hadoop 的三大组件和关系
1. HDFS:分布式文件系统
hdfs 的特点和不适用使用场景
1.1 HDFS文件系统可存储超大文件(不适用有大量小文件场景和小量场景,默认块大小是MB,资源浪费)
1.2 一次写入,多次读取(不适用多用户更新,hadoop 不支持记录级别的插入更新)
1.3 运行在普通廉价的机器上
1.4 DFS适合存储半结构化和非结构化数据,HDFS延时较高 (不适用低延时场景和严格结构化数据场景,推荐使用Hbase)
2. MapReduce:计算模型(分布式并行计算框架)
2.1 概念浅析
MapReduce 可以将一个大型的数据处理任务分解成很多单个的可以在服务器集群中并行执行的任务,这些任务的计算结果可以合并在一起来计算最终结果。
MapReduce核心思想:分而治之
2.2 模型原理
MapReduce计算模型主要由三个阶段构成:Map、shuffle、Reduce
Map :将文件按设置的block大小切片,映射,负责数据的过滤分法,将原始数据转化为键值对记录,然后输出到环形缓冲区或磁盘;
Shuffle:对MapTask 输出的处理结果进行一定的排序与分割,进一步整理并交给Reduce的过程(Shuffle过程包含在Map和Reduce两端,即Map shuffle和Reduce shuffle)
Reduce: 并行处理Map的结果从缓存或者磁盘copy,合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果。
MapRduce过程详解
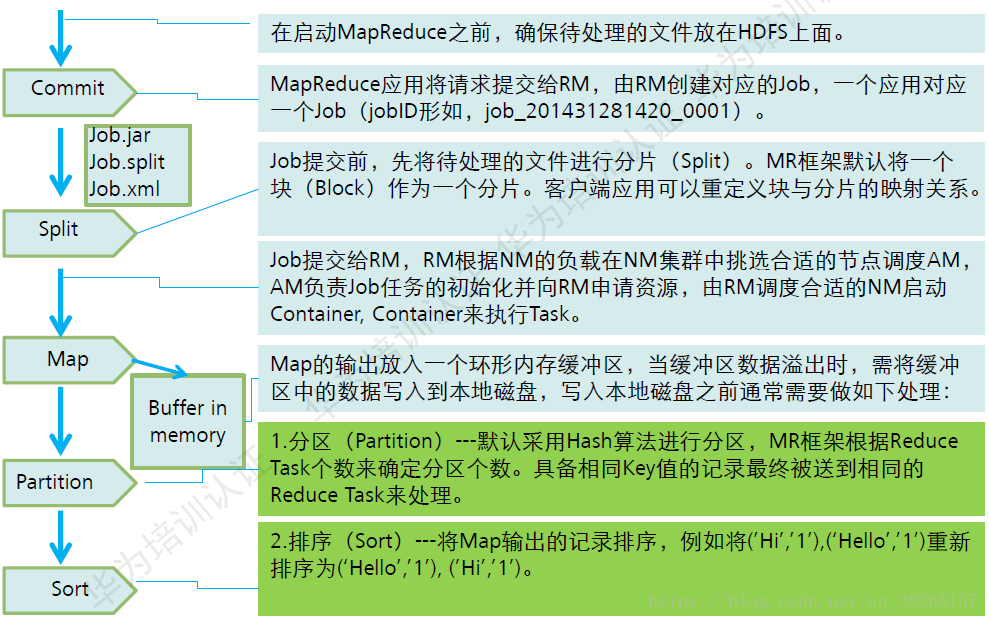

2.3 MadReduce的特点
- 易于编程:程序员仅需描述做什么,具体怎么做由系统的执行框架处理。
- 良好的扩展性:可通过添加结点以扩展集群能力。(硬件/价格/扩展性:普通PC机,便宜,扩展性好)
- 高容错性:通过计算迁移或数据迁移等策略提高集群的可用性与容错性
- 批处理、非实时、数据密集型
3. Yarn:
1.客户端:提交MapReduce作业
2.YARN的资源管理器(Resource Manager),协调集群中资源的分配
YARN的引入,使得多个计算框架(Spark,MapReduce,storm等)可运行在一个集群中
3.YARN的节点管理器(Node Manager)启动并监控集群中的计算容器。
4.ApplicationMaster:每个应用程序对应一个ApplicationMaster负责应用程序相关的事务、比如任务调度、任务监控和容错等。(Spark,MapReduce,storm等)
MapReduce的Application Master,协调MapReduce作业中任务的运行。Application Master和MapReduce任务运行于容器中。这些容器由resourcemanager调度,由namenode管理。
5.分布式文件系统(HDFS),在组建之间共享作业数据