DETR基于Transformer目标检测
DETR首次将Transformer应用到了目标检测任务中。图像会先经过一个传统的CNN抽出图像特征来,然后再将CNN的输出直接送到Transformer网路中,Transformer会直接输出一组预测的集合,每个预测包含框的中心点坐标、宽高以及框的类别,然后通过一个二分图匹配策略将预测框和GT框一一匹配用来计算Loss。
论文原文: https://arxiv.org/pdf/2005.12872.pdf
源码地址:https://github.com/facebookresearch/detr
DETR是第一个使用transformer编码器-解码器架构的端到端对象检测器
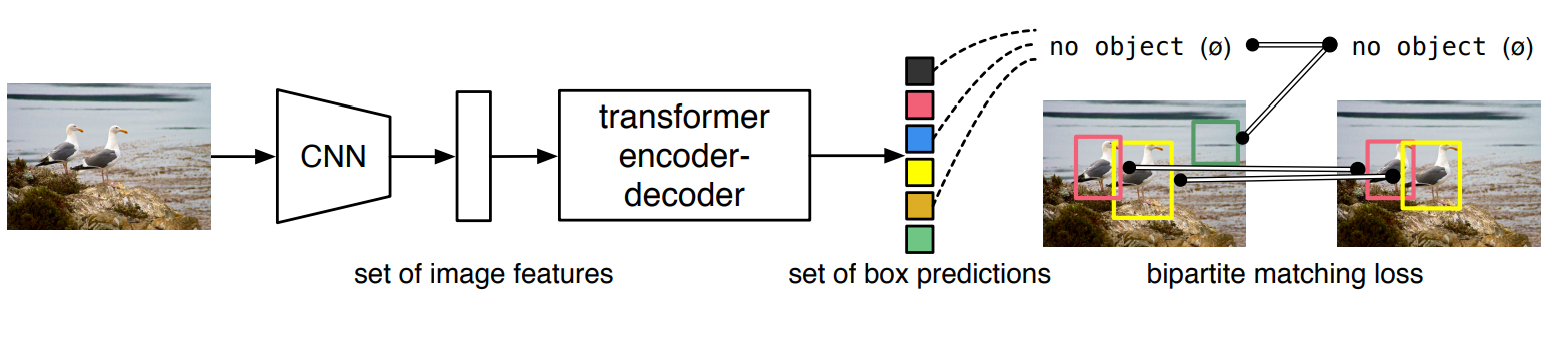
现有的目标检测算法是将GT进行正匹配作为一种启发式方法,需要对近似重复预测进行非极大值抑制 (NMS) 后处理。
传统目标检测算法的缺点:
在每个像素点上枚举预定义的anchor,照成大量候选框的是无效的
RPN输出了太多冗余的框需要NMS来删除
DETR通过基于集合的目标消除了对NMS后处理的需要,引入了完全端到端的检测器DETR。训练目标采用匈牙利算法设计,既考虑分类成本,又考虑回归成本,并获得极具竞争力的性能。
DETR网络结构
从DETR中的论文原图,DETR 网络主要由三部分组成 backbone layers、transformer layers、prediction layers。
整体结构分为3部分:
1、传统CNN,用于提取图片局部特征
2、Transformer 结构,Encoder提取图片全局特征和 Decoder 做预测
3、Bipartite Matching Loss 来训练网络
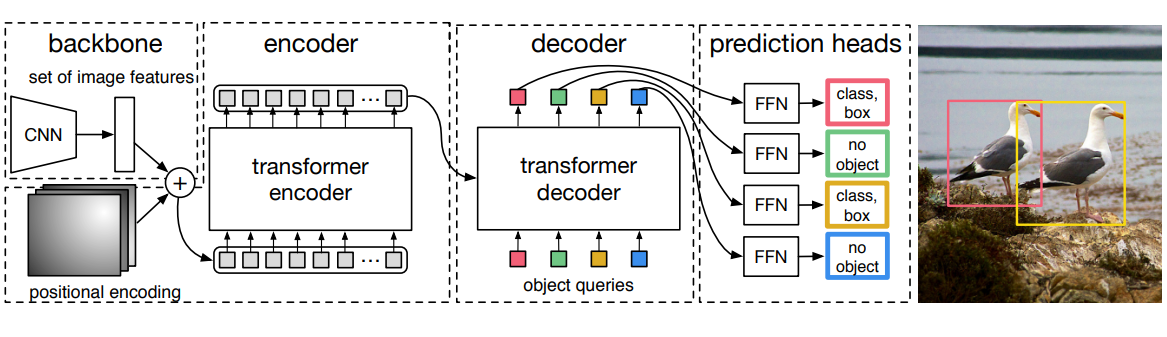
backbone
DETR整个过程就是使用CNN提取特征后编码解码得到预测输出
在神经网络里backbone结构可以理解为一个预处理器或者一个特征提取器。作为神经网络的底层结构,该部分主要用于提取数据的features。backbone通常采用网络上现有的经过预训练的网络结构,backbone有vggnet,resnet,谷歌的inception等。在DETR的源代码code里,使用了resnet50的预训练模型作为特征提取器,一方面缩短训练模型的时间,另一方面特征提取效果更好。
输入原始图像为 B x C × H × W 输出低分辨率特征B x C x H x W一般 C=2048,H=1/32,W=1/32也就是32倍下采样
然后 H,W 维度拉平 B, C, H*W 再加上位置编码信息一起送入encoder中。进一步提取全局的特征
经过 Backbone 后,将输出特征图 reshape 为 C × H W ,因为 C = 2048 是每个 token 的维度,还是比较大,所以先经过一个 1 × 1 的卷积进行降维,然后再输入 Transformer Encoder 会更好。
为了体现图像在x和y的信息,分别计算两个维度的 positional encoding,然后cat 到一起,基础方法话还是采用了原版 transformer结构的位置编码, 用周期函数 保证在一定范围内的编码差异不依赖于序列的长度,这样长序列的相对次序关系不会被稀释。
Transformer
该部分的网络结构与原本attention all need 中提出的模型相比基本没变,
DETR中关于Transformer部分在原有的网络基础上,修改了三个地方
encoder里是一个自注意力机制,输入为Image Feature和位置编码,这里和NLP中Transformer Encoder是一样的,只不过NLP输入的是文本Embedding。
Decoder里首先是一个Self Attention, Key Value Query是都是decoder embedding + object queries ,Value没有加object queries
Decoder embedding是decoder每一层的输出,在第一层初始为一个全0的向量;然后是一个Cross-Attention,在cross attention中 decoder embedding + learnable queries作为Query, Encoder的输出作为Key和Value,这里和NLP中transformer的结构是一致的。
Transformers decoder 部分是输入是 100 个 Object queries,比如说我们数据集总共有100个类别的物体需要预测,那么这 100 object queries 经过Transformers decoder 之后会预测出若干类别的物体和位置信息.
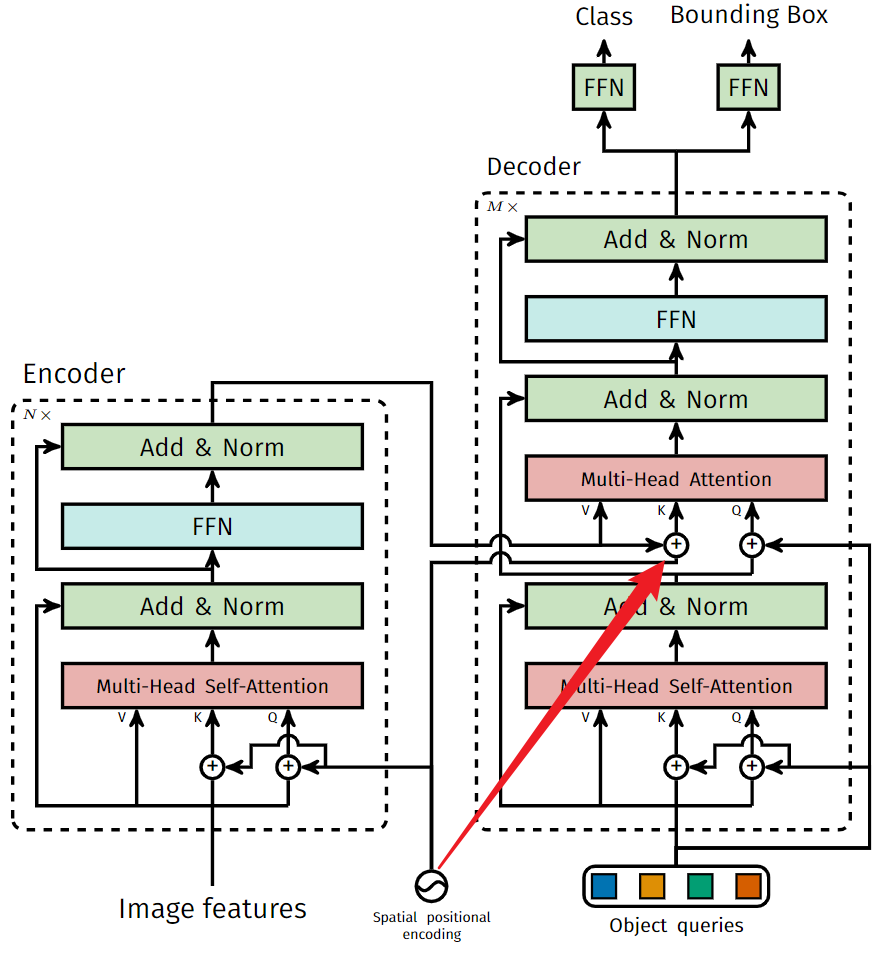
和NLP Transformer对比
在Encoder 中
Key: Image Features + Positonal Embeding==上面图的Spatial positional encoding(空间位置编码)
Query:Image Features + Positonal Embeding==上面图的Spatial positional encoding(空间位置编码)
Value: Image Feature
在Decoder Cross-Attention 中
Key: Image Features + Positonal Embeding==上面图的Spatial positional encoding(空间位置编码)
Value:Image Features
Query:可学习的query + Decoder Embeddings(初始化为全0)
在 Decoder Self-Attention
Key: 可学习的query + Decoder Embeddings(初始化为全0)
Value: 可学习的query + Decoder Embeddings(初始化为全0)
Query:可学习的query + Decoder Embeddings(初始化为全0)
参考:https://juejin.cn/post/7283691376649338916?searchId=20231214134247AA97C08F24DD7135C234#heading-1
Object Query
-
object queries是可学习的embedding,与当前输入图像的内容无关
-
object query可以看成是CNN 中动态的、可变的自适应anchor,每个query对应图像中的一个物体实例。因此,object query的数量一般设置要远大于数据库中一张图像内包含的最多物体数。论文设置的为100,使用COCO数据集
-
object query通过cross-attention(decoder)从编码器输出的序列中对特定物体实例的特征做聚合(即让该可学习object queries中的每个元素可以捕获原图像中不同位置与大小特征等的物体信息),又通过self-attention(encoder)建模该物体实例域其他物体实例之间的关系。
FFN
DETR在每个解码器层之后添加预测FFN和Hungarian loss,所有预测FFN共享其参数。
FFN 是一个最简单的多层感知机模块,对 Transformers decoder 的输出预测每个 object query的类别和位置信息.在实际训练的过程中,通过匈牙利算法匹配预测和标签最小的损失,仅适用配对上的query 计算 loss回传梯度.
二分图匹配
由于之前object queries 设置的为100。所以DETR 预测了一组固定大小的 N = 100 个边界框,这比图像中感兴趣的对象的实际数量大得多。为了解决这个问题,第一步是将 ground-truth 也扩展成 N = 100 个检测框。使用了一个额外的特殊类标签代表未检测到目标。得到预测和真实都是两个100 个元素的集合。
怎样判别预测框和真实框之间的差异?
采用匈牙利算法进行二分图匹配,即对预测集合和真实集合的元素进行一一匹配,使得匹配损失最小。
匹配成功之后,对预测框的分数、类别、中心点坐标和宽高进行损失值的计算。
为什么DETR不需要NMS
参考:https://www.zhihu.com/question/455837660/answer/3341680977
采用了Set prediction的方法,利用匈牙利算法获得candidates和ground-truth boxes的最优匹配后,再去计算loss。
优缺点
- 不需要anchor,不需要nms后处理。
- Transformer关注全局信息,能建模更加长距离的依赖关系,而CNN关注局部信息,全局信息的捕捉能力弱
收敛速度慢,训练时间长。在 COCO 数据集上,DETR 需要 500 个 epoch 才能收敛
小物体检测性能差。高分辨率的特征图为Transformer的Attention机制带来不可接受的计算复杂度和内存复杂度。
object query设置不合理,应该引入一部分位置信息
参考资料
https://zhuanlan.zhihu.com/p/376311764?utm_id=0 详细
https://juejin.cn/post/7283691376649338916?searchId=20231214134247AA97C08F24DD7135C234
https://blog.csdn.net/qq_54185421/article/details/125992305 损失函数