本实验基于MRS环境,Impala部分主要介绍基本操作。假定用户开发一个应用程序,用于管理企业中的使用A业务的用户信息,使用Impala客户端实现A业务操作流程。Flink部分主要介绍如何实现Flink与Kafka的连接以满足实时计算场景应用。
购买MRS集群
选择“自定义购买”
区域:华北-北京四
集群名称:mrs
版本类型:普通版
集群版本:MRS 3.1.0 WXL
集群类型:自定义
勾选组件:Hadoop/Impala/Kafka/Flink/Zookeeper/Ranger
开启“拓扑调整”,勾选如下图位置所示的“DN, NM, B”。勾选所有节点上的Impalad服务
添加安全组规则,默认情况下华为云外部无法直接连接集群,我们需要放开安全组限制。
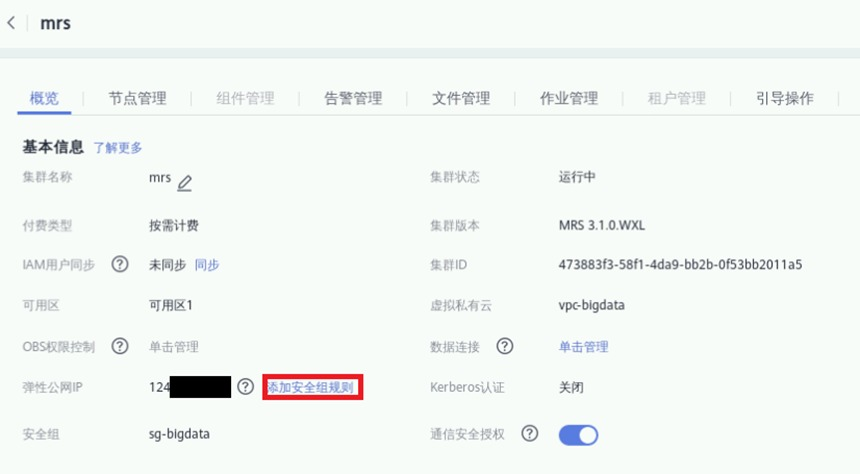
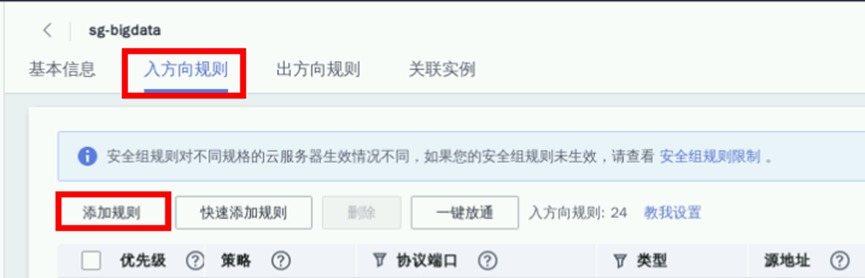
链接MRS集群
打开实验桌面的“Xfce终端”,使用ssh命令连接集群。
Impala实验
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。 它是一个用C++和Java编写的开源软件。 与其他Hadoop的SQL引擎相比,它拥有高性能和低延迟的特点。
2.1背景信息
假定用户开发一个应用程序,用于管理企业中的使用A业务的用户信息,使用Impala客户端实现A业务操作流程如下:
普通表的操作:
1.创建用户信息表user_info。
2.在用户信息中新增用户的学历、职称信息。
3.根据用户编号查询用户姓名和地址。
4.A业务结束后,删除用户信息表。
安装Impala客户端
在MRS集群详情页面,点击“前往Manager”
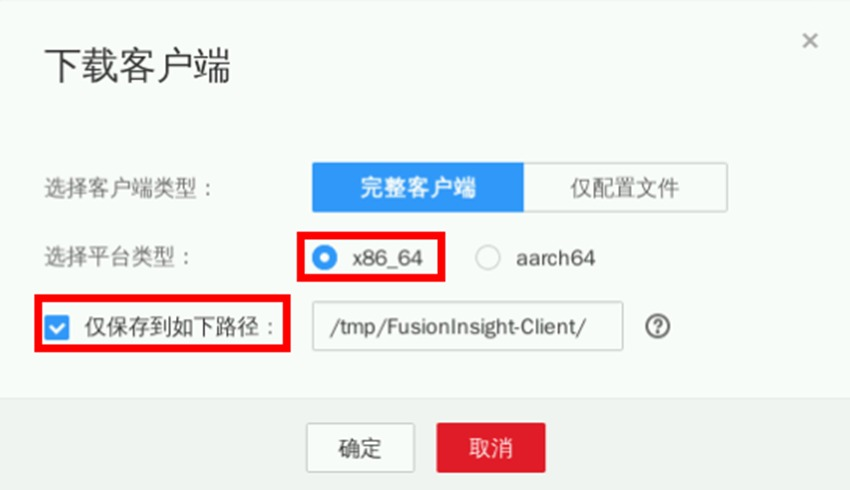
打开实验桌面的“Xfce终端”,使用ssh命令连接集群
进入Impala客户端下载目录并解压
cd /tmp/FusionInsight-Client/
tar -vxf FusionInsight_Cluster_1_Impala_Client.tar
tar -vxf FusionInsight_Cluster_1_Impala_ClientConfig.tar
安装Impala客户端至/opt/client目录
cd /tmp/FusionInsight-Client/FusionInsight_Cluster_1_Impala_ClientConfig
./install.sh /opt/client
切换到Impala安装目录并启动
cd /opt/client
source bigdata_env
impala-shell
退出Impala环境
quit;
创建用户信息数据
创建用户信息表user_info。
vi user_info
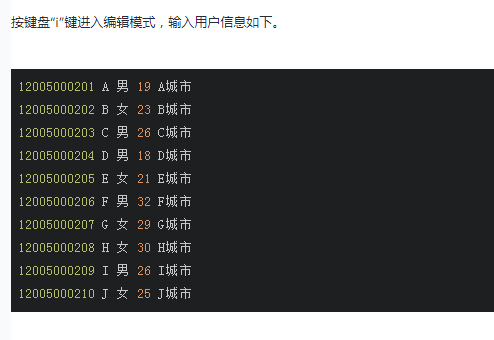
登录Impala客户端
运行Impala客户端命令
impala-shell
内部表的操作
创建用户信息表user_info并添加相关数据。
create table user_info(id string,name string,gender string,age int,addr string);
insert into table user_info(id,name,gender,age,addr) values ("12005000201","A","男",19,"A城市");
在用户信息表user_info中新增用户的学历、职称信息。
alter table user_info add columns(education string,technical string);
根据用户编号查询用户姓名和地址。
select name,addr from user_info where id='12005000201';
删除用户信息表。
drop table user_info;
外部表的操作
创建外部表。
create external table user_info(id string,name string,gender string,age int,addr string) partitioned by(year string) row format delimited fields terminated by ' ' lines terminated by '\n' stored as textfile location '/hive/user_info';使用insert语句插入数据。
insert into user_info partition(year="2018") values ("12005000201","A","男",19,"A城市");
执行以下SQL语句,查看数据插入成功。
select * from user_info;
退出Impala环境
使用load data命令导入文件数据
上传文件至hdfs。
hdfs dfs -put user_info /tmp
进入Impala环境
impala-shell
加载数据到表中。
load data inpath '/tmp/user_info' into table user_info partition (year='2018');
select * from user_info;drop table user_info;场景介绍
假定某个Flink业务每秒就会收到1个消息记录。基于某些业务要求,开发的Flink应用程序实现功能:实时输出带有前缀的消息内容。
安装JDK环境
wget https://sandbox-expriment-files.obs.cn-north-1.myhuaweicloud.com/hccdp/HCCDP/jdk-8u341-linux-x64.tar.gz下载完成后,运行下列命令进行解压:
tar -zxvf jdk-8u341-linux-x64.tar.gz
3新建Flink Maven工程
打开实验桌面的eclipse,点击“File->New->Project”
Group Id: com.huawei
Artifact Id: FlinkExample
修改JDK路径
右上角选择Window标签,在下拉菜单最后一栏中找到Preferences。
看到项目名称下有一个类似JRE System Library [J2SE-1.5]的标签。右键点击该标签,选择Build Path->Configure Build Path:
在新窗口点击Add Library
配置POM文件
打开“FlinkExample->pom.xml”文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.huawei</groupId>
<artifactId>FlinkExample</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<flink.version>1.12.0-hw-ei-310003</flink.version>
<flink.shaded.zookeeper.version>3.5.6-12.0</flink.shaded.zookeeper.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-zookeeper-3</artifactId>
<version>${flink.shaded.zookeeper.version}</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>huaweicloud2</id>
<name>huaweicloud2</name>
<url>https://mirrors.huaweicloud.com/repository/maven/</url>
</repository>
<repository>
<id>huaweicloud1</id>
<name>huaweicloud1</name>
<url>https://repo.huaweicloud.com/repository/maven/huaweicloudsdk/</url>
</repository>
</repositories>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
关闭pom.xml,下载第三方依赖程序包需要一定时间,预计约需5分钟左右。
开发程序
3.6.1创建程序包
在“src/main/java”处右键“new->package”
创建包FlinkDemo,点击“Finish”
创建类WriteIntoKafka
在上步FlinkDemo处右键点击,选择“New->Class”创建Java类WriteIntoKafka。
package FlinkDemo;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
public class WriteIntoKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
ParameterTool paraTool = ParameterTool.fromArgs(args);
DataStream<String> messageStream = env.addSource(new SimpleStringGenerator());
messageStream.addSink(
new FlinkKafkaProducer<String>(paraTool.get("topic"), new SimpleStringSchema(), paraTool.getProperties()));
env.execute();
}
public static class SimpleStringGenerator implements SourceFunction<String> {
private static final long serialVersionUID = 2174904787118597072L;
boolean running = true;
long i = 0;
public void run(SourceContext<String> ctx) throws Exception {
while (running) {
ctx.collect("element-" + (i++));
Thread.sleep(1000);
}
}
public void cancel() {
running = false;
}
}
}
程序打包
在FlinkExample右键,选择“Run As->Maven install”导出Jar包。
成功导出Jar包后,可以在target文件夹下找到FlinkExample-0.0.1-SNAPSHOT.jar
将FlinkExample-0.0.1-SNAPSHOT.jar上传至大数据集群/home/omm目录下
scp /home/user/eclipse-workspace/FlinkExample/target/FlinkExample-0.0.1-SNAPSHOT.jar root@xxx.xxx.xxx.xxx:/home/omm
安装Flink客户端
类似于Impala客户端安装,需要进入MRS Manager页面,找到对应Flink服务。
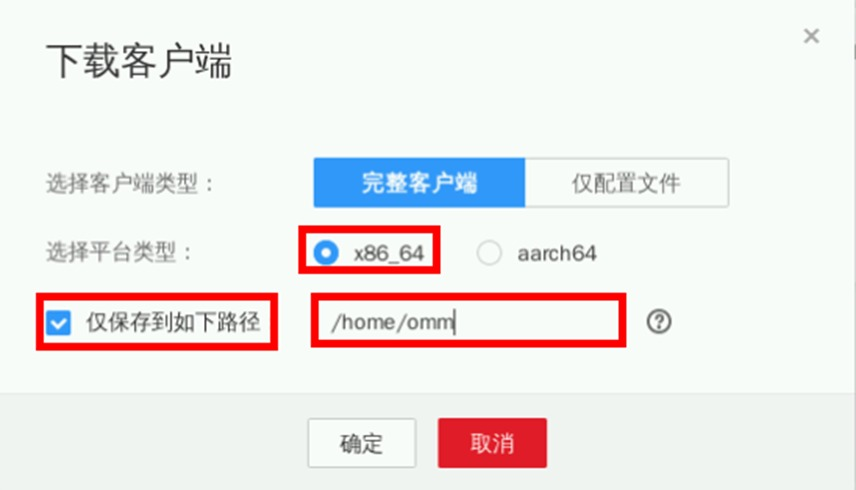
打开实验桌面的“Xfce终端”,使用ssh命令连接集群。
修改文件所属用户、用户组信息、操作权限
cd /home/omm
chown omm:wheel FlinkExample-0.0.1-SNAPSHOT.jar
chmod 777 FlinkExample-0.0.1-SNAPSHOT.jar
chmod 777 FusionInsight_Cluster_1_Flink_Client.tar
解压客户端
tar -vxf FusionInsight_Cluster_1_Flink_Client.tar
tar -vxf FusionInsight_Cluster_1_Flink_ClientConfig.tar
安装Flink客户端至/home/omm目录
cd FusionInsight_Cluster_1_Flink_ClientConfig
./install.sh /home/omm/FlinkClient
WriteIntoKafka程序运行
查询集群Kafka Broker信息
查询集群Zookeeper信息
创建kafka主题Topic
进入Kakfa客户端目录
cd /opt/Bigdata/components/FusionInsight_HD_8.1.0.1/Kafka/client/install_files/kafka/binchmod 777 kafka-topics.sh
chmod 777 kafka-run-class.sh
chmod 777 kafka-console-producer.sh
chmod 777 kafka-console-consumer.sh
创建Topic:
./kafka-topics.sh --create --zookeeper xxx.xxx.xxx.xxx:2181/kafka --topic FlinkTopic --replication-factor 2 --partitions 2查看topic
./kafka-topics.sh --list --zookeeper xxx.xxx.xxx.xxx:2181/kafkaWriteIntoKafka程序运行
创建Kafka消费者
新建Xfce终端窗口,登录集群。
cd /opt/Bigdata/components/FusionInsight_HD_8.1.0.1/Kafka/client/install_files/kafka/bin./kafka-console-consumer.sh --topic FlinkTopic --bootstrap-server xxx.xxx.xxx.xxx:9092 --from-beginning启动WriteIntoKafka作为Kafka生产者
新建Xfce终端窗口,登录集群
Flink应用处于安全性考虑,需要由非root用户启动
su omm
切换到Flink安装目录
cd /home/omm/FlinkClientsource bigdata_envflink run --class FlinkDemo.WriteIntoKafka /home/omm/FlinkExample-0.0.1-SNAPSHOT.jar --topic FlinkTopic --bootstrap.servers xxx.xxx.xxx.xxx:9092