1. 为什么要升维
升维的目的是为了去解决欠拟合的问题的,也就是为了提高模型的准确率为目的的,因为当维度不够时,说白了就是对于预测结果考虑的因素少的话,肯定不能准确的计算出模型。
在做升维的时候,最常见的手段就是将已知维度进行相乘来构建新的维度,如下图所示。下图左展示的是线性不可分的情况,下图右通过升维使得变得线性可分。

属于数据预处理的手段,在sklearn模块下它处于sklearn.preprocessing模块下。它的目的就是将已有维度进行相乘,包括自己和自己相乘,来组成二阶的甚至更高阶的维度。
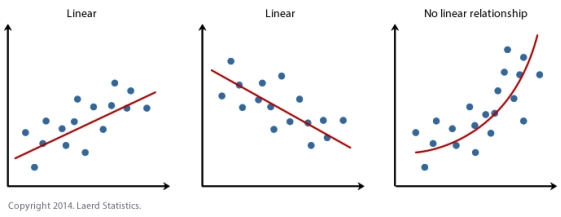
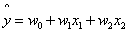
升维后
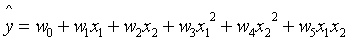
多项式升维PolynomialFeatures
2 代码实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
np.random.seed(42)
m = 100
X = 6 * np.random.rand(m, 1) - 3
y = 0.5*X**2 + X + 2 + np.random.randn(m, 1)
X_train = X[:80]
X_test = X[80:]
y_train = y[:80]
y_test = y[80:]
plt.plot(X, y, "b.")
# plt.show()
d = {1: "g-", 2: "r+", 10: "y*"}
for i in d:
poly_features = PolynomialFeatures(degree=i, include_bias=True)
X_poly_train = poly_features.fit_transform(X_train)
X_poly_test = poly_features.fit_transform(X_test)
# print(X_train[0])
# print(X_poly_train[0])
#
# print(X_train.shape)
# print(X_poly_train.shape)
line_reg = LinearRegression(fit_intercept=False)
line_reg.fit(X_poly_train, y_train)
y_train_predict = line_reg.predict(X_poly_train) # 训练集上的预测
y_test_predict = line_reg.predict(X_poly_test) # 测试集的预测
plt.plot(X_poly_train[:, 1], y_train_predict, d[i])
print(f"degree: {i}, 训练集mse:", mean_squared_error(y_train, y_train_predict))
print(f"degree: {i}, 测试集mse:", mean_squared_error(y_test, y_test_predict))
plt.show()
3, 总结
无论从下图,还是从上面的评估指标的对比,我们都可以发现使用多项式回归的时候,超参数degree很重要。当我们设置为1的时候欠拟合,当我们设置为10的时候过拟合,当我们设置为2的时候just right
过拟合:训练接表现ok 测试集表现不行
