概
蒸馏表征间的结构关系, 教师必须是图网络结构?
符号说明
- \(\mathcal{G} = (\mathcal{V}, \mathcal{E})\), 图;
- \(\mathbb{X} = \{x_1, x_2, \ldots, x_n\} \subset \mathbb{R}^F\), \(x_i \in \mathbb{R}^F\) 表示结点 \(v_i\) 上的特征;
- 一般的图网络更新方式为:\[x_i' = \oplus_{j \in \mathcal{N}(i)} h_{\theta}(g_{\phi}(x_i), g_{\phi}(x_j)), \]其中 \(g, h\) 学习边和结点信息, \(\oplus_{j \in \mathcal{N}(i)}\) 则表示融合邻居 \(\mathcal{N}(i)\) 的一种策略 (例如, 求和或者平均);
DistillGCN
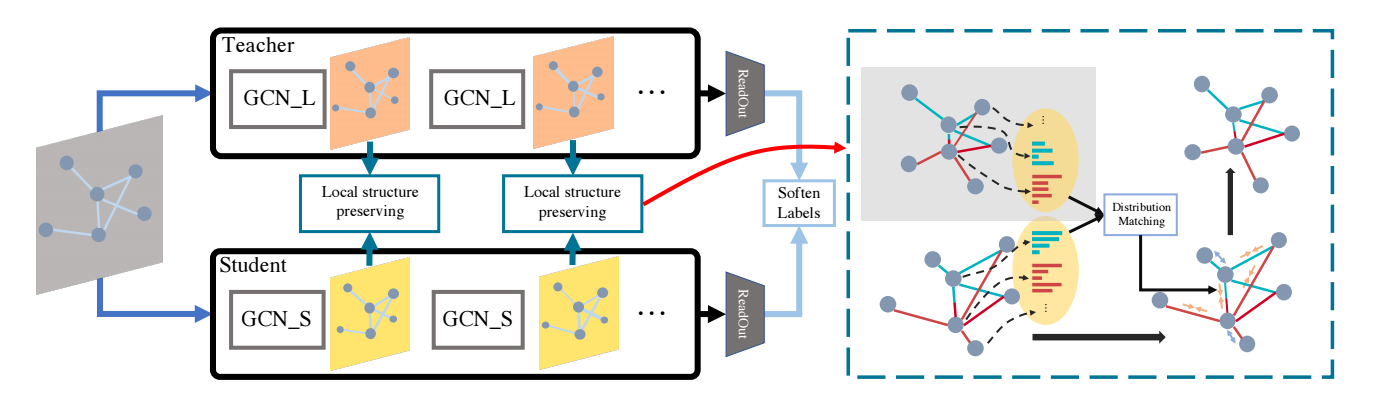
Local Structure Preserving
-
假设我们有每个节点当前的特征:
\[\mathbb{Z} = \{z_1, z_2, \ldots, z_n\} \subset \mathbb{R}^F. \] -
对于每个结点 \(i\), 我们可以计算得到它和邻居结点的一个关系:
\[LS_{ij} = \frac{e^{\mathcal{SIM}(z_i, z_j)}}{\sum_{k \in \mathcal{N}(i)}e^{\mathcal{SIM}(z_i, z_k)}}, \quad j \in \mathcal{N}(i). \] -
这里 \(\mathcal{SIM}(z_i, z_j)\) 为相似度度量函数, 作者建议如下的几种选择 (RBF 的结果最好一点):
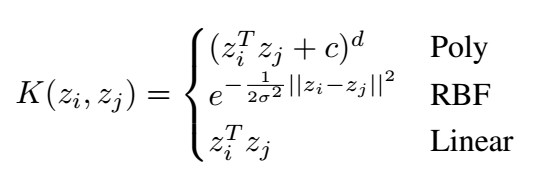
-
假设, 对于教师模型和学生模型我们分别有:
\[LS^t, LS^s, \]则我们可以通过 KL 散度来让学生模仿教师和邻居的关系 (KL 散度确定没搞反吗?):
\[\mathcal{S}_i = D_{KL}(LS_i^s\| LS_i^t) = \sum_{j \in \mathcal{N}(i)} LS_{ij}^s \log \frac{LS_{ij}^s}{LS_{ij}^t}. \] -
然后总的蒸馏损失为:
\[\mathcal{L}_{LSP} = \frac{1}{n} \sum_{i=1}^n \mathcal{S}_i. \] -
总的损失为:
\[\mathcal{L} = \mathcal{H}(p_s, y) + \lambda \mathcal{L}_{LSP}. \]
代码
[official]
- Convolutional Distilling Knowledge Networks Graphconvolutional distilling knowledge networks convolutional eigenpooling networks graph convolutional segmentation biomedical networks classification convolutional imagenet networks convolutional stochastic reduction networks convolutional segmentation networks semantic recommendation convolutional networks hamming convolutional networks neural cnn skeleton-based convolutional recognition networks 卷积convolutional网路networks