Hadoop
java环境安装
hadoop上传、解压
环境变量配置
JAVA_HOME=/usr/local/java/jdk1.8.0_161
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
export HADOOP_HOME=/hadoop/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
修改配置文件
core-site.xml
/hadoop/hadoop-3.3.6/etc/hadoop/core-site.xml
<configuration>
<!--配置文件系统和端口,但不是web端直接访问端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.70.9:9000</value>
</property>
<!--临时文件夹,会创建在对应本地目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/data/tmp</value>
</property>
<!--流文件的缓冲区大小-->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
hadoop-env.sh
/hadoop/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_161
hdfs-site.xml
/hadoop/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
<configuration>
<!--副本数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
启动
第一次初始化
hdfs namenode -format
打印:format success,出现shutting down xxxx不影响。
hadoop-daemon.sh start namenode
use of this script to start hdfs daemons is deprecated
启动namenode 和 datanode
hdfs --daemon start namenode
hdfs --daemon start datanode
报错:Cannot set priority of namenode process 3304
根据日志路经检查:Invalid URI for NameNode address (check fs.defaultFS): file:/// has no authority.
发现配置文件core-site.xml中defaultFS 单词写错,修改后启动成功。
浏览器访问
访问:192.168.70.9:9000
It looks like you are making an HTTP request to a Hadoop IPC port. This is not the correct port for the web interface on this daemon.
特别注意:HaDoop3.0之前web访问端口是50070 hadoop3.0之后web访问端口为9870
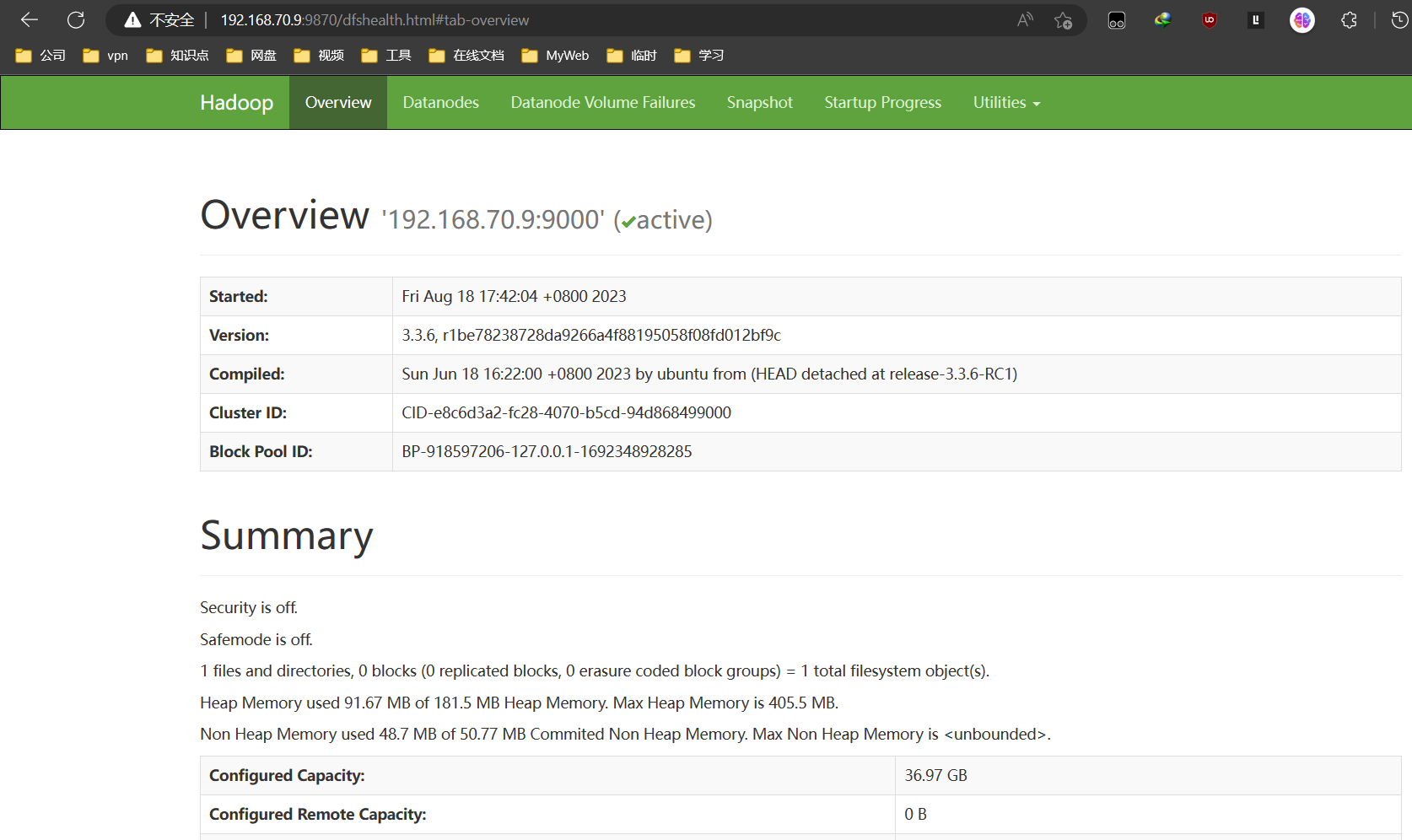
服务器信息
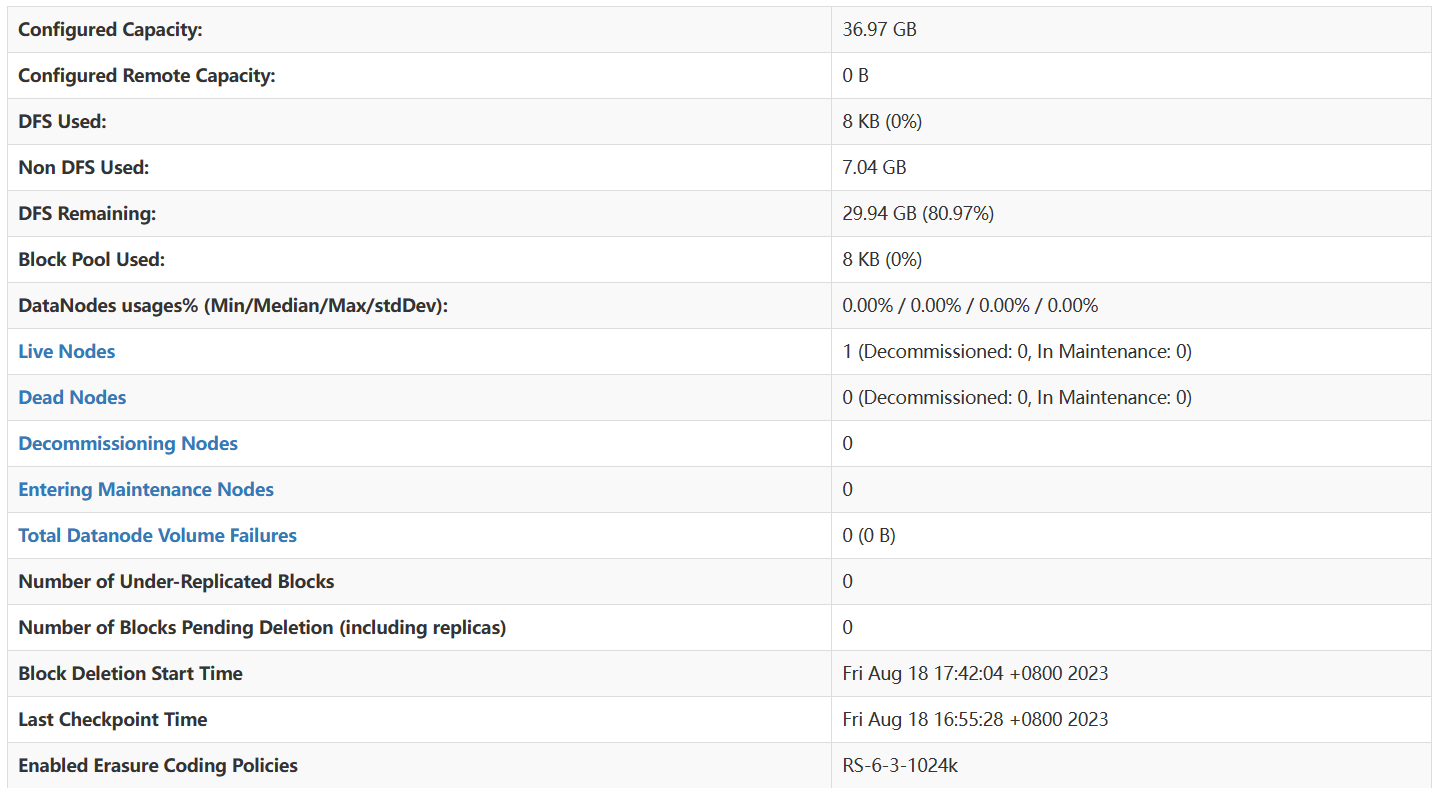
上传文件
[root@localhost sbin]# hdfs dfs -mkdir -p /hadoop/input
[root@localhost sbin]# hdfs dfs -ls /hadoop
Found 1 items
drwxr-xr-x - root supergroup 0 2023-08-18 17:57 /hadoop/input
[root@localhost sbin]# hdfs dfs -put wc.txt /hadoop/input/
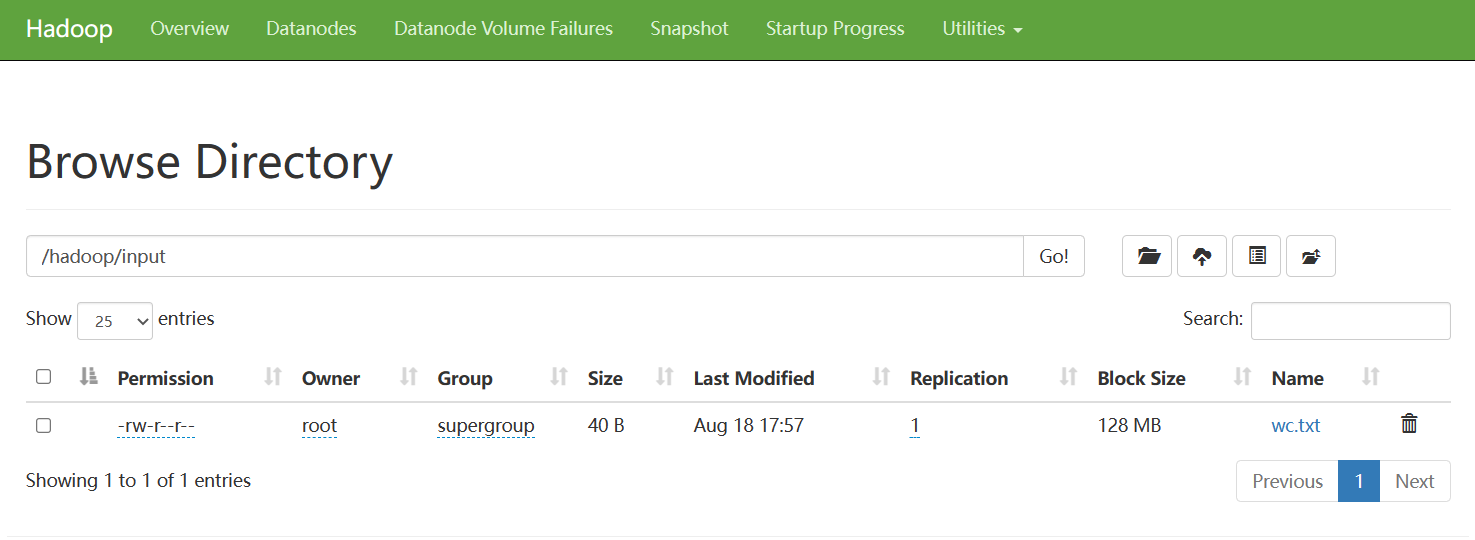
执行统计单词数样例
[root@localhost sbin]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /hadoop/input /hadoop/output
...
[root@localhost hadoop-3.3.6]# hdfs dfs -ls /hadoop/output/
Found 2 items
-rw-r--r-- 1 root supergroup 0 2023-08-18 18:08 /hadoop/output/_SUCCESS
-rw-r--r-- 1 root supergroup 27 2023-08-18 18:08 /hadoop/output/part-r-00000
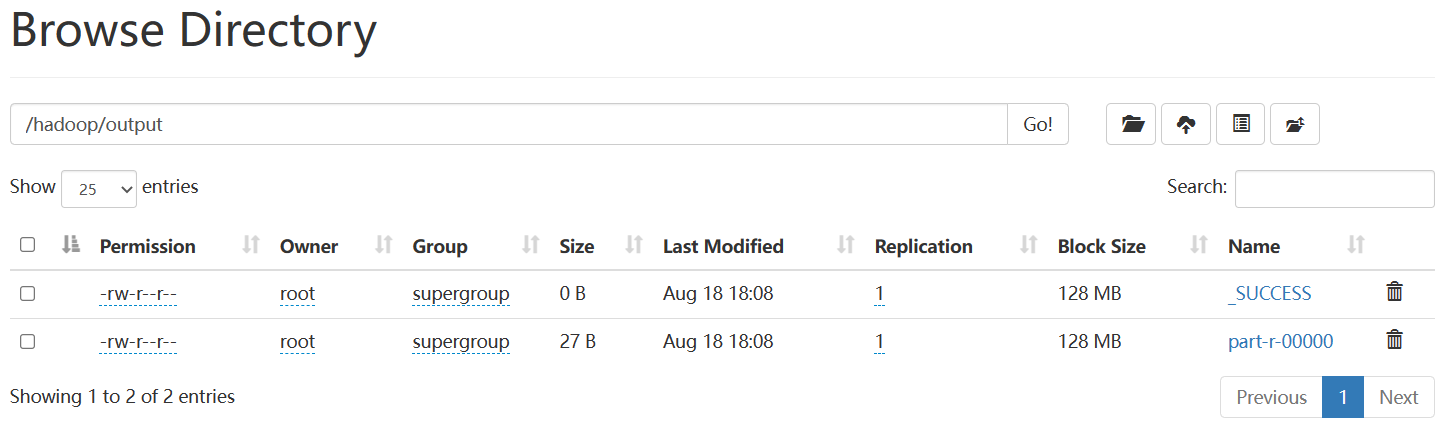
查看统计结果
[root@localhost hadoop-3.3.6]# hdfs dfs -cat /hadoop/output/*
cao 1
chen 1
chenhe 2
he 3
停止datanode 和 namenode
[root@localhost hadoop-3.3.6]# hdfs --daemon stop datanode
[root@localhost hadoop-3.3.6]# hdfs --daemon stop namenode
[root@localhost hadoop-3.3.6]# jps
9391 Jps
HDFS的优缺点
优点
- 高容错,多副本、自动恢复
- 数据、文件规模大
- 流式数据访问
- 可构建在廉价的机器上
缺点
- 不适合低时延的数据访问。
- 大量小文件处理效率不高。会大量占用目录、块信息;查找时间会超过读取文件内容的时间;
- 不支持并发写。一个文件只能有一个写,不支持多线程写;仅支持数据追加;
基础命令
hadoop fs 老版命令
hdfs dfs 新版命令
-ls 查看目录
-cat 查看文件
-put 上传文件
-get 下载文件
-mv 移动文件
-rm 删除文件(有回收站)
-cp 复制文件
-appendToFile 文件追加内容
-chmod 修改权限
-chown 修改所属
存储
设置副本
多备份存储保障高可用、容错;
hdfs-site.xml中配置副本数量,默认数量 3,修改后需要同步修改每一台服务器的配置文件并重启。
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
也可以在上传文件时,指定副本数,但是对已存在hdfs的文件无效
hadoop fs -D dfs.replication=2 -put test.txt /tmp/
对于已存在hdfs的文件,也可修改副本数量
hadoop fs -setrep [-R] 2 path
指定 path 的内容将会被修改为 2 个副本存储。
-R 选项可选,使用 -R 表示对子目录也生效。
fsck命令
file system check:用于检查文件的副本数量
hdfs fsck path [-files [-blocks [-locations]]]
fsck 可以检查指定路径是否正常
• -files 可以列出路径内的文件状态
• -files -blocks 输出文件块报告(有几个块,默认一个块256M,多少副本)
• -files -blocks -locations 输出每一个 block 的详情,存储在哪个节点等待
管理
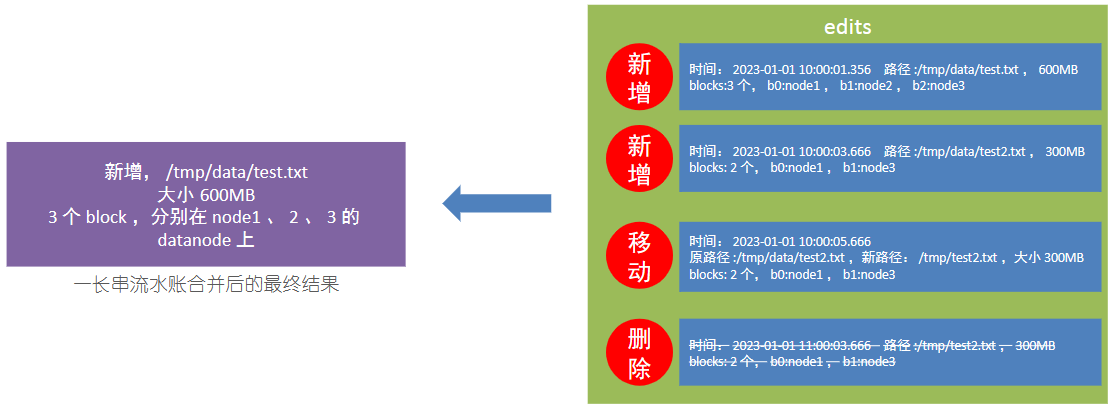
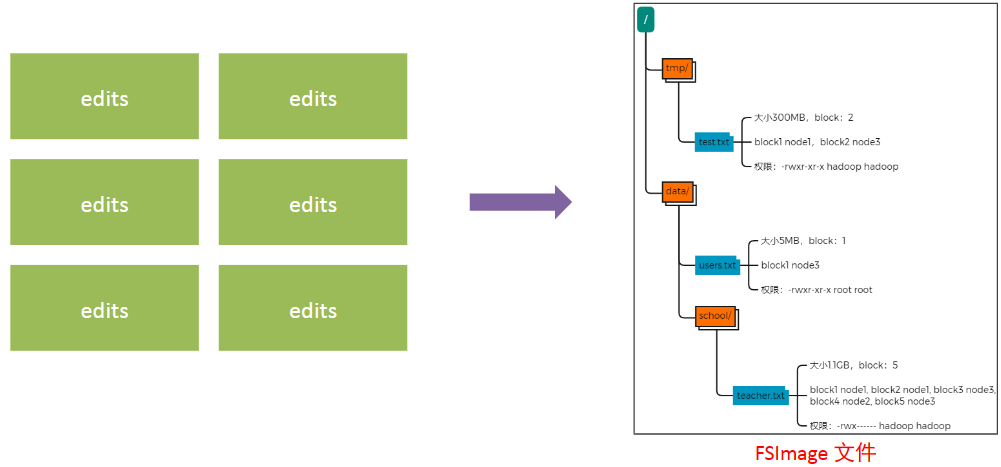
NameNode 基于一批 edits 和一个 fsimage 文件的配合完成整个文件系统的管理和维护。
edits记录每次文件操作信息(增删改),有大小限制,达到阈值后会生成新的,类似于流水账信息;
fsimage整合所有edits信息,保存最后文件存储信息,用于后续文件的查询使用,类似总账信息。fsimage由SeconNameNode进行整合
# 默认定时、按照事务次数进行整合
dfs.namenode.checkpoint.period ,默认 3600 (秒)即 1 小时
dfs.namenode.checkpoint.txns ,默认 1000000 ,即 100W 次事务
# 可设置检查间隔,检查时间、事务次数是否达到阈值
dfs.namenode.checkpoint.check.period ,默认 60 (秒),来决定
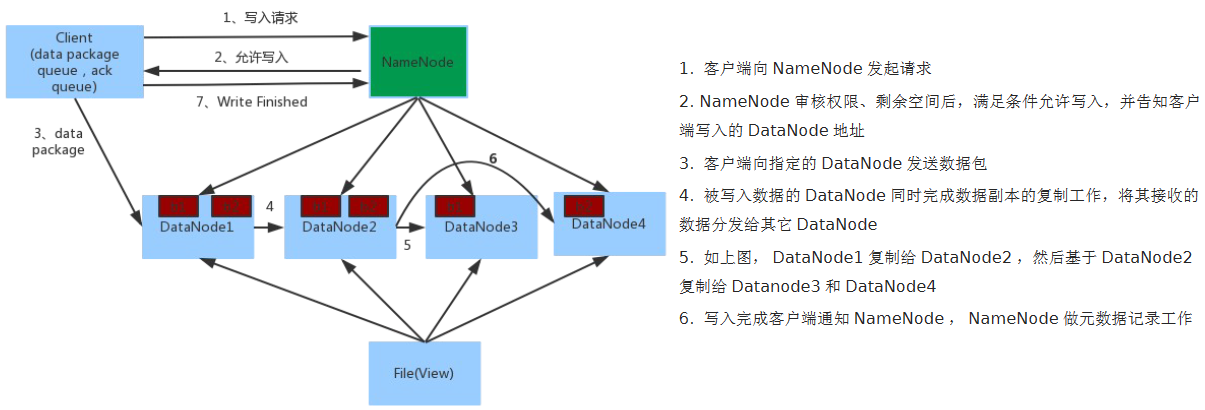
数据读写
NameNode不处理数据的写入,只负责权限审批和操作记录,分配写入节点(计算寻路最近的节点)。
客户端直接向DataNode1写入数据,再由DataNode1向DataNode2复制数据,2复制给3。。。完成后客户端在通知NameNode做元数据记录工作。
MapReduce
概述
核心思想
MapReduce程序运行一半分为两个阶段:Map阶段和Reduce阶段。
Map阶段并发Map task,完全并行,互不相干;
Reduce阶段并发Reduce task,互不相干,但是依赖于上一步map的输出结果;
如果逻辑复杂,就需要多个MapReduce串行。
优点
编写分布式程序,可以分布到大量廉价机器上,可以通过增加机器数量来扩展计算能力;
如果一个机器挂掉了,hadoop会自动将该机器上的计算任务转移到其他机器上,不需要人工参与;
离线处理,适合大量数据计算。
缺点
不适合做实时计算;
输入的数据是静态的,不适合做流式计算;
不适合做有向图的计算(下一次计算依赖于上一次的计算结果);如果做这样的,其前一次的计算结果要写入磁盘,大量io,降低性能;
进程
一个完整的MapReduce程序运行时有三类实例进程:
- MrAppMaster:负责整个程序的过程调度和状态监控协调;
- Map task:负责map阶段数据计算处理;
- Reduce task:负责Reduce阶段数据计算处理;
YARN
架构
主要角色
- ResouManager:整个集群的资源调度者, 负责协调调度各个程序所需的资源。
- NodeManager:单个服务器的资源调度者,负责调度单个服务器上的资源提供给应用程序使用。
NodeManager上分配的资源叫容器,应用程序运行在此容器中,不能突破上限。
辅助角色
- 代理服务器 (ProxyServer) : Web Application Proxy Web 应用程序代理。提高YARN在开放网络中的安全性。提供WEB UI查看。
- 历史服务器 (JobHistoryServer) : 应用程序历史信息记录服务。收集所有容器运行日志,聚合到HDFS,提供WEB UI查看。
Hive
操作语法
数据库操作
创建
指定hdfs存储位置,使用location指定
本质上是保存在hdfs上的一个以.db结尾的文件,默认存储在/user/hive/warehouse(hive.metastore.warehouse.dir)
create databases [if not exists] myhive [localtion '/myhive'] ;
删除
空数据库,如果有数据会报错
drop database myhive;
强制删除
drop database myhive cascade;
数据表操作
建表
内部表
无EXTERNAL修饰;
不可指定保存位置,根据hive.metastore.warehouse.dir指定地址(默认/user/hive/warehouse);
删除时会直接删除元数据和存储的内容,不适合与其他表共享数据;
外部表
有EXTERNAL修饰;create external table ...
可存储在任意位置,通过localtion指定,因为不为hive内部管理,可以随意链接到外部数据上;做临时关联使用;
删除的时候仅仅删除的时元数据(表信息);
表和数据相互独立,表名可以和存储数据的文件名不一致;
- 先创建表,再移动数据到指定的目录下;
- 先创建对应hadoop目录,上传对应数据文件,再根据目录和内容创建表;
自定义分隔符
默认分隔符为ASCII编码字符\001,在linux,cat查看不到,但可以使用vim看到
create table stu(id int,name string ) row format delimited fields terminated by '\t'
内外部表转换
查看表信息
desc formatted table_name;
table_type属性为:MANAGED TABLE代表内部表
# 括号内属性必须要大写
alter table table_name set tblproperties('EXTERNAL'='TRUE');
alter table table_name set tblproperties('EXTERNAL'='FALSE');
数据加载
加载文件数据
LOAD DATA [LOCAL] INPATH 'FILENAME' [OVERWRITE] INTO TABLE TABLE_NAME;
# [LOCAL] 代表加载的文件在Linux文件系统
# [OVERWRITE] 是否覆盖
加载linux文件系统数据后,文件不会消失;
加载hdfs系统文件后,文件本质上是移动到表的hdfs路径;
加载其他表数据
此方式走mapreduce,速度比较慢;
INSERT OVERERITE/INTO TABLE TABLE_NAME1 SELECT * FROM TABLE_NAME2;
数据导出
也是走mapreduce,默认导出分隔符为ASCII编码的;
INSERT OVERWRITE [LOCAL] directory 'path' [row format delimited fields terminated by '\t'] select * from table_name ;
也可以通过hive shell导出
bin/hive -e "select * from table-name" > /test/export.txt
bin/hive -f export.sql > /test/export.txt # export.sql 中保存要执行的sql语句
分区表
CREATE TABLE TABLE_NAME(ID INT,NAME STRING) PARTITONED BY (MONTH STRING )
row format delimited fields terminated by '\t';
LOAD DATA [LOCAL] INPATH 'FILENAME' [OVERWRITE] INTO TABLE TABLE_NAME PARTITION(MONTH='202309')
# 会自动为表添加一列:MONTH
# 会自动在hdfs中表的文件路径下创建文件夹MONTH=202309,下保存数据,多级分区会创建多级目录保存数据;
# 如果创建表的时候指定多几分区,那么加载数据时,也要指定多级的分区配置,一一对应,不能少,也不能多;
可以包分区字段作为条件查询
select * from table_name where month = '202309';