1 UUID 概述
1.1 UUID的定义
UUID(Universally Unique IDentifier)全局唯一标识符,用于标识信息元素,是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的。
通常平台会提供生成的API。按照开发软件基金会(OSF)制定的标准计算,用到了
以太网卡地址、纳秒级时间、芯片ID码和许多可能的数字
-
UUID是一种软件构建的标准,同时也为开放软件基金会组织在分布式计算环境领域的一部分。 -
UUID的作用是【让分布式系统中的所有元素,都能有唯一的辨识信息,而不需要通过中央控制端来做辨识信息的指定】。类似于我们的身份证是表明我们唯一身份的标识。如此一来,每个人都可以创建不与其它人冲突的UUID。在这样的情况下,就不需要考虑数据库创建时的名称重复问题。目前最广泛应用的UUID,是微软公司的全局唯一标识符(GUID Globally Unique IDentifier),而其它重要的应用,则有Linux ext2/ext3文件系统,LUKS加密分区、GNOME、KDE、Mac OS X等等。
-
UUID的标准形式包含32个16进制数字,被分为5个组,以4-4-4-12的形式显示。
- 当前日期和时间,UUID的第一个部分与时间有关,如果你在生成一个UUID之后,过几秒又生成一个UUID,则第一个部分不同,其余相同。
- 时钟序列
- 全局唯一的IEEE机器识别号,如果有网卡,从网卡MAC地址获得,没有网卡以其它方式获得
1.2 UUID的特点
- UUID具有以下特点:
- 唯一性:UUID的生成算法保证在同一时空中不会产生重复的ID,可以作为唯一标识符。
- 不可预测性:UUID的生成算法是基于随机数的,不可预测,可以用于防止信息泄露。
- 分布式:UUID的生成算法不依赖于中央管理机构,可以在分布式环境下使用。
在分布式环境中,使用UUID作为唯一标识符有一定的优势,因为UUID的生成算法不依赖于中央管理机构,不会产生冲突,也不需要进行同步操作。
- 长度较长(缺点):UUID的唯一缺陷在于生成的结果串会比较长。
但是,UUID的缺点是生成的ID比较长,占用存储空间比较大,不适合作为索引或数据库主键。
标准的UUID格式为: XXXXXXXX-XXXX-XXXX-XXXXXXXXXXXX(8-4-4-4-12(32位)),其中每个X是0-9或者a-f范围内的一个十六进制的数字,可以从cflib下载CreateGUID() UDF记性转换。
简单的UUID可以通过ColdFusion中的CreateUUID()函数很简单生成格式为: XXXXXXXX-XXXX-XXXX-XXXXXXXXXXXXXXXX(8-4-4-16)。
1.X 辨析:UUID(全局唯一标识符) vs. ID(数据库自增ID)
1.x.1 为什么UUID能够成为主键(Primary Key)?
其实在InnoDB存储引擎(Mysql)下,自增长的ID做主键性能已经达到了最佳。
不论是存储和读取速度都是最快的,而且占的存储空间也是最小的。
但是在我们实际的项目中会存在问题,历史数据表的主键id会与数据表的id重复,两张自增id做主键的表合并时,id一定会有冲突,但如果各自的id还关联了其他表,这就很不好操作了。
如果使用了UUID,生成的ID不仅是表独立的,而且还是库独立的。
对以后的数据操作很有好处,可以说是彻底解决了【历史数据】和【新数据】之间的冲突问题,这也是为什么UUID可以选择成为主键的原因,但是它也有缺点。
1.x.1 UUID的优点 vs. ID的缺点
- UUID
- 保证【全局唯一】:出现需要数据拆分、合并存储的时候,能够达到全局整体的唯一性
- 支持在【分布式系统】中使用
原因:每个节点都可以生成自己的UUID,而不需要与其他节点协调。
- ID
- ID可能会出现【重复】的情况,尤其是在分布式系统中。
- ID的生成顺序是递增的,这可能会导致某些行锁定,从而影响系统的【并发能力】。
1.x.2 UUID的缺点 vs ID的优点
-
UUID
- UUID比ID更长,需要更多的存储空间。(1个UUID就占用32位/4byte),一般会选择VARCHAR(36),若你建的索引越多,影响越严重)
- UUID生成的顺序是随机的,而ID生成的顺序是递增的。=> 这意味着: 在使用UUID作为主键时,数据表中的记录可能不会按照时间顺序排序,这可能会影响查询速度
- 影响插入(INSERT)速度
-
ID
- ID是一种自增长的整数,与UUID相比,ID更加【节省存储空间】(它只需要4个字节)
- ID的生成顺序是递增的,这意味着:数据表中的记录可按照时间顺序排序,这有助于【提高查询速度】
2 UUID的使用
2.1 UUID与Java
UUID.randomUUID().toString()是 java (JDK 1.5以上的版本)提供的一个自动生成主键的方法,它生成的是以为32位的数字和字母组合的字符,中间还参杂着4个-符号。
作用:它可以作为数据库表的标识列来增加,比序列增长更加方便。当然还可以用来拼接作为路径,或者图片的前缀名等等。
- Java中可以使用
java.util.UUID类来生成UUID:
JDK 1.5 +
@Test
public void uuidTest(){
//jdk1.5+
UUID uuid = UUID.randomUUID();
System.out.println(uuid.toString());
// out: 5a0c3541-4be1-424f-bc4a-4addbcd62328
}
2.2 UUID与MySQL
2.2.1 UUID做唯一主键的注意事项
- 如果是主从即M-S模式,最好是不使用mysql自带函数UUID来生成唯一主键
- 因为主表生成的UUID要再关联从表时:需要再去数据库查出这个UUID,需要多进行一次数据库交互,且在这个时间差里面主表很有可能还有数据生成,这样就很容易导致关联的UUID出错。
- 如果真要使用UUID,可以在服务端中生成后,直接存储到DB里,这时主从的UUID就是一样的了。
2.2.2 UUID做为表主键的最佳实践方案
- InnoDB引擎表是基于B+树的索引组织表
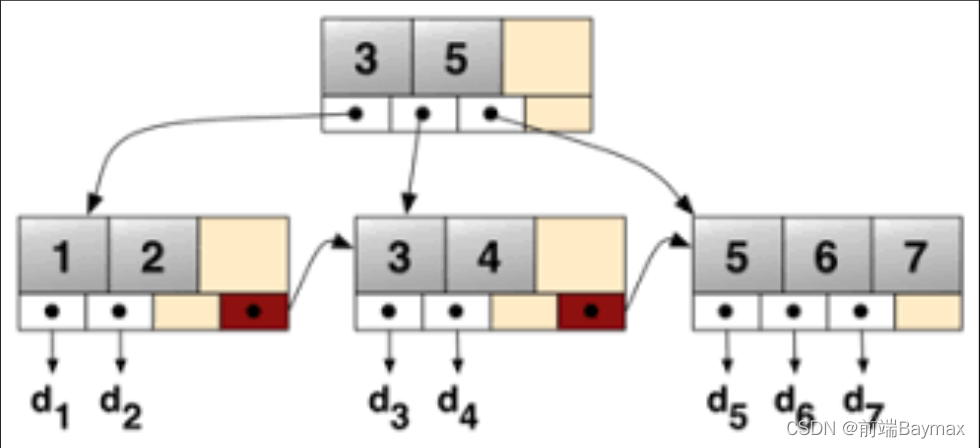
-
B+树: B+树是为磁盘或者其他直接存取辅助设备而设计的一种平衡查找树,在B+树中,所有记录节点都是按健值的大小顺序存放在同一层的叶节点中,各叶节点指针进行连接。
-
InnoDB主索引: 叶节点包含了完整的数据记录。这种索引叫做聚焦索引。InnoDB的索引能提供一种非常快速的主键查找性能。不过,它的辅助索引也会包含主键列,所以,如果主键定义的比较大,其他索引也将很大。如果想在表上定义很多索引,则争取尽量把主键定义得小一些。InnoDB不会压缩索引。
-
聚焦索引这种实现方式使得按照主键的搜索十分高效,但是辅助索引需要检索两遍索引: 首先检索辅助索引获得主键,然后用主键道主索引中检索获得记录。
-
方案:
如果InnoDB表的数据写入顺序能和B+树索引的叶子节点顺序一致的话,这时候存取效率是最高的。为了存储和查询性能应该使用自增长ID做主键。
对于InnoDB的主索引,数据会按照主键进行排序,由于UUID的无序性,InnoDB会产生巨大的IO压力,此时不适合使用UUID做物理主键,可以把它作为逻辑主键,物理主键依然使用自增ID。为了全局的唯一性,应该使用UUID做索引关联其他表或者做外键。
-- ID继续为主键, UUID为外键
CREATE TABLE `system_roles` (
`id` INT(11) NOT NULL AUTO_INCREMENT COMMENT "序号",
`rid` VARCHAR(36) DEFAULT NULL COMMENT "角色UUID",
`name` VARCHAR(64) DEFAULT NULL COMMENT "角色名",
`describe` VARCHAR(64) DEFAULT NULL COMMENT "角色描述",
`status` BOOLEAN DEFAULT true COMMENT "角色状态",
`created_at` datetime DEFAULT NULL COMMENT '创建时间',
`updated_at` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`),
FOREIGN KEY (`rid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;