第四章 并发编程
并行计算
是一种计算方案,它尝试使用多个执行并行算法的处理器更快速的解决问题
并行性与并发性
并行算法只识别可并行执行的任务。CPU系统中,并发性是通过多任务处理来实现的
线程
线程的原理
某进程同一地址空间上的独立执行单元
线程的优点
线程创建和切换速度更快
线程的响应速度更快
线程更适合并行运算
线程的缺点
线程需要来自用户的明确同步
库函数不安全
单CPU系统中,线程解决问题实际上要比使用顺序程序慢
线程操作
线程可在内核模式或用户模式下执行
其中涉及Linux下的pthread并发编程
线程管理函数
创建线程
使用pthread_create()
int pthread_create(pthread_t *pthread_id,pthread_attr_t attr,void (func)(void),void *arg)
注意:
1、pthread_id是指向pthread_t类型变量的指针
2、attr如果是NULL,将使用默认属性创建线程
线程ID
int pthread_equal(pthread_t t1,pthread_t t2);
不同的线程,返回0,否则返回非0
线程终止
int pthread_exit(void *status);
线程连接
int pthread_join(pthread_t thread,void **status_ptr)
线程示例程序
用线程计算矩阵的和
点击查看代码
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define ROWS 3
#define COLS 3
#define NUM_THREADS 3
int matrix[ROWS][COLS] = {{1, 2, 3}, {4, 5, 6}, {7, 8, 9}};
int sum = 0;
pthread_mutex_t mutex_sum;
void *calc_sum(void *thread_id) {
int tid = *(int*)thread_id;
int start_row = tid * ROWS / NUM_THREADS;
int end_row = (tid + 1) * ROWS / NUM_THREADS;
int local_sum = 0;
for (int i = start_row; i < end_row; i++) {
for (int j = 0; j < COLS; j++) {
local_sum += matrix[i][j];
}
}
pthread_mutex_lock(&mutex_sum);
sum += local_sum;
pthread_mutex_unlock(&mutex_sum);
pthread_exit(NULL);
}
int main() {
pthread_t threads[NUM_THREADS];
int thread_ids[NUM_THREADS];
pthread_mutex_init(&mutex_sum, NULL);
for (int i = 0; i < NUM_THREADS; i++) {
thread_ids[i] = i;
pthread_create(&threads[i], NULL, calc_sum, &thread_ids[i]);
}
for (int i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
}
pthread_mutex_destroy(&mutex_sum);
printf("The sum of the matrix is %d\n", sum);
return 0;
}

用线程快速排序
点击查看代码
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define N 10
typedef struct{
int upperbound;
int lowerbound;
}PARM;
int A[N]={5,1,6,4,7,2,9,8,0,3};
int print() // print current a[] contents
{
int i;
printf("[ ");
for (i=0; i<N; i++)
{
printf("%d ", A[i]);
}
printf("]\n");
}
void *qsort_1(void *aptr)
{
PARM *ap, aleft, aright;
int pivot, pivotIndex, left, right, temp;
int upperbound, lowerbound;
pthread_t me, leftThread, rightThread;
me = pthread_self();
ap = (PARM *)aptr;
upperbound = ap->upperbound;
lowerbound = ap->lowerbound;
pivot = A[upperbound];
left = lowerbound - 1;
right = upperbound;
if (lowerbound >= upperbound)
pthread_exit(NULL);
while (left < right)
{
do { left++;} while (A[left] < pivot);
do { right--;}while (A[right] > pivot);
if (left < right )
{
temp = A[left];
A[left] = A[right];
A[right] = temp;
}
}
print();
pivotIndex = left;
temp = A[pivotIndex];
A[pivotIndex] = pivot;
A[upperbound] = temp; // start the "recursive threads"
aleft.upperbound = pivotIndex - 1;
aleft.lowerbound = lowerbound;
aright.upperbound = upperbound;
aright.lowerbound = pivotIndex + 1;
printf("%lu: create left and right threads\n", me);
pthread_create(&leftThread, NULL, qsort_1, (void *)&aleft);
pthread_create(&rightThread, NULL, qsort_1, (void *)&aright);// wait for left and right threads
pthread_join(leftThread, NULL);
pthread_join(rightThread, NULL);
printf("%lu: joined with left & right threads\n", me);
}
int main(int argc, char *argv[])
{
PARM arg;
int i, *array;
pthread_t me, thread;
me = pthread_self();
printf("main %lu: unsorted array =" ,me);
print();
arg.upperbound = N-1;
arg.lowerbound = 0;
printf("main %lu create a thread to do QS\n", me);
pthread_create(&thread, NULL, qsort_1, (void *)&arg); // wait for QS thread to finish
pthread_join(thread, NULL);
printf("main %lu sorted array = ", me);
print();
}
线程同步
竞态条件:修改结果取决于线程执行顺序
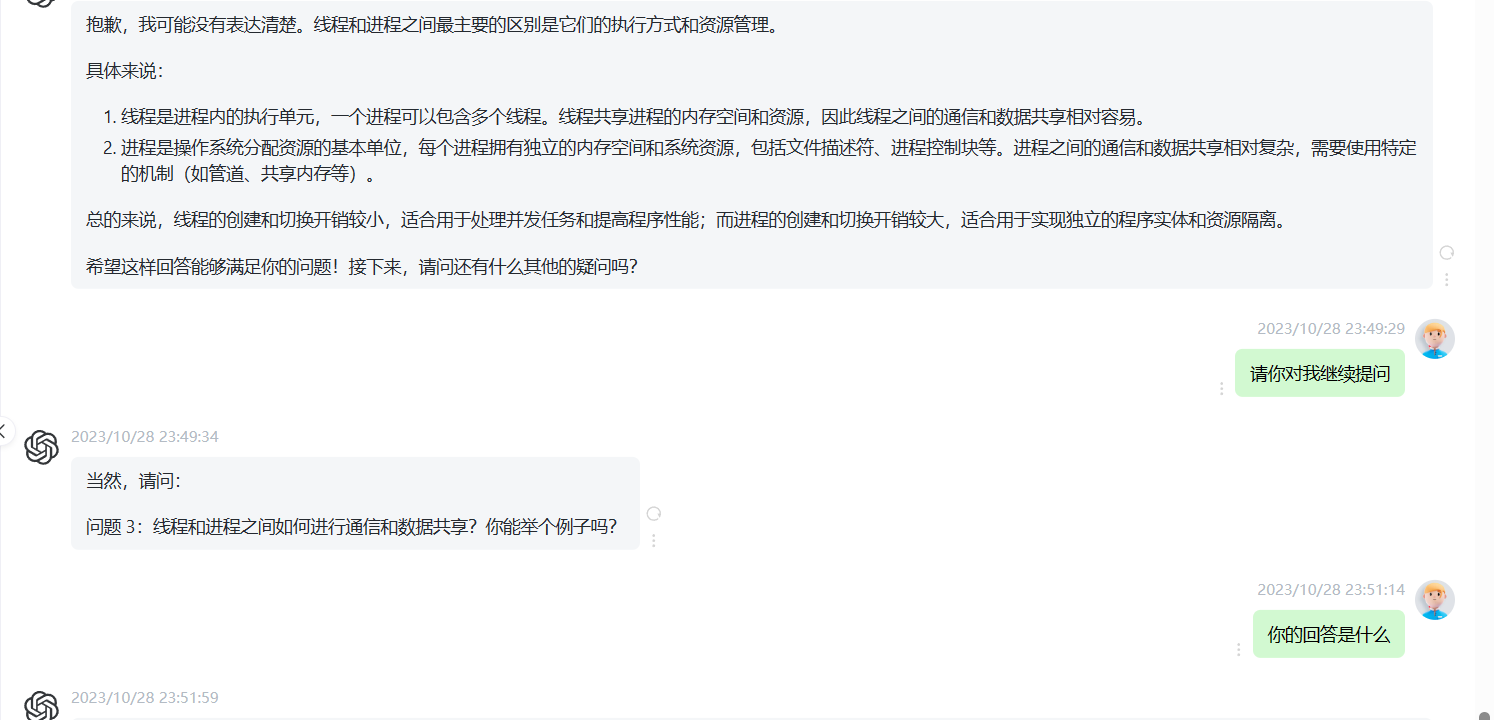
互斥量
在pthread中,锁被称为互斥量
pthread_mutex_lock(&m);
access shared data object;
pthread_mutex_unlock(&m);
示例
点击查看代码
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define N 4
int A[N][N];
int total = 0;
pthread_mutex_t *m;
void *func(void *arg)
{
int i, row, sum = 0;
pthread_t tid = pthread_self(); // get thread ID number
row = (int)arg; // get row number from arg
printf("Thread %d [%lu] computes sum of row %d\n", row, tid, row);
for (i=0; i<N; i++)
sum += A[row][i];
printf("Thread %d [%lu] update total with %d : Thread %d : ", row, tid, sum,row);
//pthread_mutx_lock(m);
pthread_mutex_lock(m);
total += sum;
pthread_mutex_unlock(m);
printf ("total = %d\n", total);
}
int main (int argc, char *argv[])
{
pthread_t thread[N];
int i, j, r;
void *status;
printf("Main: initialize A matrix\n");
for (i=0; i<N; i++)
{
//sum[i] = 0;
for (j=0; j<N; j++)
{
A[i][j] = i*N + j + 1;
printf("%4d ", A[i][j]);
}
printf("\n");
}
// create a mutex m
m = (pthread_mutex_t *)malloc(sizeof(pthread_mutex_t));
pthread_mutex_init(m, NULL); // initialize mutex m
printf("Main: create %d threads\n", N);
for(i=0; i<N; i++)
{
pthread_create(&thread[i], NULL, func, (void *)i);
}
printf("Main: try to join with threads\n");
for(i=0; i<N; i++)
{
pthread_join(thread[1], &status);
printf("Main: joined with %d [%lu]: status=%d\n",i, thread[i]/ (int)status);
}
printf("Main: tatal = %d\n", total);
pthread_mutex_destroy (m); // destroy mutex m
pthread_exit(NULL);
}
条件变量
条件变量可以通过两种方法进行初始化
静态方法
动态方法
生产者-消费者问题
共享全局变量
int buf[NBUF];
int head,tail;
int data;
点击查看代码
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define NBUF 5
#define N 10
// shared global variables
int buf[NBUF]; // circular buffers
int head, tail; // indices
int data; // number of full buffers
pthread_mutex_t mutex;
pthread_cond_t empty, full;
int init()
{
head = tail = data = 0;
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&full, NULL);
pthread_cond_init(&empty, NULL);
}
void *producer()
{
int i;
pthread_t me = pthread_self();
for (i=0; i<N; i++) // try to put N items into buf[]
{
pthread_mutex_lock(&mutex); // lock mutex
if (data == NBUF)
{
printf ("producer %lu: all bufs FULL: wait\n", me);
pthread_cond_wait(&empty, &mutex); // wait
}
buf[head++] = i+1;
head %= NBUF;
data++;
printf("producer %lu: data=%d value=%d\n", me, data, i+1);
pthread_mutex_unlock (&mutex);
pthread_cond_signal(&full);
}
printf("producer %lu: exit\n", me);
}
void *consumer()
{
int i, c;
pthread_t me = pthread_self();
for (i=0; i<N; i++)
{
pthread_mutex_lock(&mutex); // lock mutex
if (data == 0)
{
printf ("consumer %lu: all bufs EMPTY: wait\n", me);
pthread_cond_wait(&full, &mutex); // wait
}
c = buf[tail++]; // get an item
tail %= NBUF;
data--; // dec data by 1
printf("consumer %lu: value=%d\n", me, c);
pthread_mutex_unlock(&mutex); // unlock mutex
pthread_cond_signal(&empty); // unblock a producer, if any
}
printf("consumer %lu: exit\n", me);
}
int main ()
{
pthread_t pro, con;
init();
printf("main: create producer and consumer threads\n");
pthread_create(&pro, NULL, producer, NULL);
pthread_create(&con, NULL, consumer, NULL);
printf("main: join with threads\n");
pthread_join(pro, NULL);
pthread_join(con, NULL);
printf("main: exit\n");
}
屏障
线程连接操作允许某线程等待其他线程终止
在pthread中可以采用的机制是屏障以及一系列屏障函数
用并发线程解线性方程组
示例
点击查看代码
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <math.h>
#define N 4
double A[N][N+1];
pthread_barrier_t barrier;
int print_matrix()
{
int i, j;
printf("----------------------------\n");
for(i=0; i<N; i++)
{
for(j=0; j < N+1; j++)
printf("%6.2f ", A[i][j]);
printf("\n");
}
}
void *ge(void *arg) // threads function: Gauss elimination
{
int i, j, prow;
int myid = (int)arg;
double temp, factor;
for(i=0; i<N-1; i++)
{
if (i == myid)
{
printf("partial pivoting by thread %d on row %d: ", myid, i);
temp = 0.0; prow = i;
for (j=i; j<=N; j++)
{
if (fabs(A[j][i]) > temp)
{
temp = fabs(A[j][i]);
prow = j;
}
}
printf("pivot_row=%d pivot=%6.2f\n", prow, A[prow][i]);
if (prow != i) // swap rows
{
for (j=i; j<N+1; j++)
{
temp = A[i][j];
A[i][j] = A[prow][j];
A[prow][j] = temp;
}
}
}
// wait for partial pivoting done
pthread_barrier_wait(&barrier);
for(j=i+1; j<N; j++)
{
if (j == myid)
{
printf("thread %d do row %d\n", myid, j);
factor = A[j][i]/A[i][i];
for (int k=i+1; k<=N; k++)
A[j][k] -= A[i][k]*factor;
A[j][i] = 0.0;
}
}
// wait for current row reductions to finish
pthread_barrier_wait(&barrier);
if (i == myid)
print_matrix();
}
}
int main(int argc, char *argv[])
{
int i, j;
double sum;
pthread_t threads[N];
printf("main: initialize matrix A[N][N+l] as [A|B]\n");
for (i=0; i<N; i++)
for (j=0; j<N; j++)
A[i][j] = 1.0;
for (i=0; i<N; i++)
A[i][N-i-1] = 1.0*N;
for (i=0; i<N; i++)
{
A[i][N] = 2.0*N - 1;
}
print_matrix(); // show initial matrix [A|B]
pthread_barrier_init(&barrier, NULL, N); // set up barrier
printf("main: create N=%d working threads\n", N);
for (i=0; i<N; i++)
{
pthread_create(&threads[i], NULL, ge, (void *)i);
}
printf("main: wait for all %d working threads to join\n", N);
for (i=0; i<N; i++)
{
pthread_join(threads[i], NULL);
}
printf("main: back substitution :");
for (i=N-1; i>=0; i--)
{
sum = 0.0;
for (j=i+1; j<N; j++)
sum += A[i][N];
A[i][N] = (A[i][N]- sum)/A[i][i];
}
// print solution
printf("The solution is :\n");
for(i=0; i<N; i++)
{
printf("%6.2f ",A[i][N]);
}
printf("\n");
}
int clone(int (fn)(void),void *child_stack,int flags,void *arg)
问题及解决方法
信号量与条件变量的区别:
条件变量、互斥锁——主要用于线程间通信
pthread_cond_wait()
pthread_cond_wait(&m_cond,&m_mutex); 指的是等待条件变量,总和一个互斥锁结合使用。
pthread_cond_wait() 函数执行时先自动释放指定的互斥锁,然后等待条!
件变量的变化;在函数调用返回之前(即wait成功获得cond条件的时候),会自动将指定的互斥量重新锁住(即在“等待的条件变量满足条件时,会重新锁住指定的锁”)。
苏格拉底挑战
线程:



互斥量