一、目标
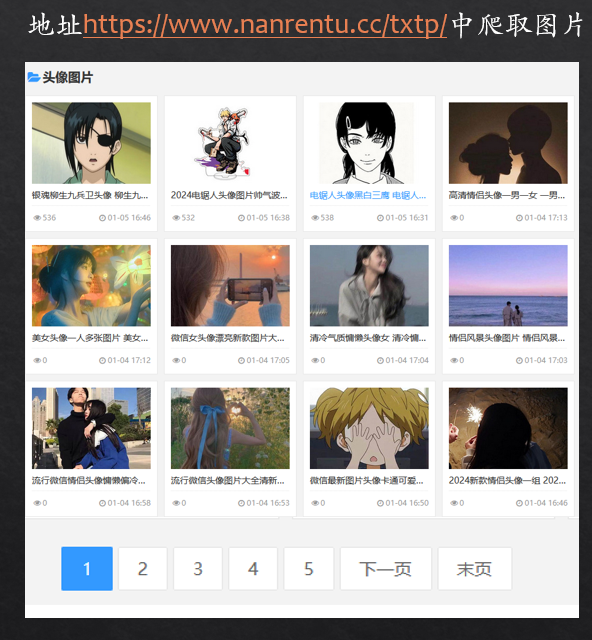
1、把头像图片下载到本地中:https://www.nanrentu.cc/txtp/
2、根据每个组的标题创建文件夹,并把每组中的全部头像图片放到对应的文件夹中
二、思路
1、首先要先分析网页结果,通过分析发现,文件的名称其实就在<ul class = "h-piclist">标签下的ul中,所以就可以通过对网页发起get请求,然后创建bs4来获取链接和文件名称了

2、根据bs4处理后,通过find("tag",class= "值")来获取整个ul下的内容,在调用.findall(“a”)获取a标签下的所有数据
# -*- coding: utf-8 -*- #1、导包 import requests import os from bs4 import BeautifulSoup #2、发起请求 url = "https://www.nanrentu.cc/txtp/page_1.html" hearder = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:120.0) Gecko/20100101 Firefox/120.0" } req = requests.get(url=url,headers=hearder) soup = BeautifulSoup(req.text,'lxml') a_list = soup.find('ul',class_ = 'h-piclist').findAll('a') for a in a_list: name = a['title'] hrefs =a['href']
print(name + hrefs)
#打印结果如下

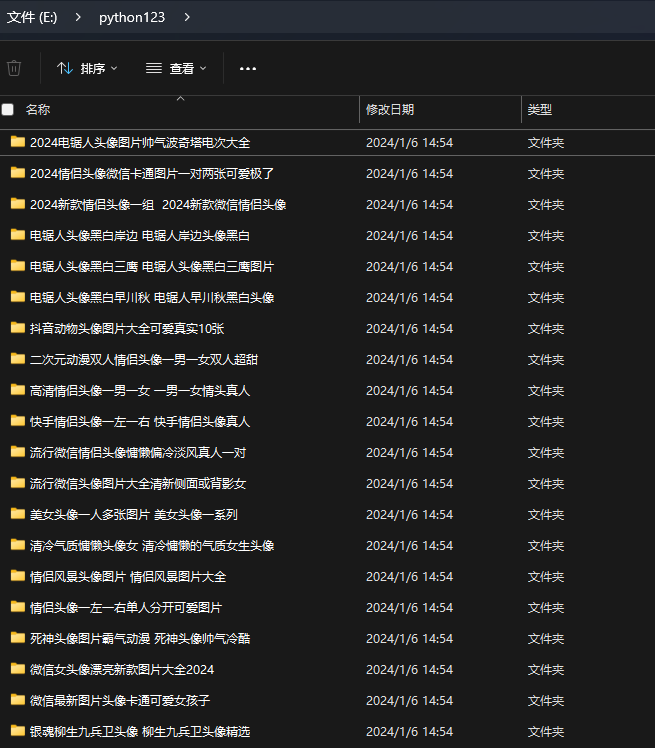
3、获取到文件夹的名称后,
1)下面需要利用os模块批量创建文件
for a in a_list: name = a['title'] hrefs =a['href'] #创建文件夹 file_path = r'E:\python123\\' dir_name = file_path + name if not os.path.exists(dir_name): os.mkdir(dir_name)
2)对获取的href链接再次发起,把每个链接中的图片src拿到并获取内容保存到对应文件夹中:

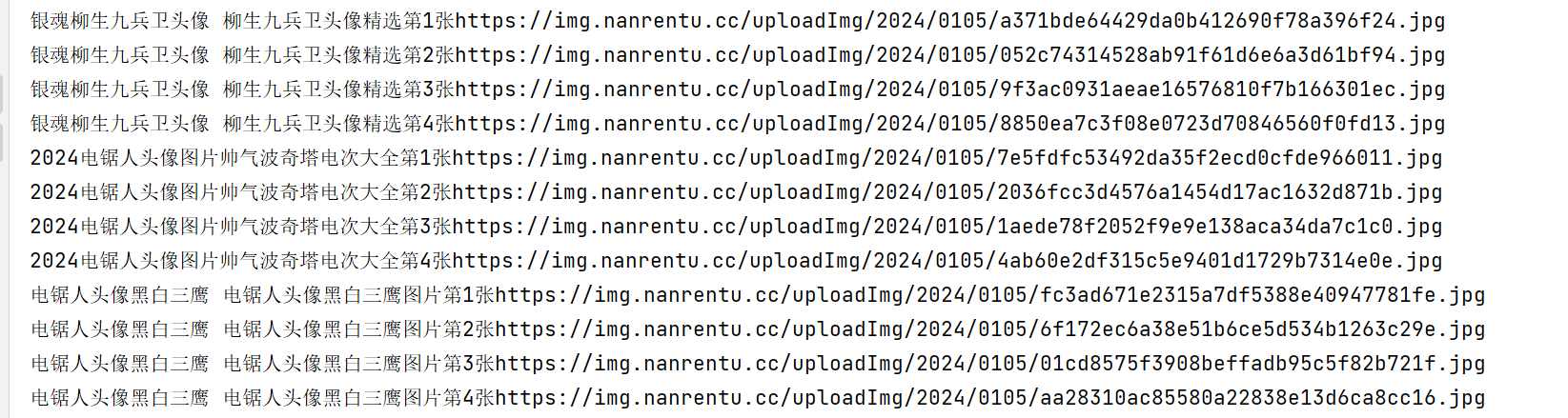
child_html = requests.get(url=hrefs,headers=hearder) child_soup = BeautifulSoup(child_html.text,'lxml') child_img_list = child_soup.find('div',class_="info-pic-list").findAll('img') for child_img in child_img_list: pic_name = child_img['alt'] pic_src = child_img['src'] print(pic_name + pic_src)
运行后如下:
for child_img in tqdm(child_img_list): pic_name = child_img['alt'] pic_src = child_img['src'] print(pic_name + pic_src) #保存数据 with open(dir_name + "/" + pic_name + ".jpg" ,mode='wb')as f : f.write(requests.get(pic_src).content) print(pic_name + "下载完成") f.close()
至此,图片就会保存到对应的文件夹中了
补充:为了下载有进度条,看起来更加优雅美观,在for i in tqmd(xxx)循环中加上tqdm即可
from tqdm import tqdm
三、过程【完整代码】
# -*- coding: utf-8 -*- #1、导包 import requests import os from bs4 import BeautifulSoup from tqdm import tqdm #2、发起请求 url = "https://www.nanrentu.cc/txtp/page_1.html" hearder = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:120.0) Gecko/20100101 Firefox/120.0" } req = requests.get(url=url,headers=hearder) soup = BeautifulSoup(req.text,'lxml') a_list = soup.find('ul',class_ = 'h-piclist').findAll('a') for a in tqdm(a_list): name = a['title'] hrefs =a['href'] #3、创建文件夹 file_path = r'E:\python123\\' dir_name = file_path + name if not os.path.exists(dir_name): os.mkdir(dir_name) child_html = requests.get(url=hrefs,headers=hearder) child_soup = BeautifulSoup(child_html.text,'lxml') child_img_list = child_soup.find('div',class_="info-pic-list").findAll('img') for child_img in tqdm(child_img_list): pic_name = child_img['alt'] pic_src = child_img['src'] print(pic_name + pic_src) #4、保存数据 with open(dir_name + "/" + pic_name + ".jpg" ,mode='wb')as f : f.write(requests.get(pic_src).content) print(pic_name + "下载完成") f.close()
四、总结
1、以上代码还存在点问题,后续有时间再优化