本例是俩个768×768的矩阵相乘的例子,代码来自《OpenCL异构并行计算》这本书,有修改。下文代码在VS2017和OpenCV430和OpenCL3的环境下开发和测试的,CPU型号是Intel Core i5-7400,用的是核芯显卡。代码里的kernel1是普通OpenCL代码计算乘法,kernel2是使用local内存优化的乘法。代码里也有OpenCV的矩阵乘法。总共3种方法用于对比效率。
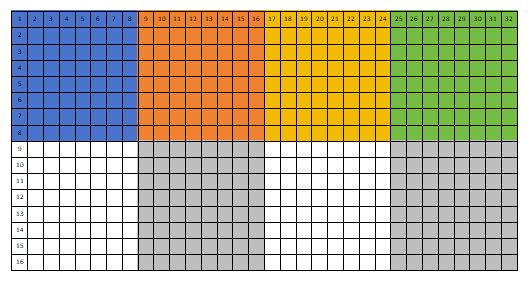
这里详细说明kernel2优化的代码执行流程。注意本说明不是下方代码功能的准确复述,而是一个流程描述。假如矩阵A是16行32列,矩阵B是32行16列,代码中设置一个工作组是8×8的大小。下图已把每个组标记成不同的颜色。那么外层for循环是移动8×8的运算块,第一次循环时加载的是A的蓝色块数据和B的蓝色块数据,第二次循环时加载的是A的橙色块数据和B的橙色块数据,第三次循环时加载的是A的黄色块数据和B的黄色块数据……而内层for循环是计算色块内部的每一个结果,即A的色块的一行乘以B的色块中的一列。因为有barrier(...)函数,所以内层for循环会在ta和tb数组中数据填充完成之后才计算乘积。待外层for循环结束之后内层for循环则把A的一整行乘以B的一整列的结果计算出来存入矩阵C中。
矩阵A示意图
矩阵B示意图

下面是程序运行输出的结果矩阵的样子。是灰色背景,加黑色文字IOU,符合预期:

CPP文件。注意代码中str2Kernel的work-item大小是(16,16),它的值应根据实际情况设置。如果设置的值过大可能会导致核函数无法执行,从而使输出矩阵C的数据全是错的:
int main() { int64 t1, t2; /* A是M行K列,B是K行N列,C是M行N列 */ std::string kernel1(R"CLC( kernel void func1(global float* a, global float* b, int M, int N, int K, global float *c) { int i = get_global_id(1); int j = get_global_id(0); float v = 0; for (int k = 0; k < K; k++) { v += a[i * K + k] * b[k * N + j]; } c[i * N + j] = v; })CLC"); std::string kernel2(R"CLC( #define BS 16 kernel void func2(global float* a, global float* b, int M, int N, int K, global float *c) { int by = get_group_id(1); int bx = get_group_id(0); int ty = get_local_id(1); /* 0~BS */ int tx = get_local_id(0); /* 0~BS */ local float ta[BS][BS]; local float tb[BS][BS]; int ab = K * BS * by; /* a的起始行 */ int ae = ab + K; /* a的行结尾 */ int bb = BS * bx; /* 列号 */ float v = 0; int i, j; for (i = ab, j = bb; i < ae; i += BS, j += BS * N) { ta[ty][tx] = a[i + ty * K + tx]; tb[ty][tx] = b[j + ty * N + tx]; barrier(CLK_LOCAL_MEM_FENCE); for (int k = 0; k < BS; k++) { v += ta[ty][k] * tb[k][tx]; } barrier(CLK_LOCAL_MEM_FENCE); } c[N * BS * by + ty * N + bx * BS + tx] = v; })CLC"); std::vector<std::string> funcStrings; funcStrings.push_back(kernel1); funcStrings.push_back(kernel2); cl::Program multiplyProgram(funcStrings); cl_int result = multiplyProgram.build("-cl-std=CL2.0"); if (result) { cl_int buildErr = CL_SUCCESS; auto buildInfo = multiplyProgram.getBuildInfo<CL_PROGRAM_BUILD_LOG>(&buildErr); for (auto &pair : buildInfo) { std::cerr << pair.second << std::endl << std::endl; } return 1; } Mat a = Mat::eye(768, 768, CV_32FC1) * 1.5; Mat b(768, 768, CV_32FC1, Scalar(0.5)); Mat c(768, 768, CV_32FC1); cv::putText(b, "IOU", Point(200, 400), FONT_HERSHEY_PLAIN, 18, Scalar(0), 12); cl::Buffer ia(a.ptr<float>(0), a.ptr<float>(0) + 768 * 768, true); cl::Buffer ib(b.ptr<float>(0), b.ptr<float>(0) + 768 * 768, true); cl::Buffer ic(c.ptr<float>(0), c.ptr<float>(0) + 768 * 768, false); t1 = getTickCount(); auto str1Kernel = cl::KernelFunctor<cl::Buffer, cl::Buffer, int, int, int, cl::Buffer>(multiplyProgram, "func1"); str1Kernel(cl::EnqueueArgs(cl::NDRange(768, 768)), ia, ib, 768, 768, 768, ic); cl::copy(ic, c.ptr<float>(0), c.ptr<float>(0) + 768 * 768); t2 = getTickCount(); qDebug() << u8"CL1(ms):" << (t2 - t1) / getTickFrequency() * 1000; imshow("c1", c); t1 = getTickCount(); auto str2Kernel = cl::KernelFunctor<cl::Buffer, cl::Buffer, int, int, int, cl::Buffer>(multiplyProgram, "func2"); str2Kernel(cl::EnqueueArgs(cl::NDRange(768, 768), cl::NDRange(16, 16)), ia, ib, 768, 768, 768, ic); cl::copy(ic, c.ptr<float>(0), c.ptr<float>(0) + 768 * 768); t2 = getTickCount(); qDebug() << u8"CL2(ms):" << (t2 - t1) / getTickFrequency() * 1000; imshow("c2", c); t1 = getTickCount(); c = a * b; t2 = getTickCount(); qDebug() << u8"CV3(ms):" << (t2 - t1) / getTickFrequency() * 1000; imshow("c3", c); return 0; }
以下是控制台输出文本。可以看出来使用local内存加速有较大作用。
CL1(ms): 43.5501 CL2(ms): 34.6158 CV3(ms): 296.618