背景
对于消息数量很少的场景, 尝试使用redis stream来做消息队列.
为什么要用redis的stream, redis的其他数据结构可以吗?
参考文章1:https://www.zhihu.com/question/43688764?sort=created
参考文章2:https://www.cnblogs.com/williamjie/p/11201654.html
redis有一些机制有队列的性质,但都有各自的缺点,我们动手试试看
1. List数据类型
List是一个顺序集合,底层数据结构是链表.在尾部追加元素时性能很高,并且数据是顺序结构的.
我们试试看:
# 添加一个字符串
> LPUSH datalist 1,2,3
(integer) 1
# 再添加一个字符串
> LPUSH datalist 4,5,6
(integer) 2
#获取datalist的值
> RPOP datalist
"1,2,3"
#第二次获取
> RPOP datalist
"4,5,6"
#第三次获取
> RPOP datalist
(nil)

原理图:
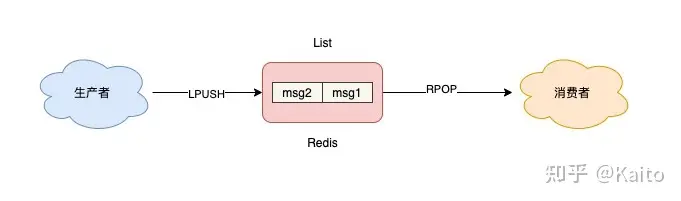
从试验中我们看出来,List数据结构确实有先进先出的队列的性质,生产者往list的尾部添加数据,消费者从头部开始获取数据, 当消费者把数据获取完了之后,再次请求获取到的是nil空值.
我们使用List去拉取数据的时候,肯定是要做一个轮询去查询list中的数据,于是问题出现了:假如list中已经没有数据的话,消费者轮询数据就会造成服务器资源的浪费. 也就是说,这种方法是非阻塞式的拉取消息,不管有没有数据都需要一样的资源消耗.
那么list有没有什么办法可以阻塞式拉取数据, 有数据就拉取没有数据了就阻塞(Block)住呢?
可以用BRPOP和BLPOP, 这个B就是block阻塞的意思,而后面的0就是超时时间,如果设置为0代表不会超时,否则到了超时时间还是会返回一个空值.
#推3条数据进入datalist
> LPUSH datalist 1 2 3
(integer) 3
#第一次阻塞式获取数据
> BRPOP datalist 0
1) "datalist"
2) "1"
#第二次阻塞式获取数据
> BRPOP datalist 0
1) "datalist"
2) "2"
#第三次阻塞式获取数据
> BRPOP datalist 0
1) "datalist"
2) "3"
#第四次阻塞式获取数据
> BRPOP datalist 0
Executing command...
#如果超时时间是1,它一开始也会阻塞,然后过1秒后返回空值
> BRPOP datalist 1
(nil)
从试验中看出来,第四次获取的时候没有获取到数据, 所以它就阻塞住没有返回值了.
这个方案看似挺好的.符合队列的顺序结构, 又能阻塞式拉取避免资源浪费,但也存在以下问题
问题
-
数据丢失
由于list的方式,消费者从list中拉取到数据,这条数据就被list删除了. 如果消费者端出现异常,拉取到了数据之后,处理时异常了(比如插入数据库失败了), 在这种情况下,消息在list中已经被删除了.这条数据就彻底丢失了 -
不能多消费者一起消费同样的数据
这种模式一个消费者消费掉一条数据后, 其他消费者就无法消费到那条数据了, 也就是说不能多个消费者同时消费同样的数据.
比如有两个微服务A,B都需要拉取这个list中的数据做不同的操作, 消息1被A拉走之后,B就获取不到这条数据了, 也即是说一个list中的一条数据只能被消费一次.
2. 发布/订阅模式
如果想要多个消费者消费同样的数据,redis提供了一种发布订阅命令.
使用方法:
#开2个redis-cli客户端做消费者,分别执行SUBSCRIBE [通道名]
127.0.0.1:6379> SUBSCRIBE channel1
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel1"
3) (integer) 1

打开第三个客户端做生产者
127.0.0.1:6379> PUBLISH channel1 hello
(integer) 2
查看两个消费者受到的消息:
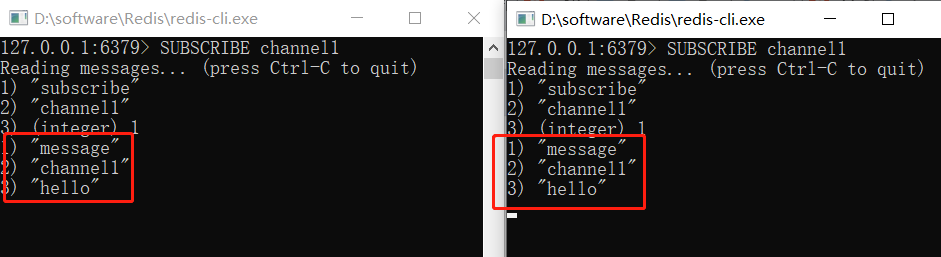
使用发布/订阅模式,既能阻塞式获取数据,又能多个消费者同时消费同样的数据.并且一个消费者还可以同时订阅多个通道比如用通配符的方式
#这种方式可以同时订阅到channel1,channel2....等等的数据
SUBSCRIBE channel*
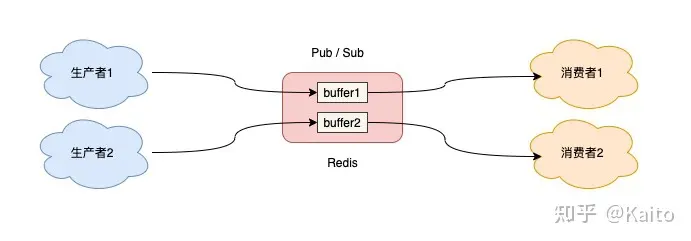
但它也有它的问题
问题
-
数据丢失--消费者必须在线
发布订阅模式,没有做数据的持久化, 仅仅是把生产者和消费者做了信息转发, 一切数据的消费都是实时的,如果发布消息的时候,消费者不在线,那么这个消息就会丢失. 不会做数据的持久化. -
数据丢失--消息积压
发布订阅模式,每个消费者都有一个缓冲区,很小,生产者生产消息后,会把消息推送到各个在线消费者的缓冲区. 如果消费者没及时消费,这个缓冲区就会积压,积压超过缓冲区大小的话,消费者就会被redis认为消费能力不足或者离线,就被踢掉了. -
数据丢失--不会持久化
发布订阅模式不会把未被消费的数据通过AOF或RDB的方式持久化到文件中,因此如果缓冲区还有未被消费的数据, redis宕机重启后,这部分数据也会丢失
3. stream
在redis5.0以上版本增加了一种数据类型:stream. 它是专门用来做轻量级的消息队列的.
值得一提的是,redis的windows版本,官方只维护到了3.x
https://github.com/MicrosoftArchive/redis/releases
如果想要在windows上使用redis5.0才有的stream可以用第github上别人维护的
https://github.com/tporadowski/redis/releases
stream是一个redis的数据结构, 是可以保存数据并且可以持久化的(AOF+RDB),stream做消息队列整个流程可以简化如下:
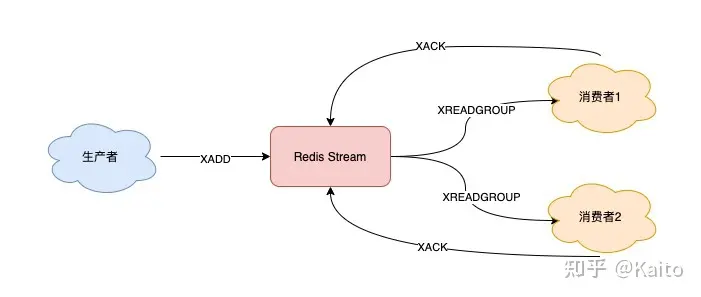
stream消息队列相关命令:
XADD - 添加消息到末尾
XTRIM - 对流进行修剪,限制长度
XDEL - 删除消息
XLEN - 获取流包含的元素数量,即消息长度
XRANGE - 获取消息列表,会自动过滤已经删除的消息
XREVRANGE - 反向获取消息列表,ID 从大到小
XREAD - 以阻塞或非阻塞方式获取消息列表
消费者组相关命令:
XGROUP CREATE - 创建消费者组
XREADGROUP GROUP - 读取消费者组中的消息
XACK - 将消息标记为"已处理"
XGROUP SETID - 为消费者组设置新的最后递送消息ID
XGROUP DELCONSUMER - 删除消费者
XGROUP DESTROY - 删除消费者组
XPENDING - 显示待处理消息的相关信息
XCLAIM - 转移消息的归属权
XINFO - 查看流和消费者组的相关信息;
XINFO GROUPS - 打印消费者组的信息;
XINFO STREAM - 打印流信息
Stream如何使用和注意事项
1. 生产者XADD
# 向stream1(这个是stream的key)中发送一个值为value1的字段feild1(其中value1是我们要获取到的值,而feild1类似表头), 这条消息的id为*也就是让redis自动生成
127.0.0.1:6379> XADD stream1 * feild1 value1
"1690966744938-0"
#再发送一条数据
127.0.0.1:6379> XADD stream1 * feild2 value2
"1690966754533-0"

2. 创建消费者组XGROUP
#创建一个消费者组叫group-1,消费stream1中的数据, 最后一个参数是从哪个id开始消费
# $表示从最后的位置开始,只会接受新的数据,
# 0-0表示从第一个消息开始消费
127.0.0.1:6379> XGROUP CREATE stream1 group-1 0-0
OK
3. 开始消费XREAD
#XREADGROUP用来消费信息,名为consumer的消费者属于group-1消费者组,从stream1中消费
#注意,这个group-1和stream1的对应关系一定要在上一步确定
# 最后的>符号代表这个消费者从最新的没被确认消费过的ID开始消费, 你也可以填任何具体id
#让消费者从你指定的id的下一条开始消费
127.0.0.1:6379> XREADGROUP GROUP group-1 consumer STREAMS stream1 >
1) 1) "stream1"
2) 1) 1) "1690967701252-0"
2) 1) "feild1"
2) "value1"
2) 1) "1690967706594-0"
2) 1) "feild2"
2) "value2"
#当stream1中没有数据的话消费会返回空值
127.0.0.1:6379> XREADGROUP GROUP group-1 consumer STREAMS stream1 >
(nil)
4. 确认消费成功XACK
#确认id为1690967701252-0被消费者组group-1中的消费者消费了,
#注意:同一组的消费者不会互相重复消费,而两个不同消费者组之间同一条数据是两个组都会消费一次的
127.0.0.1:6379> XACK stream1 group-1 1690967701252-0
(integer) 1
5. 主动拉取
XREADGROUP传入上一条数据的id,再拉取下一条(一条循环链就形成了)
COUNT是一次拉取多少条数据
#传入上一条的id: 1690967706594-0再次拉取数据
127.0.0.1:6379> XREADGROUP GROUP group-1 consumer COUNT 1 STREAMS stream1 1690967701252-0
1) 1) "stream1"
2) 1) 1) "1690967706594-0"
2) 1) "feild2"
2) "value2"
6. 阻塞式拉取 BLOCK
a. 当stream中有数据时,拉取指定条数的数据,
b. 当stream中没有数据时,阻塞住,一旦有数据就会立刻拉取
c. BLOCK 0: 其中0表示超时时间无限,即一直阻塞,如果填1000就是阻塞1000ms,超时后没有获取到数据就返回nil
#拉取时没有最新的未被消费数据
127.0.0.1:6379> XREADGROUP GROUP group-1 consumer BLOCK 0 STREAMS stream1 >
Executing command...
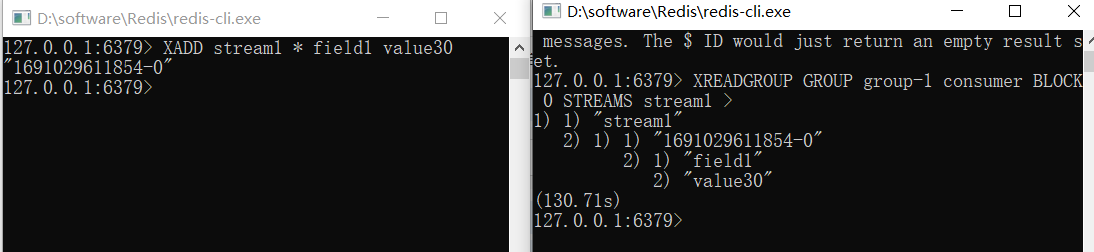
#在另一个redis客户端XADD一条数据到stream1里面看看
127.0.0.1:6379> XADD stream1 * field1 value30
"1691029611854-0"
#可以发现上面那个阻塞的redis客户端立刻获取到了数据,阻塞了130.71s
127.0.0.1:6379> XREADGROUP GROUP group-1 consumer BLOCK 0 STREAMS stream1 >
1) 1) "stream1"
2) 1) 1) "1691029611854-0"
2) 1) "field1"
2) "value30"
(130.71s)
7. 多消费者或多消费者组
#再创建一个消费者组
127.0.0.1:6379> XGROUP CREATE stream1 group-2 $
OK
#组1开两个消费者测试多消费者,组2开一个消费者测试多消费者组
#组1消费者1开启监听
127.0.0.1:6379> XREADGROUP GROUP group-1 consumer1 BLOCK 0 STREAMS stream1 >
_
#组1消费者2开启监听
127.0.0.1:6379> XREADGROUP GROUP group-1 consumer2 BLOCK 0 STREAMS stream1 >
_
#组2消费者开启监听
127.0.0.1:6379> XREADGROUP GROUP group-2 consumer BLOCK 0 STREAMS stream1 >
_
再开一个客户端做消息生产者,逐条生产两条消息
127.0.0.1:6379> XADD stream1 * filed1 value50
"1691030261575-0"
127.0.0.1:6379> XADD stream1 * filed1 value51
"1691030263866-0"
我们来看看结果
#组1消费者1
127.0.0.1:6379> XREADGROUP GROUP group-1 consumer1 BLOCK 0 STREAMS stream1 >
1) 1) "stream1"
2) 1) 1) "1691030261575-0"
2) 1) "filed1"
2) "value50"
(203.10s)
#组1消费者2
127.0.0.1:6379> XREADGROUP GROUP group-1 consumer2 BLOCK 0 STREAMS stream1 >
1) 1) "stream1"
2) 1) 1) "1691030263866-0"
2) 1) "filed1"
2) "value51"
(144.39s)
#组2消费者1
127.0.0.1:6379> XREADGROUP GROUP group-2 consumer BLOCK 0 STREAMS stream1 >
1) 1) "stream1"
2) 1) 1) "1691030261575-0"
2) 1) "filed1"
2) "value50"
(246.37s)
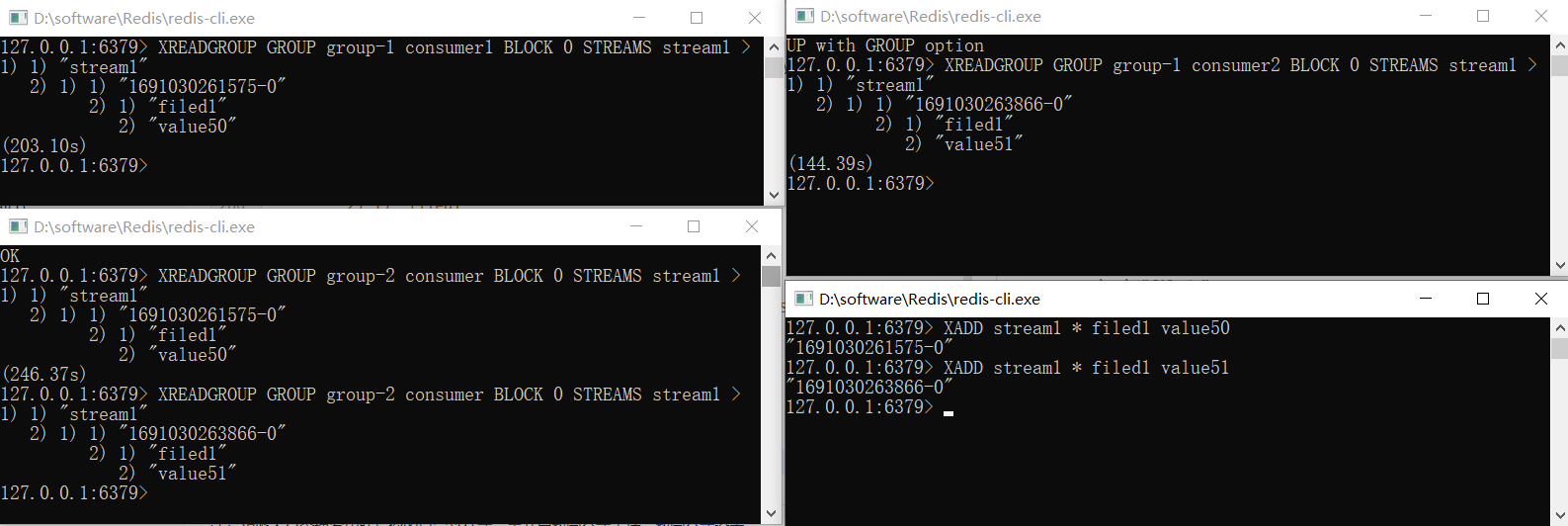
分析下:
- 组1中的两个消费者是分别消费了两条不同的数据, 第一次ADD的数据被消费者1消费了,第二次ADD的数据被消费者2消费了
- 组2中消费者消费了2次,把两条数据都消费到了
- 组1和组2的消费者互不影响, 各自分别从stream中获取数据,两组都会处理同一批数据.
8. 消息拉取成功但是消费失败,如何做到不丢失数据
有了List的前车之鉴,我们想知道stream在消息成功被拉取但是消费失败时是不是也会出现消息丢失呢?
- stream对其下的每个消费者组维护一个待处理条目列表(简称 PEL), 当一条消息被某组中的一个消费者获取到了的时候,就会在PEL中增加这条消息,且这条消息会固定指派给这个消费者;如果这条消息被确认(XACK),就会从PEL中清除,释放内存.
- 如果一条消息被组1消费者1拉取(接管)放入PEL中,但没有被消费者1确认, 那么虽然这条消息还是未确认状态,其他消费者也获取不到它,因为它在获取的时候就已经被消费者1接管了,如果消费者1在未确认的情况下宕机,再次重启使用XREADGROUP读取PEL时,则会再次获取到这条数据.
9. 如果数据未消费完,redis宕机了,如何做到数据不丢失?---持久化
stream作为redis数据类型的一种,它的每个写操作也都会被AOF记录下来, 写入的结果也会被RDB记录下.
AOF记录了redis写操作的操作历史
RDB则是根据一定规则对redis内存中的数据做快照
如果redis宕机重启后,如果配置好持久化策略,也能够恢复回来
但是
- AOF与redis的主写入线程是异步的,因此可能会导致redis突然宕机时,AOF落后于真实数据,造成数据丢失
- RDB是定期做快照,这个就更可能丢失了,快照和宕机之间的数据就丢失了
因此:redis stream无法做到严格的数据完整性
10. 消息积压了怎么办?
消息中间件就像一个水池, 生产者是进入口,消费者是出水口.如果出水的速度比进水慢,那么就会造成消息积压.
解决积压的两个常规思路:
a. 限制生产者生产消息的速度
比如如果是web项目,我们可以通过限流来限制客户访问的数量, 超出数量的客户就提示他网站正忙,稍后重试.
b. 增加消费者消费速度
有一些场景是无法限制生产者生产速度的, 比如接受工厂机器传感器监控生产而定期传入的数据,这些数据是用来控制产品质量的,必须按照一定的并发量生产消息.
stream怎么解决处理:
因为redis的数据都放在内存中, 消息积压可能会导致内存溢出. 所以stream有一个属性就是队列最大长度(MAXLEN), 如果消息积压超过了最大长度,最旧的消息会被截断(XTRIM)丢掉.
具体操作是:
#创建时指定最大长度
XADD stream10 MAXLEN 1000 * field1 value1
"1691035235169-0"
#把stream10剪切到长度为1
127.0.0.1:6379> XTRIM stream10 MAXLEN 1
(integer) 0