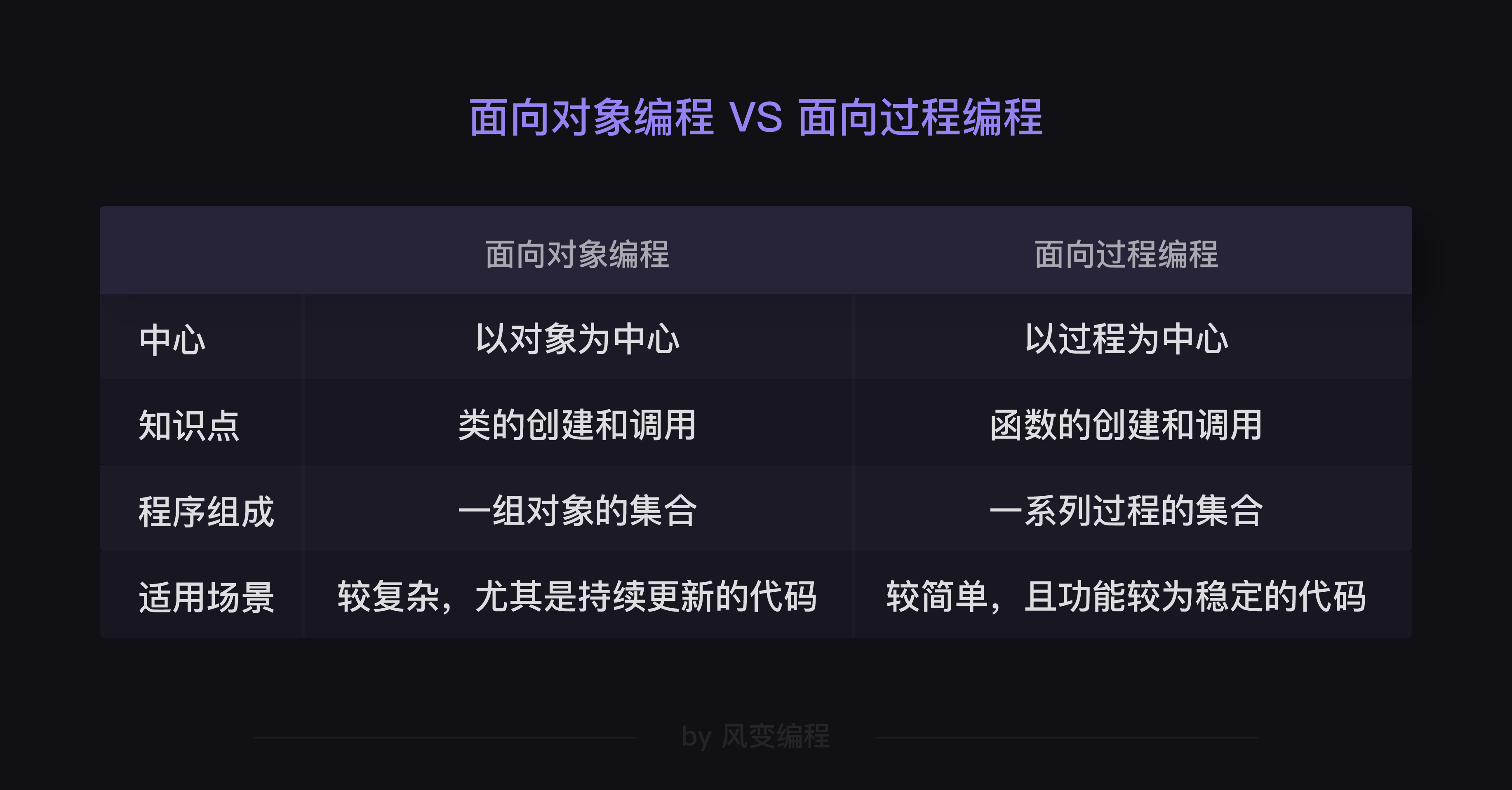
【3】两者的区别
【二】类的定义和对象的产生
【1】基本语法
class 类名():
类体
- 类名的命名:
- 一般情况下遵循变量的命名规范,类名一般首字母大写
- 当类名比较长时,推荐使用大驼峰体(ClassName),尽量不要使用下划线
- 类名后的小括号不可以省略:
- 虽然省略小括号后也不会报错,但一般情况还是加上小括号
【2】定义类的时候发生了哪些事情?
- 【1/2】类一旦定义完成,会立马执行类体代码
class Index():
name = 'user'
def func(self):
pass
print('hello')
'''没有调用类,但是执行了print语句'''
# hello
- 【2/2】会产生类的名称空间,其实就是一个大字典,然后把类中的名字都丢到类的名称空间去
- 可以通过
类名.__dict__查看
- 可以通过
class Index():
name = 'user'
def func(self):
pass
print(Index.__dict__)
# {'__module__': '__main__', 'name': 'user', 'func': <function Index.func at 0x00000203AFC927A0>, '__dict__': <attribute '__dict__' of 'Index' objects>, '__weakref__': <attribute '__weakref__' of 'Index' objects>, '__doc__': None}
'''字典中的内容就是可以通过类名+【.】调用的'''
print(Index.__module__) # __main__ # 意思是该类是执行文件中的类
print(Index.name) # user # 拿到类中的数据数据 name 的值
【3】如何产生对象(实例)
- 通过调用类,产生对象(实例)
class Index():
name = 'user'
def func(self):
return "我是类中的func函数"
# index1 就可以称为Index类中的一个实例
# 这个过程就叫做实例化对象
index1 = Index()
print(index1) # <__main__.Index object at 0x0000020D324EA6B0>
# 实例化对象可以调用类中的数据属性和函数属性
print(index1.name) # user
print(index1.func()) # 我是类中的func函数
'''实例化的对象也有自己的名称空间,默认为空'''
# 所以实例化的对象可以调用类名称空间中的内容,同时也有自己的名称空间
print(index1.__dict__) # {}
【4】如何定制对象自己的独有的属性
# <__main__.Student object at 内存地址>也就是<__模块名__.类名 对象 at 内存地址>的含义是,是类中的一个对象
【4.1】通过名称空间字典进行添加(一般情况下不推荐使用)
-
__方法名__一般情况都有特殊用法,不推荐经常使用 -
我们通过
对象(object).__dict__得到的名称空间是个字典,而字典是可以通过添加键值对添加值的
class Student(object): # 加了小括号带有继承的含义,这里定义一个类,继承object这个类,object这个类,是最顶层的基类,没有再往上的父类了
...
'''对象与对象是隔离的,互不影响'''
# 对象1
stu1 = Student()
print(stu1) # <__main__.Student object at 0x00000233C8BCB910>
print(stu1.__dict__) # {}
stu1.__dict__['name'] = 'use001'
stu1.__dict__['age'] = 18
stu1.__dict__['gender'] = 'male'
print(stu1.__dict__) # {'name': 'use001', 'age': 18, 'gender': 'male'
# 对象2
stu2 = Student()
print(stu2) # <__main__.Student object at 0x0000028543379720>
print(stu2.__dict__) # {}
stu2.__dict__['name'] = 'use002'
stu2.__dict__['age'] = 28
stu2.__dict__['gender'] = 'female'
print(stu2.__dict__) # {'name': 'use002', 'age': 28, 'gender': 'female'}
【4.2】通过点语法(对象名 + . )
# 对象1
stu1 = Student()
print(stu1) # <__main__.Student object at 0x00000233C8BCB910>
print(stu1.__dict__) # {}
stu1.name = 'use001'
stu1.age = 18
stu1.gender = 'male'
print(stu1.__dict__) # {'name': 'use001', 'age': 18, 'gender': 'male'
# 对象2
stu2 = Student()
print(stu2) # <__main__.Student object at 0x0000028543379720>
print(stu2.__dict__) # {}
stu2.name = 'use002'
stu2.age = 28
stu2.gender = 'female'
print(stu2.__dict__) # {'name': 'use002', 'age': 28, 'gender': 'female'}
【4.3】为了避免代码冗余,可以封装成函数使用
def init_func(stu_obj, name, age, gender):
stu_obj.name = name # stu1.name = 'use001'
stu_obj.age = age # stu1.age = 18
stu_obj.gender = gender # stu1.gender = 'male'
'''除去打印代码,实际执行代码一句话即可使用'''
stu1 = Student()
print(stu1.__dict__) # {}
init_func(stu_obj=stu1, name='user001', age=18, gender='male')
print(stu1.__dict__) # {'name': 'user001', 'age': 18, 'gender': 'male'}
stu2 = Student()
print(stu2.__dict__) # {}
init_func(stu_obj=stu2, name='user002', age=28, gender='female')
print(stu2.__dict__) # {'name': 'user002', 'age': 28, 'gender': 'female'}
- 而我们就可以更加拓展一下,stu1 和 stu2 都是类Student,那么它们是不是相当于有同样的技能init,那么我们就可以将该函数放到类中,作为一个函数属性,也叫做方法来共同使用
class Student(object):
'''当函数放在类中的时候,就叫做类的函数属性,也叫做方法'''
def init_func(stu_obj, name, age, gender):
stu_obj.name = name
stu_obj.age = age
stu_obj.gender = gender
stu1 = Student()
stu1.init_func(name='user001', age=18, gender='male')
print(stu1.__dict__) # {'name': 'user001', 'age': 18, 'gender': 'male'}
- 我们可以发现,我们只需要传递给函数三个参数就可以了
- 这里就涉及到类中方法的特殊参数了,方法的第一个参数默认是作为对象传递给类的
- 具体请看下文
self函数详细介绍
- 具体请看下文
【4.4】使用魔法方法__init__,同样能够实现定制
- 魔法方法是在类定义中使用双下划线
__包围的方法,也被称为特殊方法或魔术方法。这些方法在特定的情境下会被 Python 解释器自动调用,用于执行一些特殊的操作。- 具体请看另一篇文章【Python面向对象之内置方法-魔法方法】
class Student(object):
'''类里面不一定非要有这个方法,只有当你需要提前定制对象的属性时,才需要写这个函数'''
def __init__(stu_obj, name, age, gender):
stu_obj.name = name
stu_obj.age = age
stu_obj.gender = gender
# 当我们实例化对象时,就强制要求我们传值,如果不传,将会报错
# stu1 = Student() # 不传值的情况
# TypeError: Student.__init__() missing 3 required positional arguments: 'name', 'age', and 'gender'
'''当我们在类中定义了__init__方法后,将会自动帮我们执行函数内容'''
stu1 = Student(name='user001', age=18, gender='male')
print(stu1.__dict__) # {'name': 'user001', 'age': 18, 'gender': 'male'}
'''__init__的标准用法'''
def 类名():
def __init__(self): # __init__ 的第一个默认参数是self
'''初始化函数体'''
【5】特殊的参数self
- 特殊参数self的作用:self会接收实例化过程中传入的数据,当实例对象创建后,实例便会代替 self,在代码中运行。
- 换言之,self 是所有实例的替身
class Student(object):
'''第一个参数默认是self,但它其实就是一个形参,可以自由的改名,但约定俗成的第一个参数就叫self'''
'''不仅仅是为了能够通俗的明白这个参数的作用,用来代替自己的self,也是为了方便互相理解代码'''
def __init__(self, name, age, gender):
print(self) # <__main__.Student object at 0x000002159B4BA6B0>
self.name = name
self.age = age
self.gender = gender
stu1 = Student(name='user001', age=18, gender='male')
- 【self函数】可以通过self.类中的数据属性或函数属性 获取到类中的属性
- 【self函数】可以提前”占位“
- 具体如下
class Class(object):
name = 'user'
'''任何普通方法的第一个参数,都是【self参数】'''
def say(self):
'''此时self就相当于类的对象,类的对象就可以调用类的数据属性'''
print(f'{self.name} 正在说话') # self.name = Class.name
return "这是say函数"
'''当你添加了新的属性到对象名称空间,也可以通过self.xxx提前”占位“'''
def run(self):
print(f'{self.name} 正在跑步 {self.meter}') # self.meter = c.meter
# user 正在跑步 100m
'''也可以通过self.func调用类中的其他函数'''
def code(self):
print(f'{self.name} 正在敲代码 \n-----{self.say()}')
# user 正在说话 # 因为调用了say函数,所以先执行函数的内容,再接收返回值
# user 正在敲代码
# -----这是say函数
c = Class()
c.say()
c.meter = '100m'
c.run()
c.code()