Improving Computer Vision Accuracy using Convolutions
在前面的课程中,你们了解了如何使用包含三层的深度神经网络(DNN)进行时装识别,这三层分别是输入层(数据的形状)、输出层(所需输出的形状)和隐藏层。你试验了不同大小的隐藏层、训练epochs数等对最终准确率的影响。
为方便起见,这里再次提供整个代码。运行它,并注意最后打印出的测试精度。
import tensorflow as tf
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images=training_images / 255.0
test_images=test_images / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=5)
test_loss = model.evaluate(test_images, test_labels)
你的训练准确率可能约为 89%,验证准确率约为 87%......还不错......但如何才能使准确率更高呢?一种方法是使用一种叫做 "卷积 "的东西。关于卷积的细节我就不多说了,但它的终极概念是缩小图像内容的范围,将注意力集中在特定的、独特的细节上。
如果你曾经使用滤镜进行过图像处理(例如:https://en.wikipedia.org/wiki/Kernel_(image_processing)),那么卷积看起来会非常熟悉。
简而言之,就是将一个数组(通常为 3x3 或 5x5)传递到图像上。根据矩阵中的公式改变底层像素,就能实现边缘检测等功能。例如,如果你查看上面的链接,你会看到一个为边缘检测而定义的 3x3 矩阵,其中中间的单元格为 8,其所有相邻单元格均为-1。对每个像素点都这样做,最后就会得到一个增强了边缘的新图像。
这种方法非常适合计算机视觉,因为通常这样突出显示的特征可以将一个物品与另一个物品区分开来,这样所需的信息量就少了很多......因为你只需对突出显示的特征进行训练。
这就是卷积神经网络的概念。在密集层之前添加一些层来进行卷积,这样进入密集层的信息就会更加集中,可能也会更加准确。
运行下面的代码 -- 这是与之前相同的神经网络,但这次先添加了卷积层。这将花费更长的时间,但看看对准确性的影响。
import tensorflow as tf
print(tf.__version__)
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images=training_images.reshape(60000, 28, 28, 1)
training_images=training_images / 255.0
test_images = test_images.reshape(10000, 28, 28, 1)
test_images=test_images/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
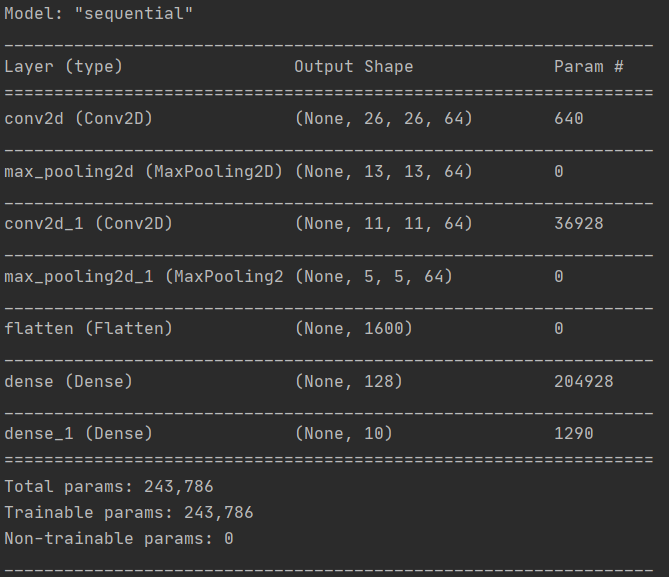
model.summary()
model.fit(training_images, training_labels, epochs=5)
test_loss = model.evaluate(test_images, test_labels)
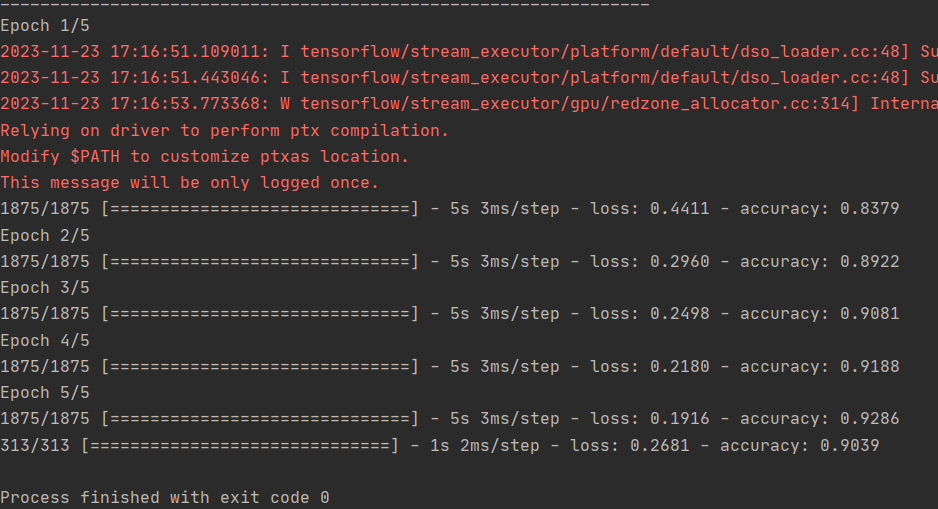
在训练数据和验证数据上,分别提高了约 93% 和 91%。
这很重要,是朝着正确方向迈出的一步!
试着运行更多的历元--比如大约 20 个历元,看看结果如何!虽然结果看起来不错,但验证结果实际上可能会下降,原因是 "过拟合",这将在后面讨论。
(简而言之,"过拟合 "是指网络从训练集中很好地学习了数据,但由于过于专注于这些数据,因此对其他数据的学习效率较低。举个例子,如果你一辈子只见过红鞋子,那么当你看到红鞋子时,你会很擅长识别它,但蓝色的绒面革鞋可能会让你感到困惑......你知道你永远都不应该碰我的蓝色绒面革鞋)。
然后,再看一遍代码,一步步了解如何构建卷积:
第一步是收集数据。你会发现这里有一点变化,训练数据需要重塑。这是因为第一次卷积需要一个包含所有内容的单一张量,因此我们需要一个 60,000x28x28x1 的单一 4D 列表,而不是 60,000 28x28x1 的列表。如果不这样做,在训练时就会出错,因为卷积无法识别形状。
import tensorflow as tf
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images=training_images.reshape(60000, 28, 28, 1)
training_images=training_images / 255.0
test_images = test_images.reshape(10000, 28, 28, 1)
test_images=test_images/255.0
接下来是定义模型。现在,你要添加一个卷积层,而不是顶部的输入层。参数如下:
1.你想要生成的卷积次数(The number of convolutions)应该就是一层多少个卷积神经元。这完全是任意设定的,但最好从 32 个左右开始。
2.卷积的大小,本例中为 3x3 网格
3.要使用的激活函数--在本例中我们将使用 relu,你可能还记得它相当于在 x>0 时返回 x,否则返回 0。
4.在第一层,输入数据的形状。
在卷积之后,您将使用 MaxPooling 图层来压缩图像,同时保留卷积所突出的特征内容。通过为 MaxPooling 指定 (2,2),其效果是将图像的大小压缩为原来的四分之一。这里不做过多赘述,其原理是创建一个 2x2 的像素数组,并选取最大的一个,从而将 4 个像素变成 1 个。在整个图像中重复此操作,这样就可以将水平和垂直像素的数量分别减半,从而有效地将图像缩小 25%。
你可以调用 model.summary() 查看网络的大小和形状,你会发现在每个 MaxPooling 层之后,图像的大小都会以这种方式缩小。
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
添加另一个卷积
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2)
现在平铺输出。之后,您将拥有与非卷积版本相同的 DNN 结构
tf.keras.layers.Flatten(),
与之前卷积示例中的 128 个密集层和 10 个输出层相同:
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
现在compile模型,调用fit method进行训练,并评估测试集的loss和准确率。
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=5)
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(test_acc)
Visualizing the Convolutions and Pooling
这段代码将以图形方式显示卷积结果。print (test_labels[;100]) 显示的是测试集中的前 100 个标签,可以看到位于索引 0、索引 23 和索引 28 的标签都是相同的值(9)。它们都是鞋子。让我们看看对每个标签运行卷积的结果,你会发现它们之间出现了共同的特征。现在,当 DNN 对这些数据进行训练时,它需要处理的数据就少了很多,而且它可能会根据这种卷积/池化组合找到鞋子之间的共性。
print(test_labels[:100])
import matplotlib.pyplot as plt
f, axarr = plt.subplots(3,4)
FIRST_IMAGE=0
SECOND_IMAGE=7
THIRD_IMAGE=26
CONVOLUTION_NUMBER = 1
from tensorflow.keras import models
layer_outputs = [layer.output for layer in model.layers]
activation_model = tf.keras.models.Model(inputs = model.input, outputs = layer_outputs)
for x in range(0,4):
f1 = activation_model.predict(test_images[FIRST_IMAGE].reshape(1, 28, 28, 1))[x]
axarr[0,x].imshow(f1[0, : , :, CONVOLUTION_NUMBER], cmap='inferno')
axarr[0,x].grid(False)
f2 = activation_model.predict(test_images[SECOND_IMAGE].reshape(1, 28, 28, 1))[x]
axarr[1,x].imshow(f2[0, : , :, CONVOLUTION_NUMBER], cmap='inferno')
axarr[1,x].grid(False)
f3 = activation_model.predict(test_images[THIRD_IMAGE].reshape(1, 28, 28, 1))[x]
axarr[2,x].imshow(f3[0, : , :, CONVOLUTION_NUMBER], cmap='inferno')
axarr[2,x].grid(False)
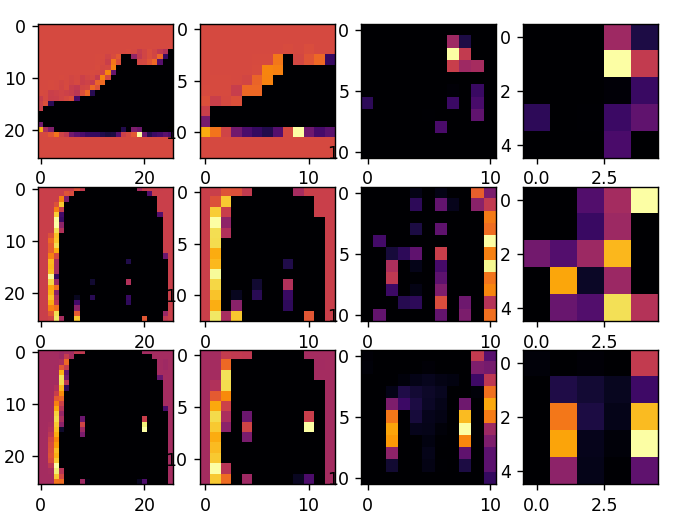
练习(我的API只返回了1875个训练集数据和313个测试集数据?实验结果不可靠)
1.尝试编辑卷积。将 32 改为 16 或 64。这对准确性和/或训练时间有什么影响。
16: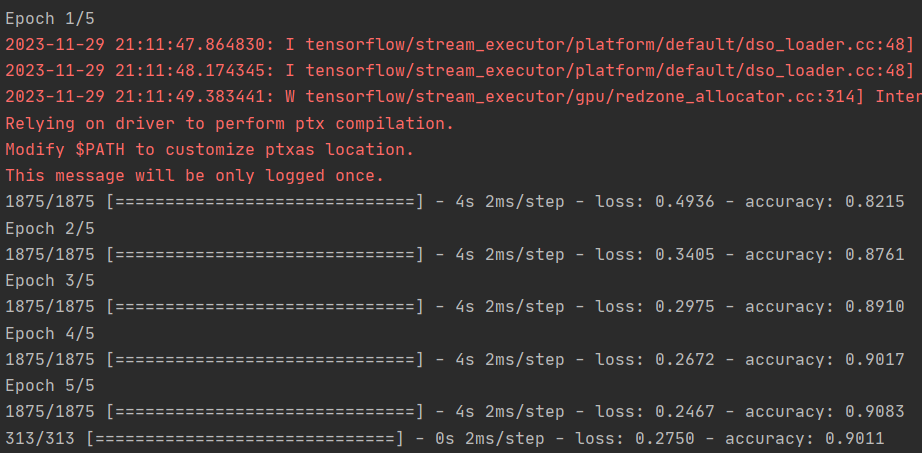
32:
64: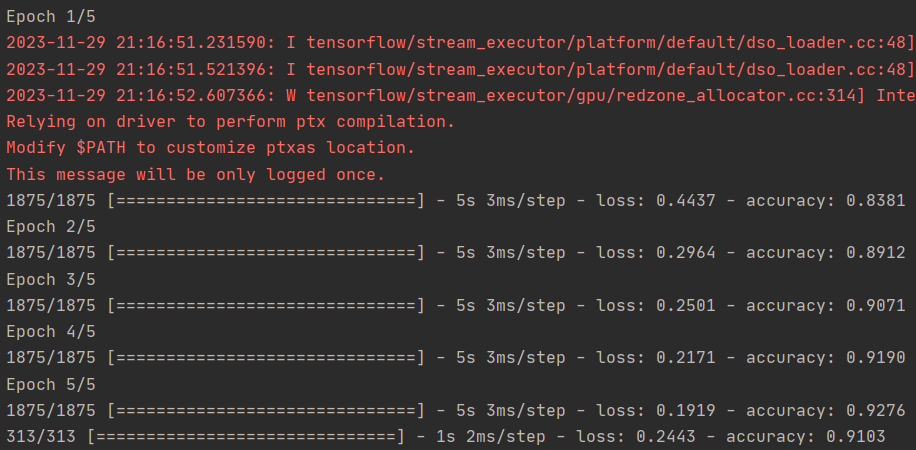
卷积越多准确率越高
2.删除最后的卷积。这会对准确性或训练时间产生什么影响?Remove the final Convolution.
不理解,这和4有什么区别?
3.增加更多卷积呢?你认为这会产生什么影响?进行实验。
三个64卷积层,速度更慢,压缩到池化后1×1,准确率更低
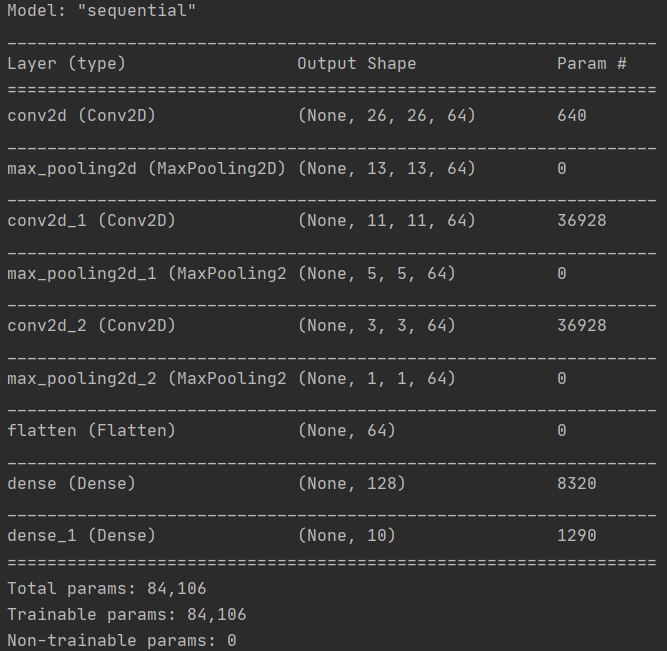
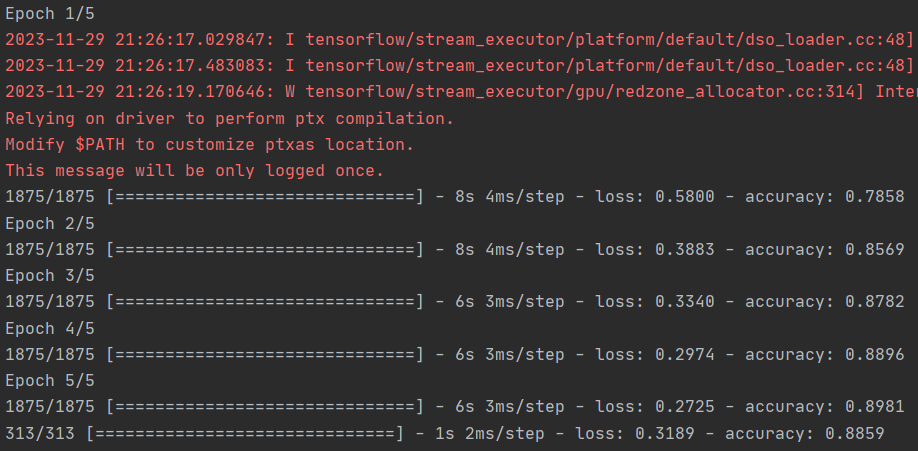
4.删除除第一个卷积之外的所有卷积。你认为这会产生什么影响?实验一下。Remove all Convolutions but the first.
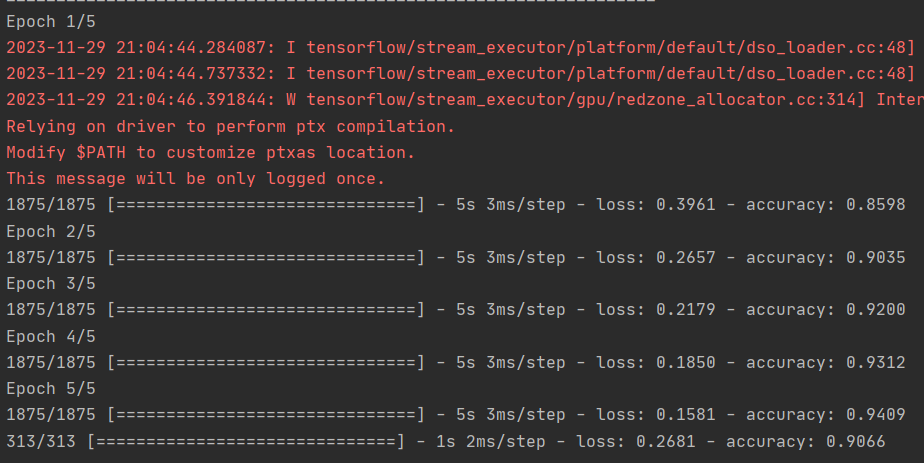
在上一课中,你实现了一个回调来检查损失函数,并在损失函数达到一定值时取消训练。看看能否在这里实现!
[04 Improving Computer Vision Accuracy using Convolutions.py](assets/04 Improving Computer Vision Accuracy using Convolutions-20231129214455-svq89qk.py)
- Convolutions Improving Computer Accuracy Visionconvolutions improving computer accuracy convolutions transformers introducing vision computer example beyond vision inference computer learning vision accuracy convolutions tesseract accuracy improve how improving convolutions-googlenet convolutions transformer prediction versatile