多线程服务器常用的编程模型及适用场合
线程与进程
- 先区分下线程和进程的概念,一个进程是内存中正在运行的程序,每个进程都有自己独立的地址空间,Linux操作系统通过
fork()系统调用产生进程。 - 线程的特点是共享地址空间,从而可以高效地共享数据。一台机器上的多个进程能够高效地共享代码段(操作系统可以映射为同样的物理内存),但是无法共享数据。
- 多线程的价值在于能够发挥多核处理器的能力,单核多线程没有多大价值。
单线程服务器常用的编程模型
使用最广泛的为 non-blocking IO+IO multiplexing 模型,即 Reactor模式。比如在 lighttpd、libevent、java NIO、Netty 都使用了上述模型。
在 non-blocking IO+IO multiplexing 这种模型中,程序的基本结构是一个事件循环,以事件驱动和事件回调的方式实现业务逻辑。一般通过 select、poll、epoll 实现。

多线程服务器的常用模型
- 每个请求创建一个线程,使用阻塞式IO操作;
- 使用线程池,同样使用阻塞式IO操作,相比第一种性能有所提升;
- 使用
non-blocking IO+IO multiplexing,即Java NIO的方式; Leader/Follewer等高级模式。
一般会使用第三种方法,即 non-blocking IO+one loop per thread 模式,它的好处如下:
- 线程数目基本固定,可以在程序启动的时候设置,不会频繁创建与销毁;
- 可以很方便地在线程间调配负载;
- IO事件发生的线程是固定的,同一个TCP连接不必考虑事件并发;
这种模式中,Eventloop 代表线程的主循环,需要让哪个线程干活,就把 timer 或者 IO channel 注册到哪个线程的 loop 里即可。对于实时性要求高的连接可以单独用一个线程,数据量大的连接可以单独占用一个线程,并把数据处理任务分摊到几个计算线程(线程池);其它次要的辅助性连接可以共享一个线程。
一般使用时,每个连接都会注册到某个 event loop上,程序里有多个 event loop,每个线程至多有一个 event loop。
线程安全的线程池
实现一个线程池,我们需要通过 vector<std::thread> 来存储工作线程、一个存储任务的队列;同时还需要考虑线程安全,那么任务队列应该是一个线程安全的队列;其次如果发生了异常,应该立刻停止新任务的提交执行,但已经提交正在执行的任务需要等待执行完毕后再释放资源,所以需要用到 std::thread 的 join() 来等待所有执行线程的结束,所以我们需要合理安排资源析构函数的执行顺序。
// ThreadPool.h
#include"../../threadsafe_queue/theadsafe_queue.h"
#include"../joiner.h"
#include <vector>
#include <functional>
#include <thread>
namespace v1
{
using std::thread;
using std::vector;
using std::function;
using std::atomic;
class ThreadPool
{
public:
explicit ThreadPool(uint32_t threadNum = thread::hardware_concurrency()) : m_done(false), m_joiner() {
try
{
for (int i = 0; i < threadNum; i++)
{
m_threads.emplace_back(&ThreadPool::worker_thread, this);
}
}
catch (...)
{
m_done = true; //出现异常,第一时间设置 m_done 为true
throw std::runtime_error("thread create error");
}
}
~ThreadPool()
{
m_done = true; //析构时先将 m_done设为true,那么 worker_thread 会停止新任务的提交,正在执行任务的线程会继续执行;然后再优先析构m_joiner
}
template<typename FunctionType>
void Submit(FunctionType f)
{
m_queue.Push(function<void()>(f));
}
private:
void work_thread() //工作线程,不断取任务
{
while (!m_done)
{
function<void()> task;
if (m_queue.TryPop(task))
{
task();
} else
{
std::this_thread::yield(); //当前线程挂起,避免争抢资源
}
}
}
private:
atomic<bool> m_done; //非正常,抛出异常。必须保证 m_done 放在 m_joiner之前,防止任务还未执行结束 m_done已经从内存中释放,那么work_thread会导致段错误
util::ThreadSafeQueue<function<void()>> m_queue;
vector<thread> m_threads;
util::Joiner m_joiner;
};
}
//joiner.h
#include <thread>
#include <vector>
namespace util
{
using std::vector;
using std::thread;
class Joiner
{
public:
explicit Joiner(vector<thread> &thread) : m_threads(thread) {}
~Joiner() //析构时会依次调用 join 函数等待线程执行任务结束,防止因为异常导致线程资源泄漏
{
for (auto &&th : m_threads)
{
if (th.joinable())
{
th.join();
}
}
}
private:
vector<thread> &m_threads; //这里是左值引用,会影响到
};
}
上述代码实现了一个线程安全的线程池,其中 util::ThreadSafeQueue<function<void()>> m_queue 为自己封装的线程安全的任务队列,实现时有以下需要注意的点:
- 需要有任务发生意外的线程正常终止处理,代码中通过原子变量
atomic<bool> m_done保证多线程下的唯一性,当发生异常时,立即将该值置为true,表示线程池失效,此时任何线程不再拿取新任务;任务分派线程通过循环不断判断m_done的值,当线程池状态正常时从队列中取出任务执行,如果取不到任务,当前线程执行yield()挂起; - 状态异常时,已经提交运行的任务不可中断,需要通过
join()等待任务执行结束再回收线程资源,所以代码中采用了Joiner类的对象来等待资源回收。如果所有任务均执行完毕,此时执行析构函数,优先执行Joiner类析构函数,再执行m_threads的析构函数、m_queue的析构函数,最后是m_done析构。需要保证m_done变量在m_joiner之后析构,否则当task()执行完毕后会再回到while(!m_done),m_done先被析构会导致段错误。
进程间通信使用TCP
使用TCP而不是采用其它进程间通信的好处如下:
- TCP socket和 pipe 本质上都是操作文件描述符,都可以使用
select、poll;不同的是 TCP 是双向的,pipe是单向的,进程间通信还得开启两个文件描述符,不方便;并且进程间需要有父子关系才能使用 pipe; - TCP port由一个进程独占,并且操作系统会自动回收所有文件描述符。这样保证即使程序出现异常退出,也不会给系统留下垃圾,程序重启后能比较快速地恢复;
- 两个进程通信,一个崩溃了,操作系统会立刻断开连接,另一方能够快速感知;
- tcpdump、wireshark 等软件很方便解决进程间协议和状态争端,也是性能分析的利器;
- TCP连接是可再生的,这对开发分布式系统意义重大。
某些场景下使用TCP长连接:
- 长连接很容易定位分布式系统中服务之间的依赖,通过
netstat -anpt | grep :port查看某服务的客户端地址,然后通过ps -ef | grep pid查看具体的执行进程。 - 通过发送和接收队列长度定位网络故障。正常运行时,
netstat打印的Recv-Q、Send-Q都接近于0,或者在 0 附件摆动。如果Recv-Q保持不变或持续增加,就意味着服务端进程处理速度变慢,可能发生了死锁或阻塞;同理Send-Q保持不变或持续增加,可能是服务器来不及处理。

多线程服务器适用场合
如果在一台多核机器上提供服务,有以下四种模式:
- 运行一个单线程的进程; ———————— 无法发挥多核的计算能力
- 运行一个多线程的进程; ———————— 多线程难以编写
- 运行多个单线程的进程; ———————— a.简单把模式1复制多份;b.主进程+worker进程
- 运行多个多线程的进程; ———————— 无优势
必须使用单线程的场合
有两种场合必须使用单线程:
- 程序可能执行
fork(); - 需要限制CPU的占用率;
一般一个程序执行 fork() 后,要么执行 exec() 变身为另外一个程序,它通常用在集群中运行在计算节点上的负责启动 job 的守护进程;如果不调用 exec(),那么就变成了父子进程之间的通信。
单线程会限制CPU的占用率,比如在一个8核处理器上执行一个单线程程序,即使程序发生了故障,它的CPU使用率也只有12.5%,剩下的资源系统还是能够提供给其它服务进程使用。
区分多核和多CPU两种不同的处理器架构:
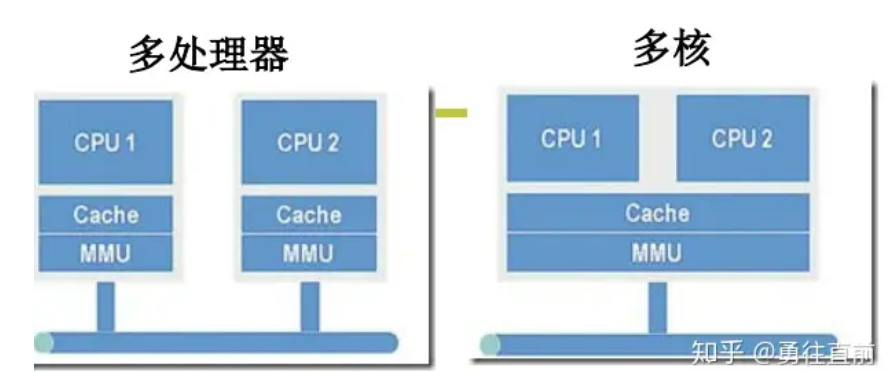
对于多核心的架构,由于共用一套MMU和cache,所以地址空间是一个,同一时刻只能运行一个进程,此时进程不能并行只能并发。同一个进程下的多线程可以并行执行,因为多线程共享同一套进程空间资源。但是对于多CPU架构,多进程可以并行。
适合多线程程序的场景
多线程的适合场景:IO和计算相互重叠,降低时延;多线程不能提高绝对性能,但是能提高平均响应性能。
一个程序做成多线程,需要满足:
- 多个CPU可用,发挥计算资源;
- 多线程间有共享数据,否则用模型3b即可;
- 提供非均质的服务,如事件响应有优先级差异,可以用专门的线程来处理优先级高的事件;
- 利用异步操作,比如 logging,无论是记录磁盘还是往log server发送消息,采用异步不阻塞主线程;
- 具有可预测的性能。并且随着负载增加,性能缓慢下降,到达某个临界点后会急速下降;
- 多线程划分责任和功能,不应该把所有逻辑塞到一个
event loop里面,不同类别的事件之间不应该相互影响。
多线程服务设计
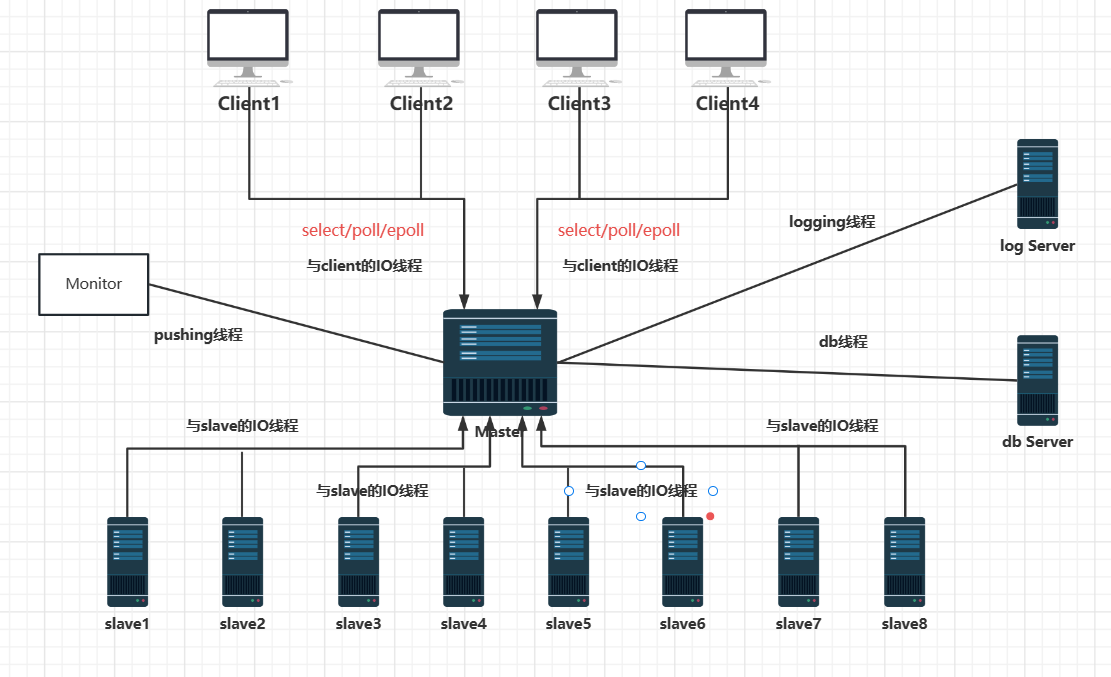
假设现在需要管理一个Linux服务器集群,集群中有8个计算节点,1个控制节点,双路四核CPU,现需要集群管理软件:
- 运行在控制节点上的master,监控整个集群系统的状态;
- 运行在每个计算节点上的slave,负责启动和终止job,监控本机资源;
- 供用户在使用的 client 命令行工具,用于提交 job。
设计:
- 运行在每个计算节点上的slave,充当看门狗进程,它会启动别的job进程执行计算任务,因此必须是个单线程程序,不应该占用太多资源;
- master应该采取模型2的多线程程序,如果它采用模型1,会浪费掉87.5%的CPU资源;整个集群状态完全放在内存中,状态间应该可以共享,如果用模型3,进程间同步会有问题;
- master的主要任务是降低处理延时,而不是提高吞吐量,它不会存在把IO或者CPU跑满的情况;
- master监控的事件有优先级区别,程序正常结束和出现异常崩溃优先级不同;
- master和每个slave之间用一个TCP连接,那么采用2个或者4个IO线程来处理8个TCP连接能有效降低延迟;
- master需要异步往本地硬盘写日志,这需要 logging library 有自己的IO线程;
- master可能需要读写数据库,第三方库有自己的线程,并回调 master 的代码;
- master服务于多个客户端,可以用2个IO线程来处理和客户端通信;
- master提供一个monitor接口,来广播推送集群的状态,避免了用户轮询,采用单独线程处理。
合计一共10个线程:
- 4个和slave通信的IO线程;
- 1个logging线程;
- 1个数据库IO线程;
- 2个和客户端通信的IO线程;
- 1个主线程,处理job调度;
- 1个广播线程,主动广播集群状态。
多线程模型中线程类型总结:
- IO线程,这类线程主循环是
IO multiplexing,阻塞等待select/poll/epoll_wait系统调用上,一些简单的计算如消息编码或解码也可放入其中; - 计算线程,主要循环是
blocking Queue,阻塞等待在条件变量condition variable上,这些工作线程一般放在线程池中,需要避免任何的阻塞操作; - 第三方库线程,如 logging、db connection。
一些问题










网络编程模型 Reactor
常见的网络编程模型主要有:Reactor、Proactor、Asynchronous、Completion Token、Acceptor Connector;
Reactor网络模型
https://zhuanlan.zhihu.com/p/93612337
https://www.zhihu.com/question/26943938/answer/1856426252