Spark SQL
1.1Spark SQL简介
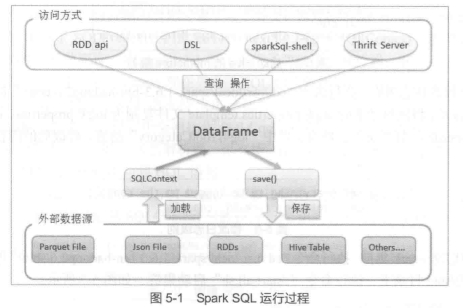
Spark SQL是一个用来处理结构化数据的Spark 组件。它可被视为一个分 布式的SQL查询引擎,并且提供了一个叫作DataFrame的可编程抽象数据模型。Spark SQL的前身是Shark,由于Shark需要依赖于Hive而制约了Spark 各个组件的相互集成,因此Spark团队提出了Spark SQL项目。
Spark SQL提供的最核心的编程抽象是DataFrame, DataFrame是一个分布式的Row对象的数据集合,其本身实现了RDD的绝大多数功能。Spark SQL通常从外部数据源加载数据为DataFrame,然后通过DataFrame上丰富的API进行查询、转换,最后可将结果进行展现或存储为各种外部数据形式。
1.2Spark SQL CLI配置
Spark SQL可以兼容Hive以便Spark SQL支持Hive表访问、UDF ( 用户自定义函数)以及Hive查询语言( HiveQLHQL )。从Spark 1.1 开始,Spark 增加了Spark SQL CLI和ThritServer,使得Hive用户还有用惯了命令行的RDBMS数据库管理员较容易上手。
若要使用Spark SQL CLI的方式访问操作Hive表数据,需要对Spark SQL进行如下所示的环境配置( Spark集群已搭建好),将Spark SQL连接到一一个部署好的Hive.上。当然,即使没有部署好Hive, Spark SQL也可以运行,但是Spark SQL会在当前的工作目录中创建出自己的Hive元数据库.称为metastore_ db。 下面介绍配置Spark SQL使用的Hive环境。