Learning A Single Network for Scale-Arbitrary Super-Resolution

abstract
现有的single image SR网络是为具有特定整数比例因子(例如,×2/3/4)的图像开发的,无法处理非整数和非对称 SR。
在本文中,作者建议从特定比例的网络中学习任意比例的图像 SR 网络。
introduction
由于上采样模块中的固定过滤器,大多数现有网络只能放大具有特定整数比例的图像,无法处理现实世界场景中的任意比例 SR。
在本文中,作者建议从特定比例的网络中学习任意比例的单图像 SR 网络。具体来说,作者为现有的 SR 网络开发了一个插件模块,以实现任意尺度的 SR,它由多个尺度感知的特征自适应块和一个尺度感知的上采样层组成。
尺度感知特征适配块用于使主干中的特征适应特定尺度因子,尺度感知上采样层用于尺度任意上采样。在作者的插件模块中,条件卷积(conditional convolution)用于生成动态比例感知过滤器(dynamic scale-aware filters)以处理不同的比例因子。
主要贡献:
- 作者为现有的 SR 网络开发了一个插件模块,以实现任意尺度的 SR,包括多个尺度感知特征自适应块和一个尺度感知上采样层。
- 作者的插件模块使用条件卷积根据输入的尺度信息动态生成过滤器,这有助于作者的网络适应特定的尺度因子。
related work
Single Image Super-Resolution
下面两篇文章通过分别引入通道注意力和二阶通道注意力进一步提高了特定尺寸SR的性能。
-
Image super-resolution using very deep residual channel attention networks
-
Second-order attention network for single image super-resolution.
Meta-SR使用元学习来预测不同比例因子的过滤器权重。
- Meta-SR: A magnification-arbitrary
network for super-resolution.
然而,Meta-SR 在主干特征学习过程中并没有利用尺度信息的好处。
为了更好地利用尺度信息,Fu引入了一个残差尺度注意网络(RSAN),其中尺度信息被用作先验知识来学习判别特征以获得卓越的性能。
- Residual scale attention network for arbitrary scale image super-resolution.
尽管 Meta-SR 和 RSAN 能够超分辨具有非整数比例因子的图像,但它们无法处理非对称 SR。
Conditional Convolutions
与传统的具有静态过滤器的卷积层不同,条件卷积将其过滤器的参数化,以输入为条件,作为几个专家的线性组合。
Different from traditional convolutional layers with static filters, conditional convolutions parameterize their filters conditioned on the input as linear combinations of several experts.
在本文中,作者扩展了条件卷积的概念,以生成动态的尺度感知滤波器来处理尺度任意的SR任务。事实证明,条件卷积有助于作者的网络适应任意规模的因素,从而实现更好的SR性能。
methodology
motivation
由于不同尺度因子的SR任务是相互关联的,从特定尺度的网络(如×2/3/4)中学习一个任意尺度的SR网络是非难事。早期的尝试在骨干网中使用共享特征来处理多个尺度因子,在特征学习过程中不考虑尺度信息。
直观地说,由于各种比例因子的退化是不同的,因此可以进一步使用比例信息来学习判别特征以提高 SR 性能。在本节中,我们研究了 ×2/3/4 SR 任务之间的关系,以提供对任意尺度 SR 的见解。
我们进行实验以比较预训练×2/3/4 SR 网络中特定层的特征相似性。

特征相似度图\(S_{i}\)在下图中被可视化:

从图 2 可以看出,不同块和区域的特征相似度不同。也就是说,对于不同的块和区域,特征对比例因子变化的敏感度是不同的。
因此,我们有动力相应地执行像素级特征自适应。
对于特征相似度高的区域内的特征,可以直接用于具有任意比例因子的SR。相反,低特征相似性区域内的特征适应特定的比例因子.
Our Plug-in Module
模块的架构如图 3 所示。
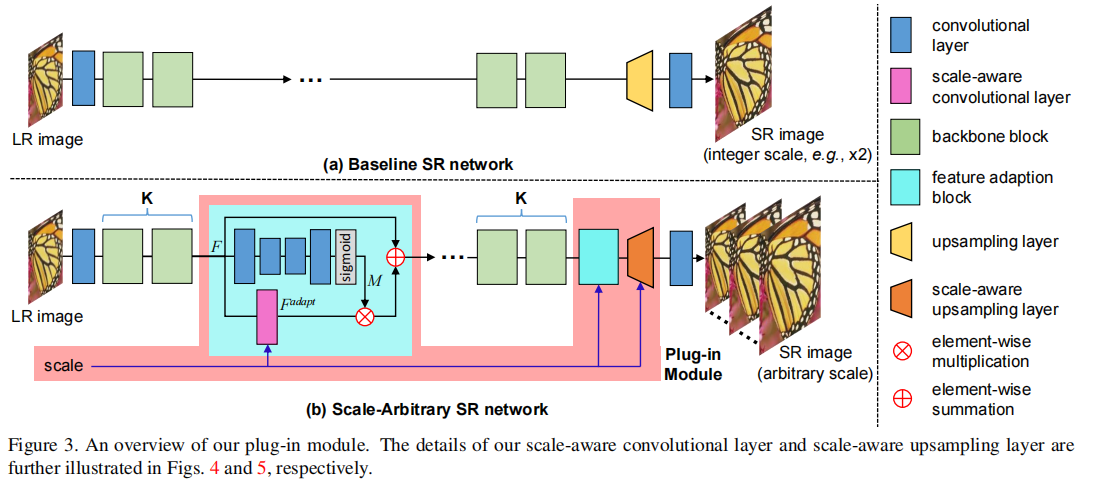
给定为具有整数比例因子的 SR 开发的基线网络(例如 EDSR),我们可以使用我们的插件模块将其扩展到任意比例的 SR 网络。
具体来说,在每 K 个骨干块之后执行尺度感知特征自适应(scale-aware feature adaption),如图 3(b)所示。在骨干模块之后,一个尺度感知上采样层(scale-aware upsampling layer)用于任意尺度上采样。
Scale-Aware Feature Adaption
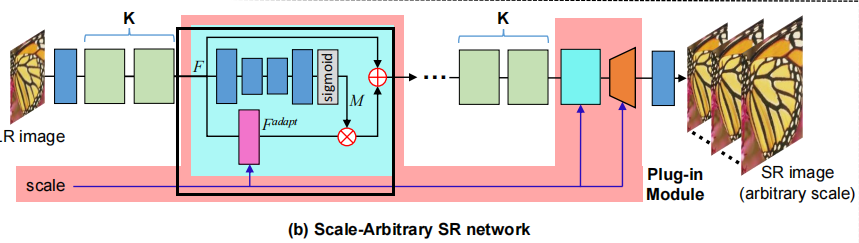
在图三(b)中,特征图F先通过漏斗形模块,以及一个sigmoid,生成一个引导图M.M的值在0-1之间.
F另外通过一个scale-aware卷积取做特征适配,生成\(F^{adapt}\).
然后,引导特征图M被用作融合F和\(F^{adapt}\):
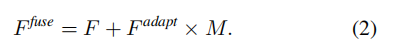
直观上,在不同比例因子之间具有高特征相似性的区域,F 可以直接用作\(F^{fuse}\)融合。
相反,在特征相似度较低的区域,\(F^{adapt}\)被添加到\(F^{fuse}\)中以进行特征自适应。
也就是说,M 作为门控机制并学习指导像素级特征自适应。
特征自适应块中的尺度感知卷积层如图4所示:

首先,将水平和垂直比例因子\(r_{h}\)和\(r_{v}\)馈送到具有两个完全连接 (FC) 层的模型控制器以生成路由权重(routing weights)。
然后,这些路由权重用于组合专家(experts),从而产生一个尺度感知过滤器。
在这里,专家表示一组要根据尺度信息组合的卷积核.
最后,预测过滤器用于处理输入特征图以进行特征自适应。
与带有固定滤波器的香草卷积不同,我们的尺度感知卷积通过结合专家的知识,根据尺度信息动态定制其滤波器。
Scale-Aware Upsampling
对于×r(R=2,3,4)的SR任务,尺寸为\(C_{in}\times H \times W\)的特征首先经过卷积调试通道,生成尺寸为\(r^{2}C_{out}\times H \times W\)的特征.然后将特征改组(shuffle)为\(C_{out}\times rH \times rW\).
pixel shuffling layer可以被认为是一个两步流水线,它由一个采样步骤和一个空间变化的过滤步骤组成(即,\(r^{2}\)个卷积用于\(r^{2}\)个不同的子位置)。
在本文中,我们将pixel shuffling layer概括为一个尺度感知上采样层,如图 5 所示。
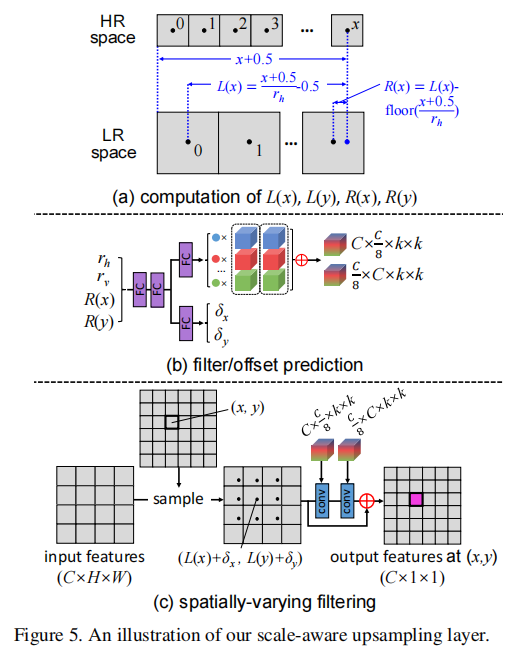
首先,将HR空间中的每个像素\((x,y)\)投影到LR空间,计算其坐标\((L(x),L(y))\)和相对距离\((R(x),R(y))\):
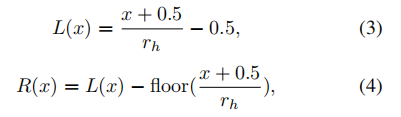
接下来,将 R(x)、R(y),\(r_{h}\) 和\(r_{v}\)连接起来并馈送到两个 FC 层以进行特征提取,如图 5(b) 所示。
然后将生成的特征传递给过滤器和偏移头(offset heads),以分别预测路由权重和偏移量(\(δ_{x}\) 和\(δ_{y}\)).
之后,路由权重用于组合两组专家,从而为图 5(c)中的瓶颈/扩展层生成一对过滤器。
最后,使用双线性插值对以\((L(x) + δ_{x}, L(y) + δ_{y})\)为中心的 k×k 邻域进行采样,并与预测滤波器进行卷积以产生 (x, y) 处的输出特征,如图所示. 5(c)。
- Super-Resolution Scale-Arbitrary Resolution Arbitrary Learningsuper-resolution scale-arbitrary resolution scale-arbitrary super-resolution super-resolution convolutional resolution real-time cvpr_spatial-frequency super-resolution resolution super-resolution continuous resolution diffusion cross-refinement super-resolution high-frequency super-resolution vdsr-accurate convolutional arbitrary arbitrary-styled