本文根据传入的用户对电影的评分以及电影的类型数据,首先电影和用户作为图的点,根据电影的类型作为电影的特征,用户则通过embedding映射成向量作为特征,用户对电影的评分作为边,再通过torch_geometric把单向边转换为双向边,也就是异构图(点的类型多种,边的类型多种)。最后,传入GNN网络,对每一个点做预测,越接近1表示用户越可能观看此电影。
1.数据处理
(1)构建点
- 处理电影数据
# 处理电影数据Load the entire movie data frame into memory:
movies_df = pd.read_csv('./ml-latest-small/movies.csv', index_col='movieId')
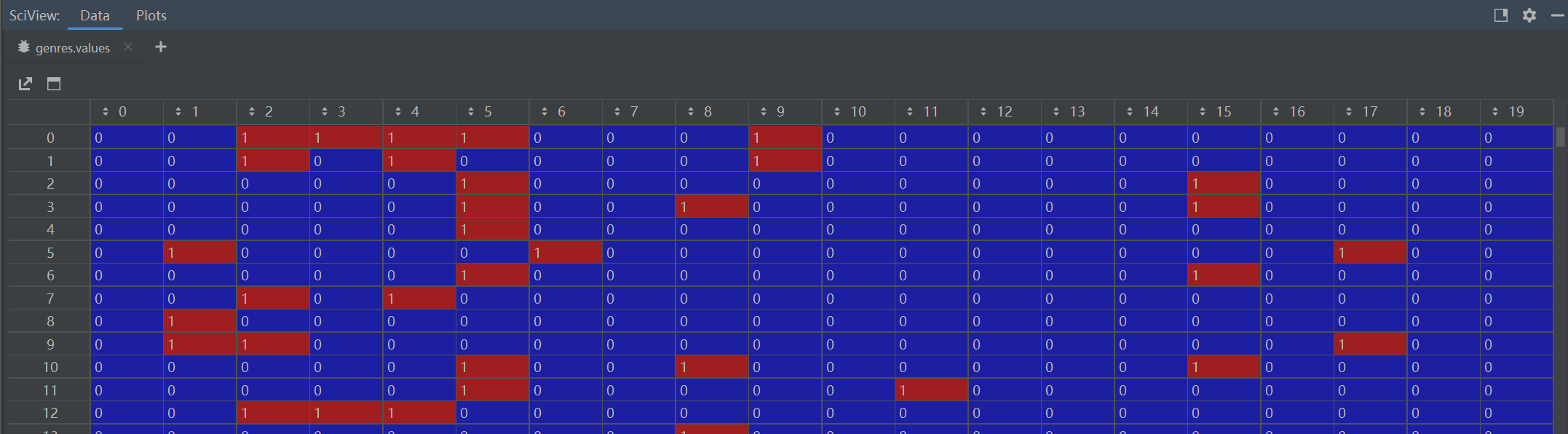
# Split genres and convert into indicator variables:
genres = movies_df['genres'].str.get_dummies('|')#每个电影是一个点,共有20种类型,用|做分隔符,显示一部电影属于哪几种题材,属于类型标1其余标0,作为电影的特征
print(genres[["Action", "Adventure", "Drama", "Horror"]].head())
# Use genres as movie input features:
movie_feat = torch.from_numpy(genres.values).to(torch.float)#转为tensor格式,共9742部电影,每部电影都是20维向量
assert movie_feat.size() == (9742, 20) # 20 genres in total.
-
原始电影数据共9742条,共有20种类型,用|做分隔符,显示一部电影属于哪几种题材,
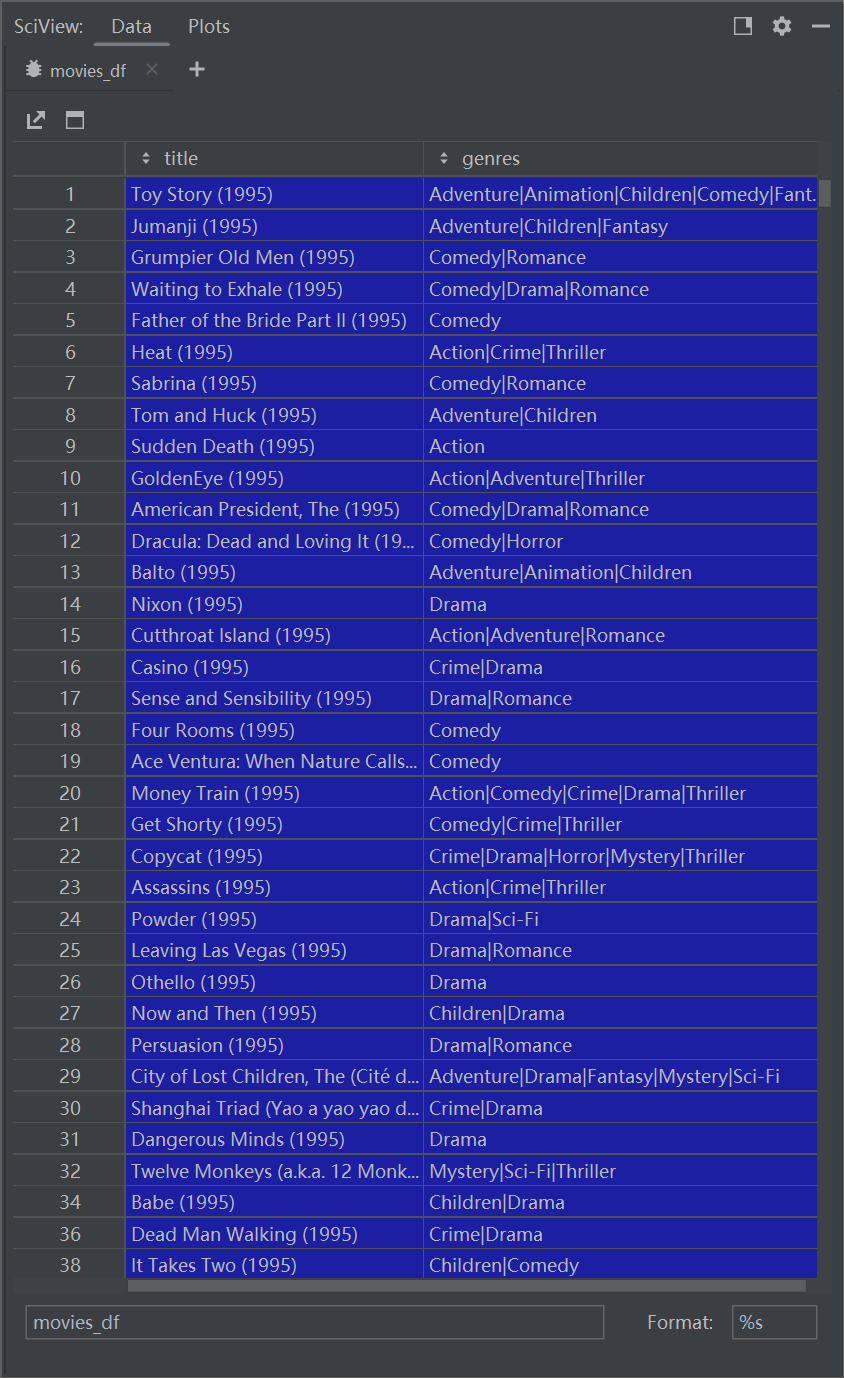
-
每个电影是一个点,属于类型标1其余标0,作为电影的特征
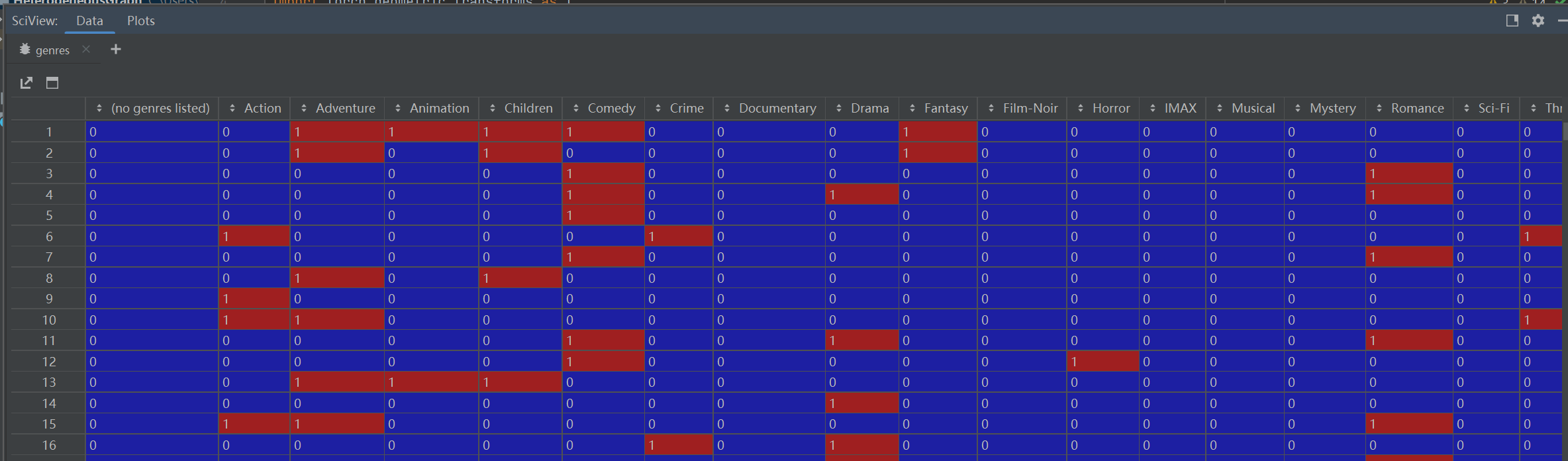
-
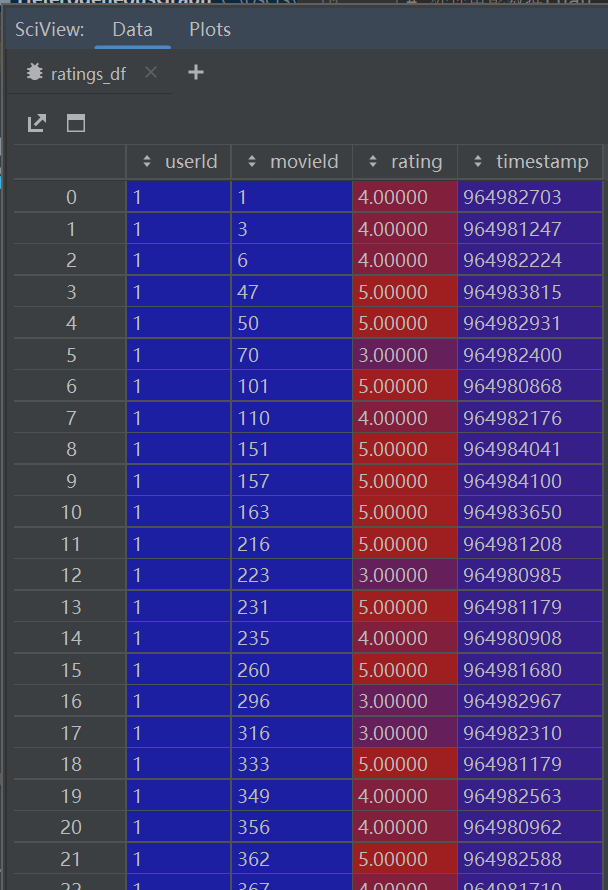
处理用户对电影评价的数据
# 处理用户对电影评价的数据Load the entire ratings data frame into memory:
ratings_df = pd.read_csv('./ml-latest-small/ratings.csv')#用户对电影的评分(1-5分)
# Create a mapping from unique user indices to range [0, num_user_nodes):
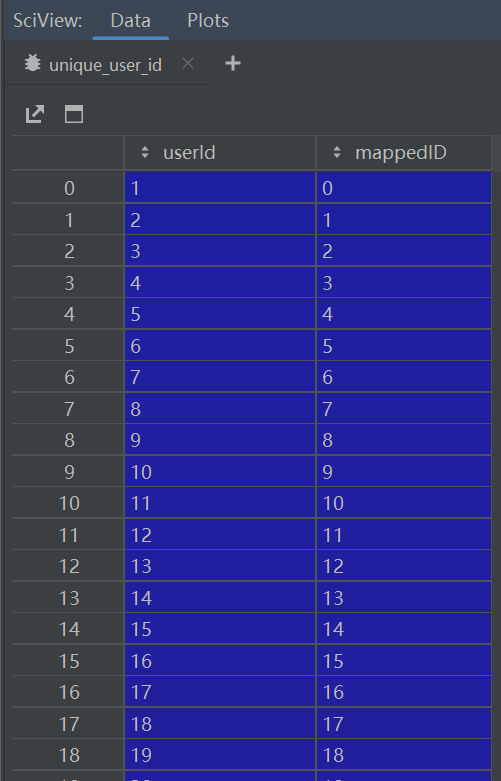
unique_user_id = ratings_df['userId'].unique()
unique_user_id = pd.DataFrame(data={
'userId': unique_user_id,
'mappedID': pd.RangeIndex(len(unique_user_id)),
})#映射userId从0开始。torch_geometric中点和边要求从0开始
# Create a mapping from unique movie indices to range [0, num_movie_nodes):
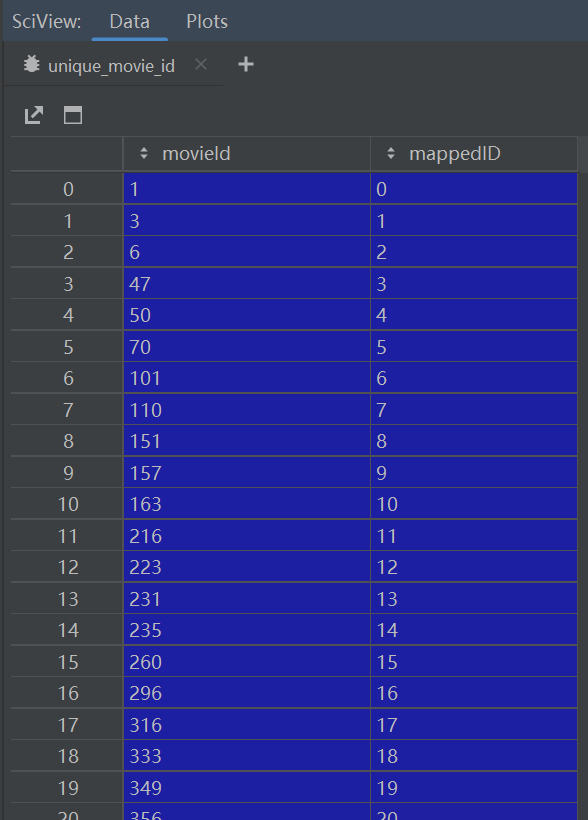
unique_movie_id = ratings_df['movieId'].unique()
unique_movie_id = pd.DataFrame(data={
'movieId': unique_movie_id,
'mappedID': pd.RangeIndex(len(unique_movie_id)),
})#映射movie_id从0开始。torch_geometric中点和边要求从0开始
- 用户对电影的评分(1-5分)
- 映射userId从0开始
- 映射movie_id从0开始
(2)构建边
# Perform merge to obtain the edges from users and movies:
ratings_user_id = pd.merge(ratings_df['userId'], unique_user_id,
left_on='userId', right_on='userId', how='left')#用编码之后的id替换之前的id,评分用户从1...映射到0...
ratings_user_id = torch.from_numpy(ratings_user_id['mappedID'].values)
ratings_movie_id = pd.merge(ratings_df['movieId'], unique_movie_id,
left_on='movieId', right_on='movieId', how='left')
ratings_movie_id = torch.from_numpy(ratings_movie_id['mappedID'].values)#用编码之后的id替换之前的id,movieId从1...映射到0...
# With this, we are ready to construct our `edge_index` in COO format
# following PyG semantics:
edge_index_user_to_movie = torch.stack([ratings_user_id, ratings_movie_id], dim=0)#100836个用户,传入用户对电影评分矩阵,用户评分了哪些电影矩阵,构建边
assert edge_index_user_to_movie.size() == (2, 100836)#由用户到电影构建成边
2.构建异构图
#构建异构图
data = HeteroData()#指定数据格式
# Save node indices:
data["user"].node_id = torch.arange(len(unique_user_id))#定义user点,共610个
data["movie"].node_id = torch.arange(len(movies_df))#定义movie点,9742个
# Add the node features and edge indices:
data["movie"].x = movie_feat#电影的特征,由20种类型构成,在此没有user的特征,后续加上embedding矩阵
data["user", "rates", "movie"].edge_index = edge_index_user_to_movie#边为3元组形式,用户到电影,边的类型(评分关系),edge_index为2*100836
# We also need to make sure to add the reverse edges from movies to users
# in order to let a GNN be able to pass messages in both directions.
# We can leverage the `T.ToUndirected()` transform for this from PyG:
data = T.ToUndirected()(data)#变为无向图,电影到用户,边的关系
3.设置训练参数
- 做二分类任务,需要正、负样本。在训练集当中不加负样本,训练的过程是迭代,负样本是每次取数据时随机选,如果指定为True,则每次迭代都会选择固定的负样本
- 数据切分:训练集中分为消息边用来传递信息,以及监督边用来做预测。验证集,测试集。
transform = T.RandomLinkSplit(
num_val=0.1,
num_test=0.1,
disjoint_train_ratio=0.3,#监督边所占比例
neg_sampling_ratio=2.0,#负样本比例,做二分类任务,需要正、负样本
add_negative_train_samples=False,#在训练集当中不加负样本,训练的过程是迭代,负样本是每次取数据时随机选,如果指定为True,则每次迭代都会选择固定的负样本
edge_types=("user", "rates", "movie"),
rev_edge_types=("movie", "rev_rates", "user"),
)
train_data, val_data, test_data = transform(data)
# In the first hop, we sample at most 20 neighbors.
# In the second hop, we sample at most 10 neighbors.
# In addition, during training, we want to sample negative edges on-the-fly with
# a ratio of 2:1.
# We can make use of the `loader.LinkNeighborLoader` from PyG:
from torch_geometric.loader import LinkNeighborLoader
#每次迭代选一个子图,调包完成
# Define seed edges:
edge_label_index = train_data["user", "rates", "movie"].edge_label_index
edge_label = train_data["user", "rates", "movie"].edge_label
train_loader = LinkNeighborLoader(#传入大图
data=train_data,
num_neighbors=[20, 10],#1阶邻居选20个,2阶邻居选10个
neg_sampling_ratio=2.0,#随机取的负样本的比例
edge_label_index=(("user", "rates", "movie"), edge_label_index),
edge_label=edge_label,
batch_size=128,
shuffle=True,
)
4.构建网络结构
class GNN(torch.nn.Module):
def __init__(self, hidden_channels):
super().__init__()
self.conv1 = SAGEConv(hidden_channels, hidden_channels)
self.conv2 = SAGEConv(hidden_channels, hidden_channels)
def forward(self, x: Tensor, edge_index: Tensor) -> Tensor:
x = F.relu(self.conv1(x, edge_index))
x = self.conv2(x, edge_index)
return x
# Our final classifier applies the dot-product between source and destination
# node embeddings to derive edge-level predictions:
class Classifier(torch.nn.Module):#分类器
def forward(self, x_user: Tensor, x_movie: Tensor, edge_label_index: Tensor) -> Tensor:
# Convert node embeddings to edge-level representations:
edge_feat_user = x_user[edge_label_index[0]]#出发点
edge_feat_movie = x_movie[edge_label_index[1]]#到达点
# Apply dot-product to get a prediction per supervision edge:
return (edge_feat_user * edge_feat_movie).sum(dim=-1)#直接相乘做得分,共384个点,正样本128,负样本两倍
class Model(torch.nn.Module):
def __init__(self, hidden_channels):
super().__init__()
# Since the dataset does not come with rich features, we also learn two
# embedding matrices for users and movies:
self.movie_lin = torch.nn.Linear(20, hidden_channels)#全连接,把movie映射成64维向量
self.user_emb = torch.nn.Embedding(data["user"].num_nodes, hidden_channels)#user用embedding映射成64维向量
self.movie_emb = torch.nn.Embedding(data["movie"].num_nodes, hidden_channels)#movie用embedding映射成64维向量,后续加上全连接的64维向量,做得更好
# Instantiate homogeneous GNN:
self.gnn = GNN(hidden_channels)#同构图
# Convert GNN model into a heterogeneous variant:
self.gnn = to_hetero(self.gnn, metadata=data.metadata())#to_hetero考虑点和边的类型,把同构图转换成异构图
self.classifier = Classifier()#分类器
def forward(self, data: HeteroData) -> Tensor:
x_dict = {#定义字典结构
"user": self.user_emb(data["user"].node_id),#embedding映射成64维向量
"movie": self.movie_lin(data["movie"].x) + self.movie_emb(data["movie"].node_id),#embedding成64维向量加上全连接的64维向量
}
# `x_dict` holds feature matrices of all node types
# `edge_index_dict` holds all edge indices of all edge types
x_dict = self.gnn(x_dict, data.edge_index_dict)#传入边,有用户到电影的边和电影到用户的边。每个源路径分别提特征,然后再做整合
pred = self.classifier(#跳121行分类器,返回384条边,每条边的预测结果
x_dict["user"],
x_dict["movie"],
data["user", "rates", "movie"].edge_label_index,
)
return pred
5.预测
model = Model(hidden_channels=64)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Device: '{device}'")
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(1, 6):
total_loss = total_examples = 0
for sampled_data in tqdm.tqdm(train_loader):
optimizer.zero_grad()
sampled_data.to(device)
pred = model(sampled_data)
ground_truth = sampled_data["user", "rates", "movie"].edge_label
loss = F.binary_cross_entropy_with_logits(pred, ground_truth)#交叉熵
print(loss)
loss.backward()
optimizer.step()
total_loss += float(loss) * pred.numel()
total_examples += pred.numel()
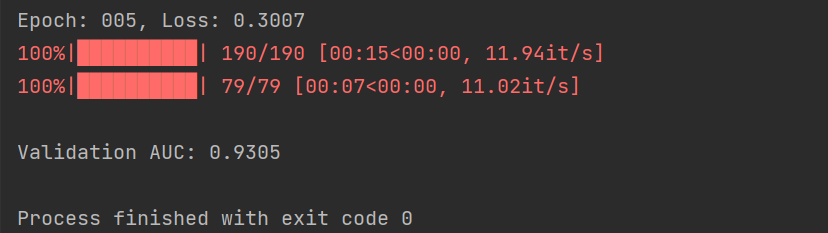
print(f"Epoch: {epoch:03d}, Loss: {total_loss / total_examples:.4f}")
# Define the validation seed edges:
edge_label_index = val_data["user", "rates", "movie"].edge_label_index
edge_label = val_data["user", "rates", "movie"].edge_label
val_loader = LinkNeighborLoader(
data=val_data,
num_neighbors=[20, 10],
edge_label_index=(("user", "rates", "movie"), edge_label_index),
edge_label=edge_label,
batch_size=3 * 128,
shuffle=False,
)
sampled_data = next(iter(val_loader))
from sklearn.metrics import roc_auc_score
preds = []
ground_truths = []
for sampled_data in tqdm.tqdm(val_loader):
with torch.no_grad():
sampled_data.to(device)
preds.append(model(sampled_data))
ground_truths.append(sampled_data["user", "rates", "movie"].edge_label)
pred = torch.cat(preds, dim=0).cpu().numpy()
ground_truth = torch.cat(ground_truths, dim=0).cpu().numpy()
auc = roc_auc_score(ground_truth, pred)
print()
print(f"Validation AUC: {auc:.4f}")
- 准确率达93.05%