复制下面代码,然后需要你本地有python环境
需要下载拓展类
pip install BeautifulSoup #这个可以搜索下用法,很多参数的,解析html和xlm都有
复制下面代码然后切换到你的文件路径运行该指令!
python3 pachong.py

点击查看代码
import requests
from bs4 import BeautifulSoup
'''
requests:获取链接内容
BeautifulSoup:解析html
需要下载指定拓展:pip install BeautifulSoup
'''
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}#模拟浏览器访问,有些是禁止爬虫的
response = requests.get('https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=python%20%E4%BB%8E%E9%9B%B6%E7%88%AC%E8%99%AB%E6%95%B0%E6%8D%AE&oq=php%2520%25E6%259C%25A8%25E9%25A9%25AC%25E5%259B%25BE%25E7%2589%2587%2520%25E5%258D%259A%25E5%25AE%25A2%25E5%259B%25AD&rsv_pq=bb6da3ce0003ab90&rsv_t=6331u6SEA9%2FR7v2jBfsICBxQa8op9atZseoYdzui2KHLfbOdEKYGtVXENp0&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_btype=t&inputT=16252&rsv_sug3=123&rsv_sug1=145&rsv_sug7=100&rsv_sug2=0&rsv_sug4=16252',headers=headers)
htmlcontent = response.content
results_soup = BeautifulSoup(htmlcontent,"html.parser")#这是解析类型
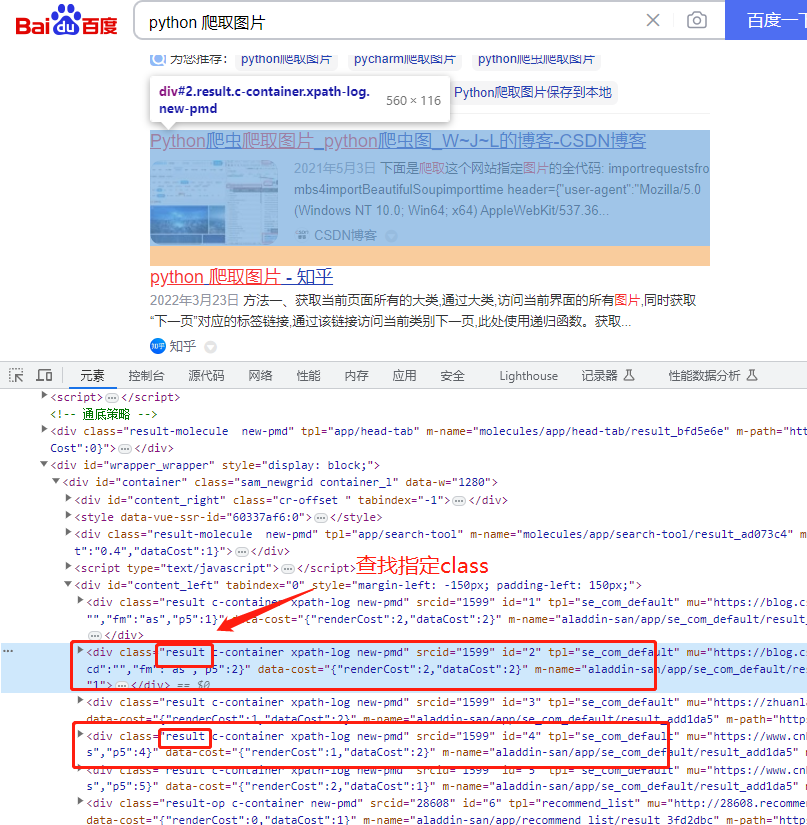
search_results = results_soup.find_all("div",{"class":"result"})#这里是查找指定类获取到所有的元素,find_all就是获取所有指定的div
title_list = []
url_list = []
for result in search_results:
title_list.append(result.find("h3").text)#返回h3的文字->标题
url_list.append(result.a.get('href'))#返回a链接里的href值->链接
#这里好像也要pip install pandas
import pandas as pd
writer = pd.ExcelWriter("测试爬虫数据.xlsx")
pd.DataFrame({"标题":title_list,"链接":url_list}).to_excel(writer,sheet_name="Sheet1",index=False)#导出在你所在文件的目录
writer.close()