前言
在17年,自然语言处理领域还在被RNN统治,当时的seq2seq任务还是用带encoder-decoder结构的RNN。然而RNN天然具有一个缺点:计算效率低。
随后的transformer也是encoder-decoder结构,但是其中信息关联采用了attention机制,而不是RNN的循环机制。
transformer一经提出,就横扫了以往的各种RNN变体,随后,人工智能社区陷入了万物transformer的时代,甚至引领了cv领域一段时间。
随后因为transformer(实际上是其中的attention)计算效率高,能极大缩短训练时间,大公司开始搜集更多的数据,用更多的算力,去训练更大的transformer,结果不经意间开启了大模型时代。目前的LLM几乎都是transformer的变体,通过学习transformer来入门大模型是很自然的。
这篇笔记从以下几个方面详细介绍transformer:
- 什么是seq2seq?
- 什么是attention,attention到底比RNN好在哪?
- 把transformer看成黑盒,训练任务是什么?
- transformer模型结构:
- word embedding && positional embedding
- self-attention && multi-head attention && cross attention
- layer normalization
- FFN|MLP
- 论文中的一些笔记
背景
什么是seq2seq?
在现实世界,有一种场景,输入一个长度为$l_i$的序列,输出一个长度$l_j$的序列。
在NLP中,一段话按照单词为单位转换成一个序列。
例如,翻译任务:”机/器/学/习“ -> ”machine/learning“,长度为4的序列被翻译成了长度为2的序列;或者对话,”太/阳/从/哪/边/升/起“->”东/边“,输入长度为7的序列,输出长度2的序列。
这类任务就被称为seq2seq任务,这类模型也可以称为seq2seq模型。
为什么要划分出这类任务,自然是因为传统的模型不能处理不等长度的序列。简单说明一下,典型的神经网络如下图,这里把每个单词变成一个数值$x_i$,要训练的参数是输入结点和中间结点之间的权重$w_{ij}$。如果输入结点增加,就会多出来一些未知参数。
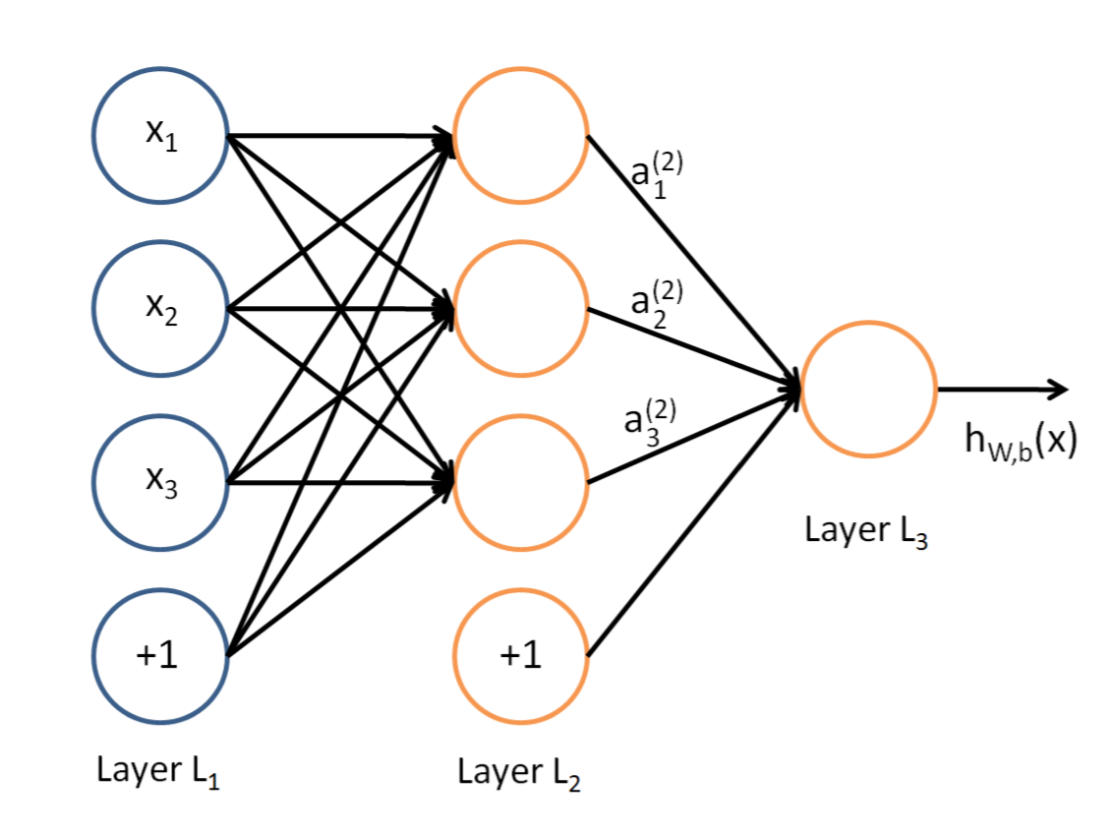
为了解决这个问题,不把单词看成数值,而是变成固定长度$d$的向量$\bold{x}_i$。这样就可以把一段$l$个单词的句子看成$X=[\bold{x}1,...,\bold{x}]^T \in R^{l\times d}$,然后全连接层的权重就是$W^{d\times d}$,这样全连接层就是每个单词(一个向量)依次进行线性变换。
我们知道序列之间存在着相互关系,例如一个单词的含义在不同的句子中可能也会不同。上面的简单的全连接中,单词之间是完全独立的,不会进行信息交换,所以也就不会捕获序列中单词之间的关系。
怎么捕获单词之间的关系——RNN
循环神经网络(Recurrent Neural Networks, RNN)提供了一种方法。如下图所示。
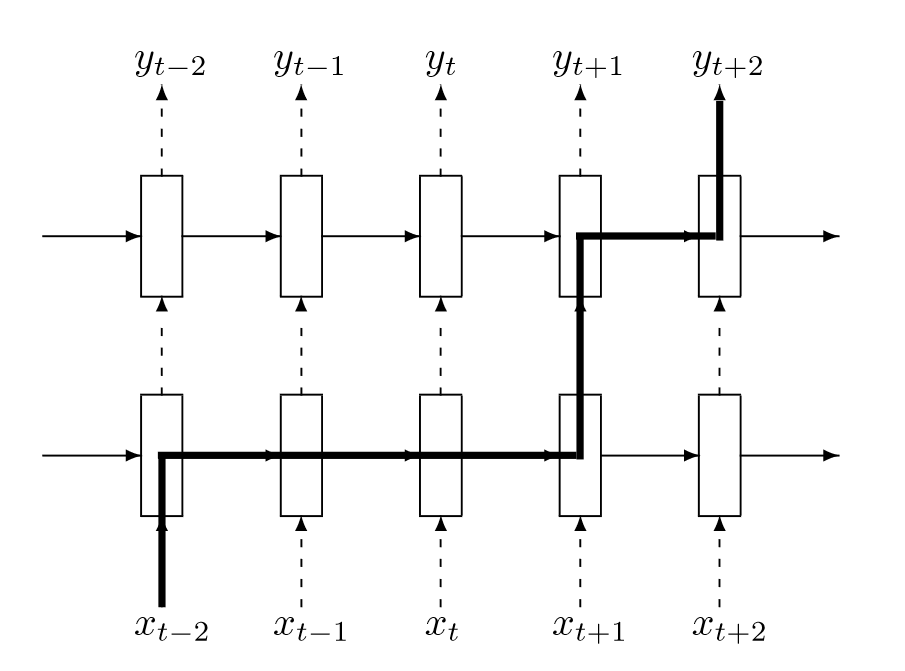
每个单词(向量)在处理时,还要接受上一个单词处理后的中间结果。这样每个单词都能获得前面所有单词的信息。然后为了能处理变长序列,上面每层模块共享参数,或者说就是同一个模块。有关RNN的讲解,我是看的完全解析RNN, Seq2Seq, Attention注意力机制 - 知乎 (zhihu.com)。
上面的模型只是能处理变长的序列,但是并不能处理seq2seq任务,因为上面的模型明显只能输出等长的序列。想要做seq2seq,需要调整成下面的结构。
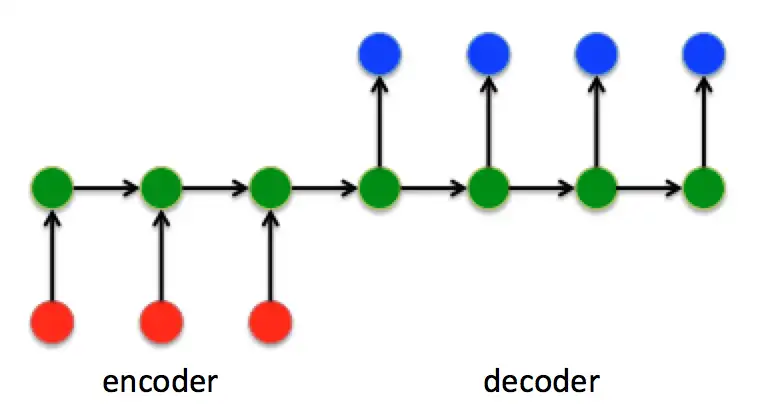
举个例子:”机/器/学/习“->”machine“,在预测”machine“的时候,参考了”机/器/学/习“的信息,随后预测”learning“,模型接下来还会预测,预测到”“符号,表示预测终止。
RNN的缺点
基于RNN的encoder-decoder模型(简称RNN)虽然可以处理seq2seq任务,但是有很多缺点:
- RNN基于时序,并行性差。也就是要一个个去处理单词。
- 容易丢失远距离的信息。单词信息在链上会逐渐衰减。
当时有工作采用了CNN的方式来解决”丢失远距离信息“的问题,但是在长序列上,CNN需要增加卷积层才能看到整个序列。
Transformer
Attention
参考大佬的文章动图轻松理解Self-Attention(自注意力机制) - 知乎 (zhihu.com)。
我这里描述一下过程:
现在有一个序列$X=[\bold{x}1,...,\bold{x}]^T \in R^{l\times d}$,这些token(就是单词对应的向量)经过三个线性变换映射成三个序列:$Q=XW_q,K=XW_k,V=xW_v$,其中$W_q,W_k,W_v\in R^{d\times d}$,因此$Q,K,V\in R^{l\times d}$。
然后计算$Softmax(\frac{QK^T}{\sqrt{d}})$得到一个得分矩阵$S\in R^{d\times d}$。得分矩阵中的元素$s_{ij}$表示$q_i$和$k_j$之间的相似度,这个相似度是用$q_ik_j^T$计算得到的。这个值越高,就表明$x_i$与$x_j$的关系较紧密,那么当我们处理$x_i$时,就要多考虑$x_j$。怎么多考虑,就是把这个得分当作是权重,也就是$S·V\in R^{l\times d}$。这个结果$V_{out}$还要再经过一个全连接层,也就是$V_{out}W_o+b_o$
上面线性代数的部分,如果基础不牢很容易看不懂,我当时就没看懂。可以参考我下面一篇文章,会详细进行计算。
attention的计算可以并行。因此极大提高了计算效率。总的来说,在并行时间内,只做了四个矩阵计算。
模型结构
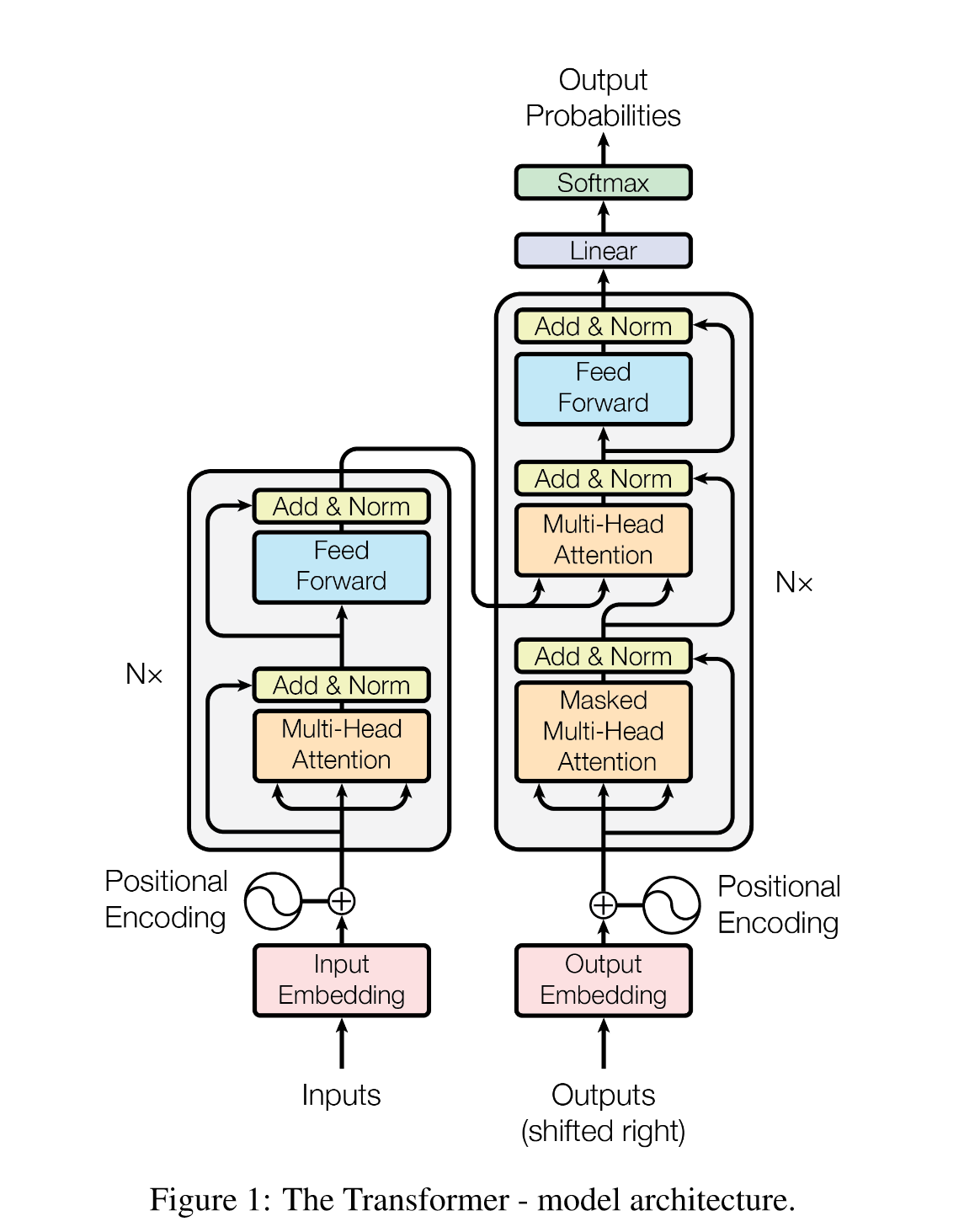
未完待续,写不动了真难写
备注:
| 机制 | Why&&How? |
|---|---|
| word2vec | 不是本论文提出的,目前主流方式是word embedding,与one-hot不同的是,隐含了不同词汇之间的关联关系。 |
| positional encoding | self-attention不能表示序列之间的顺序信息,因此在每个vector上加上位置编码,有多种位置编码。为什么会起作用?搜索‘归纳偏置’ |
| self-attention | self指query和key-value都仅依靠input。self-attention的作用是关联目前词和序列中所有的词信息。 |
| multi-head attention | 模拟了CNN中多通道的概念,可以抽象的理解为,每个attention识别了一个pattern。 |
| masked multi-head attention | 使用了掩码,这是由于该模型中的decoder是按顺序进行预测。 |
| Add&&Norm | Add是残差连接,防止网络退化,让网络仅关注数据变化的部分。Norm是layer normalization,和batch normalization不同的是,变化的序列长度也可以很好的计算。 |
| socre归一化 | 相似度计算需要除以 |
参考资料:
[1409.2329] Recurrent Neural Network Regularization (arxiv.org)