如何搭建canal
MySQL服务器设置
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
我的Linux服务器安装的MySQL服务器是8.0.x版本。
在MySQL中需要创建一个用户,并授权:
#使用命令登录: mysql -u root -p #创建用户 用户名:canal 密码:Canal@123456 create user 'canal'@'%' identified by 'Canal@123456'; #授权 *.*表示所有库 grant SELECT, REPLICATION SLAVE, REPLICATION CLIENT on *.* to 'canal'@'%';
开启mysql binlog ,修改mysql配置
vi /etc/my.cnf
加入下面这段
# 打开binlog log-bin=mysql-bin # 选择ROW(行)模式 binlog-format=ROW # 配置MySQL replaction需要定义,不要和canal的slaveId重复 server_id=1234
重启mysql
service mysqld restart
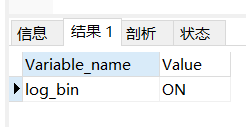
使用命令查看是否打开binlog模式:
show variables like 'log_bin';
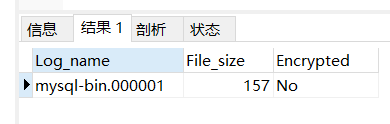
查看binlog日志文件列表:
show binary logs;
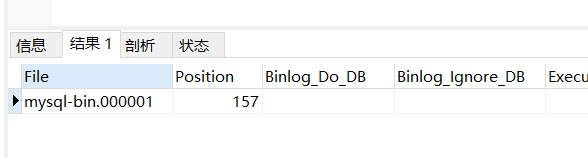
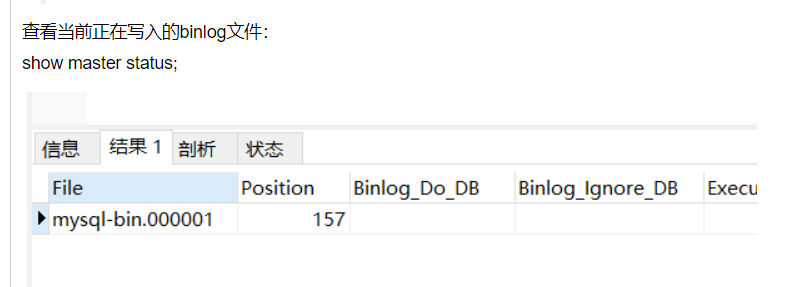
查看当前正在写入的binlog文件:
show master status;
MySQL服务器这边就搞定了,很简单。
Linux安装canal
安装命令
wget https://github.com/alibaba/canal/releases/download/v1.0.23/canal.deployer-1.0.23.tar.gz --no-check-certificate
解压
mkdir /azcf/canal
tar zxvf canal.deployer-1.0.23.tar.gz -C /azcf/canal
修改canal配置文件(如果是访问本机,并且用户密码都为canal则不需要修改配置文件)
[root@master1 canal]# vi /root/canal/conf/example/instance.properties ################################################# ## mysql serverId canal.instance.mysql.slaveId = 1234 # position info canal.instance.master.address = 127.0.0.1:3306 canal.instance.master.journal.name = canal.instance.master.position = canal.instance.master.timestamp = #canal.instance.standby.address = #canal.instance.standby.journal.name = #canal.instance.standby.position = #canal.instance.standby.timestamp = # username/password #修改这两项 canal.instance.dbUsername = canal canal.instance.dbPassword = Canal@123456 canal.instance.defaultDatabaseName = canal.instance.connectionCharset = UTF-8 # table regex canal.instance.filter.regex = .*\\..* # table black regex canal.instance.filter.black.regex = #################################################
Windows安装canal
去官网下载页面进行下载:https://github.com/alibaba/canal/releases

解压canal.deployer-1.1.4.tar.gz,我们可以看到里面有四个文件夹:

接着打开配置文件conf/example/instance.properties,配置信息如下:
## mysql serverId , v1.0.26+ will autoGen ## v1.0.26版本后会自动生成slaveId,所以可以不用配置 # canal.instance.mysql.slaveId=0 # 数据库地址 canal.instance.master.address=127.0.0.1:3306 # binlog日志名称 canal.instance.master.journal.name=mysql-bin.000001 # mysql主库链接时起始的binlog偏移量 canal.instance.master.position=154 # mysql主库链接时起始的binlog的时间戳 canal.instance.master.timestamp= canal.instance.master.gtid= # username/password # 在MySQL服务器授权的账号密码 canal.instance.dbUsername=canal canal.instance.dbPassword=Canal@123456 # 字符集 canal.instance.connectionCharset = UTF-8 # enable druid Decrypt database password canal.instance.enableDruid=false # table regex .*\\..*表示监听所有表 也可以写具体的表名,用,隔开 canal.instance.filter.regex=.*\\..* # mysql 数据解析表的黑名单,多个表用,隔开 canal.instance.filter.black.regex=
注意: # binlog日志名称 为show master status;查出的file 和position
启动:
我这里用的是win10系统,所以在bin目录下找到startup.bat启动:
启动就报错,坑呀:
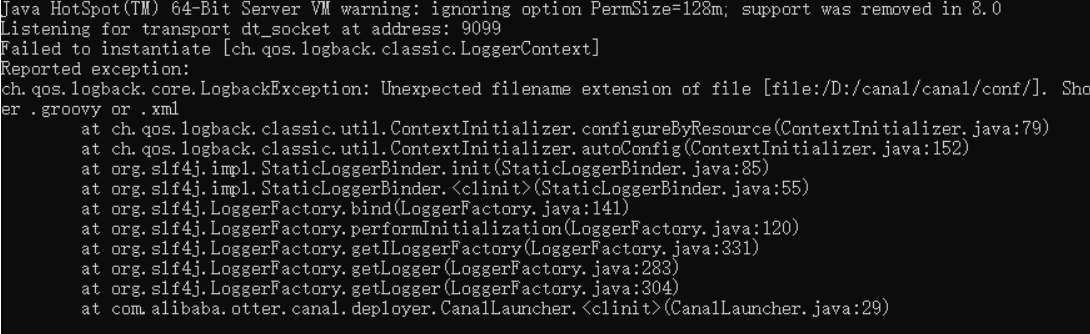
要修改一下启动的脚本startup.bat:
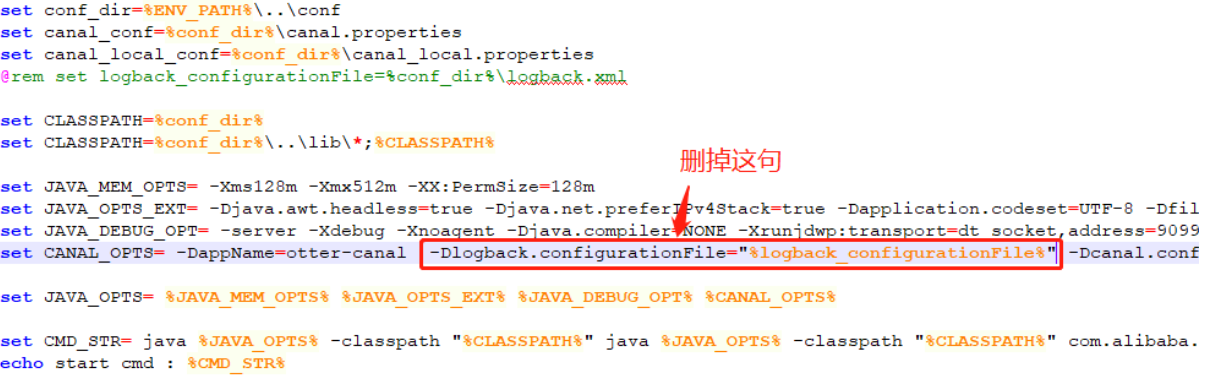
然后再启动脚本:
bin目录下找到startup.bat 双击
Java客户端操作
首先引入maven依赖:
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>
在CannalClient类使用Spring Bean的生命周期函数afterPropertiesSet():
@Component public class CannalClient implements InitializingBean { private final static int BATCH_SIZE = 1000; @Override public void afterPropertiesSet() throws Exception { // 创建链接 CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111), "example", "", ""); try { //打开连接 connector.connect(); //订阅数据库表,全部表 connector.subscribe(".*\\..*"); //回滚到未进行ack的地方,下次fetch的时候,可以从最后一个没有ack的地方开始拿 connector.rollback(); while (true) { // 获取指定数量的数据 Message message = connector.getWithoutAck(BATCH_SIZE); //获取批量ID long batchId = message.getId(); //获取批量的数量 int size = message.getEntries().size(); //如果没有数据 if (batchId == -1 || size == 0) { try { //线程休眠2秒 Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } else { //如果有数据,处理数据 printEntry(message.getEntries()); } //进行 batch id 的确认。确认之后,小于等于此 batchId 的 Message 都会被确认。 connector.ack(batchId); } } catch (Exception e) { e.printStackTrace(); } finally { connector.disconnect(); } } /** * 打印canal server解析binlog获得的实体类信息 */ private static void printEntry(List<Entry> entrys) { for (Entry entry : entrys) { if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) { //开启/关闭事务的实体类型,跳过 continue; } //RowChange对象,包含了一行数据变化的所有特征 //比如isDdl 是否是ddl变更操作 sql 具体的ddl sql beforeColumns afterColumns 变更前后的数据字段等等 RowChange rowChage; try { rowChage = RowChange.parseFrom(entry.getStoreValue()); } catch (Exception e) { throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e); } //获取操作类型:insert/update/delete类型 EventType eventType = rowChage.getEventType(); //打印Header信息 System.out.println(String.format("================》; binlog[%s:%s] , name[%s,%s] , eventType : %s", entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(), entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType)); //判断是否是DDL语句 if (rowChage.getIsDdl()) { System.out.println("================》;isDdl: true,sql:" + rowChage.getSql()); } //获取RowChange对象里的每一行数据,打印出来 for (RowData rowData : rowChage.getRowDatasList()) { //如果是删除语句 if (eventType == EventType.DELETE) { printColumn(rowData.getBeforeColumnsList()); //如果是新增语句 } else if (eventType == EventType.INSERT) { printColumn(rowData.getAfterColumnsList()); //如果是更新的语句 } else { //变更前的数据 System.out.println("------->; before"); printColumn(rowData.getBeforeColumnsList()); //变更后的数据 System.out.println("------->; after"); printColumn(rowData.getAfterColumnsList()); } } } } private static void printColumn(List<Column> columns) { for (Column column : columns) { System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated()); } } }
以上就完成了Java客户端的代码。这里不做具体的处理,仅仅是打印,先有个直观的感受。
最后我们开始测试,首先启动MySQL、Canal Server,还有刚刚写的Spring Boot项目。然后创建表:
CREATE TABLE `tb_commodity_info` ( `id` varchar(32) NOT NULL, `commodity_name` varchar(512) DEFAULT NULL COMMENT '商品名称', `commodity_price` varchar(36) DEFAULT '0' COMMENT '商品价格', `number` int(10) DEFAULT '0' COMMENT '商品数量', `description` varchar(2048) DEFAULT '' COMMENT '商品描述', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品信息表';
然后我们在控制台就可以看到如下信息:

总结
canal的好处在于对业务代码没有侵入,因为是基于监听binlog日志去进行同步数据的。实时性也能做到准实时,其实是很多企业一种比较常见的数据同步的方案。
通过上面的学习之后,我们应该都明白canal是什么,它的原理,还有用法。实际上这仅仅只是入门,因为实际项目中我们不是这样玩的…
实际项目我们是配置MQ模式,配合RocketMQ或者Kafka,canal会把数据发送到MQ的topic中,然后通过消息队列的消费者进行处理。